
무엇을 배웠는가
관계형 데이터베이스(RDBMS)
관계형 데이터베이스는 키(key)와 값(Value)들의 간단한 관계를 테이블화 시킨 데이터베이스이다. 쉽게 생각해서 엑셀에 데이터를 저장하는 것이라고 생각하면 된다. Relational DataBase Management System의 약자이다.
RDBMS 용어
- 열(column) : 필드(field)라고도 부르며, 속성을 나타낸다.
- 행(row) : 튜플(tuple) 혹은 레코드(record)라고도 부르며, 데이터 하나를 지칭한다.
- 스키마(schema) : 데이터베이스로 볼 수도 있다. 제약 사항을 설정할 수 있다. 예를 들어, 중복을 허용하지 않는다거나 NULL값을 허용하지 않는다 등.
RDBMS에서의 관계

노트북을 판매하는 상점에서 그 날 고객의 주문을 데이터베이스로 정리한다고 하면 주문이 들어오는 순서대로 테이블에 데이터가 쌓일 것이다.
그러나 한 사람이 여러번 주문할 경우 중복된 데이터가 쌓일 위험(?)이 있다. 중복된 데이터가 있을 경우 시각적으로 지저분해 보일 수도 있고 데이터를 수정할 때 복잡하고 유지보수가 어려울 수도 있다.
그래서 RDBMS에서는 테이블을 분리하여 관리할 수 있다.
-
One to One (일대일)

대한민국 국민의 이름과 주민등록번호의 테이블 중 일부만 가져왔다고 생각해보자.
930101-1111111 이라는 주민등록번호는 '송코딩'이라는 사람만 가질 수 있다. '송코딩'과 '이디비'가 동시에 930101-1111111 이라는 주민등록번호를 사용할 수 없다.
반대로 '송코딩'은 930101-1111111 이라는 주민등록번호만 가질 수 있고 다른 주민등록번호를 가질 수 없다. 즉, 이름(user)과 주민등록번호(identification number)는 One to One(1:1)관계를 가진다.

따라서 이렇게 테이블을 분리할 수 있다. 여기서user_id는 어디서 나온 값일까? 바로 Users테이블의id속성을 참조하여 작성한 것이다. 실제로 Identification numbers테이블에서user_id속성에 있는 값들을 Users테이블의id속성에 존재하는 값으로 대입하면 제일 처음 나왔던 메인 테이블과 일치하는 것을 볼 수 있다.
user_id속성은 Users테이블의id를 참조하였으므로
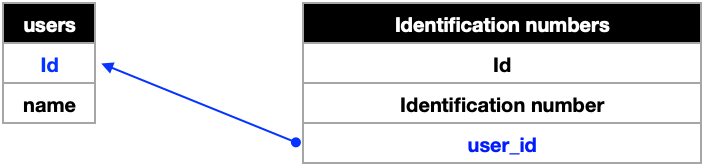
속성(각 열의 제일 첫번째 적혀있는 이름)만 따로 적어서 테이블로 도식화했을 때 이런 그림이 그려진다.user_id는 Users테이블에서 unique한 값인id를 참조하였으므로user_id를 외래키(Foreign Key, FK) 라고 부른다. 그리고 unique한 값인id속성을 고유키(Primary Key, PK) 라고 부른다. 정리하면,
Users테이블의id속성이 Users테이블의 PK, Identification numbers테이블의id속성은 또 Identi....테이블의 PK, 그리고 Identifiacation numbers테이블의user_id속성은 Identi...테이블의 FK과 된다.Users TablePK :
id
FK : None(users테이블을 참조하는 테이블이나 속성이 없음)Identification numbers TablePK :
id
FK :user_id(Users테이블의 id속성을 참조한다.)
-
One to Many (일대다)
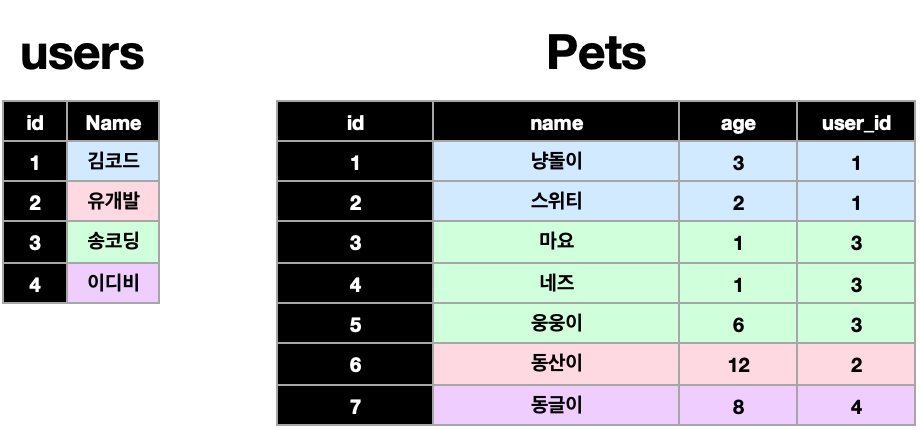
애견샵을 운영하는 매장에서 고객들의 정보를 관리하는 데이터베이스가 이렇게 존재한다고 가정해보면, 한 주인은 여러 반려동물을 가질 수 있지만 한 반려동물은 여러 주인을 가질 수 없다(실제로 불가능한건 아니지만 애견샵에서 여러 주인 중 대표로 한 명만 등록한다고 가정).
그러면 아까와는 다른 상황이 나오게 된다. One to One은 한 이름당 한 주민등록번호만 매칭 가능했지만 이건 한 주인당 여러 펫이 매칭 가능하다. 이것이 바로 One to Many (1:N) 관계이다.
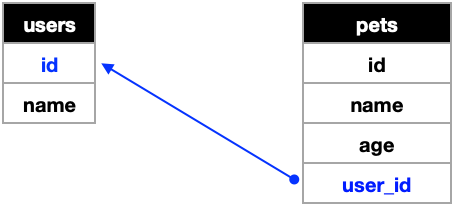
1:1과 마찬가지로 pets테이블의 user_id는 users테이블의 id속성을 참조하여 작성된다. 따라서 pets테이블의 user_id속성이 FK가 된다. -
Many to Many (다대다)
책을 보면 저자가 있다. 그런데 꼭 한명만 그 책을 집필한 것은 아닌 경우가 있다. 여러명이서 한 도서를 집필할 수도 있는 것이다. 그리고 한 저자는 꼭 한 책만 내라는 법은 없다. 즉, 저자 한명이 여러 도서를 출간할 수도 있고 한 책은 여러 저자가 썼을 수도 있다. 이 관계를 표로 정리해서 보면
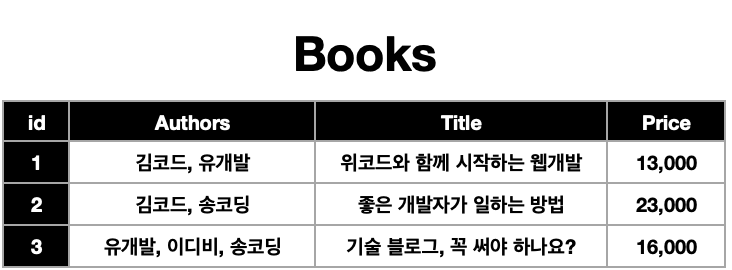
이렇게 된다. 그런데 한 속성에 여러 값이 들어가 있는 것이 보기 매끄럽지 않을 수도 있고 데이터가 많아지면 찾기 힘들어진다. 데이터베이스는 정규화를 통해 여러 테이블로 나눌 수가 있는데 이렇게 한 속성에 해당하는 로우 하나에 여러 값들이 들어갈 수 없다(제 1 정규화 위반).

따라서 귀찮더라도 이런식으로 작성해야 한다. 그런데 이것도 자세히 보면 지저분해 보인다. 중복된 값들이 많다. 이 문제를 위에서 했던 방식과 비슷하게 FK를 이용해서 테이블을 나눌 수 있다.
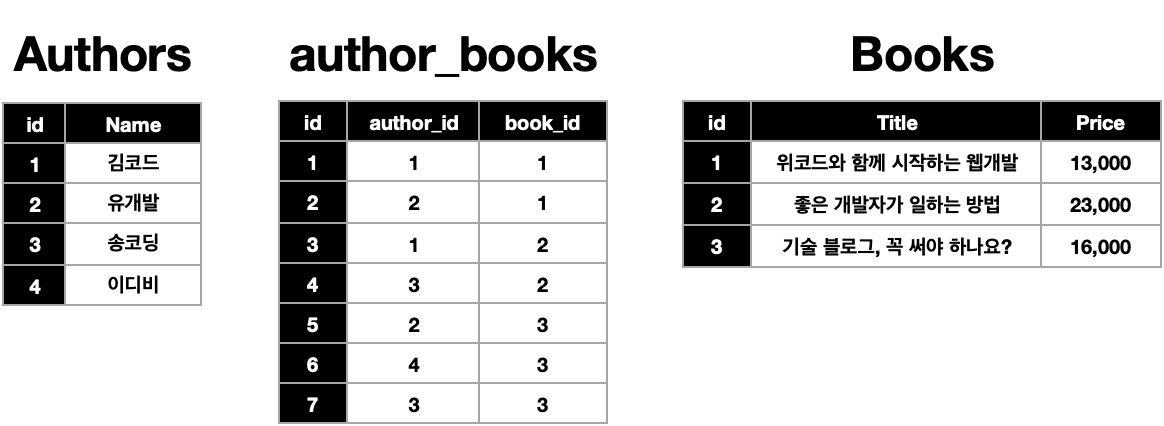
author_books테이블에서author_id는 Authors테이블의id이고book_id는 Books테이블의id이다. 실제로 각 id에 해당하는 레코드를 대입하면 위에 전체 테이블과 일치한다.결국 긴 문자열을 숫자로 매핑해서 바꿔준 것 밖에 없지 않나? 결국은 id도 중복되는데?
라고 생각할 수 있지만 바로 그것 때문에 나눠주는 것이다. 책 한권이 새로 발간되었는데 이 책을 만든 사람이 총 100명이라면 똑같은 데이터를 일일이 다 저장해야하는 수고스러움이 있을 것이다. 그러나 이렇게 테이블을 나누어서 관리하면 Books테이블에 책이름과 가격만 저장하고, Authors에는 기존에 있던 저자를 제외한 새롭게 참가한 저자들만 저장하고 두 테이블을 이어서 저장해주기만 하면 된다.
위 테이블을 도식화하면 다음과 같다.

어디에 적용했는가?
위코드 첫 팀프로젝트인 '스타벅스 서비스 모델링'에서 관계형 데이터베이스의 ER다이어그램을 모델링하는 과제를 푸는데 적용하였다. 기존에 데이터베이스를 얕게 배운터라 ERD를 구현하는데 머리가 복잡하고 시간이 오래걸렸다. 그러나 다시 정리해가며 천천히 하나씩 테이블을 연결해 보니 완벽하진 않지만 구현하는데 성공했다.
어려웠던 점은 무엇인가?
먼저 어떤 key를 외래키로 사용해야 하는지 헷갈렸다. 그리고 id값을 따로 주지 않고 음료의 이름으로 PK를 설정하려고 하다보니 계속 꼬였는데 id값을 주고나서 차근차근 연결해보니 잘 되었다.
