
Indeed 홈페이지 Web Scraping 해보기
노마드 코더를 보고 따라하는 것이라서 Indeed 구인 구직 공고 홈페이지를 Web Scraping 해보았다.
참고로 HTML과 CSS에 대한 지식이 어느정도 있어야 수월하게 진행 가능
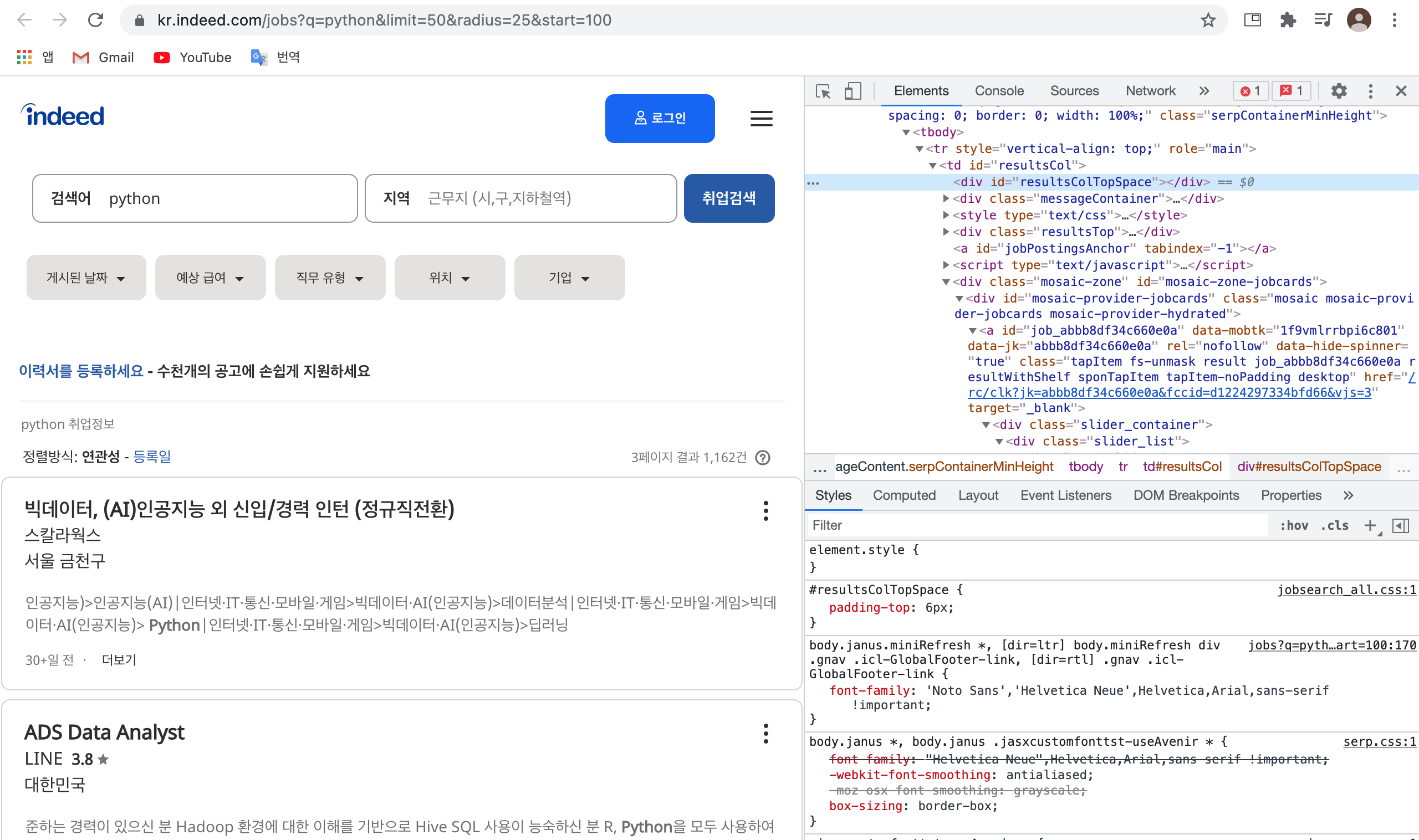
Indeed 사이트와 Inspect window이다. 먼저 이 페이지에서 python으로 검색한 결과의 회사명과 공고 title을 스크래핑할 것이기 때문에 요소 선택으로 그 요소가 어떤 class명을 가지고 있는지 먼저 확인해 본다.

Title :
h2 Tag에 class명은 jobTitle이다.Company :
span Tag에 class명은 companyName이다.
Python 코드
indeed.py
import requests from bs4 import BeautifulSoup LIMIT = 50 URL = f"https://kr.indeed.com/%EC%B7%A8%EC%97%85?q=python&limit={LIMIT}&filter=0" def extract_indeed_pages(): result = requests.get(URL) soup = BeautifulSoup(result.text,"html.parser") start = 0 next_bttn = soup.find("a",{"aria-label":"다음"}) while next_bttn: url_next = f"https://kr.indeed.com/%EC%B7%A8%EC%97%85?q=python&limit=50&start={start*50}" result_next = requests.get(url_next) soup_next = BeautifulSoup(result_next.text, "html.parser") next_bttn = soup_next.find("a", {"aria-label":"다음"}) if next_bttn==None: break start = int(start) + 1 return start + 1 def extract_indeed_jobs(last_page): result = requests.get(f"{URL}&start={0*LIMIT}") soup = BeautifulSoup(result.text, "html.parser") results = soup.find_all("td",{"class":"resultContent"}) title_list = [] comp_list = [] for res in results: h2_title = res.find_all("h2", {"class":"jobTitle"}) for h2_item in h2_title: spans = h2_item.find_all("span") for span in spans: title = span.get("title") if title is not None: title_list.append(title) companys = res.find_all("span",{"class":"companyName"}) for comp in companys: company = comp.string comp_list.append(company) for t in range(min(len(title_list),len(comp_list))): print(title_list[t], ':', comp_list[t],end='\n')main.py
from indeed import extract_indeed_pages, extract_indeed_jobs last_indeed_page = extract_indeed_pages() extract_indeed_jobs(last_indeed_page)
requests모듈과 BeautifulSoup모듈은 전에 작성한 WEB Scraping - 2에서 사용법을 알 수 있다.
먼저 시작 전에 페이지당 화면에 띄울 공고 개수를 50개로 설정한다.
그 다음 URL주소를 확인해 보면
https://kr.indeed.com/%EC%B7%A8%EC%97%85?q=python&limit=50&filter=0 이렇게 되는 것을 볼 수 있다.
def extract_indeed_pages()
먼저 위의 URL주소를 가지고 페이지가 총 몇 페이지인지 추출한다.
result = requests.get(URL)URL주소를
requests.get("URL주소")로 Get방식으로 요청한다.soup = BeautifulSoup(result.text, "html.parser")그 다음
BeautifulSoup(이하bs)모듈을 사용하여 해당 페이지의 HTML을 파싱해 온다.(soup = BeautifulSoup(result.text,"html.parser")start = 0indeed에서 python으로 검색하면 총 20개의 페이지가 나오는데, 1페이지의 start값은 0, 2페이지의 start값은 50, ... 20페이지의 start값은 950이다. 즉, 0부터 시작하여 페이지당 50씩 늘어난다.
start = 0은 시작 주소를 저장하기 위함이다.next_bttn = soup.find("a",{"aria-label":"다음"})아까 parsing해온 html에서
"a"태그를 찾는다. 근데 어디서 찾냐면"aria-label"이"다음"인 a태그를 찾는다.
실제 이 페이지에서"aria-label"이"다음"인 태그는 다음 페이지로 넘어가는 버튼 뿐이다. 이걸 만든 이유는 한 페이지에서 정보를 다 찾으면 다음 페이지에서 또 찾고, 이런 식으로 모든 페이지의 정보를 긁어오기 위함이다.while next_bttn:next_bttn이 존재할 때 까지 반복문을 진행한다. 페이지의 끝으로 가면>버튼이 안나오기 때문이다.url_next = f"https://kr.indeed.com/%EC%B7%A8%EC%97%85?q=python&limit=50&start={start*50}"다음 페이지의 주소를 f-string을 이용하여
url_next변수에 저장한다. 포맷팅이start값에 지정된다. 반복문 하단부에 start값을 1씩 올릴 것이다.result_next = requests.get(url_next)위에 저장된 링크를 요청하여 불러온다.
soup_next = BeautifulSoup(result_next.text, "html.parser")불러온 다음 페이지의 주소를 파싱한다.
next_bttn = soup_next.find("a", {"aria-label":"다음"})그 다음 페이지에서 또 라벨이 "다음"인 a태그를 찾아서
next_bttn변수에 저장한다.if next_bttn==None: break다음 버튼이 존재하지 않으면(가장 마지막 페이지로 갔으면) 반복문 종료
start = int(start) + 1start값을 1증가시킨다.
url_next = f"https://kr.indeed.com/%EC%B7%A8%EC%97%85?q=python&limit=50&start={start*50}"
에서 start값에 1증가하므로 다음 페이지의 주소가 다시 저장된다.return start + 1마지막 페이지까지 가고 반복문이 종료되면 start는 19가 되어있을 것이다. (총 20페이지인데
start가 0부터 시작했으므로 19에서 끝난다.) 그래서 1을 더해줘서 총 페이지 개수를 반환한다.
def extract_indeed_jobs(last_page)
위에서 반환된 값을 가지고 본격적으로 원하는 정보를 추출한다.
main.py파일에서 last_indeed_page = extract_indeed_pages()로 마지막 페이지를 인자값으로 전달해 주는데 사실 20페이지의 정보를 모두 가져오려면 너무 오래걸리고 많이 때문에 이 코드에서는 1페이지의 정보만 사용한다.
def extract_indeed_jobs(last_page):
#위와 똑같이 주소를 가져오고 파싱을 한다. 1페이지만 가져오기 때문에 0*LIMIT로 첫번째 페이지만 가져온다.
result = requests.get(f"{URL}&start={0*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
#직업의 정보가 들어있는 태그는 td태그에 들어있고 class는 "resultContent"이다. 그걸 찾아와서 results변수에 저장한다.
results = soup.find_all("td",{"class":"resultContent"})
#공고문의 제목과 회사명을 담을 리스트 선언
title_list = []
comp_list = []
#찾은 결과(results)에서 각각의 결과를 하나씩 확인할 것이다.
#페이지당 출력되는 공고가 50개로 설정했으므로 50개의 결과가 있을 것
for res in results:
#찾은 결과에서 title은 h2태그의 jobTitle이라는 클래스에 들어있었다.
h2_title = res.find_all("h2", {"class":"jobTitle"})
for h2_item in h2_title:
#h2에서 찾은 title은 span을 가지고 있었고 그 안에 원하는 정보가 들어있었다. 그래서 다시 하나씩 찾는다.
spans = h2_item.find_all("span")
for span in spans:
#span태그 안에 title이 있었고 그 title에 정보가 담겨있었다. get메서드를 이용하여 span의 title을 가져온다.
title = span.get("title")
#title에 정보를 적어놓지 않은 건지 무슨 이유인지는 모르겠지만 None이 출력되는 공고도 있었다. None이 아닌 것만 리스트에 저장한다.
if title is not None:
title_list.append(title)
#회사명도 title과 마찬가지 방법으로 찾아 들어가서 리스트에 저장한다.
companys = res.find_all("span",{"class":"companyName"})
for comp in companys:
company = comp.string
comp_list.append(company)
#title리스트와 company리스트에 담긴 요소의 개수가 다르다.(title에서 None이 존재하는 것 때문에 그런듯) 둘 중 작은 크기의 리스트를 돌면서 정보를 출력한다.
for t in range(min(len(title_list),len(comp_list))):
print(title_list[t], ':', comp_list[t],end='\n')결과

깔끔하지는 않다...좀 더 공부해 보고 좀 더 아름다운 수프로 만들어야겠다.
