paper
- https://arxiv.org/pdf/2112.09133v2.pdf
- 2021, 681회 인용
- https://openaccess.thecvf.com/content/CVPR2022/supplemental/Wei_Masked_Feature_Prediction_CVPR_2022_supplemental.pdf
- https://github.com/facebookresearch/SlowFast/tree/main/projects/maskfeat

0. abstract
- 개요
- 왼쪽 그림 Input -> 모델 -> 중앙 그림을 출력
- 오른쪽 GT의 HOG GT와 비교하여 학습.
- self-supervised pre-training 흐름
- 언어 데이터만으로 학습 가능함
- 이미지-언어 pair로 학습 가능함
- 이미지 데이터만으로도 self-supervised 학습이 가능하면 좋을텐데..!
Masked Feature Prediction (MaskFeat)- for self-supervised pre-training of video models
- 학습 단계
randomly masks out a portion of the input sequence
predicts the feature of the masked regions.
- 그렇다면, 패치의 어떤 feature을 맞추는 self-supervised pre-training task가 좋을까?
- 실험 결과,
Histograms of Oriented Gradients (HOG)( a hand-crafted feature descriptor)을 찾는 task가 제일 성능/효과 면에서 좋더라.
- 실험 결과,
- HOG 중에서도
local contrast normalization을 하는 것이, 학습 성능에 핵심이더라! - 이렇게 pre-train하니,
- 풍부한 visual knowledge 도 배울 수 있고,
- large-scale Transformer-based models에 적용할수도 있더라!
MViT-L모델에서, Kinetics-400의 label을 제외한 비디오 데이터만으로 사전 학습을 진행했더니, 아래와 같은 매우 좋은 성능이 나왔다!- 86.7% on Kinetics-400,
- 88.3% on Kinetics- 600,
- 80.4% on Kinetics-700,
- 또한 video input 뿐만 아니라, MaskFeat further generalizes to image input!
1. introduction
1.1. Language 처럼, 이미지 patch를 토큰화할까?
- 이 연구는 언어처럼 명확하게 정의된 어휘가 없는 비전 데이터에 대해, 효과적인 자기지도 학습 방식을 개발하려는 시도의 일부
- 텍스트의 단어들은 미리 정의된 어휘(vocabulary)에 의해 명확한 카테고리(예: 단어 또는 토큰 ID)로 분류되어 있기 때문에,
- 이 문제를 분류 문제로 정의할 수 있음
- 그러나 비전 분야에서는 원시 시각 신호가 연속적이고 조밀한 특성을 가지기 때문에, 이러한 방식으로 적용하기 어렵습니다.
- 이미지나 비디오 프레임은 픽셀 단위로 연속적인 값들로 이루어져 있고, 이것들은 자연스럽게 분류할 수 있는 명확한 어휘가 없습니다.
- 이는 컴퓨터 비전 시스템이 마스킹된 부분의 픽셀 값을 예측하는 데 있어서 훨씬 더 복잡한 문제를 안게 만듭니다.
- 기존 연구인, BEiT(Bidirectional Encoder Representations from Transformers)는 이 문제에 대한 한 가지 해결책을 제안
- 그들의 접근 방식은 이미지를 작은 패치로 나누고, 각 패치를 토큰화하는 '시각 어휘'를 만드는 것
- 이것은 NLP에서 단어나 문장을 토큰화하는 것과 유사한 방식으로, 연속적인 이미지 데이터를 이산적인 단위로 변환하여 처리
- 그러나 이 방법은 별도의 토크나이저를 필요로 하는데, 이는 비디오 데이터와 같이 많은 계산 자원을 필요로 하는 경우에 제한적일 수 있음
- tokenizer: 이미지의 분할인 패치를 작은 토큰 백터로 분할하는 프로세스
- 비디오와 같이 데이터 양이 방대한 경우에는 많은 계산 자원을 필요로 하기 때문에 효율적이지 못할 수 있음
- 논문은 Masked Feature Prediction(MaskFeat) 라는 새로운 대안을 제시
- 이 방식은 패치를 별도의 토큰으로 변환하는 대신에,
- 마스크된 패치가 원래 가지고 있었던 특징(예를 들어, 특정 유형의 텍스처 또는 색상 분포)을 직접적으로 예측하는 것
- 이를 통해 모델은 마스크된 시각적 내용에 대한 더 정확한 예측을 학습할 수 있으며, 특히 동영상과 같이 시공간적 구조가 풍부한 데이터에 유용
1.2. 이미지 patch를 어떤 feature로 변환하여, 이를 맞추는 학습을 진행하면 좋을까? -> HOG가 답.
- 그렇다면, 패치의 어떤 특징들을 맞추는 self-supervised task가 좋을까? 아래 후보군들을 전부 테스트해 보았습니다.
- 픽셀의 색상
- 직접 만든 feature descriptor
- 시각적 토큰들
- 딥 네트워크의 활성화 상태
- 네트워크 예측을 통해 생성된 가상의 라벨들
- 결론 1
- 예전에 시각 인식을 지배했던 HOG나 SIFT descriptor에서 볼 수 있었던 간단한 방향성 그래디언트의 히스토그램이
- MaskFeat에 있어서 성능과 효율성 면에서 매우 효과적이라는 걸 발견
- 예전에 시각 인식을 지배했던 HOG나 SIFT descriptor에서 볼 수 있었던 간단한 방향성 그래디언트의 히스토그램이
- 결론 2
- 시각 신호를 따로 토큰화하지 않아도, 마스킹된 시각 예측을 할 수 있으며, 실제로 연속적인 특징을 회귀하는 방식으로 잘 작동한다는 것을 발견
- 결론 3
- 마지막으로, 사람이 만든 주석으로부터 얻은 의미 있는 정보가 MaskFeat 작업에 반드시 도움이 되는 건 아니며, 오히려 지역 패턴의 특성을 잡아내는 게 중요하다는 점을 발견
- downstream-task에 대한, generalization 성능 확보를 위함
- 예를 들어, 라벨이 붙은 데이터로 훈련된 CNN이나 ViT로부터 예측하는 지도 학습 특징들을 사용했을 때, 성능이 오히려 떨어지는 결과를 보였죠.
- 논문의 방식은 매우 단순하면서 실용적
- MaskFeat는 단 하나의 네트워크와 각 샘플의 단일 관점만을 사용
- 그리고 굉장히 적은 양의 데이터 증강만으로도 효과적으로 작동
- 이전의 마스킹 방법들과 비교할 때, HOG를 이용한 MaskFeat는 별도의 외부 모델을 사용하지 않음
- MaskFeat가 대규모 비디오 모델 사전 훈련에 사용될 때 잘 일반화되며, 특히 비디오 이해에 많은 이점을 제공한다는 것을 확인
- 예를 들어, 어떠한 외부 데이터도 사용하지 않고 MaskFeat로 사전 훈련된 MViT-L 모델은 Kinetics-400에서 86.7%의 top-1 정확도를 달성
- 이는, 대규모 이미지 데이터셋을 사용하는 방법들보다도 높습니다.
2. Method
2.1. Masked Feature Prediction
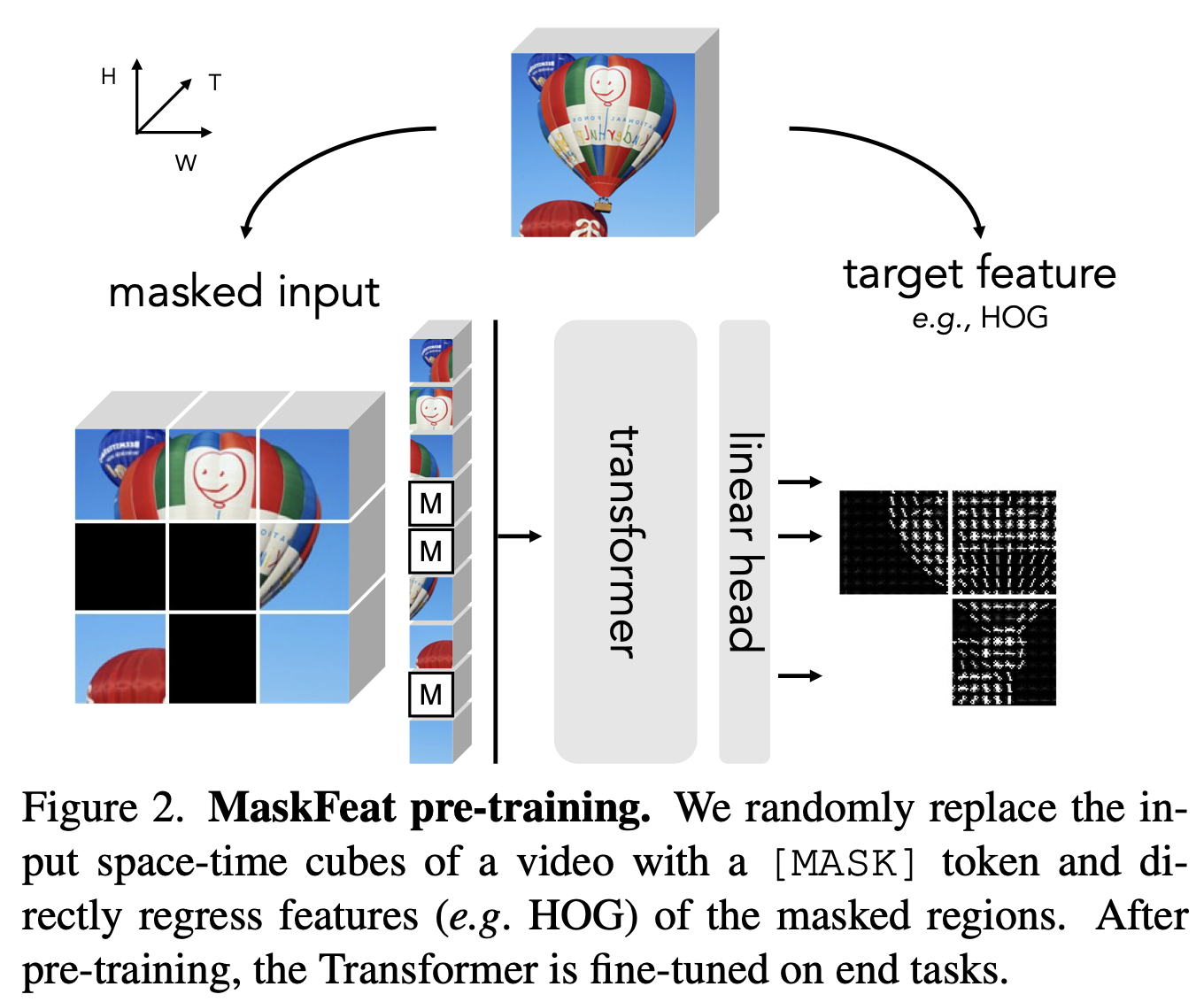
- Masked Feature Prediction은 먼저 비디오의 몇몇
공간-시간 큐브를 무작위로 마스킹한 다음, 남은 큐브를 바탕으로 마스크된 큐브를 예측 - 마스크된 샘플을 모델링함으로써, 모델은 객체의 부분과 움직임을 인식함으로써 비디오 이해를 얻게 됩니다.
- Instantiation
- 마스킹을 수행하기 위해, 시퀀스의 일부 토큰은 [MASK] 토큰으로 대체되어 무작위로 마스크
- 이는 마스크된 패치를 나타내는 학습 가능한 임베딩
- 예측을 하기 위해, [MASK] 토큰 교체 후의 토큰 시퀀스는 위치 임베딩이 추가되어 트랜스포머에 의해 처리
- 마스크된 큐브에 해당하는 출력 토큰은 선형 레이어에 의해 예측으로 투영
- 예측 output은 단순히 각 마스크된 큐브에서
시간적으로 중앙에 위치한 2-D 공간 패치의 특징(4.3절의 논의 참조). - 출력 채널의 수는 특정 대상 특징(예: 16×16 패치에서 RGB 색상을 예측하는 경우 3×16×16)에 맞게 조정됩니다.
- 손실은 마스크된 큐브에서만 계산
- 이 방법은 이미지에도 적용될 수 있으며, 이 경우에는 비디오의 한 프레임만 사용하게 됩니다.
- 이 때, 각 토큰은 3D 큐브가 아니라 2D 공간 패치만을 대표합니다.
2.2. Target Features
- 우리는 다섯 가지 다른 유형의 Target Features을 고려합니다.
- 대상들은 두 그룹으로 분류됩니다: (그룹 1이 훨씬 성능이 좋습니다.)
- 1) 픽셀 색상과 HOG와 같이 직접 얻을 수 있는 단일 단계 대상들,
- 2) 훈련된 딥 네트워크나 교사에 의해 추출되는 다른 이중 단계 대상들
2.2.1. 픽셀 색상.
- 구체적으로, 우리는 데이터셋의 평균과 표준편차로 정규화된 RGB 값을 사용
모델의 예측과 실제 RGB 값 사이의 L2 거리를 최소화- 대상으로 픽셀을 사용하는 것은
모델이 조명이나 대비 변화와 같은 중요하지 않은 요소에 지나치게 민감하게 반응하거나, 특정 세부 사항(가장자리나 미세한 텍스처 등을 의미)에 과적합될 수 있는 잠재적 단점- 전체적인 시각적 내용을 제대로 이해하지 못하게 만들 수 있음

2.2.2. HOG
- HOG는
- 작은 변화나 광도 변화에도 강인한 특성
- 계산 비용 효율적
- 부분적 불변성:
- HOG 특징은
공간 셀 내에서 일어나는 변환(위치의 약간의 이동)과 작은 회전에 대해 일정 부분 변하지 않음- 즉, 사물이 이미지 내에서 약간 움직이거나 회전해도, HOG로 포착한 그 형태와 외관은 크게 변하지 않음
- 내가 생각한 이유
- RGB 맞추기를 하면, 내가 비디오 상에서 움직이면, 내 주변 배경의 색깔이 막 바뀔 것. 그러므로, 색깔 맞추기 특성상 성능이 robust하지 못한데,
- HOG 맞추기를 하면, 내가 비디오 상에서 움직여도, 주변 배경의 색깔에 강인하다.
- 광도 변화에 대한 불변성:
- 이미지 그래디언트(밝기 변화율)와 로컬 대비 정규화(지역적 밝기 차이를 조정)를 통해, HOG는 조명 변화나 전경과 배경 간의 대비 변화 같은 광도 변화에도 일정 부분 영향을 받지 않음
- 즉, 조명이 달라져도 이미지의 기본적인 형태와 외관 정보를 잘 유지할 수 있음
- 이미지에서 마스크된 부분을 처리하고 분석하는 방식
- 전체 이미지에서 HOG 특징 추출:
- 먼저, 전체 이미지에 대해 방향성 그래디언트의 히스토그램(HOG)을 계산하여 이미지의 특징 맵을 얻음
- 이 특징 맵은 이미지의 형태와 구조, 특히 에지(경계)와 방향성을 기술
- 히스토그램 맵 분할:
- 계산된 HOG 특징 맵을 이미지의 여러 패치로 나눕니다.
- 이렇게 하면 각 마스크된 부분(패치)에 대한 HOG 정보를 구체적으로 얻을 수 있습니다.
- 장점: 경계 패딩 감소:
- 전체 이미지에서 특징을 먼저 추출한 후에 패치로 나누는 접근 방식은, 각 마스크된 패치의 경계 부분에서 필요한 패딩을 줄여줍니다.
- 패딩은 이미지의 정보가 부족한 부분을 채우는 것인데, 이 방법은 패딩이 덜 필요하게 만들어 줍니다.
- 히스토그램 평탄화 및 연결:
- 각 마스크된 패치에 대한 HOG 히스토그램을 평탄화하여 1차원 벡터로 만들고, 이를 연결하여 마스크된 부분의 전체적인 특징을 표현
- 손실 최소화:
- 이 방법의 핵심은 예측된 HOG 특징과 원본 이미지에서 계산된 HOG 특징 사이의 차이(L2 거리)를 최소화하는 것
- 색상 정보 포함:
- 성능을 향상시키기 위해, 각 RGB 채널에서 별도로 HOG를 계산하고 이를 포함시킵니다.
- 이는 색상 정보까지 고려하여 더 정확한 예측을 가능하게 합니다.
- 이거 어떻게 하는거지? 부록 참조
4. Experiments: Video Recognition
- 설정.
- MViT 비디오 처리 모델은 두 가지 버전이 있으며,
개선된 버전의 베이스 모델과대형 모델을 평가한 과정을 논문에서 소개했다! - MViT: Multiscale Vision Transformers
- https://openaccess.thecvf.com/content/ICCV2021/papers/Fan_Multiscale_Vision_Transformers_ICCV_2021_paper.pdf
- 원래 MViT 모델은 MViTv1로 알려져 있습니다.
- MViT 비디오 처리 모델은 두 가지 버전이 있으며,
- 이 모델들은 K400 비디오 클립 데이터셋을 사용하여 '사전 훈련'
- 중요한 점은, 이 학습 과정에서 비디오 클립의 라벨(즉, 분류나 설명 같은 태그)을 사용하지 않음
- 데이터를 모델에 입력하기 전에 몇 가지 '증강' 처리
- 비디오 클립을 무작위 크기로 조정하고 수평으로 뒤집는 작업을 포함
- 모델은 224x224 픽셀 해상도의 이미지에서 사전 훈련되며, 본문에 특별히 다른 해상도가 명시되지 않는 한 이 해상도를 기준으로 합니다.
-사전 훈련 과정에서는 '큐브 마스킹' 기법을 사용하여 비디오의 시간과 공간을 나타내는 '큐브'라고 불리는 데이터의 40%를 무작위로 가립니다. - 이러한 과정을 거쳐 학습된 모델은 이후에 더 세밀한 'fine-tuning' 과정을 거치게 됩니다.
- 더 자세한 구현 방법과 세부 사항은 부록 B.1에 기술되어 있습니다.
4.1. Kinetics의 주요 결과
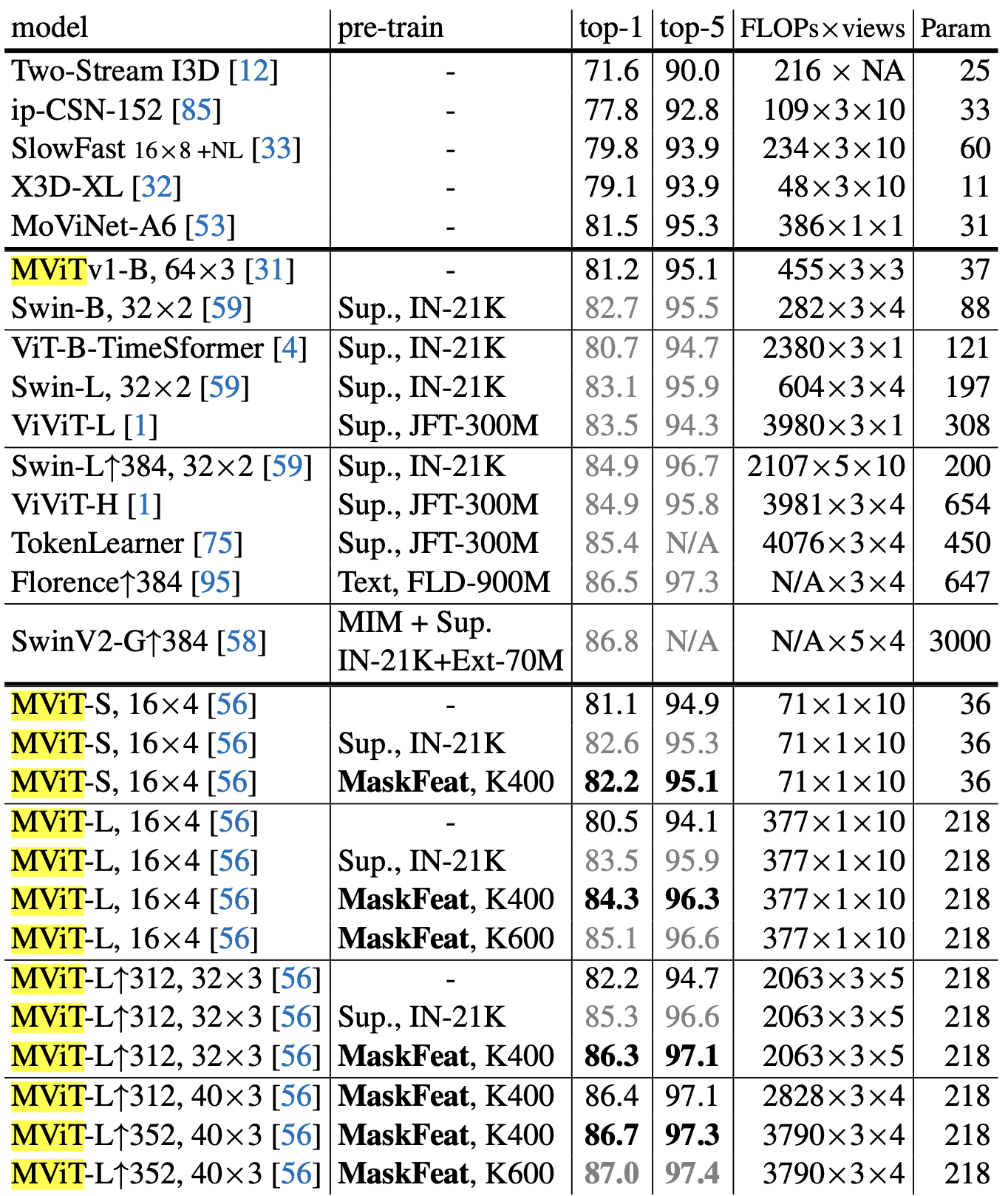
- Kinetics-400. 표 3은 K400 데이터셋에서 MaskFeat와 이전 연구를 비교합니다. 위에서 아래로 세 부분이 있습니다.
- 첫 번째 부분은 일반적으로
사전 훈련을 사용하지 않는 CNN을 사용한 이전 작업을 제시 - 두 번째 부분은
대부분 대규모 이미지 데이터셋에서의 감독된 사전 훈련에 크게 의존하는 대표적인 Transformer 기반 방법을 제시
세 번째 부분은MViT 모델에 대한 직접 비교를 제공- 이 모델에 대해, MaskFeat의 300 에포크 사전 훈련은 스크래치 MViT-S, 16×4 [56]의 81.1% 상위 1% 정확도를 +1.1% 개선
- 여기서 접미사
16×4는 훈련 중에 모델이 입력으로 사용하는 프레임 수와 시간 스트라이드
- 더 큰 데이터셋(Kinetics-600)에서 사전 훈련을 추가로 수행하면 성능이 더욱 향상
- 모델을 더 큰 이미지 해상도와 더 긴 비디오 시퀀스로 fine-tuning 하는 추가 실험을 통해, 모델의 정확도는 86.7%까지 증가합니다.
- 라벨이 없는 비디오만을 사용함에도 불구하고 기존의 최고 성능을 뛰어넘는 결과를 달성합니다.
- Kinetics-600 및 Kinetics-700 데이터셋에서의 평가: 두 개의 더 큰 데이터셋에서도 MViT 모델은 우수한 성능을 보여주며, 이전 방법들보다 훨씬 적은 계산 비용으로 높은 정확도를 달성
4.3. 비디오 인식을 위한 Ablation 연구
- Ablation 연구는 특별히 명시되지 않는 한, K400에서 300 에포크 동안 pretrain된 MViT-S, 16×4와 함께 수행됩니다.
- 우리는 K400에서 200 에포크 fine tuning 정확도(%)를 보고합니다.
4.3.1. 마스킹 전략.
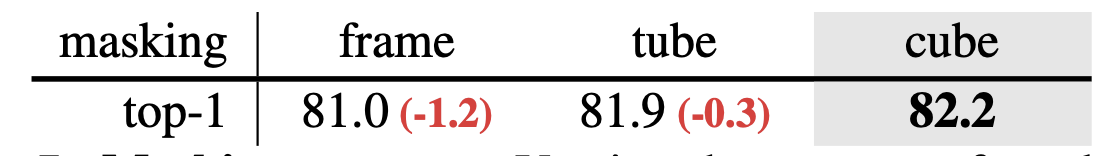
- 우리는 마스킹의 세 가지 다른 방법을 고려하고 표 7에 결과를 제시합니다. 모든 항목은 동일한 40% 마스킹 비율을 공유합니다.
- 첫째, "프레임" 마스킹
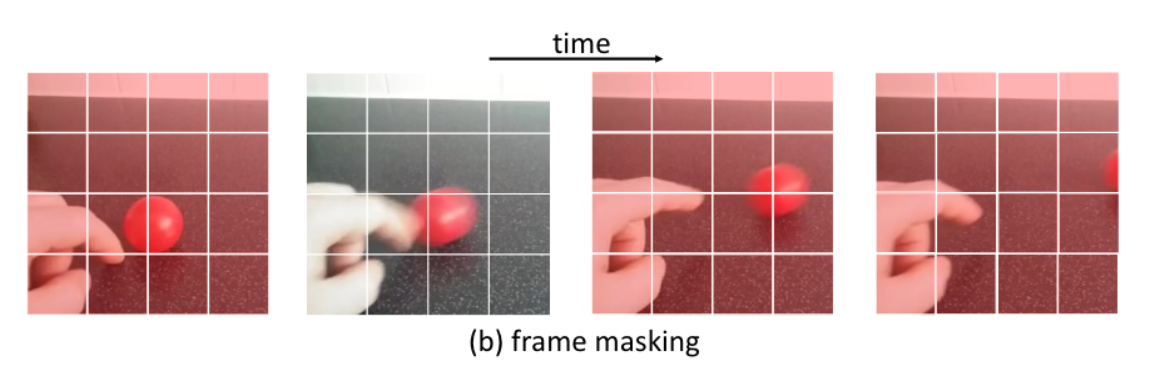
- 우리는 연속적인 프레임을 독립적으로 마스킹
- 이 전략은 주로 연속 프레임에서 다른 공간 블록을 마스킹하지만, 모델은 프레임 사이를 시간적으로 "내삽"하여 태스크를 해결할 수 있습니다.
- 이 전략은 81.0%의 정확도
- 둘째, "튜브" 마스킹
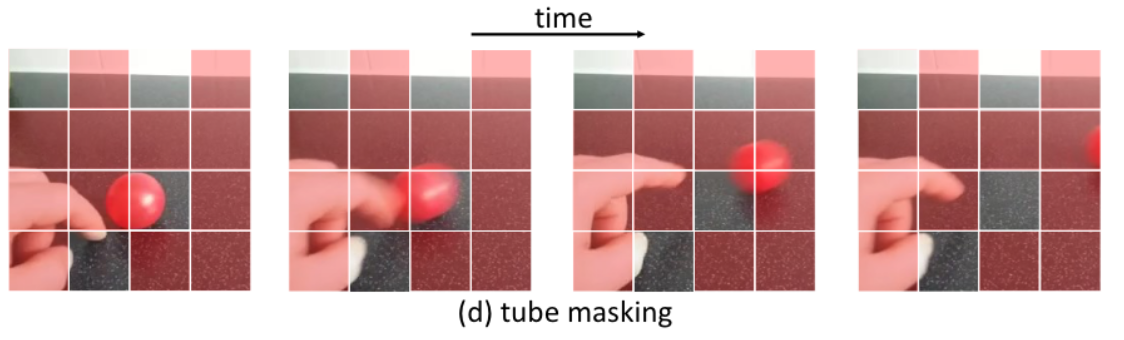
- 튜브 마스킹은 2차원의 마스크를 생성한 후, 이 마스크를 시간 축을 따라 일정하게 반복하여 확장
- 이 방법으로 마스크된 영역은 비디오의 모든 프레임에서 동일한 위치에 나타남
- 즉, 비디오 전체에서 공간적으로 마스크된 영역이 동일하게 유지
- 이 방식은 비디오 내에서 시간에 따른 변화를 예측하는 데 도움이 될 수 있지만,
- 모든 프레임에서 동일한 영역만을 가린다는 특성 때문에, 시간적 변화에 대한 예측에는 제한적
- 이는 81.9%의 정확도로 이어집니다.
- 셋째, 큐브 마스킹 (가장 좋은 성능!)
- 큐브 마스킹은 비디오 내의 작은 3차원 입방체(큐브) 영역을 무작위로 선택하여 마스킹
- 이는 공간적으로도, 시간적으로도 블록을 가립니다. 즉, 비디오의 일부 프레임에서만 특정 공간 영역이 가려지게 됩니다.
- 이 방법은 모델이 공간적인 정보와 시간적인 정보 모두를 예측해야 하므로, 튜브 마스킹에 비해 더 복잡한 패턴과 변화를 학습할 수 있습니다.
4.3.2. target design
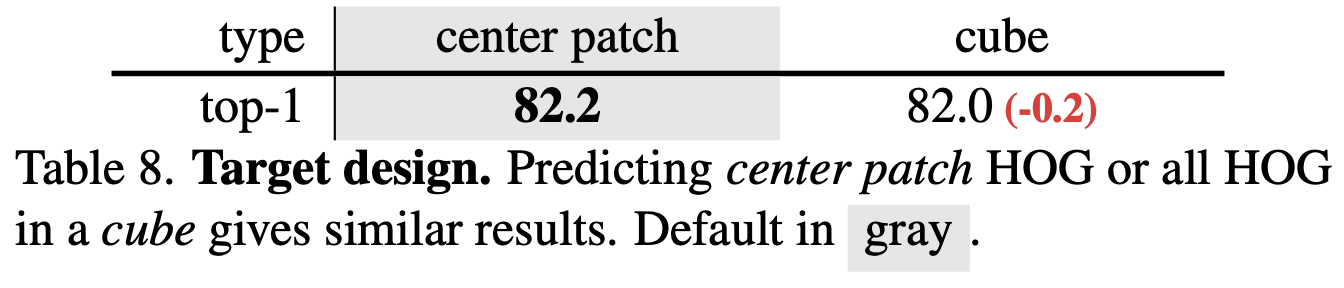
- 예측은 단순히 각 마스크된 큐브에서 시간적으로 중앙에 위치한 2-D 공간 패치의 특징을 예측하는 것이 더 성능이 좋더라.
4.3.3. 마스킹 비율.
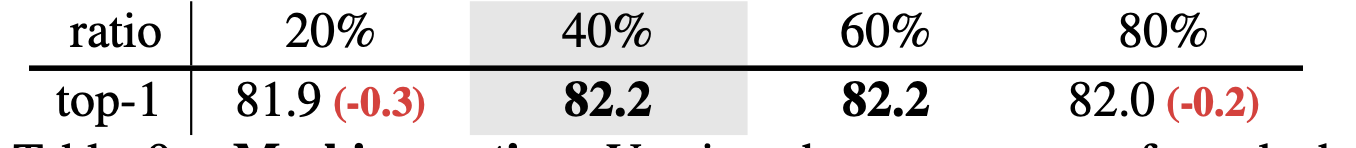
- 40%에서 극단적인 80%까지의 넓은 범위의 마스킹 비율이 유사한 Fine-tuning 정확도를 생성할 수 있으며, 오직 작은 비율인 20%만이 약간의 하락인 -0.3%를 이끕니다.
- 이것은 이미지에서 관찰된 것과 다르며, 여기서는 40%를 초과하는 비율이 정확도 저하로 이어진다는 것을 시사합니다(부록 A의 논의 참조).
- 이는 비디오 도메인에서 시각적 패턴이 이미지보다 더 중복되어 있음을 나타내며, 따라서 MaskFeat는 적절히 어려운 태스크를 생성하기 위해 더 큰 마스킹 비율을 활용할 수 있습니다.
4.3.4. pre-train 일정.
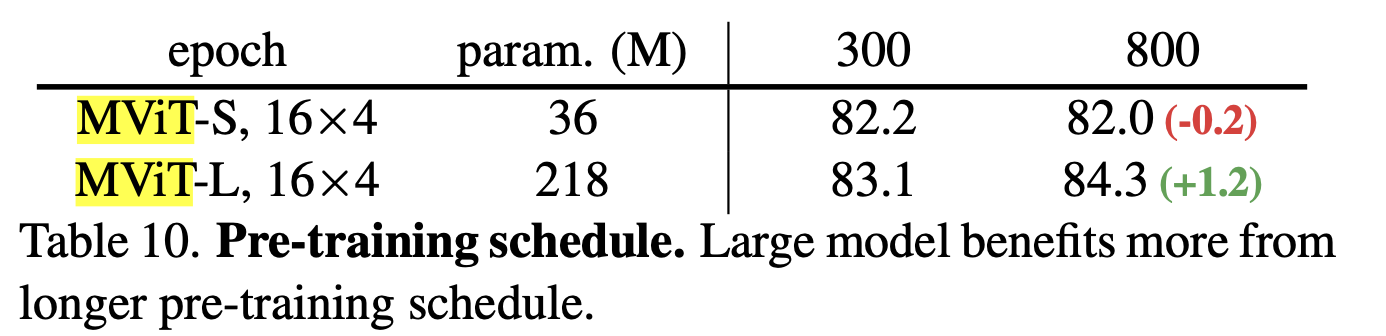
- 우리는 K400에서 다른 사전 훈련 일정 길이를 표 10에 보여줍니다. 각 결과는 중간 체크포인트가 아닌 완전히 훈련된 모델에서 미세 조정됩니다.
- 36M 파라미터를 가진 MViT-S의 경우, 300 에포크에서 800 에포크로 사전 훈련을 확장하면 0.2%의 정확도가 소폭 저하
- 반면에, MViT-L의 경우 더 긴 사전 훈련은 +1.2%의 중요한 정확도 향상을 제공합
- 이는 MaskFeat가 더 큰 용량과 더 긴 일정을 가진 모델에서 더 잘 활용될 수 있는 확장 가능한 사전 훈련 태스크임을 시사
github
- https://github.com/facebookresearch/SlowFast
- 여기에 있는듯. 그중에서도, 아래 링크를 보면 된다!
- https://github.com/facebookresearch/SlowFast/blob/main/projects/maskfeat/README.md
- MViT-L에 대한 pre-trained weight도 공개되어있고, Kinetics-400 task를 풀기 위한 fine-tuned weight도 공개되어 있다!
- 아래 첫 번째 명령어는 MaskFeat MViT-L 모델을 Kinetics-400 데이터셋에서 훈련시키는 방법을 보여줍니다. [self-supervised learning]
- 이 과정에서, configs/masked_ssl/k400_MVITv2_L_16x4_MaskFeat_PT.yaml 설정 파일을 사용하여 모델 훈련의 구성을 지정
- DATA.PATH_TO_DATA_DIR 옵션은 Kinetics 데이터셋이 위치한 경로를 지정하는 데 사용됩니다.
python tools/run_net.py \
--cfg configs/masked_ssl/k400_MVITv2_L_16x4_MaskFeat_PT.yaml \
DATA.PATH_TO_DATA_DIR path_to_your_Kinetics_dataset- 두 번째 명령어는 앞서 훈련된 모델을 fine-tuning하는 방법을 설명
- 여기서는 configs/masked_ssl/k400_MVITv2_L_16x4_FT.yaml 설정 파일과 함께, 사전 훈련된 모델의 체크포인트 파일 경로(TRAIN.CHECKPOINT_FILE_PATH)를 제공해야 함
- 미세 조정은 모델이 더 특화된 작업에 대해 더 나은 성능을 내도록 추가적인 훈련을 제공하는 과정
- 이 단계에서 모델은 특정 작업에 더 잘 맞게 조정되어, 성능을 개선할 수 있음
python tools/run_net.py \
--cfg configs/masked_ssl/k400_MVITv2_L_16x4_FT.yaml \
DATA.PATH_TO_DATA_DIR path_to_your_Kinetics_dataset \
TRAIN.CHECKPOINT_FILE_PATH path_to_your_pretrain_checkpoint
- TODO: 잘 따져보면, 내 custom dataset으로 fine-tuning 하는 방법을 찾을 수도 있을 것 같다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것