Input


Video
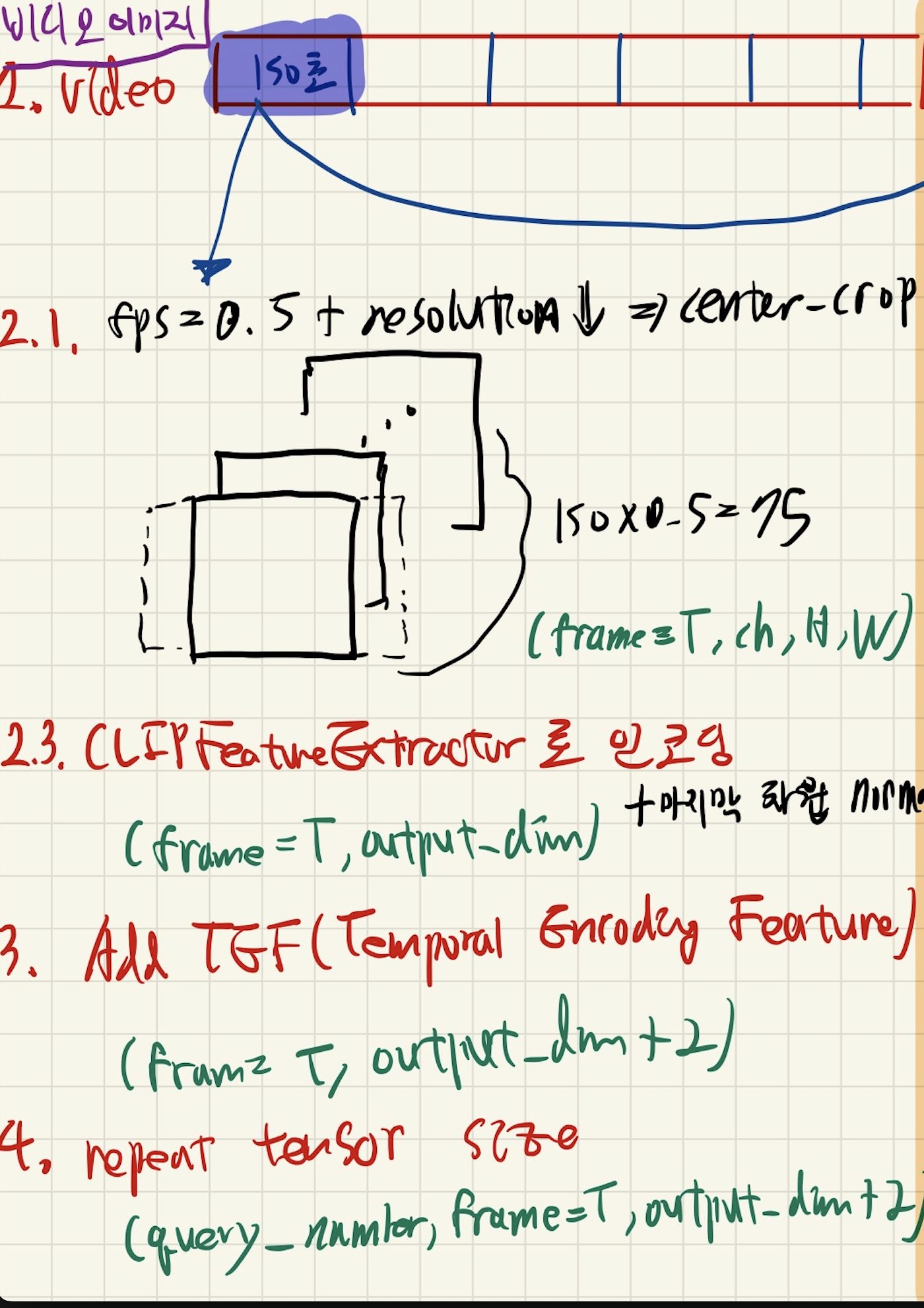
1. Split original video file to 2:30 segments
- input: mp4나 MOV 같은 비디오 파일
- output: mp4 150초짜리 비디오 파일 여러개
2. encode_video
ClipFeatureExtractor.encode_video- input: mp4 150초짜리 비디오 파일
- output: (frame=T, output_dim)
1) Make tensor from Video file
ClipFeatureExtractor.VideoLoader.read_video_from_file- 비디오 데이터를 다음과 같은 과정으로 불러옴.
- input: mp4 150초짜리 비디오 파일
- output: video_frames (frame=T, channel, height, width)
- 과정
- fps 지정 (default값은 0.5)
- 전체 이미지 해상도를 떨어뜨림
- height, width 중 짧은 쪽을 224(default)로, 긴쪽은 원본 가로세로 비율에 맞춰서
- (Optional) 정사각형 비율로 crop
- 짧은 쪽 길이에 맞춰, 긴 쪽을 자르는데, 중앙쪽을 남기도록 자름
- TODO
- default가 True라, 중앙을 남기도록 crop하고 학습했던 것으로 유추되는데
- 우리 도메인에서는 crop하면 골대가 잘릴수도 있으므로, goal 여부를 판단하기 어려워짐
- 이 Option을 False로 하고, 처음부터 network를 다시 학습시켜야할듯..
2) Preprocessing
- video_frames 를 normalize
3) Encode Image
- 이미지를 encoding 합니다.
ClipFeatureExtractor.clip_extractor.encode_imagemodel_name_or_path="ViT-B/32"- input: video_frames (frame=T, channel, height, width)
- for문을 돌며,
- input: (batch_size, 3 , height, width)
- video_frames (frame, channel, height, width) 을 그대로 넣는게 아니고,
- frame 수를 batch_size(default=60) 씩 잘라서 넣습니다.
- output: (batch_size, output_dim)
- input: (batch_size, 3 , height, width)
- output: (frame=T, output_dim)
3. Add tef(Temporal Encoding Features)
- positional encoding 개념 주입
- input: (frame=T, output_dim)
- output: (frame=T, output_dim+2)
The positional embedding of this pretrained QDDETR only support video up to 150 secs (i.e., 75 2-sec clips) in length"- 이 이유로, 영상을 150초 간격으로 짤라서, 하나씩 처리해야합니다.
4. repeat tensor size
- input: (frame=T, output_dim+2)
- output: (query_number, frame=T, output_dim+2)
Audio

1. 150초짜리 mp4 -> wav 만든 후 저장
ffmpeg.input(segment_video_path).output(segment_audio_path,
format='wav').run())2. wav를 numpy로 매모리에 올리기: (raw_dim,)
- librosa 패키지 (sampling_rate: 32000, mono: True)
(audio, _) = librosa.core.load(audio_path, sr=32000, mono=True)3. AudioTagging으로 인코딩: (frame=T, output_dim)
- 2초 단위로 끊어서 추출
0~2초 사이 특징, 2_4초 사이 특징, ~~~
- 마지막차원 normalize
audio_feats = self.audio_feature_extractor.get_audio_features(
audio, feature_time=2, sr=sample_rate)
# audio_feats from numpy to torch.
audio_feats = torch.from_numpy(audio_feats).to(self.device)
audio_feats = F.normalize(audio_feats, dim=-1, eps=1e-5)4. Add TEF(Temporal Encoding Feature): (frame=T, output_dim+2)
- positional encoding 개념 주입
5.Repeat Tensor Size: (query_number, frame=T, output_dim+2)
Text

1. encode_text
ClipFeatureExtractor.encode_text- input: 여러 쿼리를 가진 리스트
- query_list: ['All Goals & Highlights', 'Pass miss scene', ...]
- outupt: query_feats: List[(L_j, d)]
- 길이는 input query_list의 길이
- (아래 #### 들은 for문을 돌면서 진행)
1) tokenizer(text_input, context_length=77, max_valid_length=32)
clip.py -> tokenizeCLIP 모델과 호환되는 형식으로 텍스트를 변환(기계가 이해하고 처리할 수 있는 형태로 변환)- 주어진 텍스트를 소문자로 변환하고, 토큰으로 분리한 뒤,
- 각 토큰을 Byte Pair Encoding 방식으로 더 작은 단위로 나누어 해당 인코딩 값으로 변환
- 각 쿼리를, context_length 길이로 토근화하는 과정이다.
- input: text_input
- 최대 길이가 bsz인 List[str],
- 예: ['All Goals & Highlights', 'Pass miss scene']
- output: encoded_text: (쿼리 수(최대 batch_size), context_length)
- 구현 (
clip.py -> tokenize)- text_input 중, 하나씩 token화 한다.
- (max_valid_length - 2 길이로 자른다.)
- 시작과 끝을 알리는 토큰을 붙인다. (결과적으로 총 길이는 max_valid_length)
- output을 일괄적으로 (context_length) shape으로 하기 위해, "max_valid_length~ context_length-1" 구간을 zero padding 해준다.
- text_input 중, 하나씩 token화 한다.
2) encode_text
ClipFeatureExtractor.clip_extractor.encode_text- self attention 등으로 encoding 하는 과정
- input: encoded_text: (쿼리 수(최대 batch_size), context_length)
- output: encoding_dict_output
"""
output:
{"last_hidden_state":
- [쿼리 수(최대 batch_size), context_length, transformer.width]
- (1, 77, 512)
"pooler_output": 이 임베딩은 이미지 임베딩과의 비교 및 정합에 사용
- [쿼리 수(최대 batch_size), transformer.width]
- (1, 512)
}
"""3) 필요없는 0 값들 다시 제거해주기
- 각 query마다 (context_length, transformer.width) 의 last_hidden_state가 구해졌는데, 여기에서 zero_padding 된 것들을 다시 없애줌
- **input: encoding_dict_output["last_hidden_state"] = (쿼리 수(최대 batch_size), context_length, transformer.width)
- output: text_features: List([L_j, d])
- 길이는 input text_list의 길이
- L_j는 각 텍스트의 길이로, 각각 다를 수 있다. (max_valid_length 이하)
2. L_j 길이 맞춰주기
pad_sequences_1d- input: text_features: List([L_j, d])
- output
- query_feats: (query_number, max(L_j), d)
- query_mask: (query_number, max(L_j)), 1 or 0
3. normalize
- input: query_feats: (query_number, max(L_j), d)
- output: query_feats: (query_number, max(L_j), d)
Output

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것