정보
- 2023, 132회 인용
- https://openaccess.thecvf.com/content/CVPR2023/papers/Shi_TriDet_Temporal_Action_Detection_With_Relative_Boundary_Modeling_CVPR_2023_paper.pdf
- https://github.com/dingfengshi/TriDet
- 163 star
Abstract
- 이 논문에서는 Temporal Action Detection를 위한, one-stage 프레임워크인 TriDet를 제시
- 기존 방법들 문제점 1:
비디오 내에서 모호한 행동 경계로 인해 경계 예측이 부정확했음 - 해결책
- 이 문제를 완화하기 위해, 우리는
경계 주변의 추정된 상대적 확률 분포를 모델링하는 새로운 Trident-head를 제안
- 이 문제를 완화하기 위해, 우리는
- 기존 방법들 문제점 2: "self-attention의 rank loss(순위 손실) 문제"가 있었음
- "self-attention의 rank loss(순위 손실) 문제"
- 자기 주의(self-attention) 메커니즘은 비디오의 다양한 부분 사이의 관계를 이해하려고 할 때 중요한 정보를 놓칠 수 있으며, 이로 인해 행동 감지의 정확도가 떨어질 수 있음
- 특히,
비디오의 다양한 시간적 단계(즉, 짧은 동작부터 길게 이어지는 동작까지)에 걸쳐 있는 정보를 적절히 결합하지 못할 때 이 문제가 발생
- "self-attention의 rank loss(순위 손실) 문제"
- 해결책
비디오의 다양한 시간적 크기를 고려하여 정보를 효과적으로 결합하고 분석하는 새로운 기술을 도입확장 가능한 세밀도 인식(Scalable-Granularity Perception, SGP) layerbased feature pyramid- 이 층은 비디오 내에서
다양한 시간적 크기의 정보를 효율적으로 처리 - self-attention 메커니즘의 한계를 극복하여 더 정확한 행동 감지를 가능하게 함
- 즉, SGP 레이어는
비디오의 짧은 순간부터 긴 시간에 걸친 행동까지 다양한 '세밀도'의 정보를 잘 결합하고 이해할 수 있도록 함 - 이를 통해 행동의 경계를 더 정확하게 식별하고, 비디오 내에서 행동을 더 잘 감지할 수 있음
- 이 층은 비디오 내에서
- THUMOS14, HACS, EPIC-KITCHEN100에서 SOTA 성능 확보 (비교적 낮은 계산량으로도)
- https://github.com/dingfengshi/TriDet
2. Introduction
- TAD에서의 큰 문제: 행동 경계가 보통 명확하지 않다는 것
- 이의 구체적인 현상은
경계 주변의 순간들(즉, 비디오 특성 시퀀스 내의 시간적 위치)이 분류기로부터 상대적으로 높은 예측 응답 값을 가진다는 것
- 이의 구체적인 현상은
2.1. 모호한 경계를 잘 예측하는 방법

- 행동의 시작과 끝 경계를 모델링하는 세 가지 다른 방법을 비교
- 여기서 '경계'란 비디오 내에서 어떤 특정 행동이 시작하고 끝나는 시점
- 세그먼트 수준(Segment-level):
- 이 접근 방식에서는 비디오의 한 구간(segment)에 대해 전역적으로 추출된 특성을 사용하여 경계를 찾음 (21,22,29,46,51)
- 즉, 전체 구간을 보고 그 구간에 포함된 행동의 시작과 끝을 예측
- 문제점은
각 순간의 세부적인 정보를 무시할 수 있다는 것- 즉, 행동이 바뀌는 정확한 순간을 놓칠 수 있습니다.
- 순간 수준(Instant-level):
- 여기서는 비디오의 특정 순간만을 기반으로 행동의 경계를 직접 예측 (32,47)
- 다시 말해, 경계가 될 수 있는 한 지점을 선택하고 그 지점에서의 정보만으로 시작과 끝을 예측
- 그러나 이 방법은 경계 주변에서 발생할 수 있는 인접한 순간들 사이의 관계를 고려하지 않기 때문에 부정확할 수 있음
- 우리의 방법(Ours):
- 이 새로운 접근 방식에서는 'Trident-head'라는 모델을 사용하여 경계의 상대 확률 분포를 추정
- 이는 경계를 훨씬 더 세부적으로 모델링하는 방법으로, 경계를 예측하기 위해 경계점 주변의 여러 순간들의 정보를 모두 고려
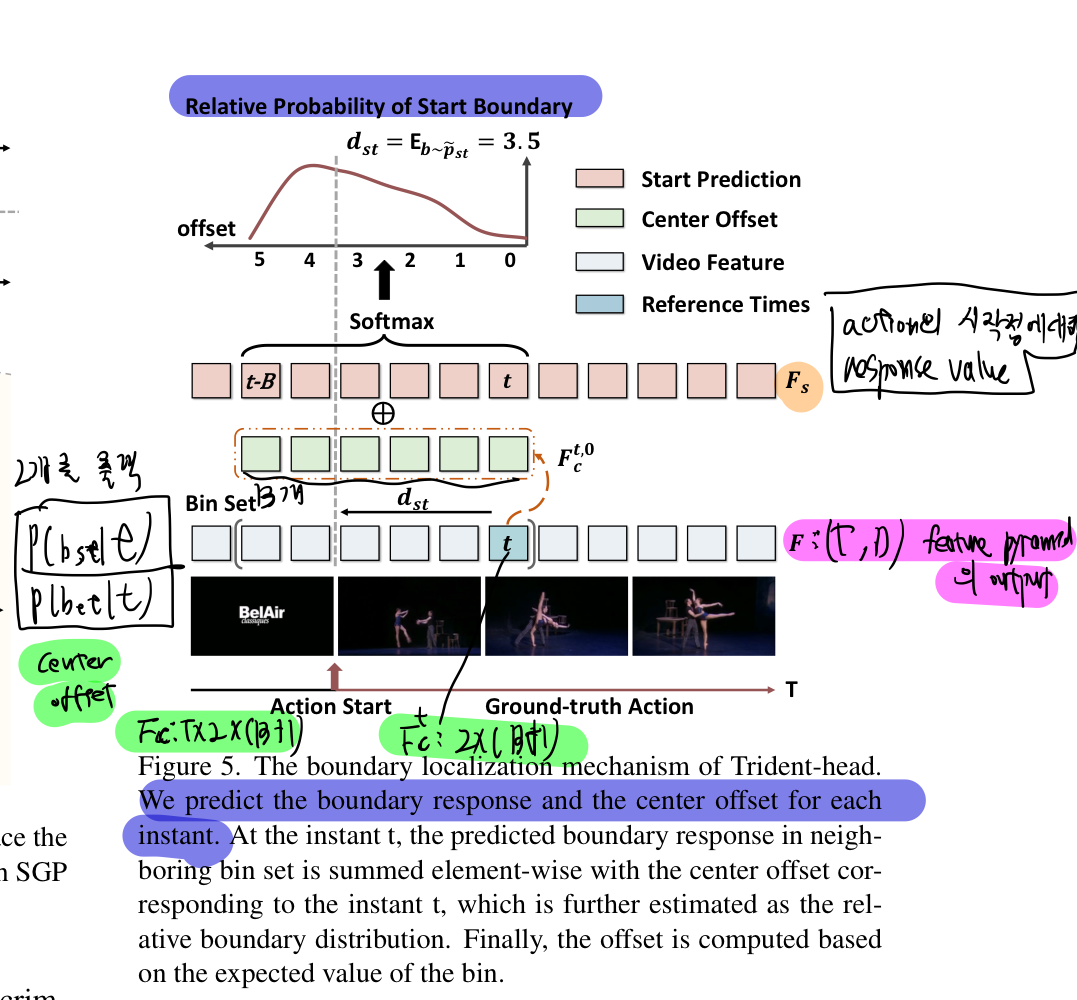
- 지역화 학습을 용이하게 하기 위해, 비디오의
시간적 특성의 상대적 응답 강도가 비디오 특성의 복잡성의 영향을 완화하고 지역화 정확도를 높일 수 있다고 가정 - 이에 동기를 얻어, 행동 경계 지역화에 맞춤화된 새로운 검출 헤드인 Trident-head를 갖춘 단일 단계 행동 감지기를 제안
- 구체적으로, 경계의 추정된 상대적 확률 분포를 통해 행동 경계를 모델링(그림 1 참조).
- 그런 다음, 경계 오프셋은 인접 위치(즉, bins)의 기대값을 기반으로 계산
- 보충 설명은 아래와 같음
- 지역화 학습 용이화 가정:
- 예를 들어, 비디오에서 누군가가 뛰기 시작하는 순간을 생각해보세요. 이 순간은 뛰기 시작하기 직전과 비교했을 때 더 많은 움직임이 있을 것입니다. 그래서 이 순간의 '반응 강도'가 더 높다고 할 수 있습니다. 이 연구는 이러한 반응 강도를 정확히 측정하면, 비디오가 복잡하더라도(많은 움직임이나 변화가 있더라도), 행동이 시작하고 끝나는 정확한 시점을 더 잘 찾아낼 수 있다고 가정합니다.
- 그래서, trident-head 중 2개의 head는, 각 Instant가 시작점일지, 끝점일지에 대한 확률을 별도로 추출함!
- 단순히 말하면, 비디오에서 어떤 중요한 순간을 더 잘 찾아내기 위해서는 그 순간의 변화를 잘 살펴보자는 것입니다. 변화가 큰 순간은 행동이 시작하거나 끝나는 중요한 시점일 가능성이 높기 때문입니다. 이 가정은 이러한 변화를 더 정확하게 찾아냄으로써 행동 감지의 정확도를 높일 수 있다고 주장합니다.
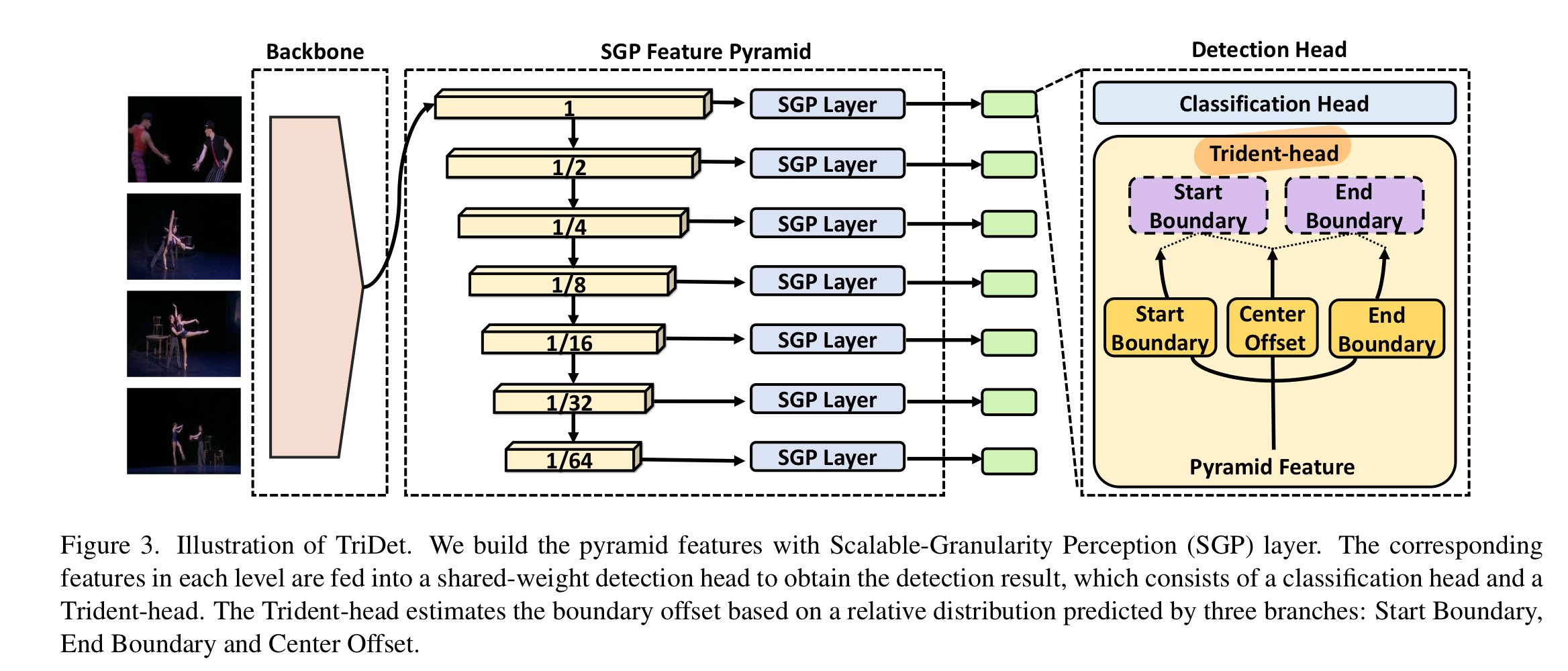
Scalable-Granularity Perception (SGP)
- Trident-head 외에도, 제안된 행동 감지기는 백본 네트워크와 feature 피라미드로 구성
- 최근 TAD 방법들(9, 40, 47)은 Transformer 기반 특성 피라미드를 채택하고 유망한 성능을 보여줌
- 그러나 비디오 백본의 비디오 feature은 스니펫 사이에 높은 유사성을 보이는 경향이 있으며, 이는 SA에 의해 더 악화되어 순위 손실 문제([12] 그림 2)를 유발
- 또한, SA는 상당한 계산 오버헤드를 발생시킴
- 다행히도, 우리는 이전의 트랜스포머 기반 레이어들(시간적 행동 감지에서)의 성공이 그들의 매크로 아키텍처, 즉 정규화 레이어와 피드포워드 네트워크(FFN)가 어떻게 연결되어 있는지에 주로 의존하며, 자기 주의 메커니즘보다는 이러한 구조에 더 크게 의존한다는 것을 발견
- 따라서 우리는 자기 주의의 앞서 언급된 두 가지 문제를 완화하기 위해 효율적인 컨볼루션 기반 레이어인 Scalable-Granularity Perception (SGP) 레이어를 제안합니다.
- SGP는 두 개의 주요 분기로 구성되어 있으며,
- 이는 각 순간의 특징을 구별하는 능력을 증가시키고
- 다양한 크기의 수용 필드를 가진 시간적 정보를 포착하는 역할
3. Method
3.1. Backbone
3.1.1. SlowFast Networks for Video Recognition

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것