Vision Language Models are Explained
- 주요 트릭은
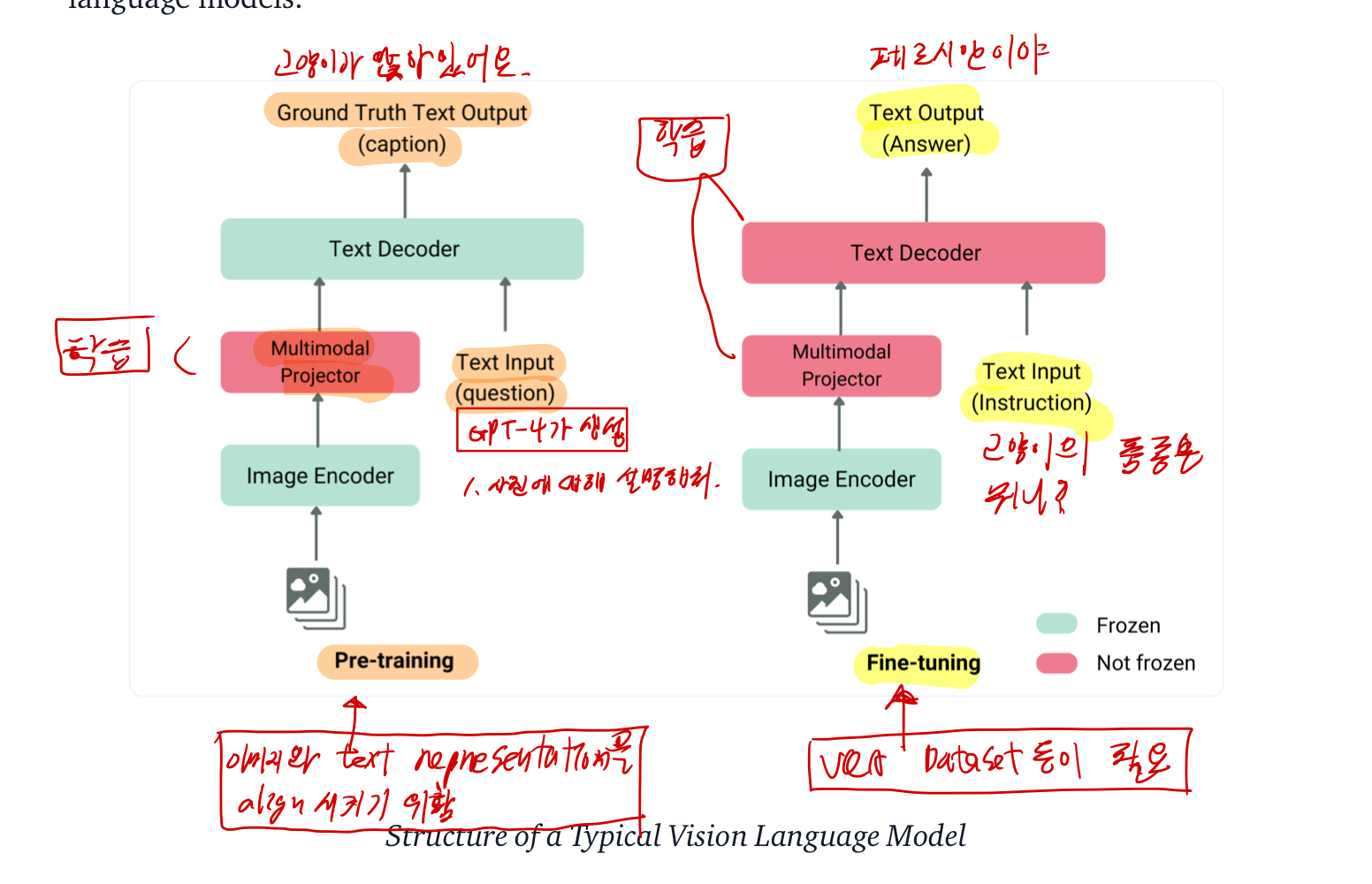
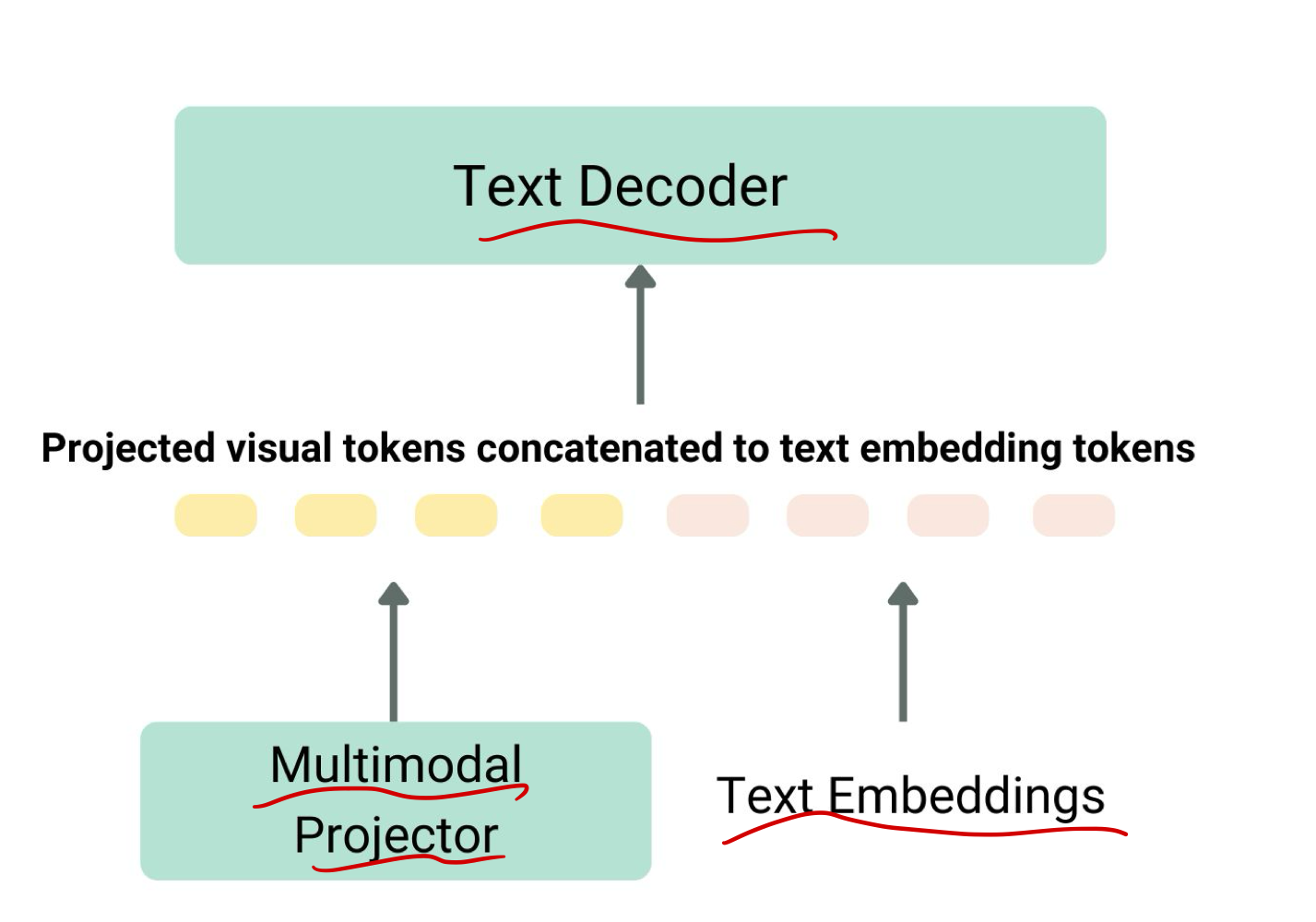
이미지와 텍스트 표현을 통합하고 이를 텍스트 디코더에 입력하여 생성하는 것 - 가장 흔하고 뛰어난 모델은 종종
- 이미지 인코더, 이미지와 텍스트 표현을 정렬하는 임베딩 프로젝터(대개 밀집 신경망),
- 텍스트 디코더로 구성되며, 이 순서대로 연결된다.
- 학습 방식에 있어서는, 다양한 모델이 서로 다른 접근 방식을 사용하고 있다.
- 대부분의 경우 비전-언어 모델을 처음부터 학습시킬 필요는 없다.
- 기존 모델 중 하나를 사용하거나,
- 자신의 용도에 맞게 미세 조정하면 된다.
왼쪽 단계
- multimodal projector만 학습시킨다.
- 왼쪽이 사전 학습 단계. 많은 데이터를 이용해서 학습시킨다. 이 단계에서의 데이터를 어떻게 모으나면
- "image-text" pair를 인터넷에서 모은 후,
- "text"만을 이용해서, GPT를 활용해 Question 을 여러개 생성한다. (GPT로 안만들어도 되는 질문임)
- 예를 들면: text가 "앉아있는 고양이" 였으면, GPT를 활용해 아래의 질문들을 이용해 만든다.
- Q: 사진에 대해 설명해줘.
- Q: 사진에 뭐가 있니?
오른쪽 단계
- multimodal projector와 text decoder도 학습시킨다.
- VQA dataset을 이용해서 학습한다.
- like llava

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것