0. 두괄식 결론
- 아래의 데이터셋이 많이 쓰이는데, 특히 Kinetics-400/600/700 데이터셋, Something-to-Something V2 (SSV2) 가 많이 사용됨
- 각 데이터셋은 fps가 조금 다르고, 클립 길이도 다름.
- 해상도는 다양하나, 연구에서는 224 by 224 로 resize하여 학습하는 경우가 대부분
| Dataset | Input Resolution | FPS | 클립 길이 | 특징 |
|---|---|---|---|---|
| Kinetics‑400/600/700 | 원본 영상은 다양하지만, 모델 학습 시 일반적으로 224×224 (또는 256×256)로 리사이즈함 | 약 25 | 약 10초 | YouTube에서 추출된 액션 인식용 클립. 400~700개 클래스의 다양한 인간 활동이 포함됨 |
| Something‑to‑Something V2 (SSV2) | 원본은 다양하나, 후처리 시 224×224 또는 256×256으로 리사이즈하는 경우가 많음 | 약 12 | 평균 약 4초 (2~6초 범위) | 일상적인 사물 조작 및 상호작용과 같이 미세한 시간적 변화를 요구하는 액션 이해에 초점 |
| Charades | 원본 영상은 약 320×240이지만, 학습/평가 시 224×224 또는 256×256 등으로 리사이즈됨 | 약 30 | 평균 약 30초 | 실내에서의 일상 활동을 담은 긴 클립. 복잡한 활동과 상호작용을 포괄함 |
| AVA (Atomic Visual Actions) | 최신 연구에서는 높은 공간 해상도를 위해 448×448로 리사이즈하여 사용하는 경우가 많음 | 약 30 | 3초 (주석 프레임 중심, 전후 1.5초씩) | 영화와 같은 장편 영상에서 1초마다 주석이 달린 프레임을 중심으로, 3초 길이의 클립을 추출하여 행동 인식을 수행함 |
| WebVid‑2M / WebVid‑10M | 원본 비디오는 다양하나, 모델 학습 시 일반적으로 224×224 (또는 256×256)로 리사이즈함 | 원본은 다양 (학습 시 균일 샘플링) | WebVid‑2M: 평균 약 18초 WebVid‑10M: 유사 | 웹 스크래핑을 통해 수집된 대규모 비디오-텍스트 데이터셋. WebVid‑2M은 약 2.5M, WebVid‑10M은 약 10M 비디오-텍스트 쌍을 포함하며, retrieval 등 멀티모달 태스크에 활용됨 |
| HowTo100M | 원본 영상은 다양하지만, 모델 학습 시 일반적으로 224×224 (또는 256×256)로 리사이즈함 | 약 25–30 | 평균 약 4초 | YouTube 등에서 수집한 내레이션 영상 기반 데이터셋. ASR 전사 캡션을 활용하여 자동 생성된 텍스트로 구성되며, 대규모 instruction 데이터셋임 |
1. Video Action Recognition 분야 개요
- 이는 비디오 클립을 보고, 그 안에서 수행되는 구체적인 동작이나 활동을 정확하게 분류하는 작업
- 예를 들어, "문 열기", "책 덮기"와 같은 동작을 비디오에서 인식하는 것이 목표
2.데이터셋
2.1. Kinetics-400/600/700 데이터셋
- https://github.com/cvdfoundation/kinetics-dataset
- https://paperswithcode.com/sota/action-classification-on-kinetics-400
- https://paperswithcode.com/sota/action-classification-on-kinetics-600
- https://paperswithcode.com/sota/action-classification-on-kinetics-700
- 650,000 video clips URL links (총 1800시간)
- Each clip: single action class + 길이:
10 seconds. - 해상도와 fps는 다양하게 제공됨
- 연구자들은 실험 과정에서 일관성을 위해 비디오를 25 FPS로 리샘플링하거나 변환하여 사용하는 경우가 많습니다.
- Each clip: single action class + 길이:
400/600/700 human action classes- 클래스 종류는 논문에서 확인 가능
- 400
- ∼240k training videos and 20k validation videos
- https://arxiv.org/pdf/1705.06950.pdf
- 176. kicking soccer ball (544)
- 298. shooting goal (soccer) (444)
- 600
- ∼370k training videos and 28.3k validation videos
- 119. passing soccer ball (400에서 추가됨)
- 700
- 축구 관련해서 추가된 것은 없음.
- 400
- 클래스 종류는 논문에서 확인 가능

2.2. Something-to-Something V2 (SSV2)
- https://paperswithcode.com/dataset/something-something-v2
- 많이 사용되는 데이터셋
- 사람이 일상적인 물체를 사용하여 수행하는 간단한 동작들을 담은 짧은 비디오 클립으로 구성
- 사람과 object간의 interaction을 잘 보여줌
- 답변이
putting "something" onto "something" 형식으로 되어 있음 - 174 classes
- SSV2는 다양한 동작을 이해하고, 비디오 내의 객체와의 상호작용을 인식하는 능력을 평가하기 위해 설계
- 해상도는 다양하게 제공됨
- 220 000 개 비디오
- 168.9K training videos and 24.7K validation videos.
- 비디오 당 2~6초 + 12 fps
- 주된 차이:
- SSV2는
물체와의 상호작용에 중점을 둔 일상 생활 속의 구체적인 동작들을 포함하는 반면, Kinetics는 더 넓은 범위의 동작과 자연스러운 상황에서의 인간 활동을 다룹니다. - 데이터의 다양성과 규모: Kinetics는 더 크고 다양한 소스에서 비디오를 수집하지만,
SSV2는 창의적이고 다양한 방식으로 특정 동작을 수행하는 비디오에 중점을 둡니다. - 상호작용의 유형:
SSV2는 사람과 물체 간의 상호작용을 강조하는 반면, Kinetics는 스포츠, 일상 생활 동작 등 더 광범위한 활동을 포함합니다.
- SSV2는
2.3. AVA
- https://github.com/cvdfoundation/ava-dataset
- 원본 영화 클립은 보통 30fps(초당 30프레임)로 제공되며, AVA의 경우 주로 30fps로 재샘플링하여 사용합니다
- AVA 데이터셋은 영화와 같은 장편 영상에서 15분 정도 길이의 구간을 추출하여, 그 구간 내에서 1초마다 한 프레임을 골라 행동(annotation)을 부여하는 방식으로 구성됩니다.
- 모델 학습이나 평가에서는 각 주석이 달린 프레임을 중심으로 좌우 1.5초씩, 총 3초 길이의 클립을 추출하여 사용합니다.
- 즉, AVA에서 “하나의 클립”은 일반적으로 3초 길이로 구성되어 있으며, 이 3초 클립 내에서 행동을 인식하는 방식으로 연구가 진행됩니다.
- 80개의 visual action class
- 430개의 movie clips (
15분 길이) - 1장에 여러개의 class도 존재.
- 특징
클래스 정의: 복합적인 행동이 아닌, 원자적 시각 행동의 정의(좀 더 디테일하게 정의했다는 뜻 같음)각 사람에 대해, 여러 class annotations(하나의 사람도, 여러 class가 배당되어 있다는 뜻 같음)연속된 시간 구간 안에서, 연결된 사람의 행동을 추출할 수 있다.(클립이 15분 길이이기 때문)
AVA Actions Dataset
- 논문: https://arxiv.org/pdf/1705.08421.pdf
- person pose
- person-object interaction

- person-person interaction
- 우리가 유용하게 쓸 class 없음.


단점
- 축구와 관련된 명시적 class가 없음.
AVA-kinetics Dataset
- AVA actions + Kinetics dataset
- AVA action labels on videos from Kinetics-700
- 기존 AVA dataset에 추가한것.
단점
- Kinetics의 class를 쓰지 않았음.
2.4. Charades
- http://vuchallenge.org/charades.html
- Charades 데이터셋의 원본 비디오들은 보통 30fps로 녹화되었으며, 기본 해상도는 약 320×240 픽셀로 구성되어 있습니다.
- 이 데이터셋의 비디오 클립은 대략 30초 정도의 길이를 가지며, 전체적으로 평균 30초 내외의 길이로 수집되었습니다.
- 9,848 videos of daily indoors (
평균 30초 길이) - 157 action classes
interactions with 46 objects classesin15 types of indoor scenesand containing avocabulary of 30 verbs- 이 클래스에, 축구 관련된 용어는 없어보임.
- Each video is annotated by
- multiple
free-text descriptions(27,847) action labels,action intervalsclasses of interacting objects
- multiple
- 41,104 labels for 46 object classes
- The classification track
- to recognize all activity categories for given videos ('Activity Classification')
- where multiple overlapping activities can occur in each video.
- 우린 여기엔 관심 없음.
- The localization track
- find the
temporal locations of all activitiesin a video ('Activity Localization'). - 이 task가 더 유용해보임.
- find the
SoccerNet
- 논문
- 아직 읽어보진 않았음
- 이 분야에서 가장 관련성 높은 작업들의 오픈 소스로 적용된 구현을 통해 재현 가능합니다!
Ball action spotting
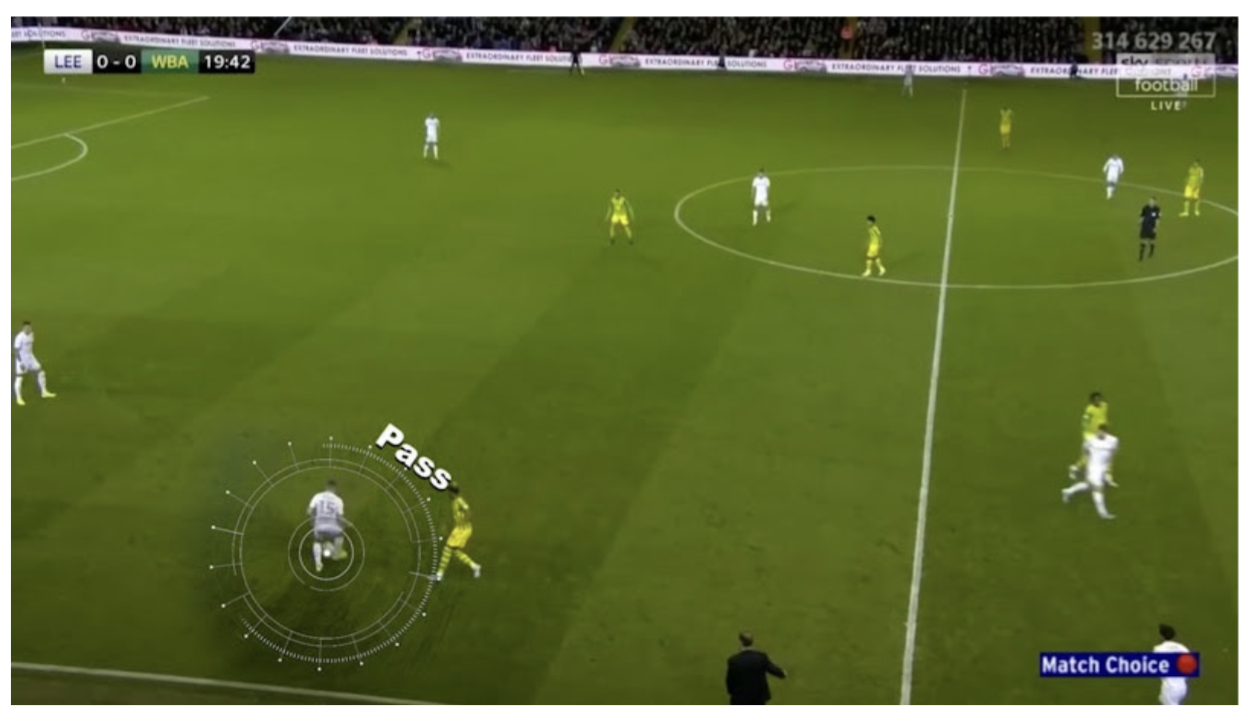
- https://www.soccer-net.org/tasks/ball-action-spotting
Pass, Drive2가지 종류 class- Each action is annotated with a single timestamp.
- 7 videos at two resolutions (720p and 224p)
- 전체 영상에서, pass/drive를 하는 순간의 timestamps들을 추출하는 Task인듯
- 축구 데이터다 보니, 풋살 데이터와는 화각이 다름.
Action Spotting
- https://www.soccer-net.org/tasks/action-spotting


- 해당 동작이 일어나기 시작하는 그 순간의 timestamp를 찍어놓았음!
- 득점은, 골 라인을 넘어가는 그 순간의 timestamp를 찍어놓음.
- 클래스 종류 매우 칭찬해 (17개)
- Penalty,
- Kick-off, (좋아!)
- Goal, (좋아!)
- Substitution,
- Offside,
- Shots on target, (좋아!)
- Shots off target,
- Clearance,
- Ball out of play, (좋아!)
- Throw-in,
- Foul,
- Indirect free-kick,
- Direct free-kick,
- Corner,
- Yellow card,
- Red card,
- Yellow->red card
- 500 videos at two resolutions (720p and 224p)
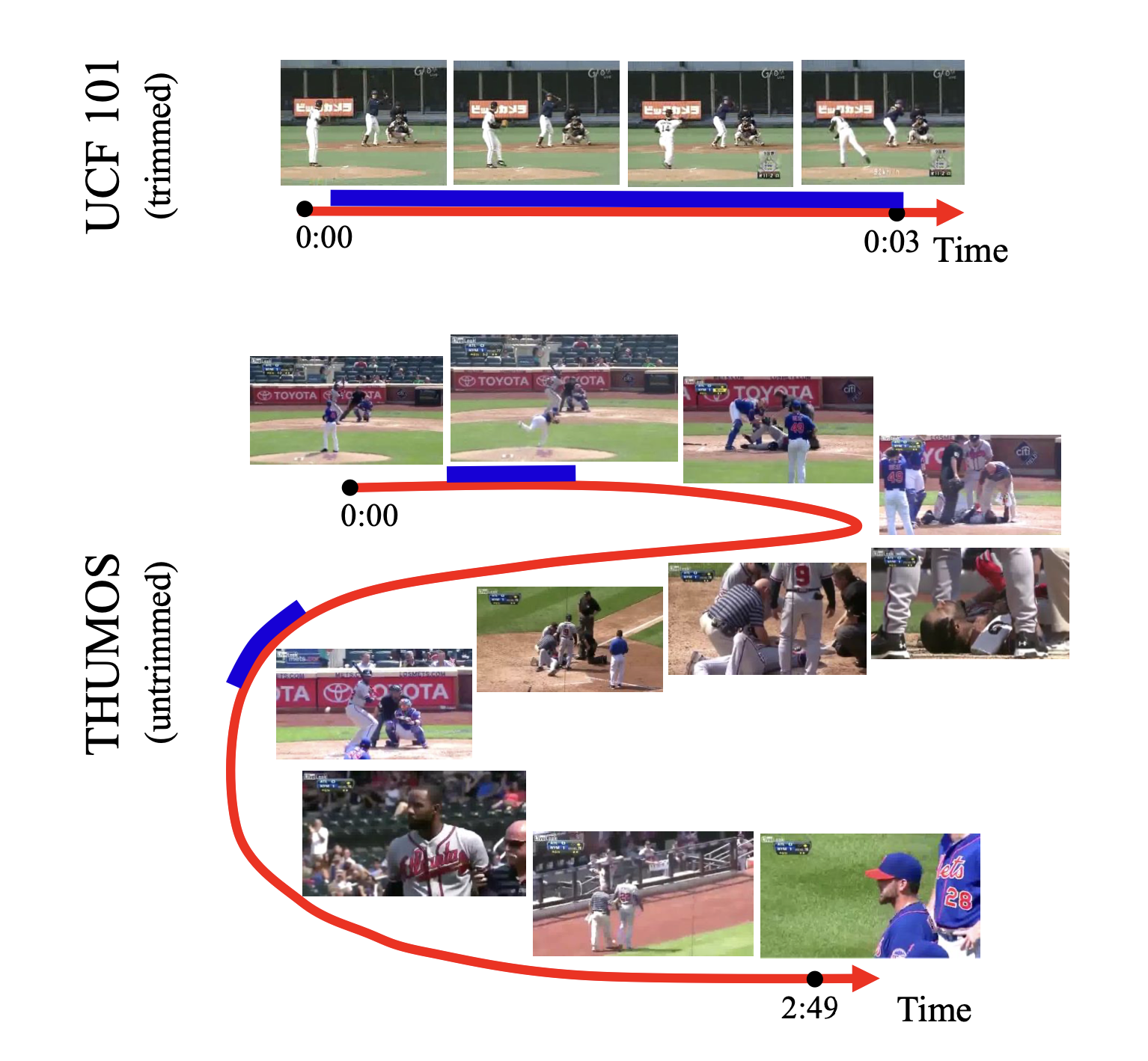
2.3. UCF101 (UCF101 Human Actions dataset) -> 도움 안됨
- https://paperswithcode.com/dataset/ucf101
- UCF101 데이터셋은 UCF50의 확장판으로, 13,320개의 비디오 클립
- 101개의 카테고리
- 카테고리는 몸동작, 인간-인간 상호작용, 인간-물체 상호작용, 악기 연주, 스포츠 등 5가지 유형으로 분류
- 총 길이는 27시간
- 모든 비디오는 YouTube에서 수집되었으며, 320×240의 해상도로 25 FPS의 고정 프레임 속도

2.4. HMDB51
- https://paperswithcode.com/dataset/hmdb51
- HMDB51 데이터셋은 영화와 웹 비디오를 포함한 다양한 출처에서 가져온 현실적인 비디오들의 대규모 컬렉
- 이 데이터셋은 51개의 액션 카테고리(예: "점프", "키스", "웃음" 등)에서 6,766개의 비디오 클립으로 구성되어 있으며, 각 카테고리는 최소 101개의 클립을 포함
- 원래 평가 방식은 세 가지 다른 훈련/테스트 분할을 사용합니다.
- 각 분할에서, 각 액션 클래스는 훈련을 위해 70개의 클립과 테스트를 위해 30개의 클립을 가집니다. 이 세 분할에 대한 평균 정확도를 사용하여 최종 성능을 측정합니다.

2.5. ActivityNet
- 축구와 관련된 것은 없는듯.
- https://paperswithcode.com/dataset/activitynet
- YouTube에서 수집한 200가지 다른 유형의 활동과 총 849시간의 비디오를
- 데이터셋의 버전 1.3은 총 19,994개의 편집되지 않은 비디오를 포함하고 있으며, 훈련, 검증, 테스트용으로 2:1:1의 비율로 세 개의 서로 겹치지 않는 부분집합으로 나뉩니다.
- 평균적으로 각 활동 카테고리는 137개의 편집되지 않은 비디오를 가지고 있습니다.
- 평균적으로 각 비디오는 시간적 경계와 함께 주석이 달린 1.41개의 활동을 가지고 있습니다.
- 테스트 비디오의 실제 주석은 공개되지 않습니다.
- https://github.com/antran89/ActivityNet/blob/master/Crawler/classes.txt
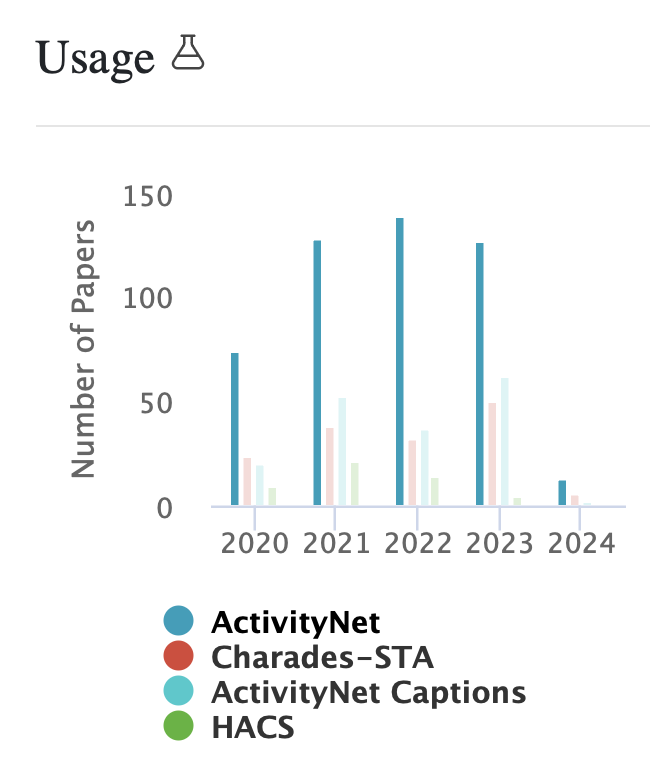
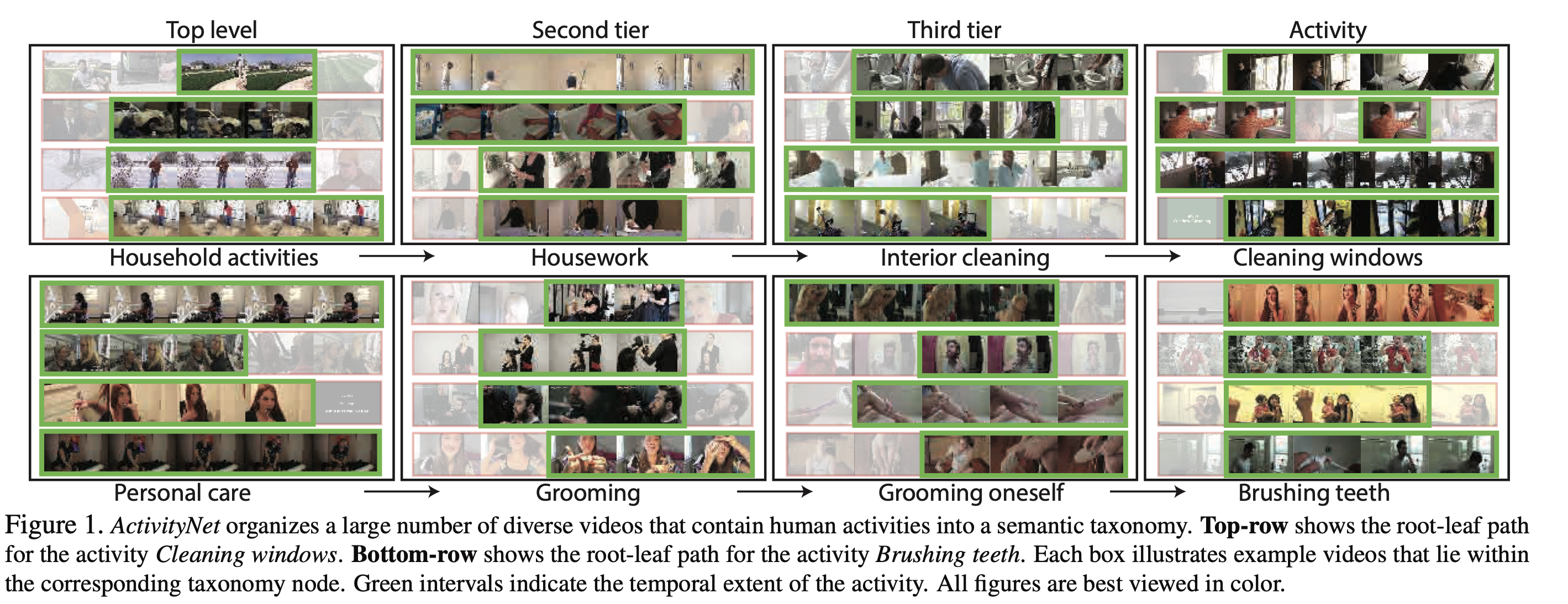
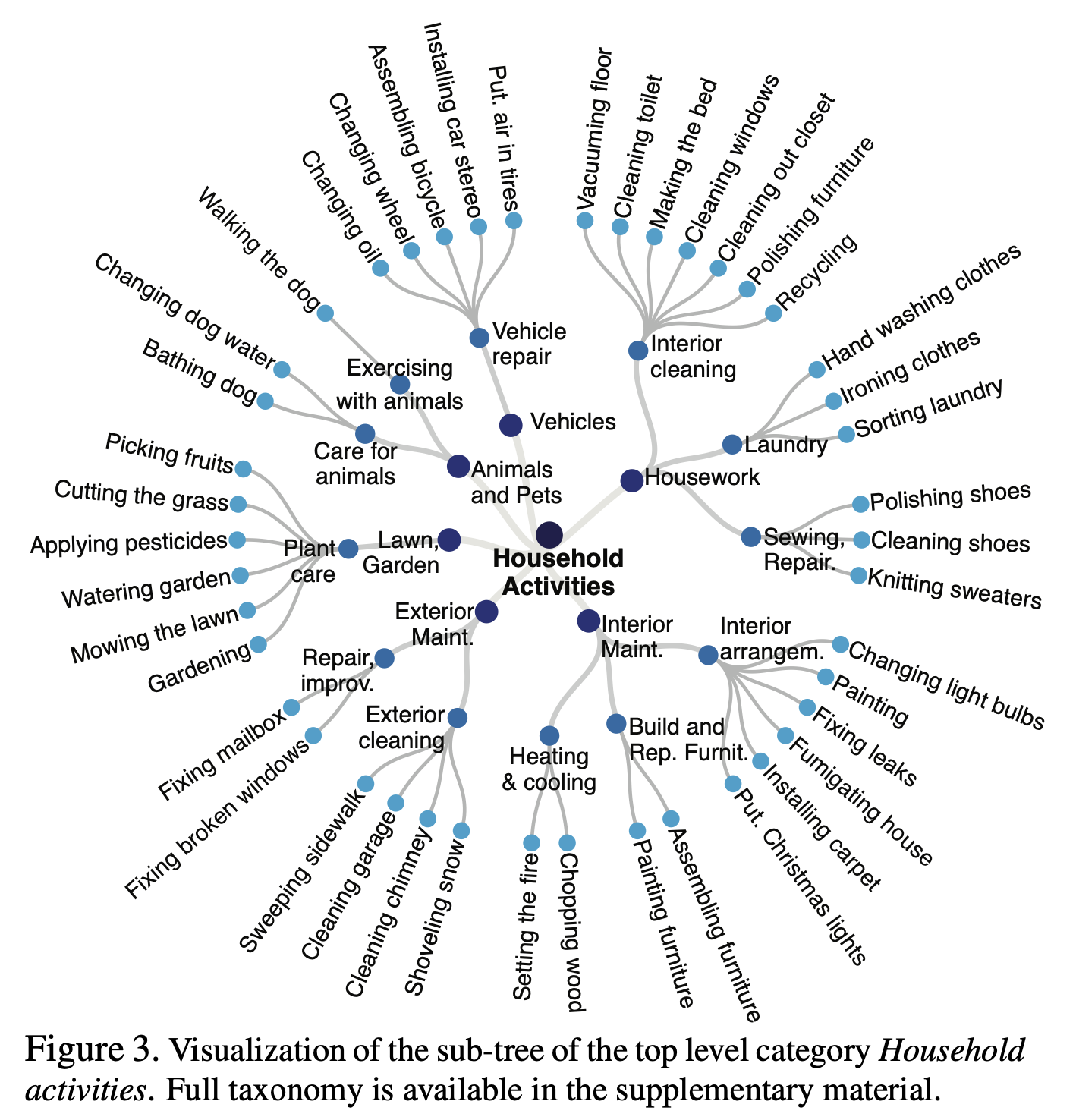
2.6. Sports-1M
- annotation을 사람이 한게 아니기 때문에, 잘 쓰이지 않음!!
- https://paperswithcode.com/dataset/sports-1m
- Sports-1M 데이터셋은 YouTube에서 100만 개 이상의 비디오로 구성되어 있습니다.
- 데이터셋의 비디오는 저자가 지정한 YouTube URL을 통해 얻을 수 있습니다.
- 데이터셋에는 487개의 스포츠 관련 카테고리에 카테고리 당 1,000개에서 3,000개의 비디오를 포함하여 100만 개 이상의 비디오
- 비디오는 YouTube의 Topics API를 사용하여 비디오와 관련된 텍스트 메타데이터(예: 태그, 설명)를 분석함으로써 자동으로 487개의 스포츠 클래스로 레이블링
- 약 5%의 비디오는 둘 이상의 클래스로 주석이 달려 있습니다.
2.7. THUMOS14

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것