LLaMA(Large Language Model Meta AI)는 Meta 가 2023년 발표한 LLM 논문으로, 챗지피티 보다 적은 파라미터 수로 훈련하고 뛰어난 성능을 보인 모델이다.
많은 파라미터 보다 더 많은 데이터로 훈련했으며, 모두 공개된 데이터를 사용하고 소스코드를 인터넷에 공개했다. 현재는 라마3까지 나왔으며, 이번에는 처음 공개된 라마 1을 리뷰한다.
용어 정리
- Text corpora (텍스트 코퍼스) : 대규모의 다양한 주제에 대한 텍스트 데이터 집합을 의미함.
- Textual instructions (텍스트 지시) : 텍스트로 주어진 지시 사항을 기반으로 모델이 새로- 운 작업을 수행할 수 있는 능력을 의미함.
Inference budget (추론 예산) : 언어 모델이 작동할 때 필요한 계산 자원의 양을 의미함. - Open-sourcing (오픈소싱) : 소스 코드를 공개하여 다른 개발자들이 사용할 수 있도록 하는 개념.
- Toxicity issues (독성 문제) : 모델이 공격적이거나 유해한 콘텐츠를 생성할 수 있는 문제.
- Pre-normalization (사전 정규화) : 모델 훈련 시 각 레이어의 입력을 정규화하여 훈련의 안정성을 높이는 기법.
- SwiGLU activation function (SwiGLU 활성화 함수) : ReLU 함수를 대체하는 활성화 함수로, 모델의 성능을 향상시키기 위해 사용됨.
- Rotary embeddings (로터리 임베딩) : 절대 위치 임베딩 대신 사용하는 기법으로, 모델의 위치 정보를 개선하는 데 사용됨.
- Gradient clipping (그래디언트 클리핑) : 모델 훈련 시 과도한 그래디언트 값이 발생하는 것을 방지하기 위해 설정된 상한값.
- Bytepair encoding (BPE) (바이트페어 인코딩) : 텍스트 데이터를 더 작은 단위로 변환하여 효율적으로 토큰화하는 알고리즘.
- Zero-shot (제로샷) : 모델이 사전 학습된 데이터 없이 새로운 작업을 수행하는 능력.
- Few-shot (퓨샷) : 적은 수의 예시로부터 모델이 학습을 수행한 후 작업을 수행하는 능력.
- Greedy decoding (탐욕적 디코딩) : 모델이 답변을 생성할 때, 가장 높은 확률을 가진 토큰을 연속적으로 선택하여 결과를 생성하는 방식.
LLaMA에서 사용한 주요 데이터셋과 그 설명
-
English CommonCrawl [67%]
2017년부터 2020년까지 수집된 CommonCrawl 덤프를 CCNet 파이프라인으로 전처리한 대규모 웹 크롤링 데이터. 중복을 줄이고 비영어 페이지를 제거하기 위해 fastText 선형 분류기를 사용하여 언어를 식별하고, n-gram 모델을 통해 저품질 콘텐츠를 필터링함. -
C4 [15%]
공개적으로 사용 가능한 CommonCrawl 기반의 데이터셋. C4 데이터셋은 중복 제거 및 언어 식별 단계를 포함한 전처리를 거쳤으며, 품질 필터링에 주로 휴리스틱을 사용하여 데이터를 정제함. -
Github [4.5%]
Google BigQuery에서 제공되는 공개 GitHub 데이터셋으로, Apache, BSD 및 MIT 라이선스 하에 배포된 프로젝트만 포함. 코드의 품질을 보장하기 위해 줄 길이와 영숫자 비율을 기반으로 저품질 파일을 필터링하며, boilerplate(반복되는 코드)도 제거함. -
Wikipedia [4.5%]
2022년 6월에서 8월 사이의 위키백과 덤프 데이터를 포함. 20개 언어를 다루며, 데이터에서 하이퍼링크, 댓글, 기타 불필요한 boilerplate를 제거함. -
Gutenberg and Books3 [4.5%]
퍼블릭 도메인에 있는 서적을 포함하는 Gutenberg Project와 ThePile의 Books3 섹션을 포함한 서적 데이터셋. 중복된 서적을 제거하여 훈련에 사용됨. -
ArXiv [2.5%]
ArXiv에서 제공되는 논문 Latex 파일 데이터셋. 첫 번째 섹션 이전의 모든 내용과 참고 문헌을 제거하여 논문 간 일관성을 높임. -
Stack Exchange [2%]
Stack Exchange의 질문 및 답변을 다루는 데이터셋으로, 28개 주요 웹사이트에서 수집된 데이터를 포함. 텍스트에서 HTML 태그를 제거하고, 답변을 점수에 따라 정렬함. -
Tokenizer (토크나이저)
bytepair encoding (BPE) 알고리즘을 사용해 데이터를 토큰화하며, SentencePiece(BPE가 특정 언어에 국한되지 않도록 하여, 영어뿐만 아니라 다른 언어에서도 동일한 방식으로 작동할 수 있음)를 통해 구현. 숫자는 개별 숫자로 분할되고, 알려지지 않은 UTF-8 문자는 바이트로 변환됨.
1. 서론
- LLaMA(Language Model with Large Scale Automatic Alignment)는 7B에서 65B 매개변수로 구성된 언어 모델 모음.
- 모델 크기는 각각 7B, 13B, 30B, 65B로, 각각 70억, 130억, 300억, 650억 개의 매개변수를 지님.
- 기존의 대규모 언어 모델들이 독점적 데이터에 의존하는 반면, LLaMA는 공개적으로 이용 가능한 데이터셋만을 사용해 훈련되었음.
- 이는 연구 커뮤니티에 쉽게 접근할 수 있도록 하고, 대규모 언어 모델 연구의 민주화를 촉진하는 것을 목표로 함.
- LLaMA-13B 모델은 GPT-3(175B) 모델과 비교했을 때, 10배 작은 모델임에도 불구하고 대부분의 benchmarks에서 더 우수한 성능을 보임.
- 이는 모델의 효율성과 경량화된 구조를 보여주는 중요한 사례.
- LLaMA-65B 모델은 크기가 더 큰 Chinchilla-70B 및 PaLM-540B 모델과 대등한 성능을 발휘하며, 최첨단 대규모 언어 모델들과 경쟁할 수 있음.
- 연구 커뮤니티에 모델을 공개함으로써, LLaMA는 대규모 언어 모델의 연구와 응용을 가속화하고, 더 많은 연구자들이 자유롭게 사용할 수 있게 함.
- 특히, LLaMA 모델은 단일 GPU에서도 실행이 가능하여, 연구 환경이 제한된 소규모 연구자들도 쉽게 접근할 수 있는 이점을 제공.
2. 접근법
2.1 훈련 방법 및 데이터
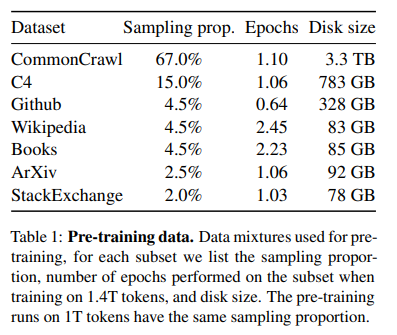
- LLaMA는 기존의 transformer architecture를 기반으로 하여, 대규모 언어 모델의 성능을 최적화하는 데 초점을 맞춤.
- 훈련 데이터는 공개적으로 이용 가능한 데이터셋으로만 구성되었으며, 대규모 text corpora에서 훈련됨.
-
CommonCrawl 데이터셋은 전체 훈련 데이터의 67%를 차지하며, 웹 크롤링 데이터로 구성됨.
- CommonCrawl 데이터를 정제하기 위해 CCNet 파이프라인을 사용하여 언어 식별 및 저품질 데이터를 필터링.
- **CommonCrawl 데이터셋**은 전체 훈련 데이터의 67%를 차지하며, 웹 크롤링 데이터로 구성됨. - **CommonCrawl**은 인터넷에서 크롤링된 웹 페이지의 방대한 데이터셋으로, 다양한 언어, 도메인, 웹사이트의 내용을 포함. - **CCNet 파이프라인**은 CommonCrawl 데이터를 처리하고 정제하는 데 사용되며, 이 과정에서 다음의 작업들이 수행됨: 1. **언어 식별**: CommonCrawl 데이터에는 여러 언어로 작성된 문서들이 포함되어 있기 때문에, 각 문서의 언어를 식별하는 작업이 필수적임. 이를 위해 **fastText** 선형 분류기를 사용하여 문서의 언어를 정확하게 분류함. 2. **저품질 데이터 필터링**: 웹 페이지에는 종종 저품질 콘텐츠(스팸, 중복 데이터, 의미 없는 문구 등)가 포함되어 있음. 이러한 데이터를 필터링하기 위해 **n-gram 언어 모델**을 사용하여 텍스트의 품질을 평가하고, 저품질 페이지는 데이터셋에서 제거. 3. **비영어 페이지 제거**: 연구에서 영어 데이터를 중심으로 모델을 훈련하기 위해 비영어 페이지를 제거하는 과정이 포함됨. 이는 언어 식별을 통해 수행되며, 영어 이외의 언어로 작성된 문서들은 필터링됨. 4. **중복 제거**: 웹 크롤링 데이터에는 같은 페이지가 여러 번 포함되거나, 내용이 중복된 문서가 많을 수 있음. 이를 방지하기 위해 데이터셋 내에서 중복을 탐지하고 제거하여 더 깨끗한 데이터를 확보함. 5. **선형 모델을 사용한 위키백과 페이지 구분**: CommonCrawl 데이터에는 위키백과 페이지도 포함되어 있을 수 있음. 위키백과는 신뢰할 수 있는 정보 소스로 간주되므로, 이를 참조 문서로 구분하기 위해 별도의 선형 모델이 사용됨. 참조되지 않는 페이지는 삭제하거나 추가적으로 검토됨. - 이러한 과정을 통해 CommonCrawl 데이터는 더 신뢰할 수 있고, 중복이나 저품질 콘텐츠가 제거된 형태로 정제됨. 결과적으로 LLaMA 모델의 훈련에 적합한 대규모 텍스트 코퍼스를 구성하게 됨.
-
- C4 데이터셋(15%)은 CommonCrawl 데이터를 전처리하여, 중복된 데이터를 제거하고 언어 식별 필터링을 적용한 데이터셋.
- Github 데이터셋(4.5%)은 오픈 소스 코드 데이터를 제공하며, 라이선스 제한을 준수한 프로젝트만 사용.
- Wikipedia 데이터셋(4.5%)은 20개 이상의 언어로 구성된 위키백과 데이터를 포함.
- Gutenberg and Books3(4.5%): 퍼블릭 도메인의 서적과 Books3 데이터셋을 포함하여 다양한 문학 자료를 제공.
- arXiv(2.5%)는 과학 논문 데이터를 추가하여, 기술적인 텍스트를 학습할 수 있게 함.
- Stack Exchange 데이터셋(2%)은 다양한 기술 질문과 답변을 포함한 포럼 데이터를 제공.
- 데이터는 bytepair encoding (BPE) 알고리즘을 통해 토큰화되었으며, 총 1.4조 개의 tokens으로 이루어짐.
- 대부분의 훈련 데이터는 1회 에폭을 통해 학습되었으며, 일부 도메인(위키백과, 서적 데이터)은 2번의 에폭을 거쳐 훈련됨.
2.2 아키텍처
- LLaMA는 transformer architecture에 기반한 모델이며, 다양한 개선 사항을 통해 기존 모델들보다 더 효율적이고 강력한 성능을 보임.
- Pre-normalization 기법을 사용하여 훈련의 안정성을 높이고, 각 transformer 하위 레이어의 입력을 정규화함.
- 이는 모델의 훈련 속도를 가속화하고, 기울기 소실 문제를 완화하는 데 도움을 줌.
- SwiGLU 활성화 함수를 도입하여, 기존의 ReLU 활성화 함수보다 더 나은 성능을 제공.
- Rotary Embeddings (RoPE)을 사용하여, 절대 위치 임베딩 대신 각 층의 상대적인 위치 정보를 학습함으로써 위치 정보 처리 효율을 높임.
- Pre-normalization 기법을 사용하여 훈련의 안정성을 높이고, 각 transformer 하위 레이어의 입력을 정규화함.
2.3 훈련 최적화
- AdamW 옵티마이저를 사용하여 훈련되었으며, 코사인 학습률 스케줄을 통해 학습률을 점진적으로 감소시킴.
- 이는 더 긴 학습 과정을 통해 모델이 최적의 성능을 달성할 수 있도록 함.
- 훈련 속도를 높이고 메모리 사용량을 줄이기 위해, 효율적인 인과적 다중 헤드 주의 기법을 도입함.
- 이를 통해 불필요한 계산을 줄이고, 모델의 실행 시간을 단축시킴.
- 훈련 중 역전파(backward pass) 단계에서 계산 효율성을 극대화하기 위해, 일부 활성화 값을 저장하여 다시 계산하는 과정을 최소화함.
- 또한, 모델 병렬화 및 시퀀스 병렬화 기술을 통해 모델 훈련 시간을 대폭 단축시킴.
3. 주요 결과
3.1 Zero-shot 및 Few-shot 성능 평가
- LLaMA는 다양한 작업에서 Zero-shot 및 Few-shot 학습 설정으로 평가됨.
- Zero-shot 학습: 모델은 사전 학습된 지식만을 바탕으로 새로운 작업을 수행하며, 추가적인 예시나 학습 과정 없이 바로 예측을 생성함.
- Few-shot 학습: 모델은 소수의 예제(1개에서 64개까지)를 제공받은 후, 이를 바탕으로 새로운 작업을 수행.
- LLaMA는 GPT-3, Chinchilla, PaLM 등 다양한 대규모 언어 모델들과 비교되어 성능을 평가받음.
- LLaMA-65B는 대부분의 benchmarks에서 Chinchilla-70B를 초과하는 성과를 거둠.
- LLaMA-13B는 크기가 10배 작은 모델임에도 불구하고 GPT-3보다 우수한 성능을 보여줌.
- LLaMA는 상식 추론, 독해, 수학적 추론 등 다양한 작업에서 최첨단 성능을 발휘함.
3.2 코드 생성 능력
- LLaMA는 HumanEval 및 MBPP와 같은 코드 생성 벤치마크에서도 평가됨.
- LLaMA-13B는 LaMDA 137B 모델보다 높은 성과를 기록하며, 코드 생성 작업에서 경쟁력을 입증.
- LLaMA-65B는 코드 전용 토큰에 대한 미세 조정 없이도 PaLM 및 LaMDA 모델과 유사한 성능을 발휘함.
- 코드 생성 작업에서 pass@1 지표를 기준으로 평가 시, LLaMA-65B는 PaLM-62B보다 우수한 결과를 기록.
3.3 다중 작업 언어 이해(MMLU) 평가
- MMLU(Massive Multitask Language Understanding)는 다양한 주제와 난이도를 가진 다중 선택 질문으로 구성된 벤치마크로, 모델의 종합적인 이해 능력을 평가함.
- LLaMA는 인문학, STEM, 사회 과학 분야를 포함한 다양한 작업에서 성능을 평가받음.
- LLaMA-65B는 일부 benchmarks에서 Chinchilla 및 PaLM 모델에 뒤처지지만, 전반적으로 높은 성능을 기록.
- 특히 서적 및 학술 논문 데이터의 양이 제한적이었기 때문에, 특정 작업에서는 성능이 다소 저하되었을 것으로 추정됨.
4. Instruction Finetuning
- LLaMA는 미세 조정을 통해 Instruction model로서의 성능을 향상시킬 수 있음.
- Instruction model이란 모델이 주어진 지시에 따라 적절한 작업을 수행하는 능력을 의미하며, 이를 위해 추가적인 지시 데이터로 미세 조정이 이루어짐.
- LLaMA-I는 지시 기반 데이터로 미세 조정된 모델로, MMLU 벤치마크에서 68.9%의 성과를 달성.
- 이는 기존의 중간 크기 Instruction model인 OPT-IML 및 Flan-PaLM 시리즈와 비교했을 때도 경쟁력 있는 성능을 보여줌.
- 지시 기반 미세 조정을 통해 LLaMA-I는 더욱 복잡한 작업에서도 성능이 향상되었으며, 이는 향후 연구에서 중요한 발전 가능성을 보여줌.
- 미세 조정을 단순히 적용했음에도 불구하고 성능 향상 폭이 크다는 점은, Instruction finetuning의 잠재력을 확인할 수 있는 중요한 증거.
5. Bias, Toxicity and Misinformation
5.1 RealToxicityPrompts
- LLaMA 모델은 독성 언어를 생성할 가능성을 평가하기 위해 RealToxicityPrompts 벤치마크에서 평가됨.
- 약 100,000개의 프롬프트가 주어지고, 각 프롬프트에 대한 모델의 응답이 PerspectiveAPI를 통해 독성 점수로 평가됨.
- 독성 점수는 0에서 1까지의 범위로 평가되며, 높은 값일수록 독성이 강함을 의미.
- LLaMA 모델은 Chinchilla 및 Gopher 모델과 비교해보았을 때, 모델 크기가 커질수록 독성 생성 가능성이 증가하는 경향을 보임.
5.2 CrowS-Pairs
- CrowS-Pairs 벤치마크는 모델의 편향을 측정하기 위해 사용됨.
- 이 벤치마크는 성별, 종교, 인종, 나이, 성적 지향 등 9가지 범주에서 편향을 측정할 수 있음.
- LLaMA는 제로샷 설정에서 각 범주의 편향을 측정하였으며, GPT-3 및 OPT-175B와 비교함.
- 결과적으로, LLaMA는 평균적으로 두 모델보다 편향이 적었지만, 특정 범주(종교, 성별, 나이)에서는 편향이 더 크게 나타남.
5.3 WinoGender
- WinoGender 벤치마크는 성별 대명사의 공참조 해결(co-reference resolution) 성능을 평가하기 위해 사용됨.
- 공참조 해결은 문맥에서 대명사가 가리키는 대상을 정확히 파악하는 능력을 의미하며, 성별과 직업에 따라 편향이 나타날 수 있음.
- LLaMA는 her/her/she, his/him/he 대명사에서 직업과 관련된 편향을 보였으며, 이는 CommonCrawl 데이터에서 기인했을 가능성이 있음.
5.4 TruthfulQA
- TruthfulQA 벤치마크는 모델이 얼마나 진실한 정보를 생성하는지 평가하는 기준임.
- 잘못된 정보를 생성할 위험을 평가하며, 진실성과 유익성의 교차점에서 모델의 성능을 측정.
- LLaMA는 GPT-3보다 더 높은 성과를 기록했으나, 여전히 진실되지 않은 정보를 환각할 가능성이 존재.
6. 탄소 발자국
- LLaMA 모델의 훈련에는 상당한 양의 에너지가 소모되었으며, 이로 인해 1,015 tCO2eq의 탄소 배출량이 발생함.
- 이는 OPT와 BLOOM 모델과 유사한 양의 훈련 에너지를 사용한 결과임.
- 훈련에 소요된 에너지는 GPU 병렬 처리를 통해 최적화되었으며, 향후 탄소 배출량을 줄이기 위한 노력이 지속적으로 필요함.
- 모델 공개를 통해 추가적인 훈련 없이도 많은 연구자들이 모델을 활용할 수 있기 때문에, 향후 발생하는 탄소 배출은 최소화될 것으로 기대됨.
7. 관련 연구
7.1 언어 모델의 발전
- 초기 언어 모델은 n-그램(n-gram) 카운트 통계를 기반으로 발전하였으며, 토큰의 확률을 계산하는 방식으로 작동.
- Katz 스무딩, Kneser-Ney 스무딩 등의 기법이 도입되어, 희소 데이터 문제를 해결하려는 시도들이 있었음.
- 그러나 통계 기반 모델은 장기 의존성(long-term dependency)을 학습하는 데 한계가 있었음.
- 이후, 신경망 기반의 접근법이 도입되어 신경 언어 모델(neural language models)로 발전하게 됨.
- Bengio et al. (2000): 신경망을 사용한 언어 모델 도입.
- Mikolov et al. (2010): RNN을 사용해 더 긴 문맥을 학습할 수 있는 모델을 제안.
- LSTM(Long Short-Term Memory) 및 GRU(Gated Recurrent Units)는 RNN의 한계를 극복하기 위해 도입된 구조로, 장기 의존성을 처리하는 데 유리함.
- Transformer networks(Vaswani et al., 2017)의 도입으로 인해, 언어 모델은 자기 주의 메커니즘(self-attention)을 활용하여 장기 의존성을 효과적으로 학습하게 되었음.
- BERT, GPT 시리즈는 transformer 구조를 통해 자연어 처리 작업에서 성능을 크게 향상시켰음.
7.2 스케일링 연구
- 언어 모델의 스케일링은 모델 크기와 데이터셋 크기 간의 관계를 탐구하는 연구로, 데이터와 매개변수를 확장함으로써 성능을 극대화하려는 시도들이 지속됨.
- Brants et al. (2007): 2조 개의 토큰을 사용한 언어 모델을 도입해, 기계 번역의 품질을 크게 개선.
- 신경 언어 모델에서도 더 많은 데이터를 활용해 성능을 극대화하려는 연구들이 이어졌음.
- Jozefo wicz et al. (2016): LSTM 모델을 10억 개의 매개변수로 확장하여 최첨단 성능을 달성.
- 대규모 transformer 아키텍처의 도입으로, BERT, GPT-3 등은 성능을 크게 개선하였으며, 이후 여러 연구에서 데이터와 모델 크기의 상관관계에 대한 분석이 이루어짐.
- Kaplan et al. (2020): 모델 성능이 매개변수와 데이터셋 크기의 확장에 따라 파워 법칙(power law)을 따름을 제시.
- Hoffmann et al. (2022): 모델 크기보다 데이터를 더 많이 활용하는 것이 성능 향상에 더 효과적임을 입증.
- LLaMA는 이러한 스케일링 연구를 기반으로, 매개변수 크기에 비해 더 많은 tokens을 사용해 훈련되어, 기존의 독점적 데이터셋에 의존하지 않고도 최첨단 성능을 발휘할 수 있음을 보여줌.
8. 결론
- LLaMA는 대규모 언어 모델 연구에서 중요한 도약을 이루었음. 공개된 데이터로만 훈련된 모델임에도 불구하고, 기존의 독점적 데이터셋을 사용한 모델들과 대등한 성능을 보임.
- 특히 LLaMA-13B는 GPT-3보다 10배 이상 작은 모델임에도 불구하고, 대부분의 benchmarks에서 더 우수한 성과를 보임.
- LLaMA-65B는 Chinchilla-70B 및 PaLM-540B와 같은 최첨단 모델들과 경쟁할 수 있음.
- LLaMA는 연구 커뮤니티에 모델을 공개함으로써, 대규모 언어 모델 연구의 민주화를 촉진.
- 연구자들은 독점적인 데이터 없이도 최첨단 성능을 발휘할 수 있는 모델을 연구하고 발전시킬 수 있게 되었음.
- 편향(bias) 및 독성(toxicity) 문제는 여전히 해결해야 할 과제.
- LLaMA는 웹에서 수집한 데이터를 사용함에 따라, 잠재적으로 편향된 콘텐츠를 학습할 위험이 존재함.
- 이러한 문제를 해결하기 위해, LLaMA는 RealToxicityPrompts와 CrowS-Pairs 벤치마크를 통해 편향과 독성 문제를 평가함.
- 향후 연구에서는 이러한 문제를 개선하고, 언어 모델이 공정하고 안전하게 사용될 수 있도록 하는 방안이 필요함.
- Instruction model로 미세 조정된 LLaMA-I는 지시를 따르는 능력이 크게 향상되었으며, 이를 통해 모델의 다양한 활용 가능성이 열림.
- 지시 기반의 미세 조정을 통해 LLaMA는 다양한 작업에서 더욱 강력한 성능을 발휘할 수 있는 가능성을 보여줌.
- 탄소 발자국 문제 또한 중요한 고려사항.
- LLaMA의 훈련 과정에서 상당한 양의 에너지가 소비되었으나, 모델이 공개되었기 때문에 추가적인 훈련이 필요하지 않음.
- 이는 장기적으로 탄소 배출을 줄이는 데 기여할 수 있으며, 환경 영향을 최소화할 수 있음.
