[2019 IEEE Access] Aggregated Residual Dilation-Based Feature Pyramid Network for Object Detection
Paper Info.
https://ieeexplore.ieee.org/abstract/document/8840842

Abstract
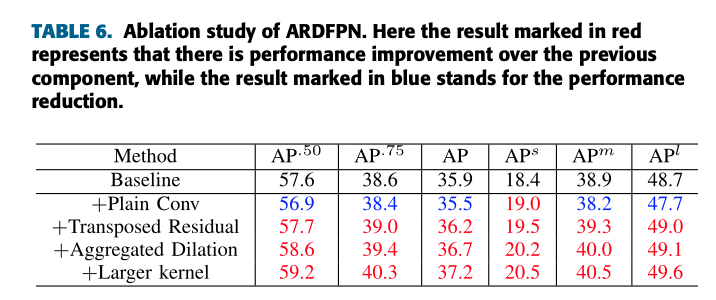
- multi-scale object detection을 위해서,
top-down features and lateral features의 naive combination으로 생성되는
hierarchical feature pyramids를 채택하는 것이 일반적이다.
(문제 제기)
-
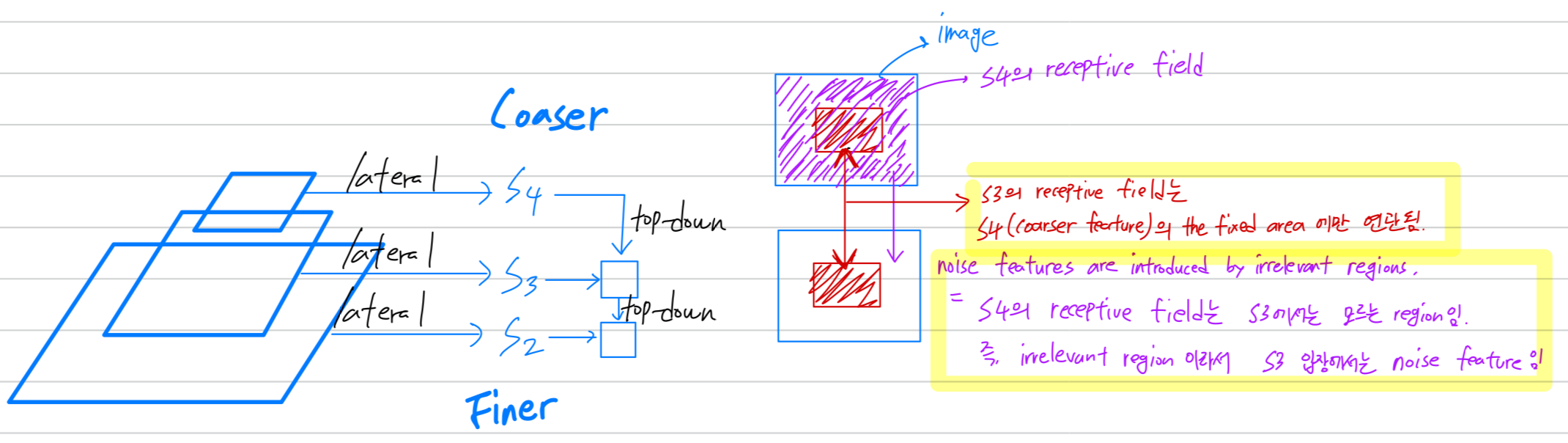
그런데 top-down features augmentation에 대한 기존 방법들은 limited effective receptive fields를 가지므로,
생성된 영역은 coarser(저해상도) features의 the fixed(고정된) areas에만 연관된다.- 내가 이해한 내용:
는 image에 대한 receptive field가 (coarser feature)만큼 global하지 않음.
그래서 의 receptive field는 의 receptive field의 일부분에만 연관되어 있음.
- 내가 이해한 내용:
-
한편, finer features가 rigid(고정된) coarser regions과 관련되어 있기 때문에
irrelevant regions(무관한) regions에 의해 noise features의 발생이 불가피해진다.- 내가 이해한 내용:
의 receptive field는 의 receptive field의 일부분에만 연관되어 있기 때문에
반대로, receptive field에 해당하지 않은 의 receptive field는 입장에서는 noise feature임.
- 내가 이해한 내용:
-
따라서 간단히 top-down features를 확대하는 것만으로 pyramidal features with strong semantics을 얻는 것은 어렵다.
(제안)
- 이 논문에서,
우리는 feature pyramid의 inherent correlation(고유한 상관관계) of regions을 활용하기 위해
Aggregated Residual Dilation based Feature Pyramid Network (ARDFPN)을 제안한다.
1. Introduction
- 비록 shallow layers에서 objects의 adequate (그럭저럭 괜찮은) finer details을 갖고 있지만,
detection을 할 만큼의 semantically strong feature maps을 extract하진 않는다.
그래서, developing a scale-invariant detector는 여전히 CV에서 fundamental challenge이다.
(과거)
- detector, image pyramid를 위한 hand-crafted detectors가 제안되었지만,,
a long range of scales에 대해 지속적으로 robust feature maps을 생성할 수 없다.
(현대)
- traditional featurized image pyramids와 반대로,
deep network based feature pyramids는 promising solution for multi-scale detection이다. (Fig. 1(b))
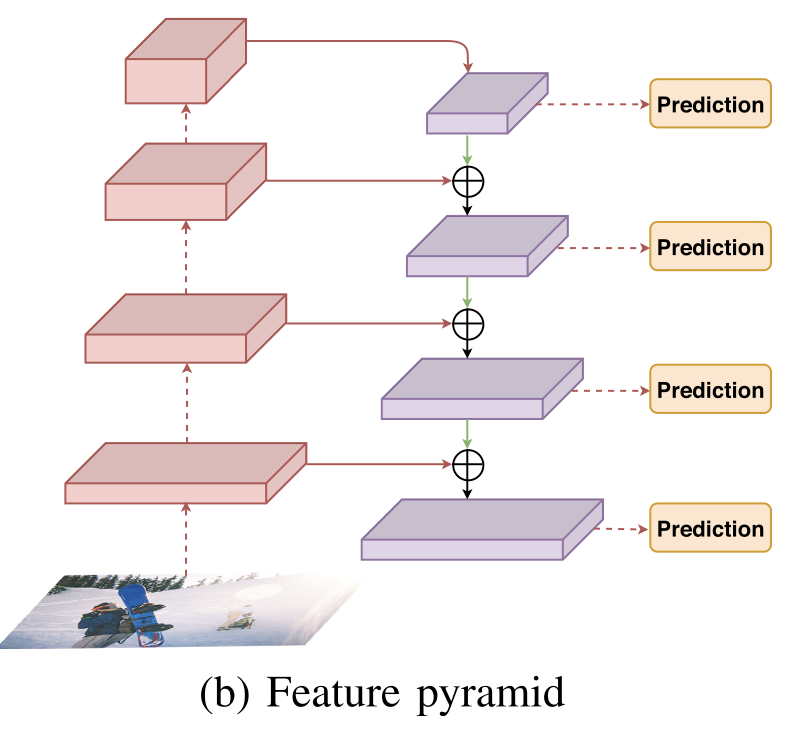 서로 다른 scales의 feature maps들이 combinations of top-down pathways and lateral connections을 생산하여
서로 다른 scales의 feature maps들이 combinations of top-down pathways and lateral connections을 생산하여
all pyramidal layers는 적절한 semantical representation을 갖게 된다.
더 구체적으로, the coarse (high level) feature maps은 interpolation or transposed convolutions을 통해 simply enlarged된다.
merge된 fine (low level) feature maps은 convolutional mappings을 통해 연결된다.
(문제)
- current pyramidal feature generation을 위한 the effective receptive fields는 작기 때문에 (e.g. 2x2),
the finer (low level) feature maps의 the generated regions은
a limited number of coarser (higher level) regions에만 연관되어 있다.
(제안)
-
여기서,
우리는 the features of the finer pyramidal levels을 복원할 때,
단순히 the solitary fixed neighbor regions을 고려하는 것이 아니라,
diverse contextual regions도 함께 고려해야 한다고 주장한다.
lateral connections을 통해 feature maps을 augmenting하는 것뿐만 아니라,
semantical feature generation을 well-designed하면 pyramidal layers를 더욱 enhance할 수 있다. -
본 논문에서,
우리는 fully conv network - Aggregated Residual Dilation based FPN (ARDFPN)을 제안한다.
이 network는 split-transform-merge philosophy에 기반하여
each pyramidal feaure generation block 내의 region correlation을 활용한다.
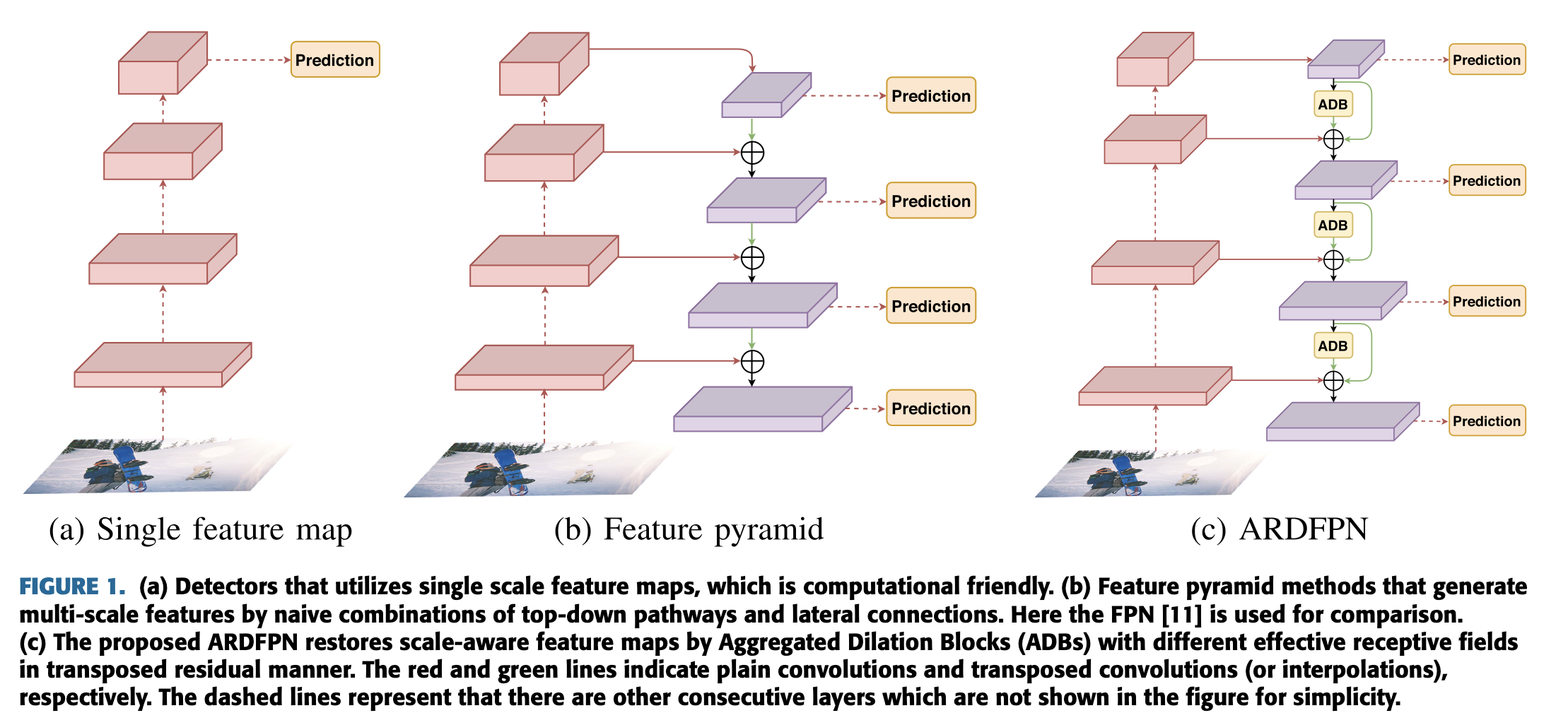 Fig. 1(c)와 같이, 단순히 interpolation이나 transposed conv를 사용하는 대신,
Fig. 1(c)와 같이, 단순히 interpolation이나 transposed conv를 사용하는 대신,
feature pyramid의 generation block은 transposed residual manner로
일련의 dilated conv transformation을 수행하며,
그 outputs들을 elementwise-summation으로 aggregated한다.
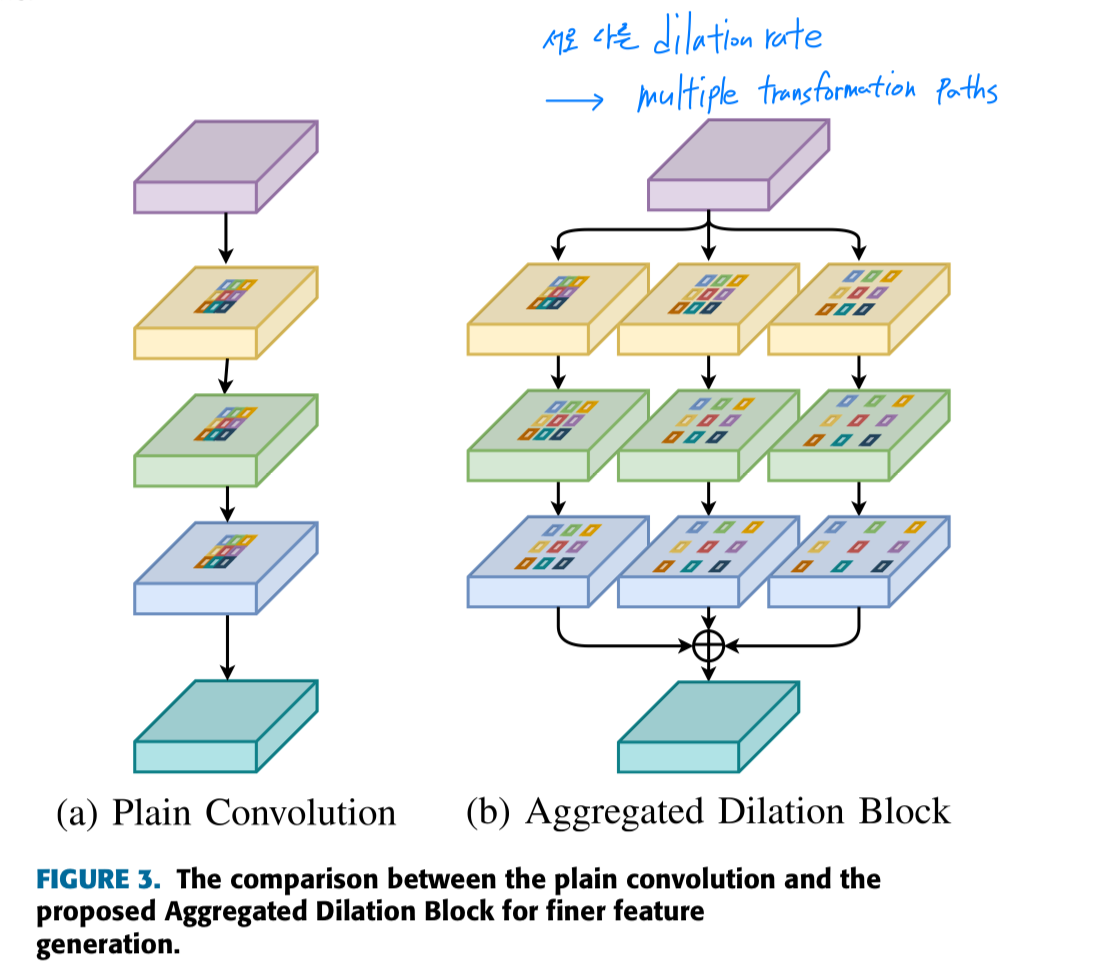
multiple transformation paths를 통해,
each generation block은 서로 다른 dilation(팽창) rate로 spatially region correlation을 활용한다.
dilation rate가 증가할수록,
a wide range of contexts로부터 the new regions이 생성되며,
feature pyramid의 top-down pathway에서 effective receptive field가 증가한다.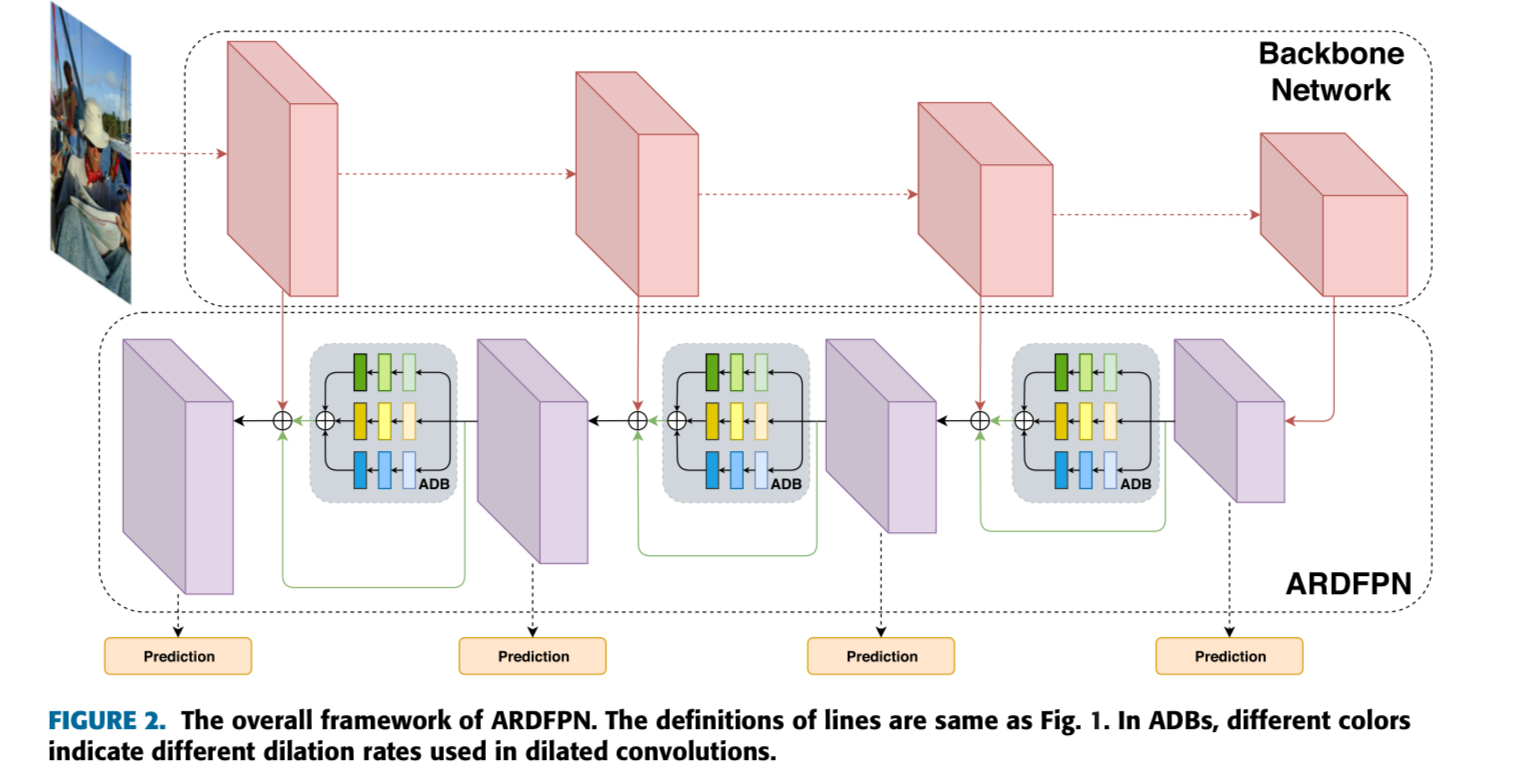
 또한, larger transposed conv kernels을 사용함으로써,
또한, larger transposed conv kernels을 사용함으로써,
the generated pyramidal feature maps는 more related coarser regions을 포함할 수 있어 semantic representation이 향상된다. -
backbone conv architecture와 관계없이,
ARDFPN이 기존의 FPN module보다 OD and instance segmentation tasks에서 outperforms함을 실험적으로 입증했다.
aggregated dilation module and transposed residual learning을 활용함으로써,
ARDFPN은 feature pyramid의 semantic generation을 촉진하여
final detection performance를 향상시킬 수 있다.
2. Related Works
(skip)
3. Model Design
dilated conv와 transposed conv의 이해를 돕기 위한 시각화
-
dilated conv: receptive field를 띄엄띄엄
(출처: https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md)
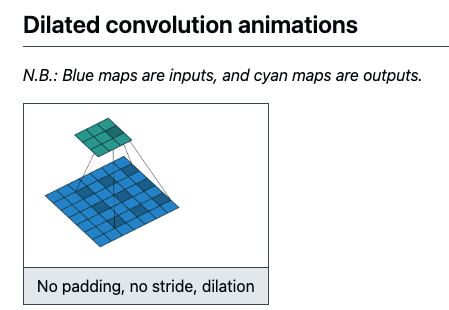
-
transposed conv: upsampling (interpolation과 달리, parameter가 존재하여 학습이 가능)
(출처: https://coronasdk.tistory.com/1408)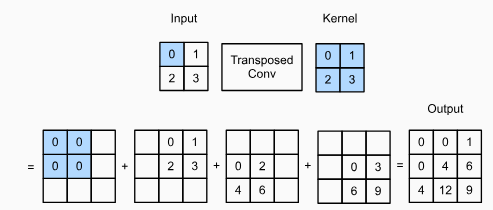
A. Aggregated Dilation Block
-
ADB의 목표는 각 pyramidal level에서 effective receptive fields를 augmenting하여
multi-scale instances의 high resolution feature maps을 restore하는 것. -
그러므로,
우리는 서로 다른 scales의 instance를 위한 receptive fields를 도모하기 위해
서로 다른 dilation rates로 이루어진 parallel dilated convs를 통해
ADB에 a multi-branch architecture를 employ했다.


- 각 branch에서,
low-resolution feature maps은 cascaded(연속된) dilated or non-dilated conv layers of 3x3 kernels with stride 1로 인해 추가로 enhanced될 수 있다.
(conv layer 뒤에 nonlinear activation이 뒤 따르므로 ADB는 more discriminate representations을 가져온다.) - 게다가, conv layers에서 the learnable weighted combinations of coarser regions 덕분에
unrelated regions에 의한 the feature noise는 certain degree에서 제거될 수 있다. - 그리고나서,
서로 다른 branches에서 나온 feature maps들을 element-wise summation하여 aggregated feature map을 얻는다.
- 각 branch에서,
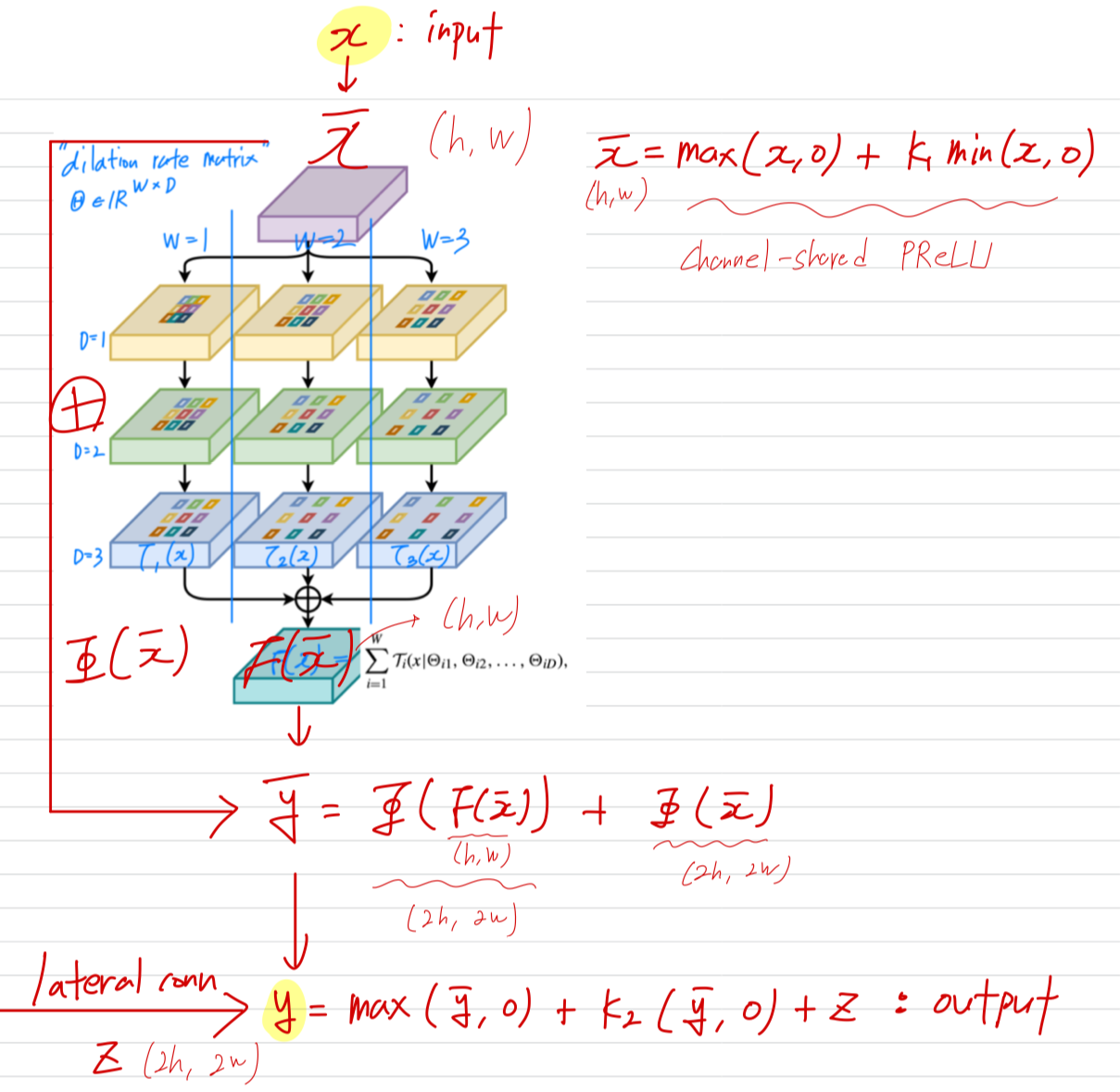
B. Transposed Residual Learning

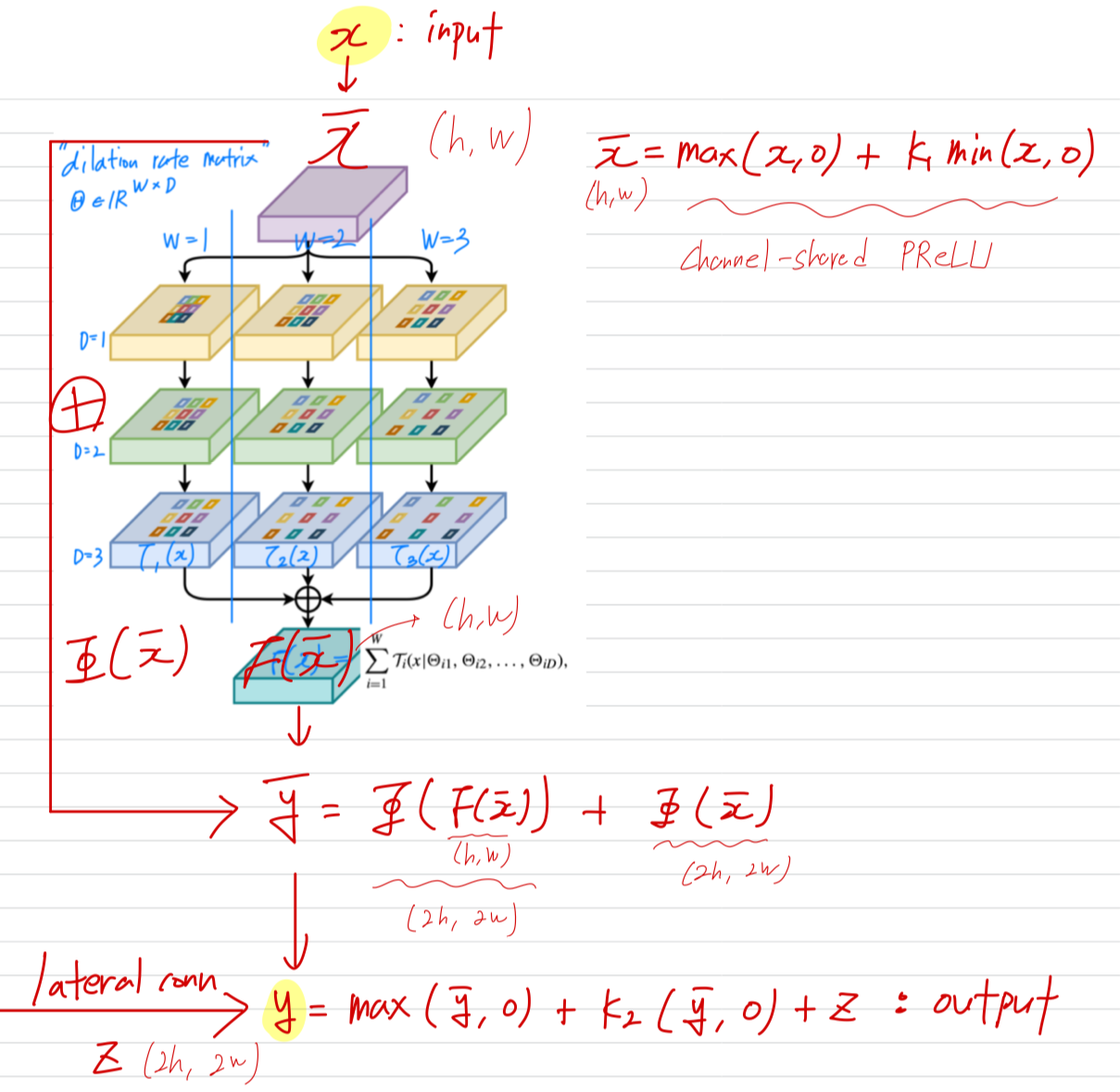
- 궁금증 1: maxmin 왜 이렇게 설계했을까?
결국 음수값에만 을 곱해주는 건데, 이 효과는?
알아보니까,
위는 PReLU의 형태이다. 근데 이 논문에서는 activation function으로 PReLU가 아닌, Channel-shared PReLU (CSPReLU)을 썼다.
근데 이 논문에서는 activation function으로 PReLU가 아닌, Channel-shared PReLU (CSPReLU)을 썼다.
PReLU는 channel마다 learnable parameter 가 있지만,
CSPReLU는 모든 channel에서 공유하는 단 하나의 learnable parameter 가 있는게 차이점이다.
activation function으로 CSPReLU를 쓴 이유는 feature extraction과는 다른 요구사항을 갖는 feature generation에 사용되기 때문이다.
feature extraction에서는 다양한 channel이 서로 다른 방식으로 변환되면서 복잡한 semantic representation을 형성해야 하기 때문에 각 channel마다 독립적 학습이 가능한 coefficient parameter를 쓰는 PReLU가 적합하지만
feature generation에서는 channel별 transformation보다 interleaved transformation (일관된 변환)이 필요하기 때문에 CSPReLU가 더 적합하다.
C. Larger Transposed Convolution Kernel
- larger kernel size일 수록, the regions in finer feature map은 more coarser contents에 연관되어 있다.
특히 the center of the finer feature map에 가까울수록.

Larger kernel의 효과가 가장 좋음.