[2022 ECCV] ByteTrack: Multi-Object Tracking by Associating Every Detection Box

Paper Info.
- https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136820001.pdf
Zhang, Yifu, et al. "Bytetrack: Multi-object tracking by associating every detection box." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.
Introduction
(Background)
-
현재, Tracking-by-detection은 MOT에서 most effective paradigm이다.
하지만 videos 내 complex scenarios 때문에, detector는 imperfect predictions을 만드는 경향이 있다. -
SOTA MOT methods들은
low confidence detection boxes를 제거하기 위해
true positives / false positive trade-off 문제를 다뤄야 한다.
(motivation)
-
However, is it the right way to eliminate all low confidence detection boxes?
Our answer is NO: as Hegel said "What is reasonable is real; that which is real is reasonable."
이 관점에서, Low confidence detection boxes는 때때로 objects (occluded objects)의 existence를 나타내기도 한다. -
low confidence detection boxes도 object에 대한 정보를 가지고 있으니, 이러한 boxes를 모두 filtering out하는 것은
irreversible errors for MOT와 non-negligible missing detection and fragmented trajectories를 유발하게 된다.
(proposition)
- 그래서 이 paper에서는,
tracklet과의 similarity가 low score detection boxes에서 objects와 background를 distinguish할 수 있는 strong cue가 된다는 것을 확인한다.

- Figure 1(c)에서 볼 수 있듯이,
Two low score detection boxe는 motion model이 prediction한 box를 통해 tracklet과 matching되며, 그 결과 occlusion된 object가 올바르게 복원된다.
동시에, Tracklet과 matching되지 않는 background box는 제거된다. - high score부터 low score까지 모든 detection boxes를 matching process에서 최대한 활용하기 위해,
우리는 BYTE라는 a simple and effective association method를 제안한다.
이 이름은, 각 detection box를 computer program의 byte처럼 tracklet의 a basic unit으로 본다는 의미에서 붙여졌으며,
우리의 tracking method가 모든 detailed detection box를 중요하게 다룬다는 점을 강조한다.- 먼저,
high score detection box를 motion similarity or appearance similarity를 기반으로 tracklet과 matching한다.
우리는 Kalman filter를 사용하여 새 frame에서 tracklet의 location을 예측한다.
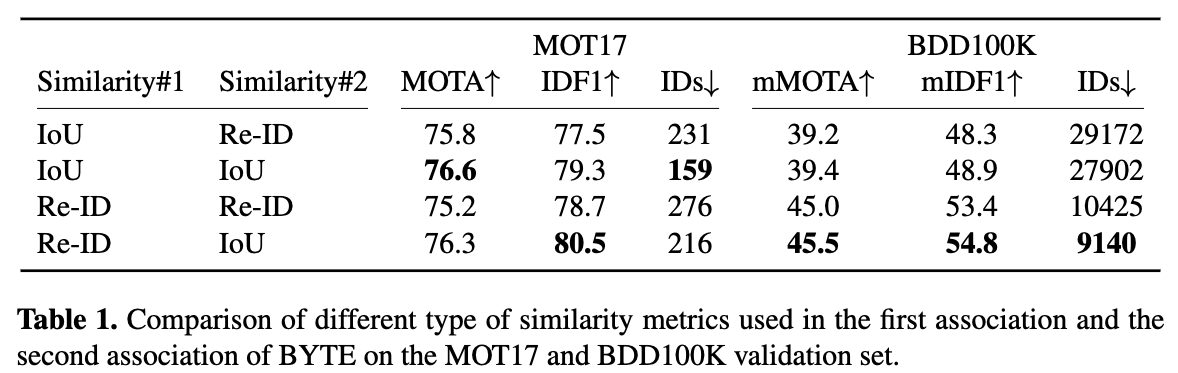
이때 Similarity는 predicted box와 detection box 간의 IoU 또는 Re-ID feature distance를 통해 계산할 수 있다.
Figure 1(b)는 first matching 이후의 결과를 보여준다.
(내가 이해한 설명: 즉 first matching은 그냥 SORT에서 했던 것처럼 IoU threshold 기반 association) - 그리고 나서,
unmatched tracklets (즉, red box로 표시된 tracklet)과 low score detection box 간에
동일한 motion similarity를 수행한다.
Figure 1(c)는 이 second matching 이후의 결과를 보여준다.
이 과정에서, low detection scores를 가진 occluded person은 이전 tracklet과 정확하게 matched되고,
반대로 image의 오른쪽에 있는 background box는 removed된다.
즉, 이 second matching이 이 논문에서 제안하는 핵심 method
- 먼저,
- Figure 1(c)에서 볼 수 있듯이,
2. Related Work
2.1. Object Detection in MOT
Tracking by detection
-
object detection의 빠른 발전으로 더 많고 powerful detectors가 high tracking performance를 달성하기 위해 활용되고 있다.
RetinaNet, CenterNet, YOLO series... 이러한 방법들은 tracking을 위한 a single image에 대한 detection boxes를 즉시 사용한다. -
하지만, video sequence에서 발생하는 occlusion or motion blur가 발생하면
the number of missing detections and very low scoring detections이 증가하기 시작하여,
video object detection methods들도 제안되었다.
즉, previous frames들에 대한 정보는 보통 video detection performance를 향상시키기 위해 사용되기도 한다.
Detection by tracking
- tracking은 또한 more accurate detection boxes를 위해 사용될 수 있다.
- 몇가지 방법들은 single object tracking (SOT) or Kalman filter를 활용하여
다음의 frame에 대한 tracklets의 location을 predict하고
detection results를 향상시키기 위해서 detection boxes와 predicted boxes를 fuse한다. - 다른 방법들은 following frame의 feature representation을 강화하기 위해 previous frames에 대한 tracked boxes를 사용한다.
- 최근 몇 방법들은 frames 간 boxes들의 propagate에 대한 strong ability 덕분에 Transformer-based detectors를 사용한다.
- 우리의 방법 또한 detection boxes의 reliability를 강화하기 위해 tracklets과의 similarity를 활용한다.
- 몇가지 방법들은 single object tracking (SOT) or Kalman filter를 활용하여
- detectors에 의해 detection boxes를 얻은 이후에,
대부분의 MOT methods들은 threshold (0.5)를 기준으로 only the high score detection boxes만 남기고
그 boxes들을 data association의 input으로 사용한다.
이는 low score detection boxes들이 많은 backgrounds를 포한하고 있고, 그것이 tracking performance를 해치기 때문이다.
하지만, 우리는 many occluded objects들이 low score detection boxes들에 의해 정확히 detected될 수 있다는 것을 관찰했다.
missing detections을 줄이고 the persistence of trajectories를 유지하기 위해,
우리는 모든 detection boxes와 그 모든 boxes들을 association의 input으로 사용했다.
2.2. Data Association
- Data association은 multi-object tracking의 core이다.
data association은 먼저 tracklets과 detection boxes간의 similarity를 구하고
그들을 similarity에 따라 match시켜주기 위해 다양한 strategies를 활용한다.
Similarity metrics
-
Location, motion and appearance는 association을 위한 useful cues이다.
SORT는 location과 motion cues를 아주 간단한 방식으로 결합한다.
SORT는 먼저 new frame에서 tracklets의 location을 predict하기 위해 Kalman filter를 적용하고
Kalman filter에 의해 predicted boxes와 detection boxes 간의 IoU를 similarity로 사용한다. -
몇가지 최근 연구에서는 object motions을 학습하기 위한 networks를 design하고
large camera motion or low frame rate의 경우세어 more robust results를 달성했다.
location and motion similarity는 short-range matching에서 accurate하다. -
Appearance similarity는 long-range matching에 유용하다.
어떤 한 object는 오랜 시간 동안 occluded된 후에도 appearance similarity를 활용하여 re-identified될 수 있다.
Appearance similarity는 Re-ID features의 cosine similarity에 의해 측정될 수 있다.
DeepSORT는 detection boxes로부터 appearance features를 extract하기 위한 stand-alone Re-ID model을 적용했다.
최근에, jointly detection and Re-ID models은 그들의 simplicity and efficiency로 인해 더 popular해지고 있다.
Matching strategy
-
similarity computation 이후에, matching strategy는 objects에 identities를 할당한다.
이는 Hungarian Algorithm or greedy assignment에 의해 수행된다.- SORT는 한 번의 matching으로 detection boxes를 tracklets에 match한다.
- DeepSORT는 the most recent tracklets에 detection boxes를 우선 match한 뒤,
그 다음 lost tracklets에 대해 match하는 cascaded matching strategy를 제안했다. - MOTDT는 먼저 appearance similarity를 이용해 matching을 수행한 뒤,
unmatched tracklets에 대해 IoU similarity를 활용하여 추가 match를 한다. - QDTrack은 appearance similarity를 bi-directional softmax operation에 의한 probability로 변환하고
matching을 수행하기 위해 a nearest neighbor search를 적용한다.
...
-
이러한 방법들은 how to design better association methods에 focus한다.
하지만 우리는 detection box를 어떻게 활용하느냐가 data association의 upper bound를 결정한다고 주장하고,
high scores부터 low scores까지의 모든 detection boxes를 matching process에서 어떻게 최대한 활용할지를 focus한다.
3. BYTE
- previous methods which only keep the high score detection boxes와는 달리,
BYTE는 대부분의 detection box를 keep하고 그들을 high score boxes와 low score boxes로 분리한다.- 우리는 우선 high score detection boxes를 tracklets에 associate한다.
- 그리고 나서, low score detection boxes에 대한 objects를 recover하고 background를 filter out하기 위해
low score detection boxes와 unmatched tracklets들을 associate한다.
- The pseudo-code of BYTE는 Algorithm 1에 있다.

4. Experiments
4.1. Setting
Implementation details.

4.2. Ablation Studies on BYTE
Similarity analysis.
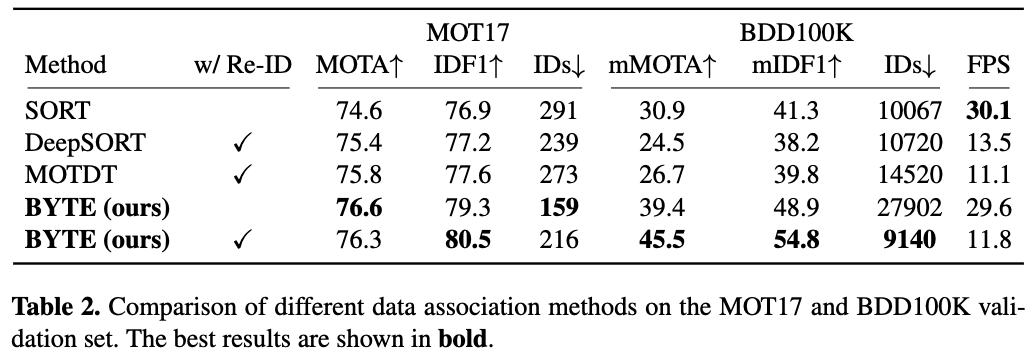
Comparisons with other association methods
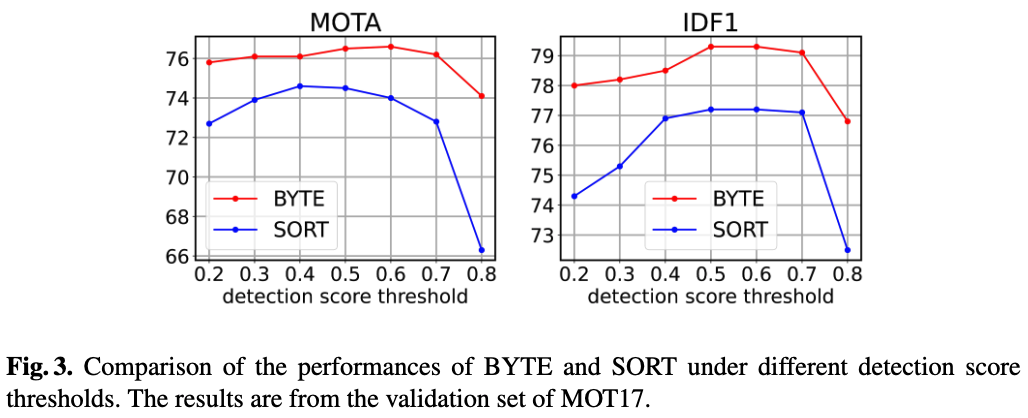
Robustness to detection score threshold.
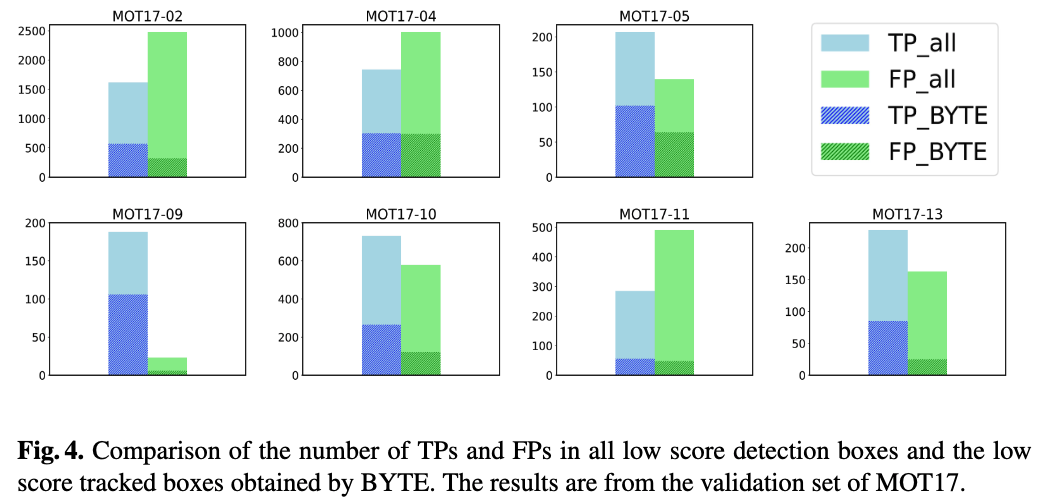
Analysis on low score detection boxes.
Applications on other trackers.
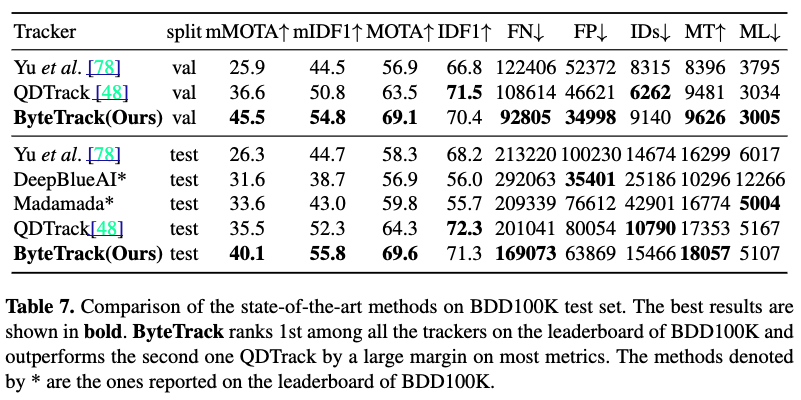
4.3. Benchmark Evaluation
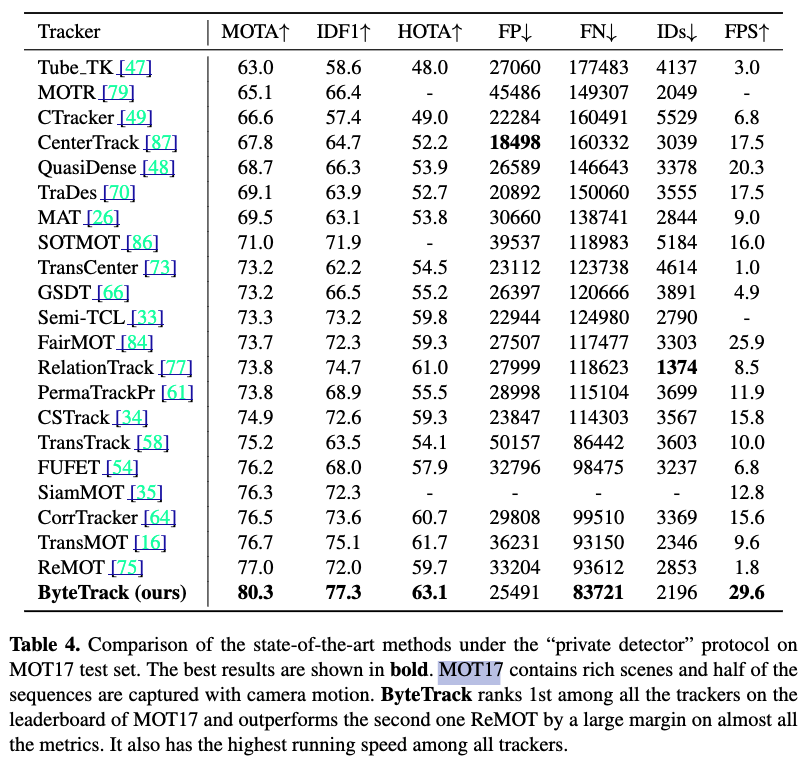
MOT17
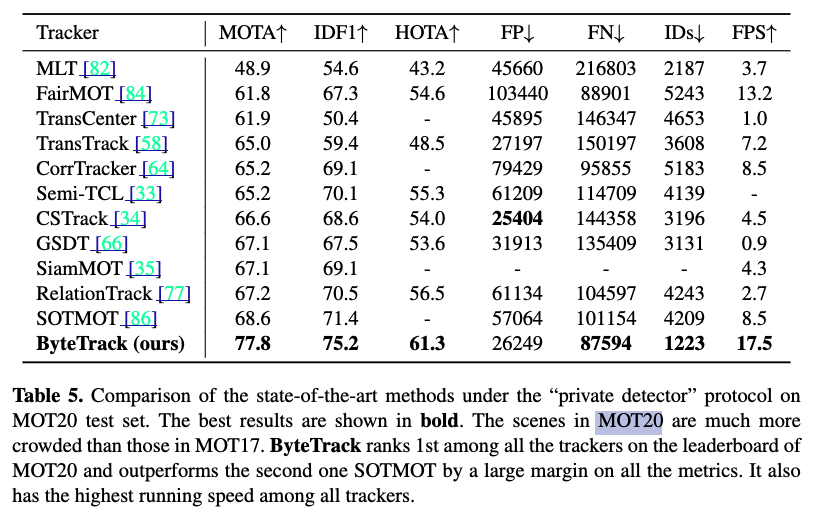
MOT20
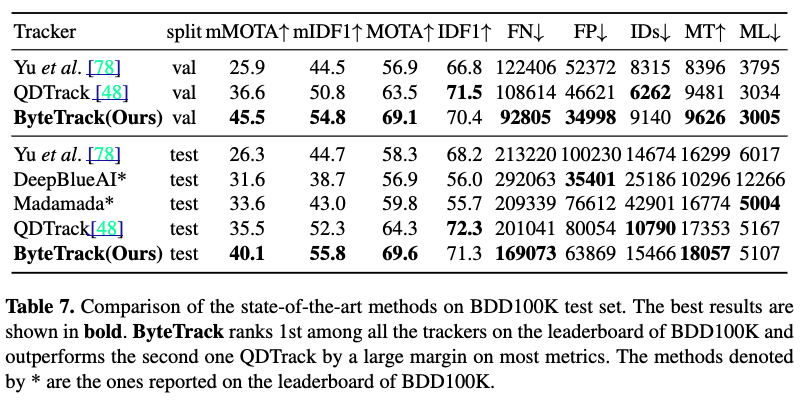
BDD100K