[Chap 1] Introduction
1.1 OS가 할 일
컴퓨터 구성 요소
UserApplication Programs: 응용프로그램
(컴파일러, 브라우저, 개발 장비, ... 컴퓨터 안에 또는 밖에 있을 수 있다 ➡️ Cloud)Operating SystemHW(CPU, memory, I/O devices, ...)Network: 최근에는 network가 필수적이라, 컴퓨터 구성요소로 포함할 수도 있다.
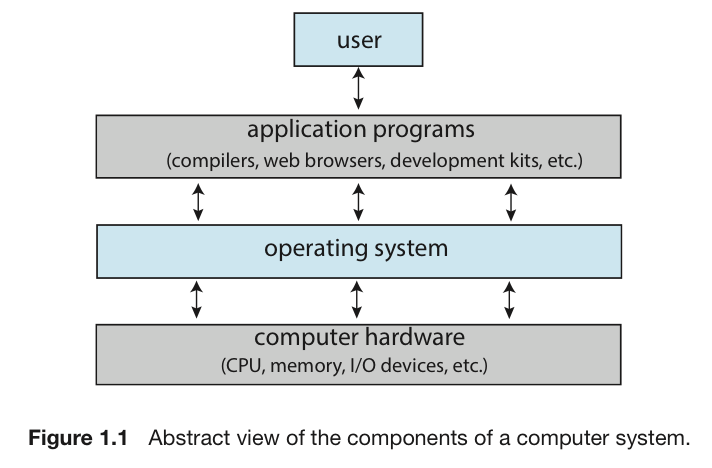
➡️ OS는 (User와 HW) 그리고 (Application과 HW) 사이를 막아선다.
운영체제의 목적
OS는 User와 HW 사이의 매개체 역할을 한다고 했다.
따라서 운영체제의 목적은 다음과 같다.
- Execute user programs and make solving user problems easier
(User Program을 실행시키고, User Problem을 쉽게 해결할 수 있도록 한다.) - Make the computer system convenient to use.
(Computer System을 사용하기 쉽도록 한다.) - Use the computer HW in an efficient manner
(HW를 효율적으로 사용할 수 있게 한다.)
사용자 관점의 OS
-
Laptop 또는 Desktop
이러한 시스템은 한 사용자가 자원을 독점하도록 설계되었으며, 목표는 사용자가 수행하는 작업을 최대화하는 것이다.
이러한 경우 OS는Ease of Use(사용의 용이성),Good Performance(좋은 성능)에
더욱 신경 쓰며Resource Utilization(자원의 이용)에는 신경을 쓰지 않는다. -
Shared Computer
이러한 시스템은 모든 사용자가 사용에 불편함이 없도록 해야 한다.
이러한 경우 OS는Resource Allocator,Control Program으로써
User Programs와 HW의 사용을 효율적으로 관리한다. -
Mobile Computer
이러한 경우 OS는Usability와Battery Life에 최적화하도록 해야 한다. -
Embedded Computer
이러한 시스템은 User Interface가 있을 수도 있고 없을 수도 있다.
(ex. 자동차의 숫자 표시등은 User Interface없이 작동한다)
OS가 있다고 해서 모든 것이 I/O가 있는 것이 아니다.
동작은 있지만 User Interface가 없을 수도 있다.
따라서 다양한 사용자 환경에 따라서 최고의 효율을 만족시키도록 해야 한다.
시스템 관점의 OS(운영체제의 정의)
- 운영체제를
Resource Allocator(자원 할당자)로 볼 수 있다.- 컴퓨터 시스템은 문제를 해결하기 위해 요구되는 여러 가지 자원들(CPU, Memory Space, Bus, I/O device,user 등)을 가진다.
- OS는 이러한 자원들의 Conflicting Requests에 대해 효율적이고 공정하게 운영할 수 있도록, 어느 Request에 Resource를 Allocating할지 결정해야 한다.
- example)
appplication을 동시에 1000개 띄운다. 어떻게 될까?
➡️ 동작은 하는데 매우 버벅일 것이다.
Allocation은 됐지만 Mangement가 안되기 때문
- 운영체제는
Control Program(제어 프로그램)이다.- Control Program은 컴퓨터의 부적절한 사용을 방지하기 위해 사용자 프로그램의 수행을 제어한다.
OS는 특히 I/O device의 제어와 작동에 깊이 관여한다.
- Control Program은 컴퓨터의 부적절한 사용을 방지하기 위해 사용자 프로그램의 수행을 제어한다.
- 운영체제는 컴퓨터에서
항상 실행되는 프로그램(Kernel)이다.
1.2 Computer-System Organization
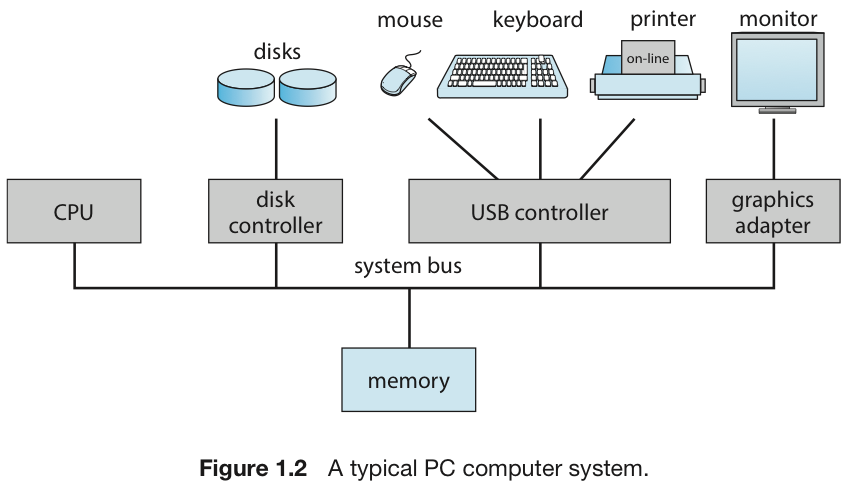
컴퓨터 시스템 구성요소
- 현대의 General-Purpose Computer System에는
- 하나 이상의 CPU
- 여러 Device Controller
(mouse devcie controller, keyboard device controller, monitor device controller, ...) - CPU와 여러 Device Controller와 Shared Memory 사이의 access를 제공하는 Bus
로 구성된다.
Device Controller
Device Controller:- 각각의 Device Controller는 Comupter System을 구성하는
각각의 device(disk drive, 오디오 장치, 모니터 등)들을 관리한다. - 각각의 Device Controller는 각각의 Device를 위한
Local Buffer Storage와 Special-purpose register 집합을 갖고 있다. - 각각의 Device Controller가 제어하는 주변 Device와 Local Buffer Storage 간에
데이터 이동을 관리한다.
- 각각의 Device Controller는 Comupter System을 구성하는
Device Driver
Device Driver: 운영체제에는 각 Device Controller마다 Device Driver가 있다.- 이 Device Driver는 각자의 Device Controller의 동작을 잘 알고 있고,
나머지 운영체제에 대한 일관된 Interface를 제공한다.
(OS 제조 회사와 HW 제조 회사끼리 표준화가 잘 되어있다)
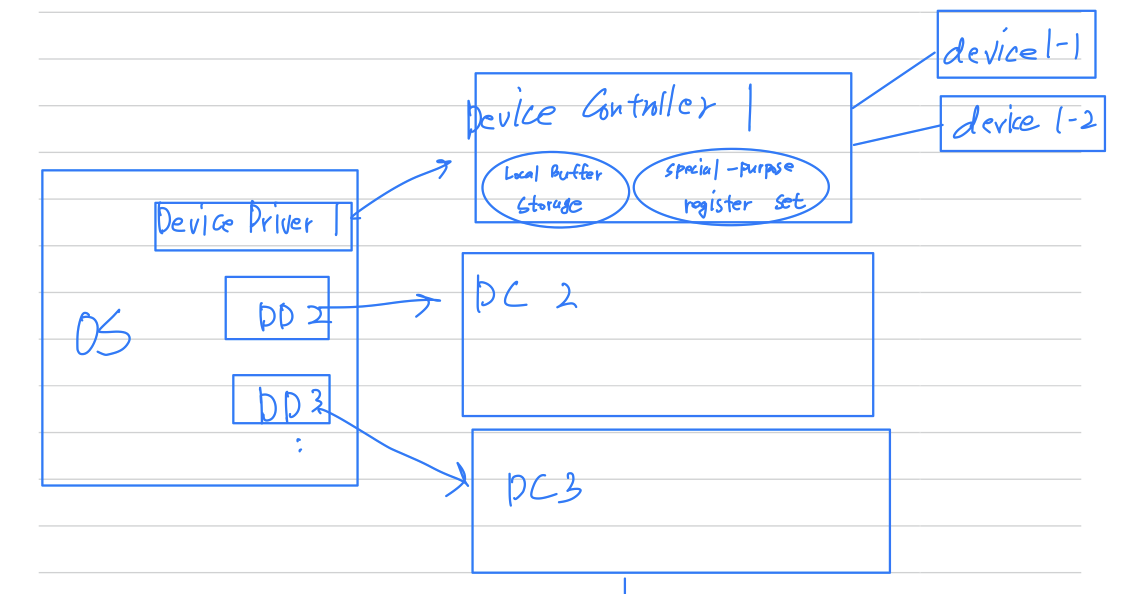
- 이 Device Driver는 각자의 Device Controller의 동작을 잘 알고 있고,
Main Memory(RAM) Bus, CPU vs Device Controller
-
CPU는 프로그램이나 데이터를 Main memory에서 읽거나 쓸 때, Bus를 사용한다.
- Loading : program을 실행시키기 위해 디스크 등의 저장장치에서
메인 메모리로 올려주는 과정. - Execution : program code를 CPU가 읽어 명령어를 실행하고,
데이터를 읽어오거나 결과를 저장하는 작업.
- Loading : program을 실행시키기 위해 디스크 등의 저장장치에서
-
Device Controller는 외부 Device와 통신하기 위해, Bus를 사용한다.
CPU와 Device Controller는 둘 다 Parellel하게 실행되어,
Main memory에 하나 밖에 없는 Bus를 두고 경쟁한다.
➡️ 이를 해결하기 위해Interrupt가 존재
Interrupt
-
interrupt: HW(실제 물리적으로 존재하는 장치로부터 신호 : clock, 디스크 쓰기 완료, 패킷 도착 등)적인 event를 운영체제에게 알리는 일이다.
(Main memory의 Bus를 사용하기 위해 운영체제에게 제어권을 요청) -
interrupt 기본 메커니즘 :
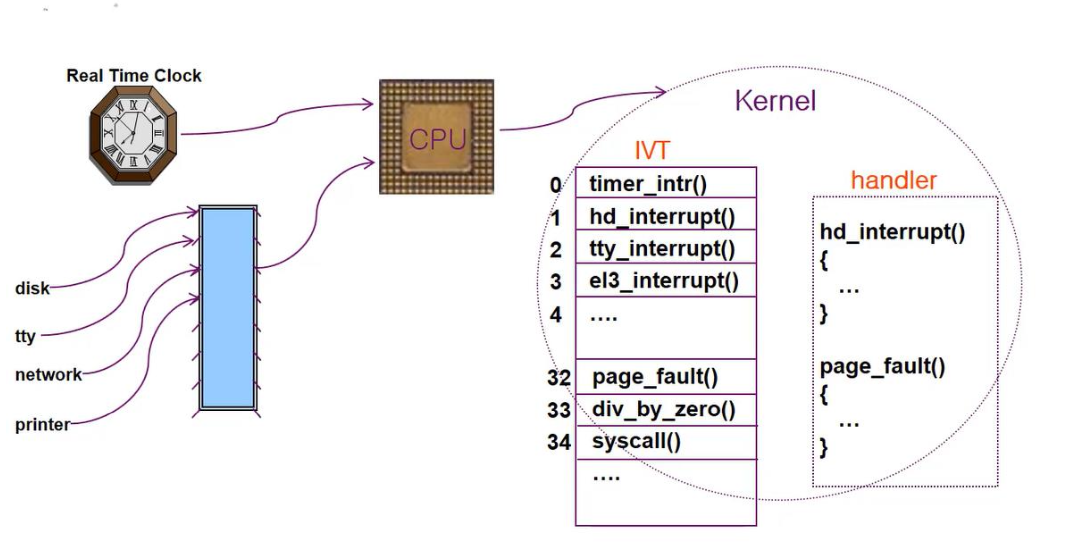
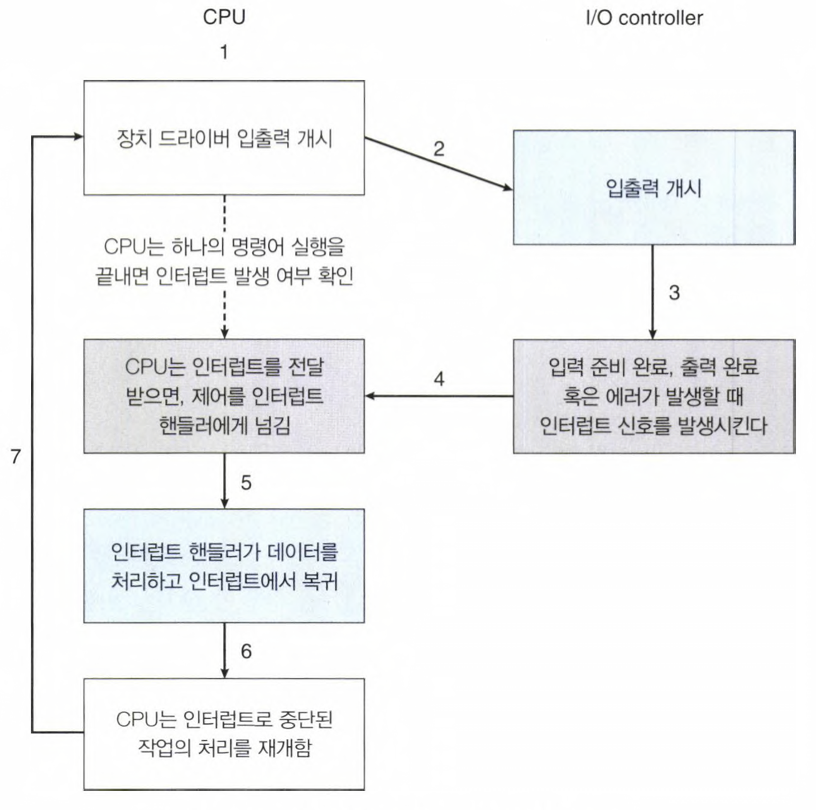
- CPU 하드웨어는 Interrupt Request Line(IRL)이라는 선이 존재한다.
- 하나의 명령어의 실행을 완료할 때마다 CPU가 이 선을 감지한다.
- CPU는 Device Driver가 IRL에 보낸 interrupt request 신호를 감지하면,
- CPU는 현재 명령의 주소와 상황을 Stack에 저장한다.
- IRL로 온 신호를 IVT(Interrupt Vector Table)에서 해석한다.
- IVT에서 어떠한 interrupt인지 찾아 그에 맞는 handler(== ISR, Interrupt Service Rountine)을 실행한다.
- ISR 실행이 완료되면, Stack에 저장해놨던 interrupt 발생 전으로 되돌아간다.
-
interrupt 처리 방식은
Polling 방식과Vector Interrupt System 방식으로 나뉜다.-
Polling 방식: CPU가 주기적으로 Device나 입출력 buffer를 확인하여 interrupt가 발생했는지 여부를 체크하는 방식.
CPU가 계속해서 polling을 반복하므로, 자원 낭비가 크고, interrupt 지연 시간도 길어짐. -
Vector Interrupt System 방식: interrupt 발생시, interrupt controller가 interrupt vector라는 특별한 메모리 위치에 ISR 주소를 저장하여 CPU에 전달한다.
CPU는 이 ISR 주소를 참조하여 해당 ISR을 실행한다.
이 방식은 Polling 방식에 비해 자원 낭비가 적고, interrupt 지연 시간도 짧아지므로
빠른 interrupt 처리가 가능하다.따라서 vector interrupt system 방식이 더욱 효율적인 interrupt 처리 방식이다
-
-
IO는 idle 상태에 있다가 있다가 event가 들어와서 CPU에 던지면,
IO가 해달라고 하는 것을 CPU가 바로 진행하지 못함.
하던거 정리하고 와야함(stack에 저장하는 과정) → 잠깐 delay 발생
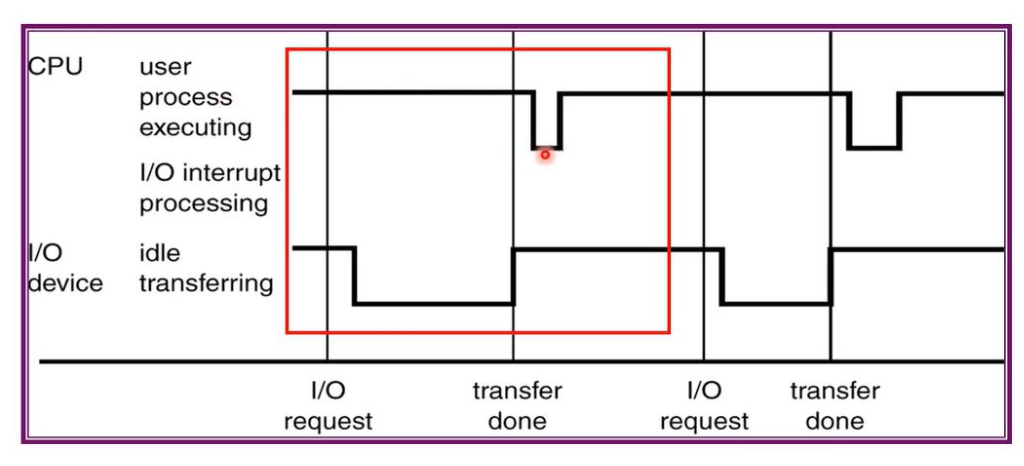
-
interrupt가 들어왔을 때, 들어온 것을
기다리고 있는 것을 pending이라고 한다.
➡️ A가 진행되고 있는 중에 B가 interrupt걸렸다.
B가 기다려야 하는 상황이면 B가 pending되었다.
Trap
Trap: SW적 event(명령어나 데이터 오류, system call)를 운영체제에게 알리는 일이다.
Interrupt VS Trap VS System Call VS API
-
Interrupt(인터럽트)- HW에서 발생하는 이벤트(HW Device 오류, 입출력 요청 등)를 운영체제에 알리는 것.
- 인터럽트는 HW에서 자동으로 발생하므로,
프로그래머가 인터럽트를 명시적으로 호출하는 것은 불가능하다.
➡️ 외부에 의해 호출 - kernel mode에서 처리된다.
간단히 하면,
Interrupt는 HW에서 발생하는 event(HW Device 오류, 입출력 요청 등)를 운영체제에 알리는 것.
-
Trap(트랩)- Trap은 CPU가 현재 실행 중인 프로세스에서
예외 상황이 발생할 때 자동으로 발생한다. - 예를 들어, 프로그램이 실행 중인 상태에서 'Divide-by-zero'연산을 시도하면,
이는 예외 상황으로 간주되어 CPU는 해당 예외 상황을 처리하기 위해 Trap을 발생시킨다.간단히 하면,
Trap은 CPU가 실행 중인 process에서 발생하는 SW적 event를 운영체제에 알리는 것.
➡️ CPU에서 어떠한 process가 실행 중인데, 그 process에서 'Division by Zero', '유효하지 않은 메모리 접근', 'Overflow', 'System call' 등등 SW에서 발생하는 event를 운영체제에게 알리는 것.
- Trap은 CPU가 현재 실행 중인 프로세스에서
-
System Call(시스템 콜)- 운영체제에서 제공하는 서비스를 호출하기 위해 사용
- 프로그램이 시스템 콜을 호출하면,
해당 서비스의 처리를 위해 운영체제에게 제어권이 넘어간다. - 시스템 콜은 프로그래머가 명시적으로 호출해야 하며,
호출하는 방식에는 보통 소프트웨어 인터럽트를 사용한다.
➡️ 내부에 의해 호출 - user mode에서 처리된다.
간단히 하면,
System Call은 programmer가 program에 코드를 작성함으로써 운영체제에서 제공하는 서비스를 호출하는 것.
System Call은 Trap을 발생시키는 종류 중 하나이다.
-
API(Application Programming Interface)- SW 응용 프로그램에서 다른 프로그램 또는 서비스와 상호 작용할 수 있도록
인터페이스를 제공하는 것을 의미. - API는 System Call과 유사한 역할을 수행하지만,
API를 사용하면, 개발자는 System Call을 직접 호출하지 않고도
운영체제의 기능을 사용할 수 있으며, 이를 통해 개발 시간을 단축하고 개발자의 편의성을 높일 수 있다.
- SW 응용 프로그램에서 다른 프로그램 또는 서비스와 상호 작용할 수 있도록
Storage Structure
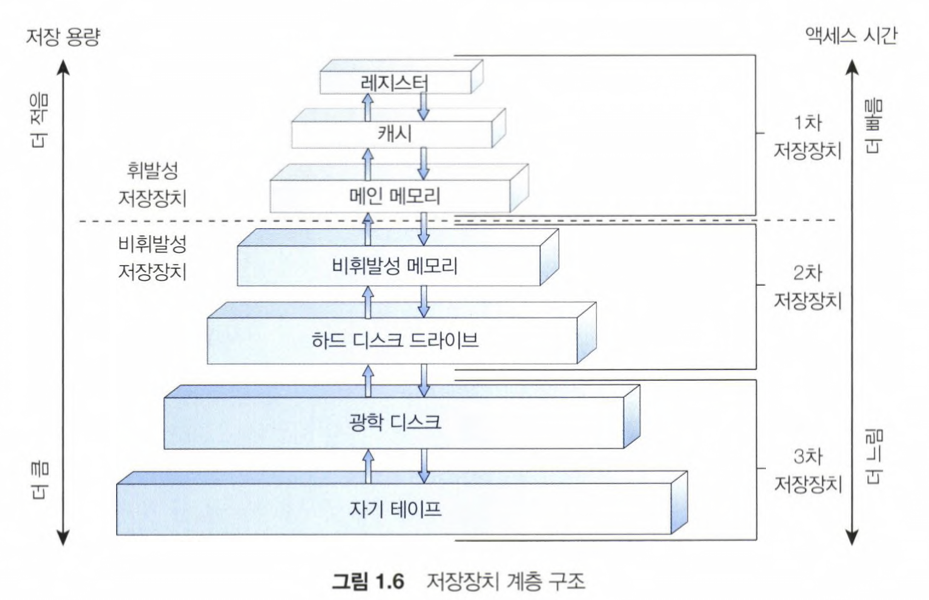
-
Cache: CPU와 주기억장치(RAM) 사이에 위치한 속도가 빠른 메모리이다.
CPU가 주기억장치로부터 데이터를 가져올 때,
이전에 사용한 데이터가 Cache에 이미 저장되어 있다면
Cache 메모리에서 데이터를 가져와 사용한다.
이렇게 함으로써 CPU가 데이터를 더 빠르게 접근할 수 있게 되어 시스템 성능을 향상시킬 수 있다.- C언어의 go-to 문법은 사용하지 않는 것이 좋다.
cache는 순차적으로 실행될 것을 예상하는데, go-to로 왔다갔다하면,
cahce의 예상이 빗나가서 프로그램이 오래 걸리게 되고, 에러 확률이 높아짐. - 2차원 배열에서 위에서 아래로 읽는 것은 보다 오래 걸림.
왼쪽에서 오른쪽으로 읽는 것이 더 빠름.
- C언어의 go-to 문법은 사용하지 않는 것이 좋다.
-
main memory:
CPU는 memory에서만 명령을 적재할 수 있으므로 실행하려면
프로그램을 먼저 memory에 적재해야 한다.
범용 컴퓨터는 프로그램 대부분을
Main memory(DRAM)이라 불리는 재기록 가능한 메모리에서 가져온다.- 모든 형태의 memory는 byte의 배열을 제공한다.
각 byte는 자신의 주소를 가지고 있다.
상호작용은 특정 memory 주소들에 대한 load 또는 store 명령을 통하여 이루어진다. - load : main memory로부터 CPU 내부의 register로 한 byte 또는 한 word를 옮기는 것.
- [word] : byte 단위의 데이터를 묶어서 처리하는 단위.
32bit architecture에서 단위 word의 크기는 4bytes.
64bit architecture에서 단위 word의 크기는 8bytes.
- [word] : byte 단위의 데이터를 묶어서 처리하는 단위.
- store : CPU 내부의 register 내용을 main memory로 옮기는 것.
- 모든 형태의 memory는 byte의 배열을 제공한다.
-
Secondary Storage(보조기억장치): 대부분의 컴퓨터 시스템은 main memory의 확장으로 보조기억장치를 제공한다.- 보조기억장치의 주요 요건은 대량의 데이터를 영구히 보존할 수 있어야 한다는 점이다.
- 가장 일반적인 보조기억장치는
HDD(Hard Disk Drive)와 NVM(Non Volatile Memory)장치로,
program과 data를 모두를 위한 저장소를 제공한다. - 대부분의 program은 memory에 load될 때까지 보조기억장치에서 저장된다.
- program load : HDD에 저장된 program을 실행하기 위해 해당 프로그램을 main memory로 load
- 보조기억장치는 main memory보다 훨씬 느리다.
- NVS(Non Volatile Storage)는 크게 두 가지로 나눈다.
- 기계적 : HDD, 광 디스크, 자기 테이프 등..
- 전기적 : SSD, Flash memory, ...
전기적 저장장치가 보다 비싸고 용량이 적으며 빠르다.
- NVS(Non Volatile Storage)는 크게 두 가지로 나눈다.
-
Storage Hierachy
- Speed (속도)
- Cost (비용)
- Volatility (휘발성)
HDD
-
일반적으로 메모리는 Byte 단위로 처리한다.
이때 메모리의 각 Byte는 고유한 주소를 갖는다. -
HDD를 main memory로 쓸 수 없는 이유
➡️ HDD의 data는 물리적인 디스크 표면에 저장되어 있기 때문에
디스크에서 읽고 쓰는 동작이 필요하여 메모리처럼 Byte 단위로 직접 접근할 수 없다.
그래서 HDD는 데이터를 읽고 쓰는 과정에서 시간이 더 소모되기 때문에 main memory보다 느리다. -
데이터 기록, 판독 원리
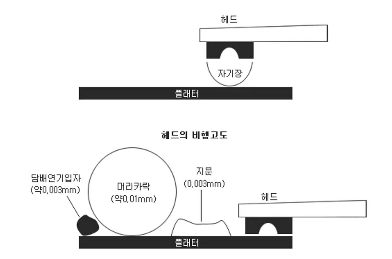
- platter와 head는 물리적으로 떨어져 있다.
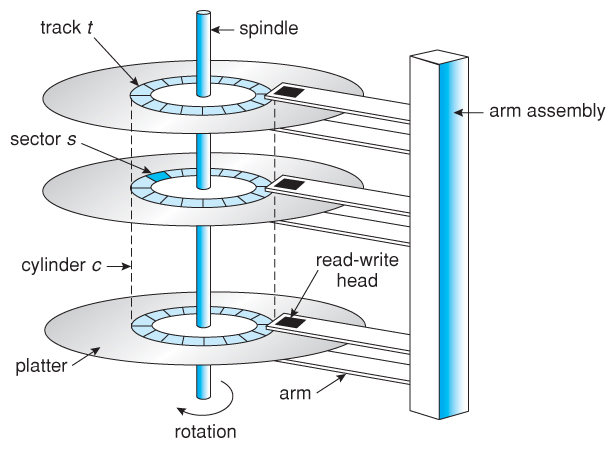
- platter는 한 장짜리도 있고, 여러 장짜리도 있다.
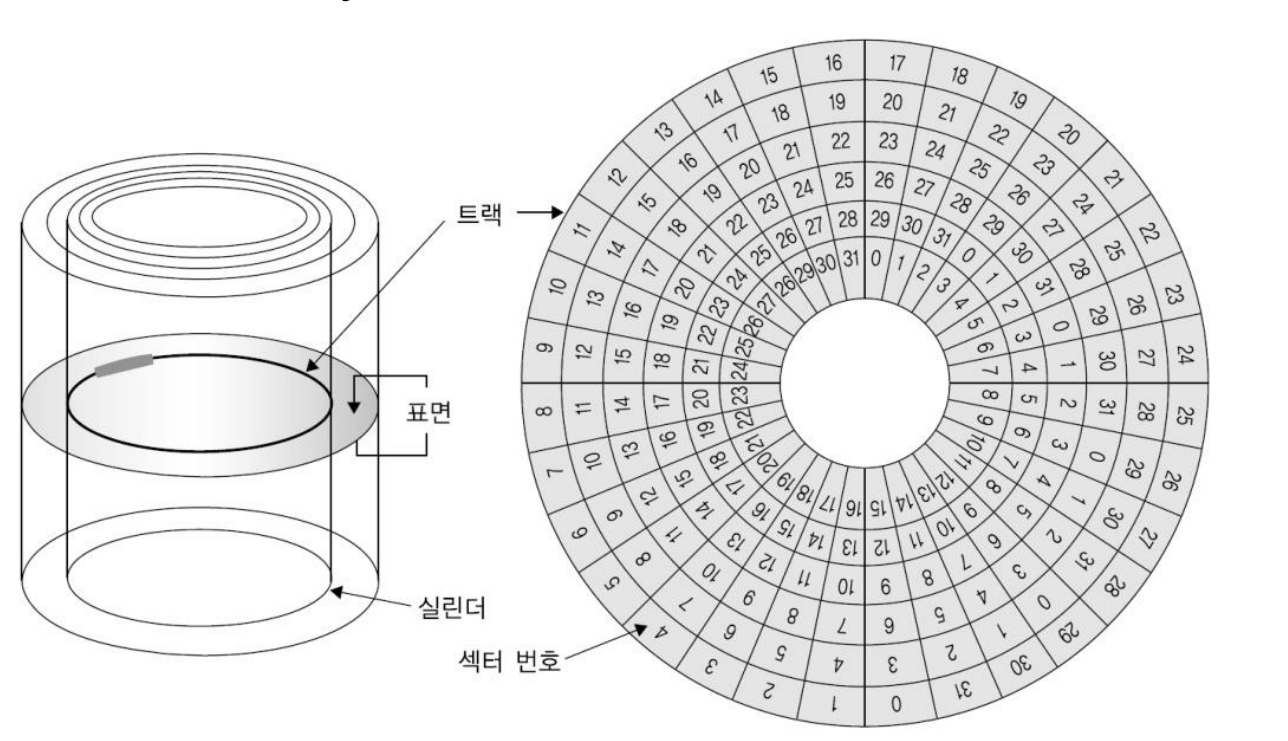
main motor == spindle: 보통 1분에 72000번 동심원 방식으로 회전한다. (72,000 RPM)sub motor == arm assembly: sub motor는 제자리에서 arm과 head를 원하는 track까지 옮겨 놓는다. ➡️ 지연 시간 발생head: head의 끝 부분에 자석이 있다. 자기장을 이용하여 data를 읽고 쓴다.arm: arm의 맨 끝에 head가 있다. arm은 sub motor에 의해 움직인다.track: 하나의 platter 위에 spindle을 기준으로 반지름이 같은 구역이 있는데, 그것을 track이라 한다.sector: head가 data를 어느 순간 딱 읽어들이는데, 읽어들이는 물리적인 최소의 size를 sector라고 한다. (보통 500bytes ~ 1kbytes) 읽음cluster: sector들을 묶어서 최소 단위로 쓰는 경우를 cluster라고 한다.
(읽는 효율은 높아지지만, 시간적인 효율은 떨어짐)cylinder: 같은 위치에 있는 sector들을 cylinder라고 한다.- head가 6개 있고, platter도 6개 있다. sector 하나 당 1kBytes라고 하면,
동시에 6개를 읽어 들여 총 6kBytes를 읽을 수 있다.
이때, 읽어들인 sector들을 cylinder라고 한다.
- head가 6개 있고, platter도 6개 있다. sector 하나 당 1kBytes라고 하면,
평균 지연 시간:
{max(arm이 원하는 track으로 옮겨가는 시간 + 원하는 sector가 돌아오는 시간) + min(arm이 원하는 track으로 옮겨가는 시간 + 원하는 sector가 돌아오는 시간)} / 2- max(arm이 원하는 track으로 옮겨가는 시간) : 원하는 track이 platter의 가장 안쪽에 있는 경우.
- min(arm이 원하는 track으로 옮겨가는 시간) : 원하는 track이 platter의 가장 바깥쪽에 있는 경우.
- max(원하는 sector가 돌아오는 시간) : arm이 track에 도착했을 때,
원하는 sector가 방금 지나간 경우. - min(원하는 sector가 돌아오는 시간) : arm이 track에 도착하자마자,
원하는 sector가 온 경우.
- platter와 head는 물리적으로 떨어져 있다.
-
컴퓨터를 고장내는 가장 좋은 방법 : HDD를 툭툭 친다.
head와 platter가 물리적으로 아주 미세한 거리만큼 떨어져 있는데,
물리적 힘을 가함으로써 head가 sector를 긁게 한다.
마침 OS가 있는 곳에 bad sector가 나면, 컴퓨터를 제대로 고장낼 수 있다.
인터리브
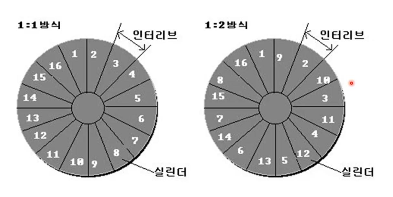
-
문제상황: head에서 sector를 읽고, 처리하고, 전송하고, bufffer 비우는 과정을 수행하는데,
Motor가 빨리 돌기 때문에 미처 다 처리하지 못한 채
다음으로 읽어야 할 sector가 돌아올 수 있다.- == motor가 돌아가는 시간보다 data를 처리하는 시간이 더 느릴 수 있다.
➡️ sector 1을 읽고 sector 2를 읽기 전에 sector 1에 대한 처리를 해야 하는데,
head가 이미 sector 2 자리에 왔다.
➡️ sector 2를 그냥 pass시키고,
한 바퀴 돌아 다시 sector 2가 head에 올 때까지 기다린다.
➡️ 매순간마다 한바퀴씩 rotation이 필요하다.
즉, 기다리는 시간이 오래 걸린다.
- == motor가 돌아가는 시간보다 data를 처리하는 시간이 더 느릴 수 있다.
-
인터리브: 인터리브는 위의 문제 상황을 해결할 수 있다.-
만약 sector가 돌아오는 속도와 이전 sector에서 data 처리하는 속도가 같다면
1 : 1 방식을 쓴다. -
만약 sector가 돌아오는 속도보다 이전 sector에서 data 처리하는 속도가 느리다면
1 : 2 방식을 쓴다.
1 : 2 방식은 sector 1을 읽고 바로 다음 sector를 2로 하지 않고, 3으로 한다. -
1 : 2 방식으로도 sector가 돌아오는 속도보다 data 처리하는 속도가 느리다면
1 : 3 방식을 쓴다.
1 : 3 방식은 sector 1을 읽고 바로 다음 sector를 2, 3로 하지 않고, 4으로 한다.더 좋은 방식은 없다.
현재 상황에 맞는 인터리브 방식을 선택하여 데이터 전송 속도 높일 수 있게 한다.
-
NAS & RAID
-
NAS(Network-Attached Storage): NAS는 Network를 통해 다양한 디바이스에서 파일 공유를 가능하게 해주는 저장장치.
NAS 기기에서 여러 개의 HDD를 구성하여 RAID를 사용할 수도 있다. -
RAID(Redundant Array of Inexpensive): RAID는 여러 개의 HDD를 하나의 논리적인 단위로 묶어서 하나의 논리적 디스크로 인식시키는 기술.- RAID 0 : 1TB 4개 ➡️ 진짜 4TB ➡️ 4개의 HDD가 하나이므로 고장나면 복구할 방법이 없다. (빠르지만 안전하진 않다)
- RAID 1 : 1TB 4개 ➡️ 1TB
(하나가 고장나면 나머지 1개의 데이터가 데이터를 복구 == 미러링) - RAID 4 : 1개의 HDD에 Parity bit 저장. 오류 정정 기능.
I/O Structure and DMA
-
우리가 쓰고 있는 모든 컴퓨터는
폰 노이만 구조시스템이다.
➡️ memory에 instruction과 data를 나누지 않는다.
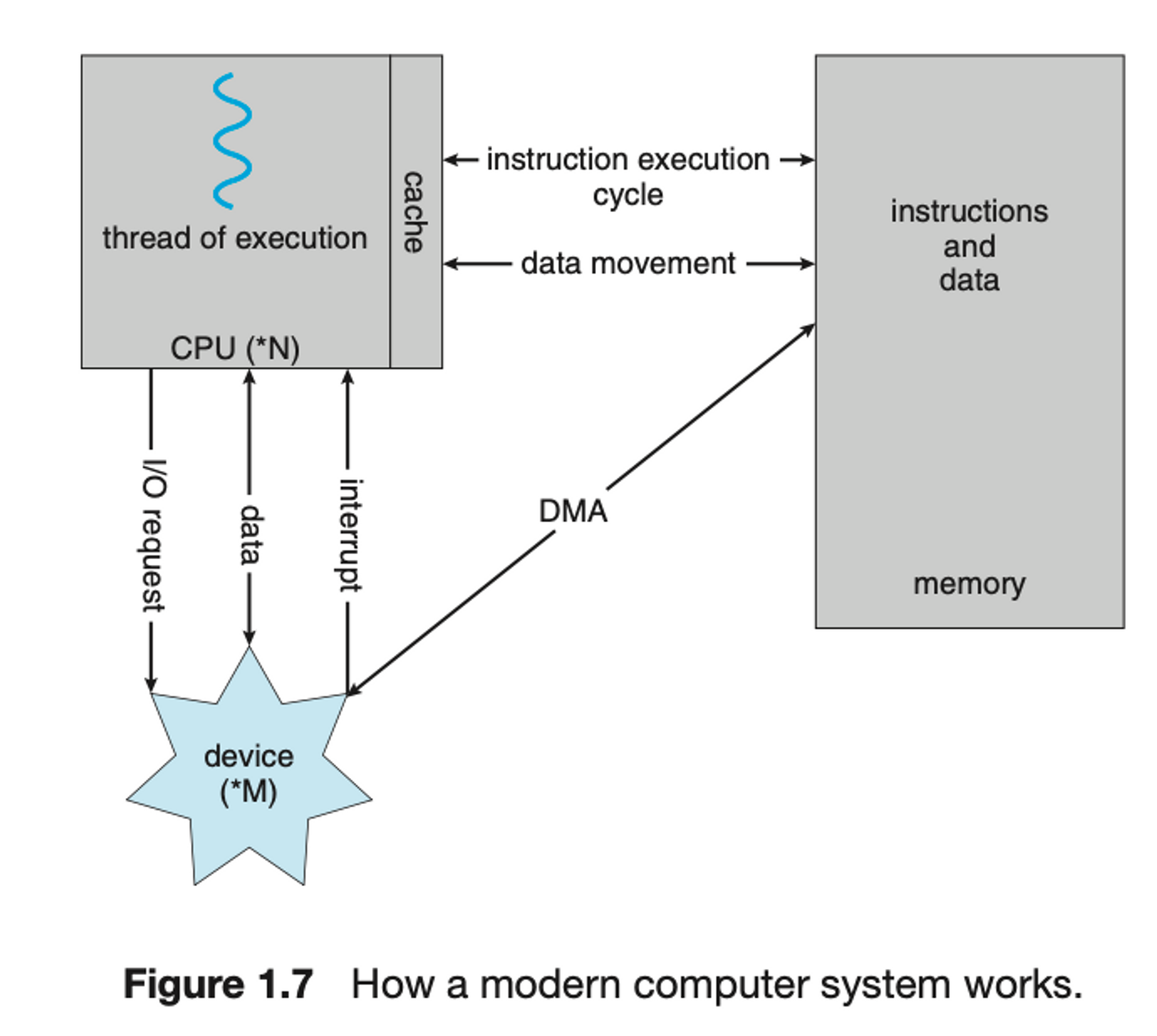
-
앞서 공부한 Interrupt 구동 I/O의 형태는 소량의 데이터를 이동하는 데는 좋지만,
NVS(보조기억장치) I/O와 같은 대량 데이터 이동에 사용될 때 높은 overhead를 유발함.
➡️ 이문제를 해결하기 위해DMA(Direct Memory Access)가 사용된다.
DMA는 I/O Device와 memory 사이에 직접 데이터 전송을 수행하는 장치이다. -
DMA- I/O Devcie가 CPU의 개입 없이 memory에 직접 데이터 전송을 수행하는 장치.
- Device에 대한 buffer 및 pointer, 입출력 count를 세팅한 후
Device Controller는 CPU의 개입 없이 자신의 buffer로부터 메모리로
데이터 block 전체를 전송한다. - 한 byte마다 interrupt가 발생하는 것이 아니라
block 전송이 완료될 때마다 interrupt가 발생한다.
➡️ Device Controller가 전송 작업을 수행하고 있는 동안
CPU는 다른 작업을 수행할 수 있다.
- I/O Devcie가 CPU의 개입 없이 memory에 직접 데이터 전송을 수행하는 장치.
-
Cycle Stealing- 그런데 CPU가 memory를 쓰고 있는데 어떻게 I/O Device가 memory에 데이터를 전송할까? ➡️
Cycle Stealing
CPU와 Memory가 데이터를 주고받는 동안, 당연히 DMA는 전송을 진행할 수 없다.
따라서 IO는 눈치보고 있다가 CPU 동작 시 메모리와 관계없는 Cycle에만
DMA의 수행을 하게 되는데, 이를 Cycle stealing이라고 한다.
즉, IO가 CPU의 Cycle을 도용한다.
- 그런데 CPU가 memory를 쓰고 있는데 어떻게 I/O Device가 memory에 데이터를 전송할까? ➡️
1.3 Computer-System Architecture
Multi-Processor System
- 현대 Computer System은 대부분 multi processor system이다.
이러한 시스템에는 단일 core CPU가 있는 두 개 이상의 processor가 있다.- CPU : 명령을 실행하는 HW
- processor : 하나 이상의 CPU를 포함하는 물리적 Chip
- Multi Processor : 여러 processor를 포함함
- Core : CPU의 기본 계산 단위
- Multi Core : 동일한 CPU에 여러 Core를 포함함
SMP (Symmetric Multi Processing)
- 가장 일반적인 Multi Processor System은
SMP를 사용한다.
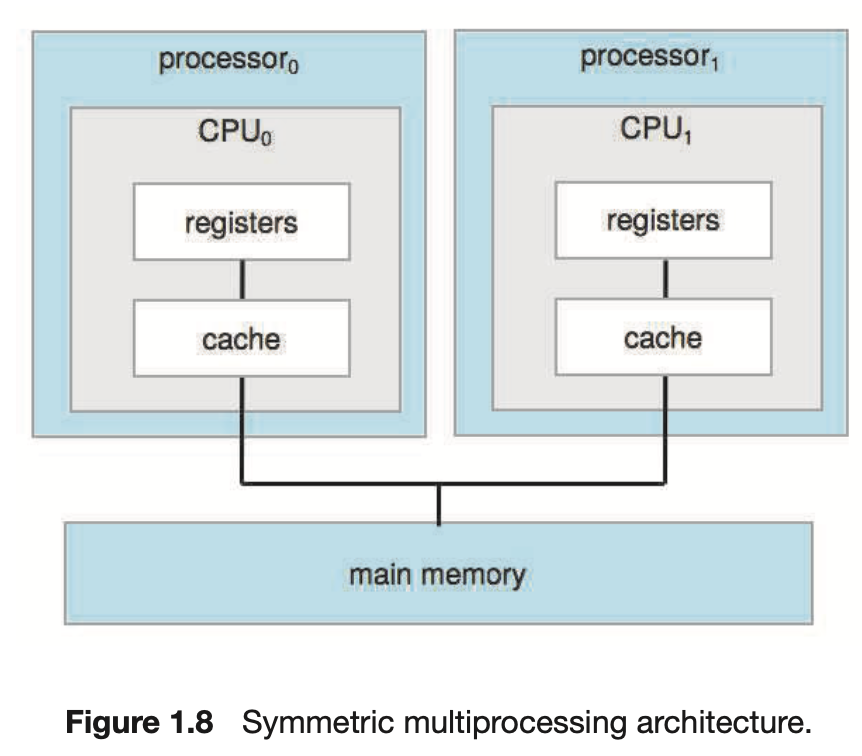
- 위의 그림은 각각 자체 CPU를 가지는 두 개의 processor가 있는 일반적인 SMP 구조이다.
- 각 CPU Processor에는 개별 Cache, Register set이 있다.
SMP의 장점은 여러 개의 프로세서가 하나의 메모리 공간을 공유하므로 각 프로세서는 다른 프로세서에서 처리한 데이터에 직접 접근하여 병렬처리가 가능하다는 것이다.하지만 여러 프로세서가 하나의 Main memory를 공유하므로 병목 현상의 문제가 발생할 수 있다.
NUMA (Non-Uniform Memory Access)
- SMP와 같이 CPU를 많이 추가하면 Bus에 대한 병목 현상 발생하여 성능이 저하될 수 있다.
그래서 각 CPU에게 local bus를 통해 access되는 자체 local memory를 제공하는 것이다.
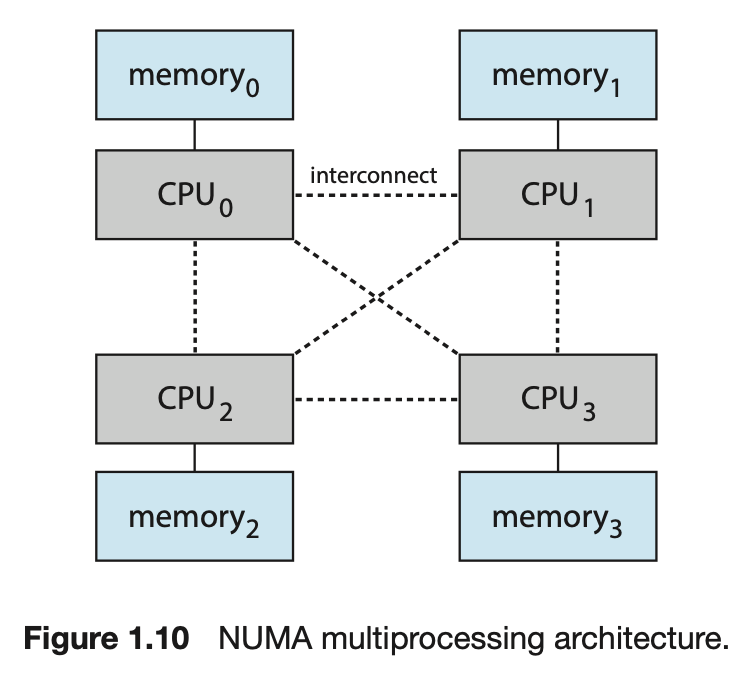
- 모든 CPU가 Shared System 연결로 연결되어
모든 CPU가 하나의 물리적 주소 공간을 공유한다. - NUMA system의
장점은 CPU가local memory에 access할 때 빠를뿐만 아니라
상호 연결에 대한병목 현상도 없다는 것이다. NUMA system의 단점은 CPU가 상호 연결을 통해원격 memory에 access해야 할 때,지연 시간이 증가하여 성능 저하가 발생할 수 있다는 것이다.
예를 들어, 는 자체 local memory에 access할 수 있는 만큼 빠르게 의 local memory에 access할 수 없어 성능이 저하된다.
- 모든 CPU가 Shared System 연결로 연결되어
Multi-Core System
Multi-Processor System의 정의는 시간이 지남에 따라 발전해 왔으며
이제는 여러 개의 Core가 단일 칩에 상주하는Multi-Core System을 포함한다.- 칩 내 통신이 칩 간 통신보다 빠르므로
Multi-Core System은 단일 코어를 가지는 Multi 칩보다 효율적일 수 있다.
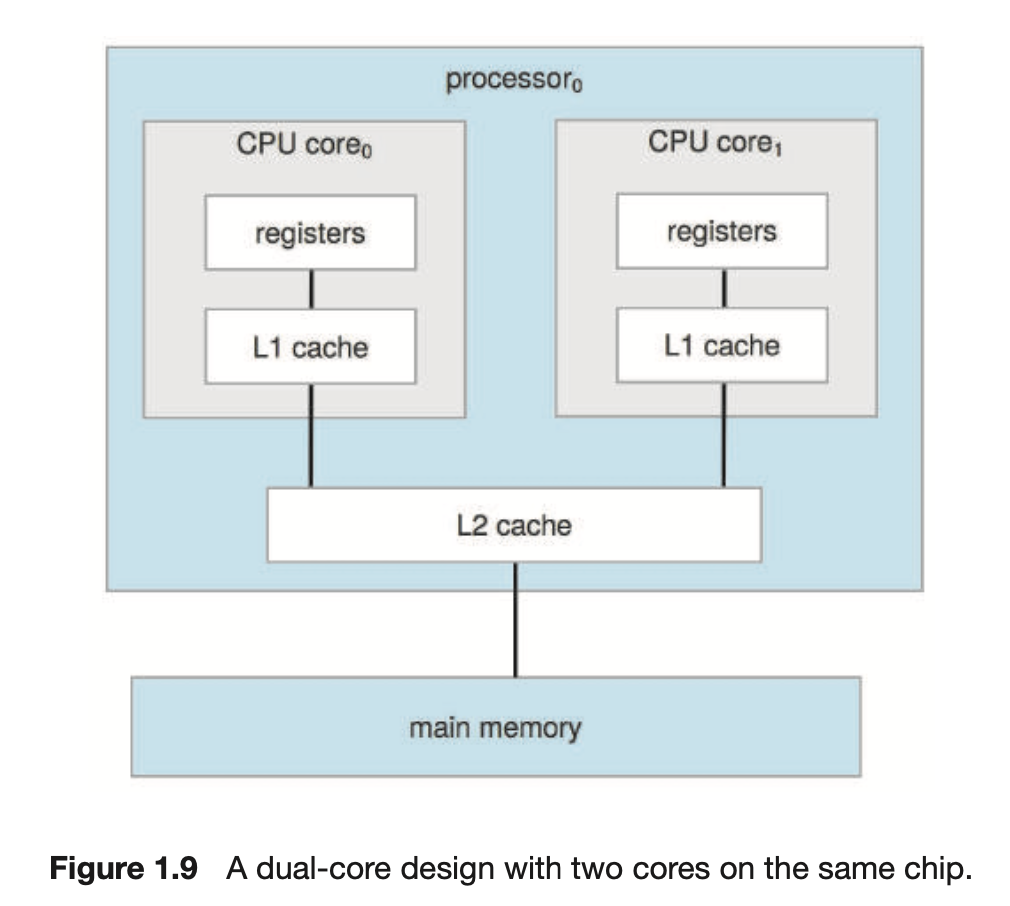
- 각 Core에는 자체 register set와 L1 Cache라고 하는 자체의 local Cache가 있다.
- 또한 L2 Cache는 칩에 국한되지만 두 처리 Core에서 공유한다.
- N Core를 가지는 Multi-Core Processor는 운영체제에 N개의 CPU처럼 보인다.
Clustered System
- 여러 CPU를 가진 시스템의 또 다른 유형으로 Clustered System이 있다.
- Clustered System은 둘 이상의 독자적인 시스템(컴퓨터)들을 연결하여 구성.
➡️ 컴퓨터 여러 개를 Clustering하여 각각의 컴퓨터를 하나의 CPU처럼 사용하여 효율을 높임 - Cluster Computer는 저장장치를 공유하고 LAN(근거리 통신망)으로 연결된다.
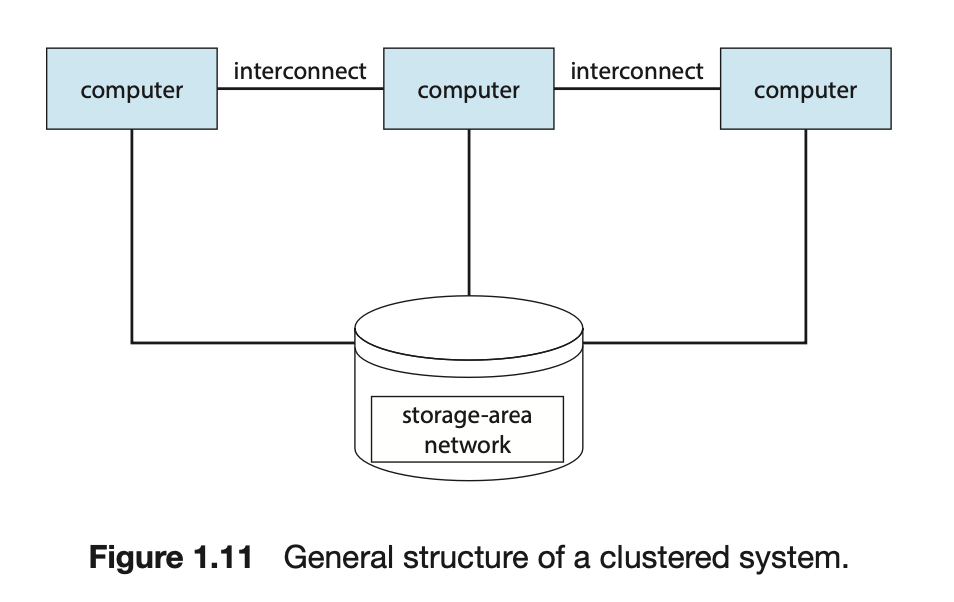
- Clustering은
높은 가용성(Availability)을 제공하기 위해 사용된다.
즉, Cluster 내의 하나 이상의 Computer가 고장나더라도 서비스는 계속 제공된다.
➡️ 각 Computer는 다른 Computer들을 감시한다.
만약 감시받던 Computer가 고장 나면,
감시하던 Computer가 고장 난 Computer의 저장장치에 대한 소유권을 넘겨받고`₩,
그 Computer에서 실행 중이던 응용 프로그램을 다시 시작한다. - Clustering은 asymmetric, symmetric으로 구성될 수 있다.
asymmetric clustering: 다른 Computer들이 응용 프로그램을 실행하는 동안 한 컴퓨터는 hot-standby mode(긴급대기모드) 상태를 유지한다.
이 hot-standby mode의 host는 활성 서버들을 감시하는 작업만을 수행한다.
서버가 고장 난다면 hot-standby mode의 host가 활성 서버가 된다.symmetric clustering: 둘 이상의 host들이 응용 프로그램을 실행하고 서로를 감시한다. 가용한 HW를 모두 사용하기 때문에 Symmetric Clustering 구성이 더욱 효율적이다.
- Cluster 기술은 급변하고 있다.
어떤 Cluster제품은 수 km 떨어진 cluster node들뿐 아니라 한 cluster 안에서 수 천개의 node를 지원한다.
이러한 개선은 Storage 전용 netowrk인SAN(Storage-Area Network)에 의해 가능해졌다.- LAN : LAN (Local Area Network)은 지리적으로 제한된 작은 지역(집, 사무실, 학교)에서 사용되는 컴퓨터 네트워크.
- WAN : WAN (Wide Area Network)은 지리적으로 넓은 지역(지역, 도시, 국가, 대륙)을 포함하는 네트워크. 인터넷과 같은 공공 네트워크를 포함하여 광범위한 지역에 걸쳐 컴퓨터, 서버 및 기타 장치를 연결하는 것.
- SAN : SAN (Storage Area Network)은 고성능 스토리지 장치에 대한 접근을 위해 구축된 네트워크.
- Clustering은
1.4 Operating-System Operations
-
Bootstrap Program:
컴퓨터를 실행시키기 위한 초기 프로그램.
운영체제 kernel을 찾아 memory에 load하는 단순한 코드.- mac에서는 여러 OS 설치가 가능한데,
bootstrap에 window? mac? linux? 어디로 갈지 선택할 수 있게 해주는
작은 프로그램을 bootstrap에 설치하여 Multi Booting이 가능해진다.
- mac에서는 여러 OS 설치가 가능한데,
-
kernel이 load된다. -
system daemon이 시작된다.
(system daemon은 운영 체제에서 백그라운드에서 실행되는 프로그램으로, 여러 가지 서비스를 제공한다) -
위 과정이 완료되면, 시스템이 완전히 부팅되고 어떤
event가 발생할 때까지 기다린다.- HW interrupt
- SW Trap : 오류(Divdision by zero, 유효하지 않은 memory 접근 등) 또는 system call로 인해 생성되는 SW interrupt
MultiProgramming VS MultiTasking
MultiProgramming
MultiProgramming(Batch System)은 여러 개의 프로세스를 동시에 메모리에 올리고,
여러 프로세스 중 하나의 프로세스를 선택하여(Job Scheduling) 실행시키는 OS의 기법이다.
➡️Batch System과 유사하다.- Job Scheduling : memory에 load된 Job들 중에 어떤 Job을 언제 실행할 것인지 결정하는 것.
- MultiProgramming System에서
실행 중인 program을Process==Job==Task라고 한다.
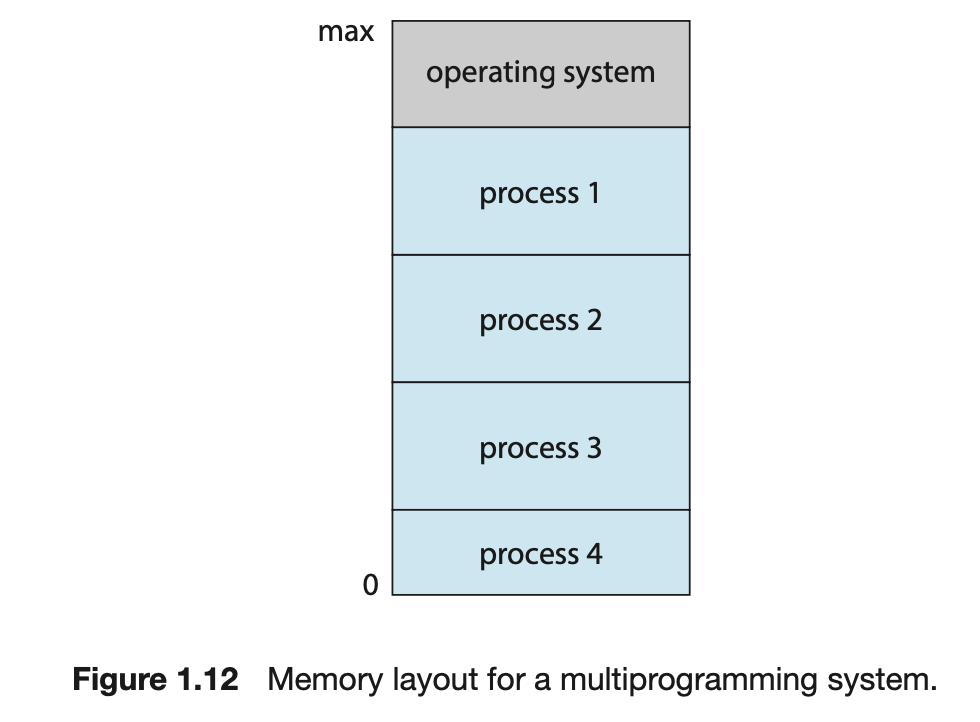
- 예를 들어,
Process 1이 실행 중에 대기해야하는 경우가 생긴다.
그러면 Process 2가 CPU를 쓰게 된다.
Process 1의 대기 상태가 풀리면, Process 1은 CPU를 돌려 받는다.
- 예를 들어,
MultiTasking
MultiTasking(==Time Sharing) System:
CPU가 CPU Schduling을 통해 여러 Process를 전환하며 실행하는 System.
➡️ 전환 시간이 매우 빨라서User에게 빠른 Response Time을 제공한다.
컴퓨터에서 '동시'란 없지만, 전환 시간이 매우 빨라서 Process가마치 동시에 처리되는 것처럼보이게 한다.- CPU Scheduling : memory에 Load된 Process들 중에서 우선순위나 작업량 등의 기준을 바탕으로 CPU를 할당받을 Process을 선택하는 것.
Swapping: Main memory에 load되는 process들이 너무 많아지면, Disk에 있는 memory와 main memory를 서로 바꾸는 것. 필요한 것을 main memory에 올리고, 불필요한 것은 disk memory로 내린다.
➡️ 이렇게 운영체제가 물리적 메모리(RAM)를 보조 저장장치인 HDD 등의 논리적 저장장치로 확장하여 사용하는 기술을Virtual Memory라고 한다.
Dual-Mode Operation
-
OS와 User는 Computer System의 HW 및 SW 자원을 공유하기 때문에
Computer System을 올바르게 관리하기 위해
자원들에 대하여 OS가 접근하려 했는지 User가 접근하려 했는지 구분할 수 있어야 한다. -
mode bit의 사용으로,
OS는 OS를 위하여 실행되는 작업과 User를 위해 실행되는 작업을 구분할 수 있다.Dual-Mode:
mode bit = 0 ➡️Kernel Mode == Privileged mode
mode bit = 1 ➡️User Mode
-
system boot 시, HW는 Kernel mode에서 시작한다.
이어 OS가 Load되고, User mode에서 User Process가 시작된다.
Trap(include System Call)이나 Interrupt가 발생할 때마다,
HW는 User mode에서 Kernel mode로 전환한다.
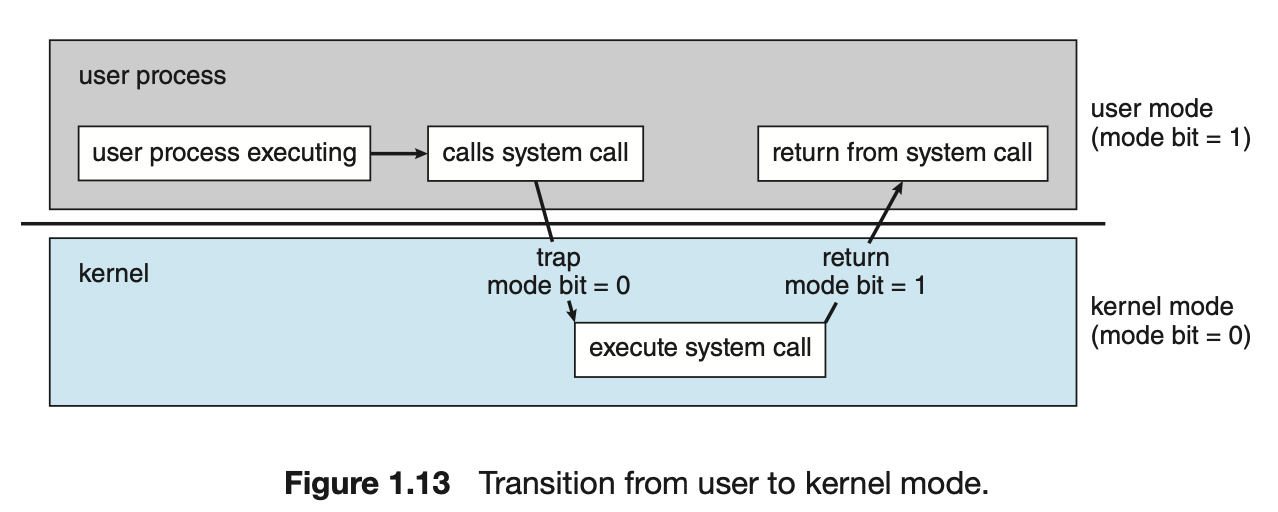
1.5 Resource Management
- OS는 Resource Manager이다.
시스템의 CPU, Memory Space, file-storage system, IO Device 등은 OS가 관리해야하는 자원에 속한다.
Process Management
-
Program은 CPU에 의해 명령이 실행되지 않으면 아무것도 할 수 없다.
-
즉, 하나의 Program은 Disk에 저장된 파일의 내용과 같이 수동적(Passive) 개체지만,
Process는 다음 수행할 명령을 지정하는 Program Counter를 가진 능동적(Active) 개체이다.
➡️ Process는 CPU, 메모리, 데이터 등과 같은 자원을 가지고 일을 수행,
일 끝나면 자원을 반드시 반환 해야함. -
Thread는 하나의 Process 내에서 실행되는 작은 실행 단위이다.
즉, 하나의 process 내에서 여러 개의 thread가 동시에 실행될 수 있다.
(Thread는 Chapter 4 에서...) -
OS는 Process Mangement에 대하여 다음과 같은 일을 한다.(Chap 3 ~ Chap 7)- User Process와 System Process의 생성과 제거
- CPU에 Process와 Thread Scheduling
- Process의 일시정지와 재수행
- Process 동기화를 위한 기법 수행
- Process 통신을 위한 기법 제공
Memory Management
-
main memory는 CPU와 I/O Device에 의하여 공유되는,
빠른 접근이 가능한 data repository이다. -
폰 노이만 방식의 컴퓨터에서는
CPU가 Instruction Fetch-Cycle동안 main memory로부터 명령어를 읽고,
Data Fetch-Cycle 동안 main memory로부터 data를 읽고 쓴다. -
Program이 수행되기 위해서는 반드시 절대 주소로 mapping되고, memory에 load되어야 한다.
-
CPU 이용률과 User에 대한 Reponse Time을 개선하기 위해,
우리는 Memory에 여러 개의 Program을 유지해야 하며,
이를 위해서 Memory Management 기법이 필요하다. -
OS는 Memory Mangement에 대하여 다음과 같은 일을 한다(Chap 9 ~ Chap 10)- memory의 어느 부분이 현재 사용되고 있으며, 어느 process에 의해 사용되고 있는지를 추적해야 한다.
- 필요에 따라 memory space를 할당하고 회수해야 한다.
- 어떤 process들을 memory에 적재하고 제거할 것인가를 결정해야 한다.
File-System Management
- OS는 저장장치의 물리적 특성을 추상화하여 논리적인 저장 단위인 파일을 정의한다.
OS는 파일을 물리적 매체로 mapping하며, 저장장치를 통해 파일에 접근한다. OS는 File-System Mangement에 대하여 다음과 같은 일을 한다.(Chap 13 ~ Chap 15)- 파일 생성 및 제거
- 디렉터리 생성 및 제거
- 파일과 디렉터리를 조작하기 위한 primitive의 제공
- 파일을 보조기억장치로 mapping
- 비휘발성 저장 매체에 파일을 백업
Mass-Storage Management
-
앞서 공부한 것처럼, Computer System은 main memory를 백업하기 위해
보조기억장치를 제공해야 한다. -
대부분의 최신 Computer System은 HDD와 NVM Device를 프로그램과 데이터 모두에 대한 주요 온라인 저장 매체로 사용한다.
- 온라인 저장 매체 : Computer System에서 직접 접근 가능하며 주로 데이터를 읽고 쓰는 데 사용되는 저장 매체.
즉, 컴퓨터가 작동하는 동안 데이터가 항상 사용 가능한 저장 매체. (HDD, SSD, Flash)
- 온라인 저장 매체 : Computer System에서 직접 접근 가능하며 주로 데이터를 읽고 쓰는 데 사용되는 저장 매체.
-
OS는 보조기억장치 관리와 관련하여 다음과 같을 일을 한다.- mounting, unmounting
- 사용 가능 공간(free-space) 관리
- 저장장소 할당
- Disk Scheduling
- 저장장치 분할
- 보호
Cache Management
-
정보는 통상 main memory와 같은 저장장치에 보관된다.
정보가 사용됨에 따라, 더 빠른 장치인 Cache에 일시적으로 복사된다.
그러므로 우리가 특정 정보가 필요할 경우, 우리는 먼저 Cache에 그 정보가 있는지를 조사해야 한다.
만약 Cache에 있으면 우리는 그 정보를 Cache로부터 직접 사용하면 되지만,
Cache에 없다면 main memory system으로부터 그 정보를 가져와서 사용해야 하며,
이 때 이 정보가 다음에 곧 다시 사용될 확률이 높다는 가정 하에 Cache에 넣는다. -
자기 디스크에 있는 file B에서 변수 A의 값을 1 증가시키는 상황.
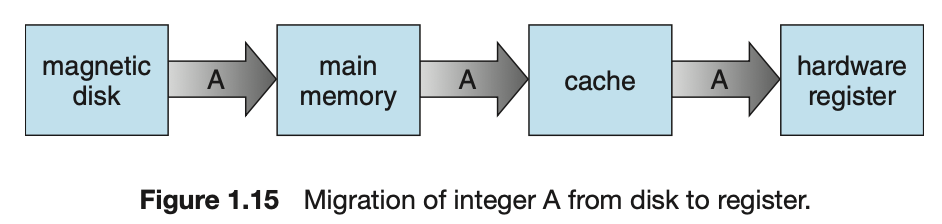
- 변수 A가 있는 HDD Block을 Main memory로 복사
- A를 Main memory에서 Cache로 복사
- A를 CPU 내부 register로 복사하여 +1 연산 수행.
- 연산 결과를 main memory에 반영한 뒤, HDD에 다시 저장.
1.6 Security and Protection
- Chapter 16, 17에서 자세한 내용.
1.7 Virtualization
-
Chapter 18에서 자세한 내용.
-
Virtualization(가상화)는 특정 CPU를 위해 compile된 OS가 동일 CPU용의 다른 OS 내에서 수행된다. -
Virtual Machine(가상머신)의 사용자는 다양한 OS 간을 전환할 수 있다. -
Emulation은 소스 CPU 유형이 대상 CPU 유형과 다른 경우에 해당 시스템의 작업을 수행할 수 있도록 사용된다.
Windows OS에서 실행되는 SW를 Mac OS에서 실행하기 위해 Windows Emulation을 사용할 수 있다.
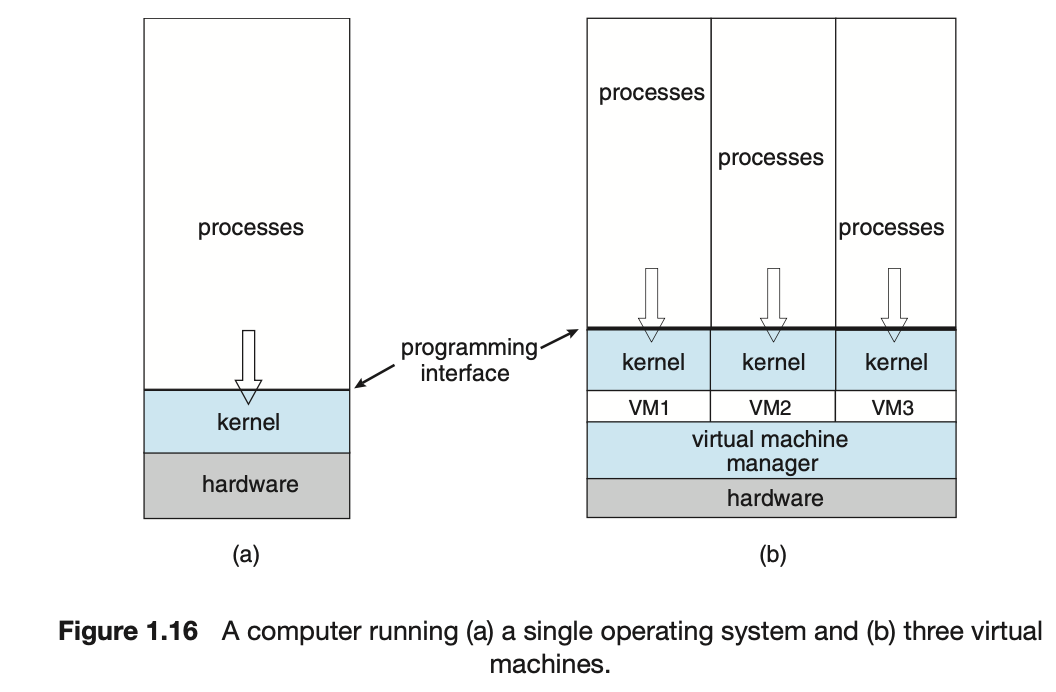
1.8 Distributed Systems
- Chapter 19에서..
1.9 Kernel Data Structures
- list, stack, queue
- Tree
- Hash and Maps
- Bitmap
1.10 Computing Environments
Traditional Computing
-
오늘날 웹 기술이 Traditional Computing 기술의 경계를 확장하고 있다.
-
회사들은 자신의 내부 서버에 웹 접근을 제공하는 Portal을 구현하고 있다.
-
Network Computer(=thin client)
-
Wireless network
-
Home Computing Environment는 방화벽(firewall)을 갖고 있다.
Mobile Computing
- Apple iOS
- Google Android
Client-Server Computing
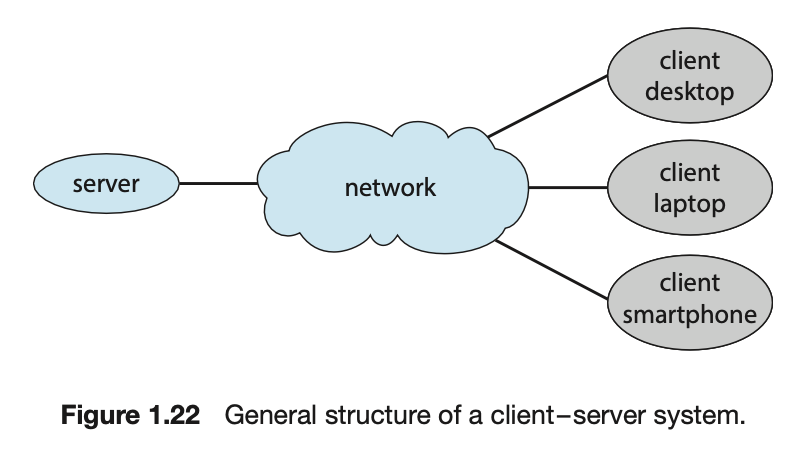
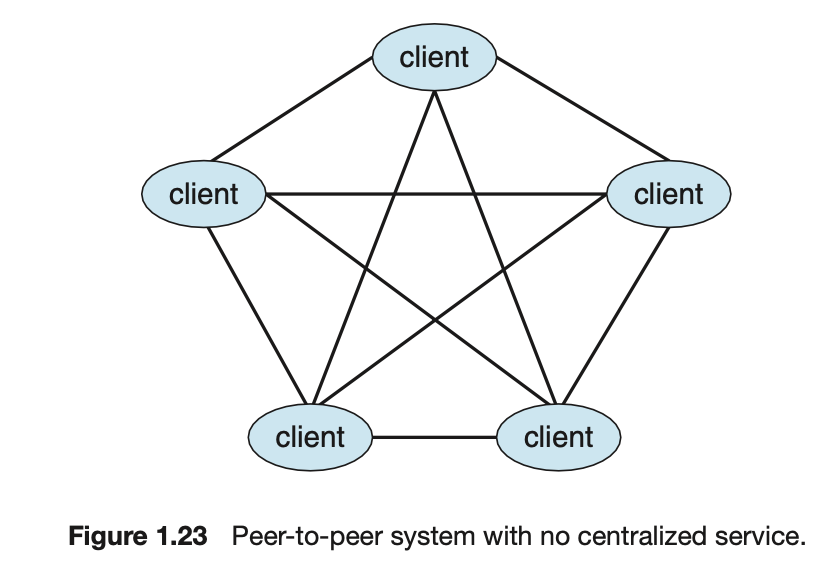
Peer-to-Peer Computing
- 이 모델은 Client와 Server가 서로 구별되지 않는다.
대신 시스템 상의 모든 노드가 Peer로 간주되고 각 Peer는 Service를 요청하느냐 제공하느냐에 따라 Client 및 Server로 동작한다.
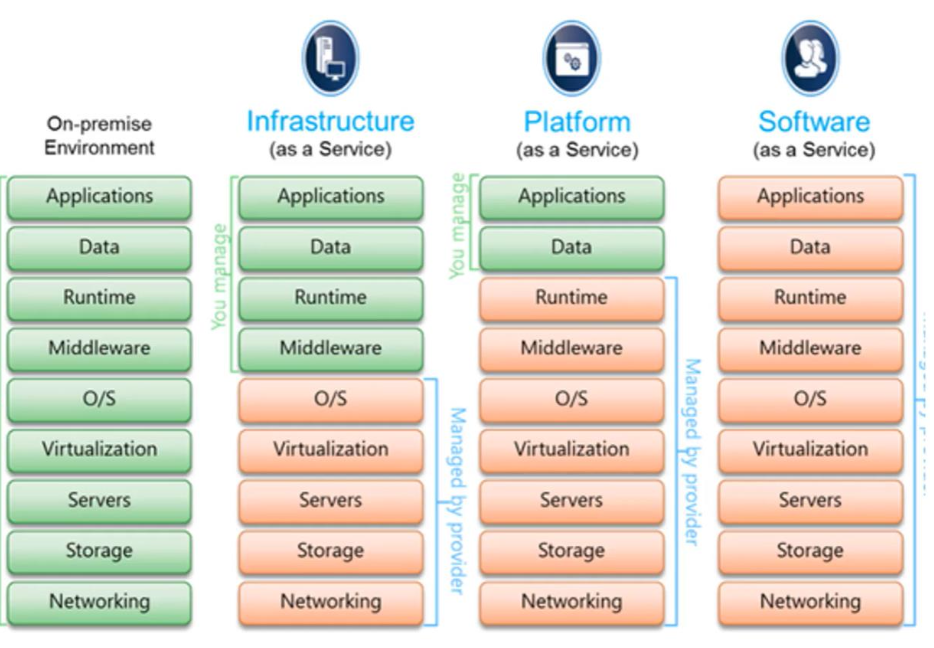
Cloud Computing
- Cloud Computing은 계산, 저장장치는 물론 응용조차도 network를 통한 서비스로 제공하는 Computing 유형이다.
- Cloud Computing은 Virtualization의 논리적 확장이다.
- Cloud Computing에는 다양한 유형이 존재한다.
Public Cloud: Service를 위해 지불 가능한 사람은 누구나 인터넷을 통해 사용 가능한 CloudPrivate Cloud: 한 회사가 사용하기 위해 운영하는 CloudHybrid Cloud: Public, Private 부분을 모두 포함하는 CloudSaaS(Software as a Service): 인터넷을 통해 사용 가능한 하나 이상의 응용 프로그램Paas(Platform as a Service): 인터넷을 통해 사용하도록 응용 프로그램에 맞게 준비된 SW stack(ex. DB server)Iaas(Infrastructure as as Service): 인터넷을 통해 사용 가능한 Server나 저장장치(ex. 생산 data의 backup 복사본을 만들기 위한 저장장치. AWS, Azure)
Real-Time Embedded System
Hard Real-Time: 시스템의 작업이 정해진 시간 내에 완료되어야 하는 경우를 말한다.Soft Real-Time: 시스템의 작업이 정해진 시간 내에 완료되어야 하지만, 이 시간 제약 조건이 엄격하지 않은 경우를 말한다.
Summary
-
OS는 Computer HW를 관리하고 응용 프로그램 실행 환경을 제공하는 SW이다.
-
Interrupt는 HW가 OS와 상호 작용하는 주요 방법이다.
HW Device는 CPU에 신호를 보내 Interrupt를 trigger하여 일부 event에 주의가 필요하다는 것을 CPU에 경고한다.
Interrupt는 Interrupt Handler에 의해 관리된다. -
Computer가 Program을 실행하려면 Program이 Main Memory에 있어야 한다.
이 Main Memory는 Processor가 직접 access할 수 있는 유일한 저장장소이다. -
Main Memory는 Non Volaitle Memory(NVM)이다.
-
NVM은 Main memory의 확장이며, 대량의 data를 영구적으로 보유할 수 있다.
-
가장 일반적인 NVM은 program과 data를 모두 저장할 수 있는 HDD이다.
-
Computer System의 다양한 저장장치 시스템은 속도와 비용에 따라 계층 구조로 구성할 수 있다.
레벨이 높을수록 비싸지만 속도가 빠르다.
계층이 내려갈수록 일반적으로 비트당 비용은 감소하고 반면 access 시간은 증가한다. -
최신 Computer Architecture는 각 CPU에 여러 Computing Core가 포함된 Multi Processor System이다.
-
CPU를 최대한 활용하기 위해 최신 OS는 Multi Programming을 사용하여
여러 작업을 동시에 memory에 load할 수 있으므로 항상 CPU가 실행할 작업이 있게 보장한다.(Idle 상태가 없도록) -
Multi Tasking은 CPU 알고리즘이 process 간에 빠르게 전환하여
User에게 빠른 Response Time을 제공하는 Multi Programming의 확장이다. -
User Program이 System의 올바른 작동을 방해하지 않도록 System HW에는
User mode와 Kernel mode로, Dual Mode가 있다. -
다양한 명령어가 특권을 가지며 Kernel Mode에서만 실행될 수 있다.
예를 들어 Kernel Mode로 전환하는 명령, I/O 제어, 타이머 관리 및 Interrupt 관리가 이러한 명령어들이다. -
Process는 OS의 기본 작업 단위이다.
Process Management에는
Process 생성 및 제거, Process 간 통신 및 동기화 기법 등이 포함된다. -
OS는 사용 중인 Memory Space와 사용 중인 Process를 추적하여 memory를 관리한다.
또한 Memory Space를 동적으로 할당하고 해제해야 한다. -
저장장치 공간은 OS에서 관리한다. 이러한 일에는 file 및 directory를 나타내는
File System을 제공하고 대용량 저장장치의 공간을 관리하는 것이 포함된다. -
Virtualization에는 Computer HW를 여러 가지 실행 환경으로 추상화하는 작업이 포함된다.
-
Computing Environment는
Traditional Computing, Mobile Computing, Client-Server System, Peer-to-Peer System, Cloud Computing, Real-time Embedded System을 포함한 다양한 환경에서 이루어진다.
연습 문제
-
OS의 3가지 주요 목적?
- Execute user programs and make solving user problems easier
(User Program을 실행시키고, User Problem을 쉽게 해결할 수 있도록 한다.) - Make the computer system convenient to use.
(Computer System을 사용하기 쉽도록 한다.) - Use the computer HW in an efficient manner
(HW를 효율적으로 사용할 수 있게 한다.)
- Execute user programs and make solving user problems easier
-
Computing HW를 효율적으로 사용하려면 OS가 필요하다고 강조하였다.
OS가 이 원칙을 버리고 자원을 낭비하는 것이 적절한 때는 언제인가?
그러한 시스템이 실제로 낭비하는 것이 아닌 이유는 무엇인가?- 자원을 낭비하는 것이 적절한 때는
'시스템의 안정성을 유지하기 위해 자원을 예비로 두는 경우',
'특정 프로세스나 애플리케이션을 빠르게 실행하기 위해 미리 자원을 할당하는 경우'이 다.
이러한 자원 예비 또는 미리 할당 등의 작업은 일시적인 것이며,
시스템의 효율성을 개선하기 위한 것이기 때문에 이러한 작업이 지속적으로 이루어지 는 것은 아니며,
일시적인 자원 낭비로 인해 전체적인 시스템 성능에 부정적인 영향을 끼치지 않는다.
- 자원을 낭비하는 것이 적절한 때는
-
실시간 환경을 위해 운영체제를 작성할 때 프로그래머가 극복해야 하는 주요 어려움은 무엇인가?
- 실시간 시스템에서는 작업을 정해진 시간 내에 처리해야 하므로,
시간 제약을 준수하도록 운영체제를 설계해야 한다. - 여러 프로세스나 스레드가 동시에 작업을 수행하므로, 이들 간의 동기화 문제를 해결해야 한다.
이를 위해 운영체제는 적절한 동기화 기법을 사용하여 공유 자원에 대한 접근을 제어합니다.
- 실시간 시스템에서는 작업을 정해진 시간 내에 처리해야 하므로,
-
커널 모드와 사용자 모드의 구별은 기본적인 형태의 보호로서 어떤 기능을 수행하는 가?
- 사용자 모드에서 실행되는 코드가 하드웨어 자원에 직접 접근할 수 없도록 보호한다.
따라서 프로그래머는 system call을 이용하여 사용자 모드에서 커널 모드로 전환하 여 원하는 OS의 서비스를 제공받는다.
- 사용자 모드에서 실행되는 코드가 하드웨어 자원에 직접 접근할 수 없도록 보호한다.
-
Cache가 유용한 두 가지 이유를 제시하라.
어떤 문제를 해결할 수 있는가?
어떤 문제를 야기하는가?
Cache의 크기를 Caching하는 장치만큼 크게 만들 수 있다면 Cache의 용량을 늘린 후 원래 장치를 제거하지 않는 이유는 무엇인가?- Cache가 유용한 두 가지 이유
- Cache는 CPU가 가장 자주 access하는 data를 저장하므로,
CPU가 이전에 access한 data를 다시 로드할 때 memory에 access할 필요가 없어진다.
이렇게 되면, Cache에서 데이터를 읽는 것이 더 빠르고 효율적이므로 시스템 성능이 개선된다. - Cache는 memory보다 낮은 전력을 사용하므로, 전력을 아낄 수 있다.
-
Cache는 다음의 문제를 야기한다.
일관성 문제: CPU는 Cache된 data가 memory의 최신 data와 동기화되어 있는지 확인해야 한다.
그렇지 않으면 CPU가 Cache된 과거 data를 사용하면서 예상치 못한 결과를 초래할 수 있다. -
Cahce의 크기를 크게하지 못하는 이유
- Cache의 가격은 비싸기 때문에 용량을 늘리는 것은 큰 추가 비용이 발생.
- 큰 Cache는 새로운 data를 load할 때 일관성을 유지하는 것이 더 어려울 수 있다. 일관성 문제를 해결하는 데 더 많은 리소스가 필요하게 된다.
-
분산 시스템의 Client-Server System과 Peer-to-Peer System의 차이를 설명하라.
- Client-Server System에서
Server는 중앙 집중식으로 데이터를 관리하며, Client는 Server에 의존하여 작업을 수행한다. - Peer-to-Peer System은 모든 구성원이 동등한 지위를 가지고 서로 연결된 형태로 구성된다. 모든 구성원이 자원을 공유하고 서로를 보완하여 작업을 수행한다.
- Client-Server System에서
