[Chap 3] Processes
Process Concept
The Process
-
program: 저장되어 있는 file 형태
program은 disk에 저장된 실행파일(prog.exe 또는 a.out)이다.
수동적인 개체이다. -
process: program이 실행가능한 상태로 memory에 상주하게 되면,
그때부터 OS가 Handling하게 되는 process라고 한다.
process는 다음에 실행할 명령어를 지정하는 Program Counter와 관련 자원의 집합을 가진
능동적인 개체이다.
(process == Job == Task) -
Batch System(일괄 처리 system): 여러 개의 program이 있더라도 한 번에 하나씩 순차적으로 수행하는 system -
Time Shared System(시분할 system): 여러 개의 program을 동시에 돌리는 system.
(많은 program들이 동시에 실행된다고 얘기하지만,
매순간 한 process에 한 명령만 실행이 된다. 너무 빨라서 동시인 것처럼 보이는 것.)
Process in Memory
-
"한 process를 실행한다"라고 하는 것은
일단 memory에 아래와 같은 block형태의 공간을 할당하는 것에서부터 시작한다. -
process의 memory 배치는 여러 section으로 구분되며, 다음과 같다.
(아래의 그림은 논리적 메모리이다. 물리적 메모리는 아니다. 물리적으로는 다 떨어져 있다.
물리적, 논리적 메모리 차이는 나중에 공부할 것이다...)
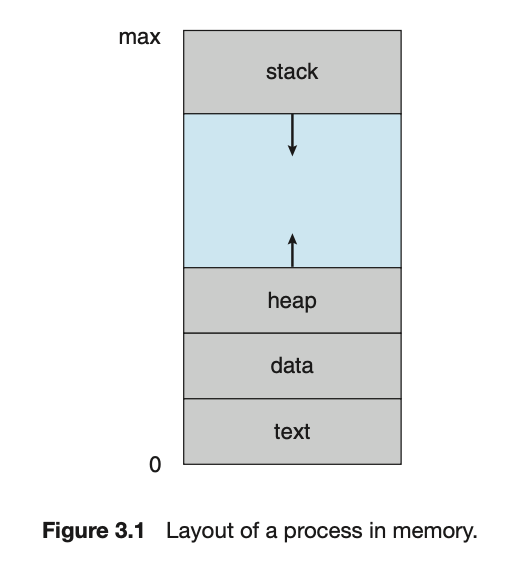
-
text section: 기계어 형태의 실행 code(소스코드의 형태가 아니다), 상수 -
data section: 전역변수(초기화된 변수, 초기화되지 않은 변수) -
heap section: Program 실행 중에 동적으로 할당되는 memory
100번지, 101번지, … 올라가는 방향으로 메모리를 관리. -
stack section: 함수를 호출할 때 Activation Record를 저장할 임시 저장장소
(Activation Record = 함수 매개변수, 복귀 주소 및 지역변수)
1000번지 999번지, … 내려오는 방향으로 메모리를 관리.
-
text section및data section은 Program 실행 중에 크기가 변하지 않는다. 고정이다. -
process의
text section도 memory 영역이니까 RAM의 어딘가에 있는 번지이다.
text section에는 기계어로 번역된 코드가 있다고 했는데,
그곳의 임의의 한 바이트의 값을 바꾼다면(바꿀 수 있도록 허용되었다면),
그것이 어떠한 영향을 미칠까?
이것은 program 자체가 바뀌었다는 것이다.
내가 원하는 동작이 아니라 다른 동작이 될 수 있다. (hacking)
따라서 OS는 process상태의 text section을 Read Only section으로 바꿔놓는다. (따라서 RAM에 올라가 있다고 해서 모두 변경 가능한 것은 아니다.) -
process가 되기 전인 program 상태에 있으면 소스코드를 바꿀 수 있다.
따라서 변경된 program이 process에서 돌아가는 순간,
내가 원래 갖고 있던 program이 아닌 다른 program으로 동작하게 된다.
내 눈에는 잘 흘러가는 것처럼 보이지만 내부에서는 다른 일을 하고 있을 수 있다.
== 이러한 것이 virus, 랜섬웨어의 원리이다.
-
요즘 나오는 OS들은 사용자가 만들어서 쓰는 Application까지는 보호하지 못하지만,
자신의 system file은 전체의 hash code를 갖고 있어서
실행될 때, 원래의 hash값과 비교하여 내용과 크기를 안전하게 유지시킬 수 있다. -
heap 및 stack section은 Program 실행 중에 동적으로 줄어들거나 커질 수 있다.
heap과 stack section이 실행 중에 너무 많이 할당된다면, Overflow 발생. -
heap section은 하위 메모리 번지에서 올라가고,
stack section은 상위 메모리 번지에서 내려와서
memory를 효율적으로 사용할 수 있다.
-
1. Example of C Program
- 아래의 C program을 compile하고 loading해서 memory에 올린다.
memory의 관점에서 보자.
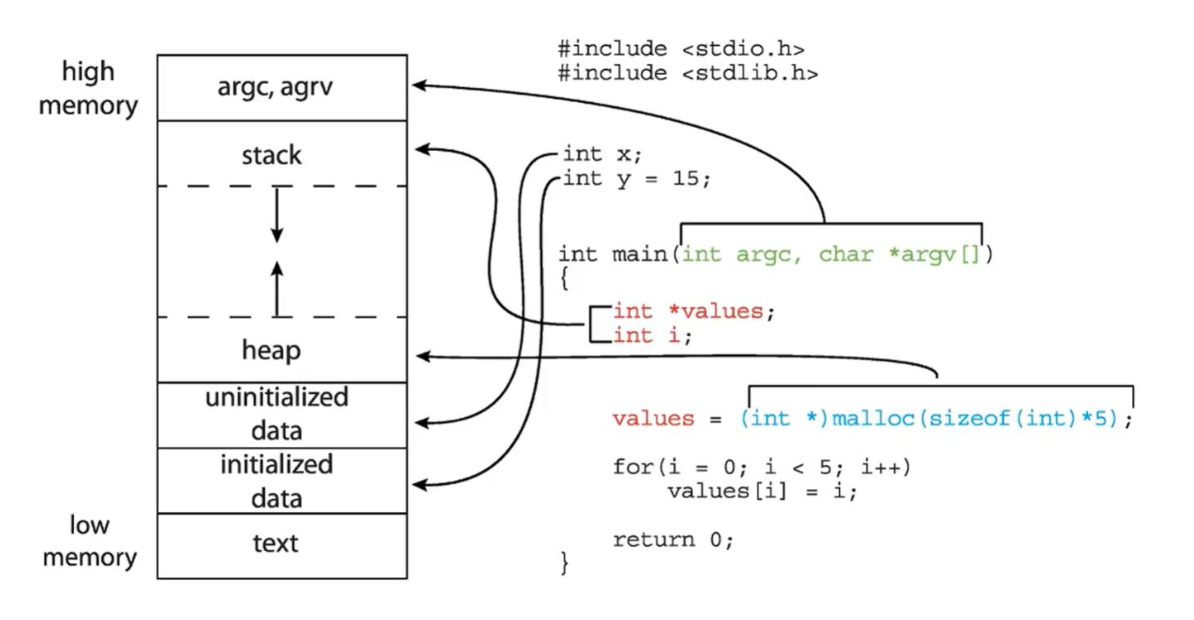
text section에는 기계어로 번역된 위의 program 코드가 들어간다.data section에는 initialized된 전역변수 와 uninitialized된 변수 가 각각 따로 나뉘어진다.heap section에는 동적으로 메모리를 할당받은 변수 values가 들어간다.stack section에는 main함수의 지역변수인 가 들어간다.
main 함수는 argument가 항상 3개 존재한다.
(argument 개수(argc), 내용(argv), 환경변수)
위 argument들은 항상 지역변수의 시작 변수가 되므로 stack의 처음 section에 넣는다.
2. Example of C program (중요)
- 다음의 program은
문법적 오류가 없고, 실행이 잘 되는가?
문법적 오류가 없지만, 실행이 잘 안되는가?
문법적 오류가 있는가?
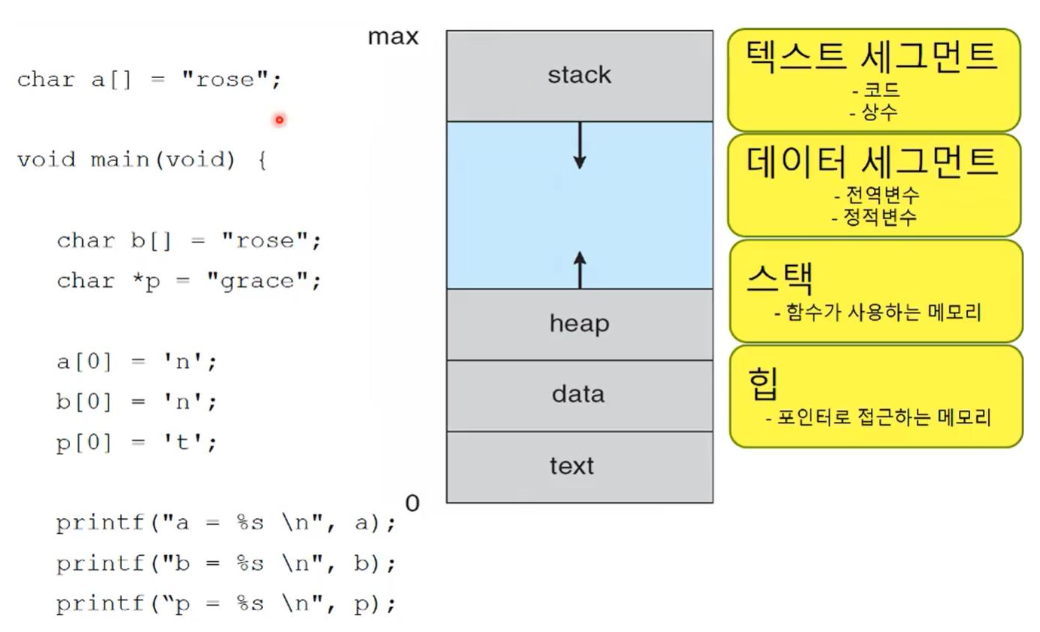
program의 의도는
a가 "rose"였는데, "nose"로 바뀌고
b도 "rose"였는데, "nose"로 바뀌고
c는 "grace"였는데, "trace"로 바뀌는 것을 희망하는 것 같다.
과연 그렇게 출력될 것인가?-
"" ➡️ Compiler는 큰 따옴표들을 모두 상수로 취급하여 text section에 보낸다.
그리고 나서 나중에 필요에 의해 다른 section으로 보내준다.
그래서 "rose\n"와 "grace\n"는 모두 text section에 저장된다.
나중에 "rose\n"를 a와 b에 할당하는 것이다.
또한 printf()의 ""가 3개 있는데, 그것들도 일단 모두 text section에 저장된다. -
char a[]의 a는 상수(포인터 상수)이다.
text section에 있는 "rose"가 1개 복사돼서 a 배열에 저장이 된다.
a는 전역변수이고, 초기화가 되었기 때문에
a는 data section의 initialized section에 들어간다.
따라서 a의 "rose"는 data section의 initialized section에 만들어진다.
➡️ text section의 "rose"는 그대로 있고,
복사만 되어 data section의 initialized section에 a의 "rose"가 만들어진다. -
char b[]의 b(포인터 상수)도 똑같은데, 지역변수이기 때문에
➡️ text section의 "rose"는 그대로 있고,
복사만 되어 stack section에 b의 "rose"가 만들어진다. -
char* p는 포인터 변수이고, 지역변수이기 때문에 stack section에 있다.
p는 포인터 변수이기 때문에 "grace"를 복사해오는 것이 아니라,
p는 text section에 있는 "grace"를 가리킨다.
가리키는 것이 "grace"인데, "grace"는 text section에 있다.
text section은 process상태인 경우, OS가 Read Only로 변경한다고 했다.
따라서 p가 가리키는 곳은 Read Only인 text section이고,
그 곳의 'g'를 't'로 바꾸려고(Write) 하고 있기 때문에
문법적 오류는 없지만, program이 죽어버린다.
(배열 a, b는 text section에 있는 "rose"를 복사해와서 자기가 가지고 있는데,
포인터 p는 text section에 있는 "grace"를 갖지 못하고 가리킨다.
이것이 배열과 포인터의 가장 큰 차이점이다.)따라서 Complie error는 안나지만, 동작은 안한다.
실행시키면 program이p[0] = 't';에서 죽는다.
왜냐하면 p가 가리키는 "grace"는 text section에 있고,
text section은 Read Only section이기 때문에 Write하지 못하기 때문이다.
-
Process State
- process는 실행되면서 그 상태(state)가 변한다. process의 state 종류는 다음과 같다.
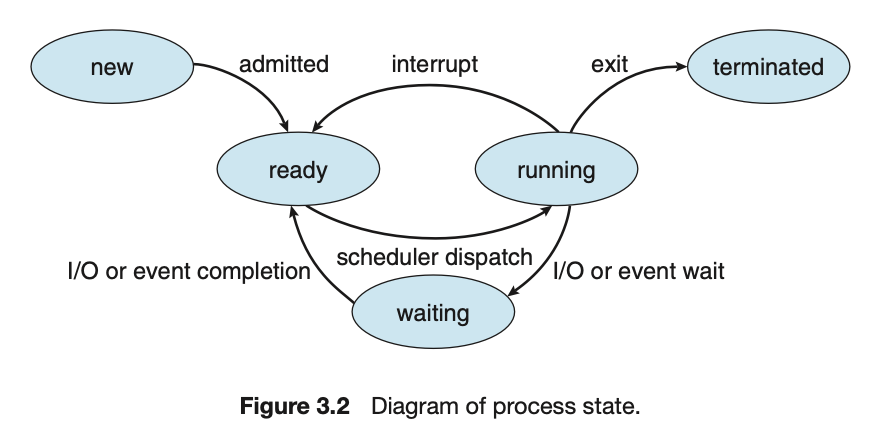
new: process가 생성 중이다.running: 명령어들이 실행되고 있는 상태 == CPU를 차지하고 있는 상태.
(수백 개의 process들 중에서 하나의 process만 running되고 있다)ready: 실행될 준비가 되어 CPU에 할당되기를 기다리는 상태.
process가 만들어지면 무조건 ready로 감.waiting: 어떠한 event(I/O, signal 등)가 일어나기를 기다리고 있는 상태. waiting이 끝날 때까지 CPU를 차지할 수 없다.terminated: process 실행이 종료된 상태. memory를 다 지워버리거나 쓰레기로 만든다.
- running state 중에 특정한 event(I/O request)가 생기면,
waiting state로 간다. - I/O 처리는 CPU가 하는게 아니라 Device Controller가 하기 때문에,
Device Controller가 I/O 처리를 끝낼 때 까지 기다린다.(waiting)
Device Controller가 I/O 처리를 끝내면 interrupt(I/O completion)를 보내어
Ready state로 간다. - running state에서 ready state로 천이되는 interrupt는 타이머, 예외 처리, system call과 같은 interrupt이다.
- running state 중에 특정한 event(I/O request)가 생기면,
Process Control Block
- 각 process는 OS에서 Process Control Block(PCB)에 의해 표현된다.
특정 process와 연관된 여러 정보를 수록하며, 다음과 같은 것들을 포함한다.
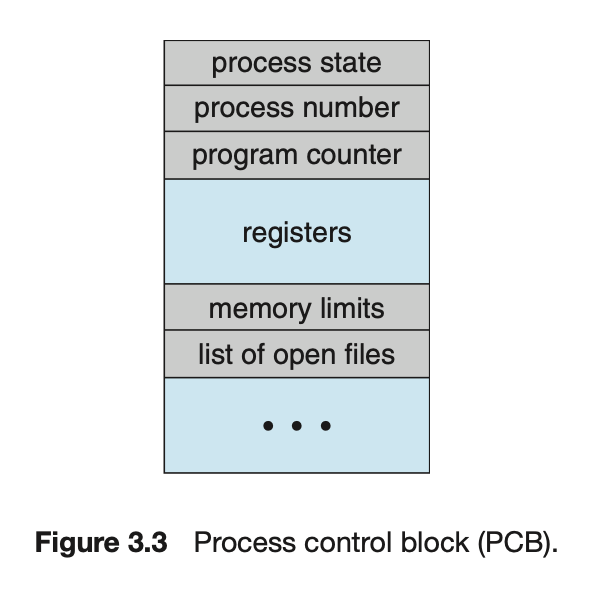
- process state : new, ready, running, waiting, terminated
- process number : process 고유 번호
- program counter : 해당 processr가 다음에 실행할 명령어의 주소
- registers : CPU register는 컴퓨터 구조에 따라 다양한 유형을 가진다.
일반적으로 register에는 누산기(accumulator), index register, stack register, general-purpose register, condition code 정보가 포함된다.
condition code는 나중에 process가 다시 시작될 때 계속 올바르게 실행되도록
하기 위해 interrupt 발생 시 저장되어야 한다. - memory limits : text, data , stack, heap section이
어디서부터 어디까지인지 알려주는 정보를 담고 있는 - list of open files :
...
여러가지 있다
PCB와 process memory(text, data, heap, stack) block만 있으면,
process 전체가 된다.
Context Switch
-
Context Switch : CPU를 차지하는 주체가 바뀐다.
(running state에 있는 process가 바뀐다) -
PCB는 Context Switch에 필요하다.
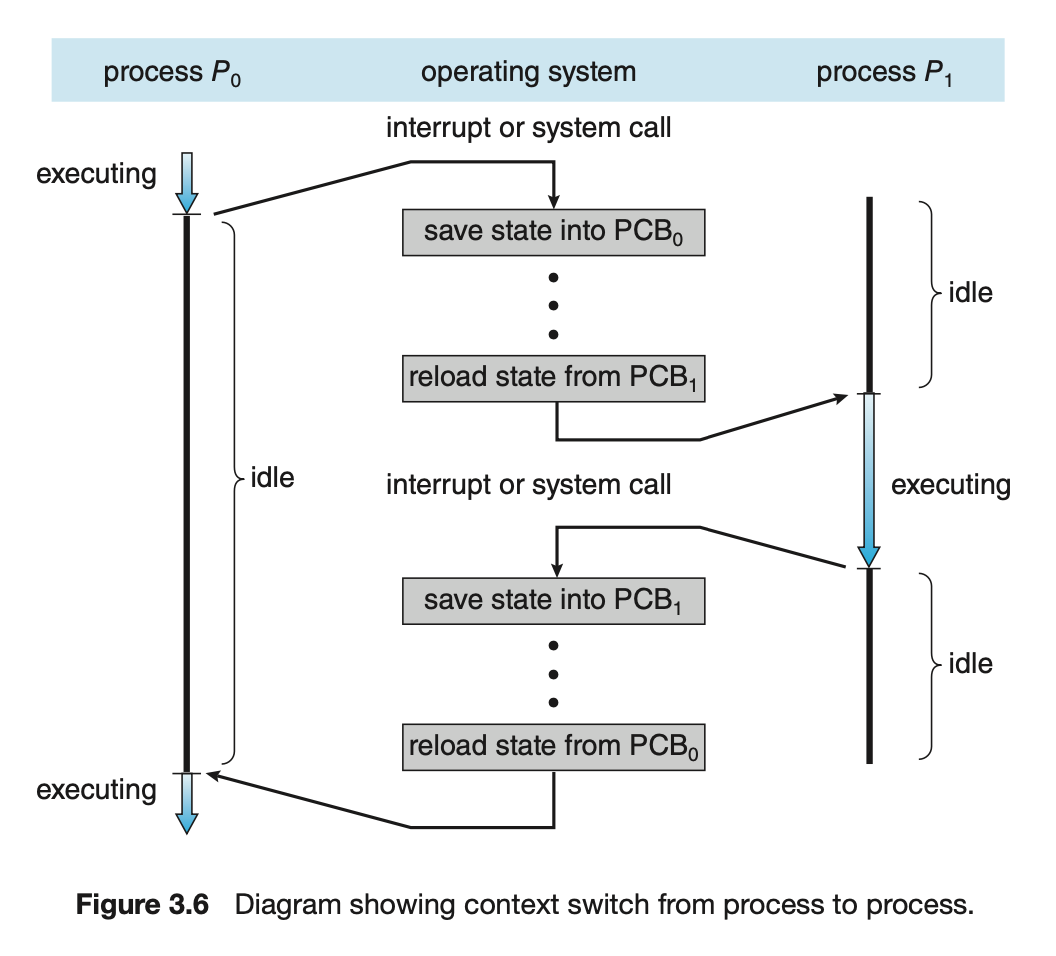
-
초기에 라는 process가 running state에 있었다.
는 ready state로 내려가고, 이 running으로 올라가려는 상황이다.
이럴 때, 어떤 일이 벌어져야 하는가?
-
가 running에서 ready state로 내려갈 때,
의 PCB를 저장해놔야 한다(Save).
Save 하는 데에 시간()이 걸린다그리고 나서 의 PCB를 Loading하여 실행시킨다.
또 다시 이 running으로 가야하는 경우,
의 PCB를 다시 Save하고
을 Reloading한다.... (반복)
-
이렇게 process를 Context switching하기 위해서는 PCB가 필수적이다.
Threads
(Chapter 4. 에서 자세히 공부...)
Process Scheduling
Process Sceduling: ready state인 process들 중에세
어떤 하나의 process를 골라 running state으로 올릴 것인지? 올린 거면 언제 올린 것인지?
running인 process를 ready로 언제 내릴 것인지?
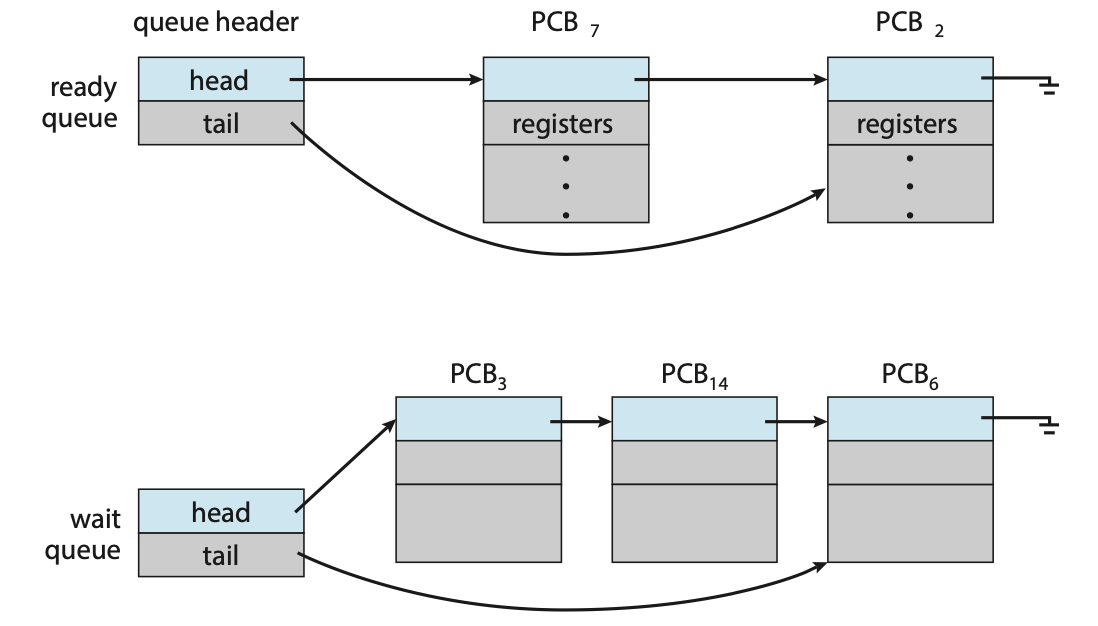
Ready and Wait Queue
-
process가 system에 들어가면
Ready Queue에 들어가서
ready state가 되어 CPU core에 실행되기를 기다린다. -
다음과 같이 queue는 일반적으로 Linked List로 저장된다.
-
그리고 I/O request와 같은 특정 event가 발생하기를 기다리는 process는
Wait Queue에 삽입된다. -
정리하면,
Ready Queue: CPU를 차지하기 위해 대기중인 process들
Wait Queue: I/O Device를 기다리는 process들
Representation of Process Scheduling
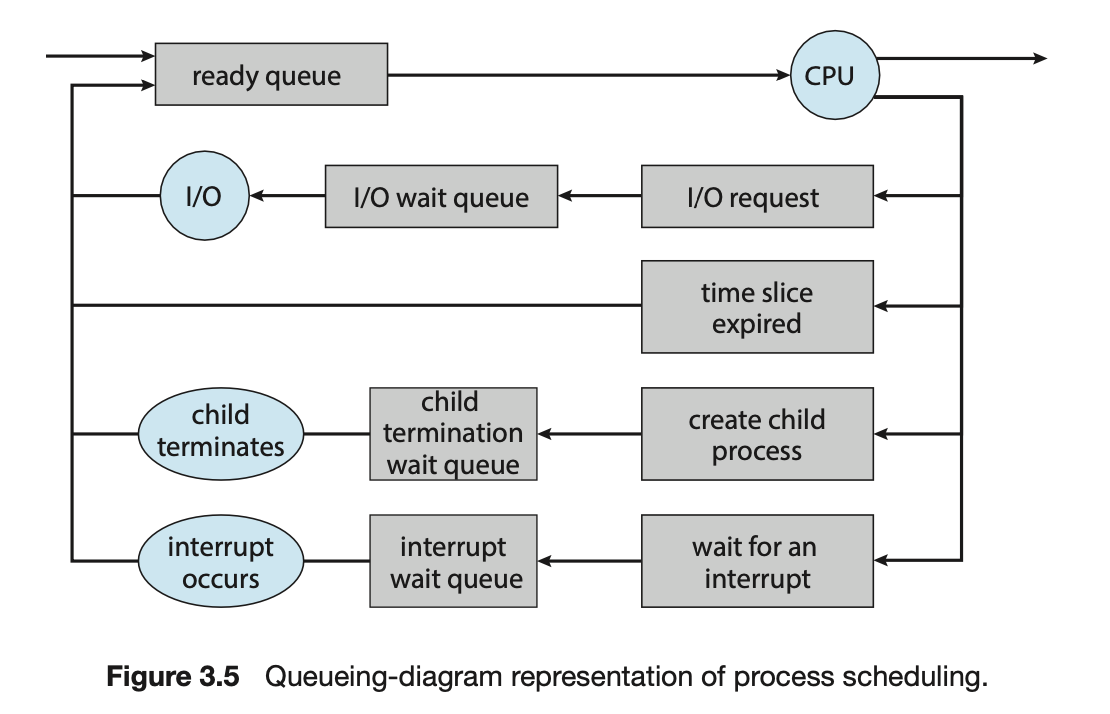
- CPU에서 빠져나가는 process : terminated state
- 끝나지 않은 것은 CPU에서 내려와서 다시 Ready Queue로 간다. (4가지 경우)
- I/O request를 해야 하는 경우
- 시간이 다 된 경우
- child process를 만들어서 child process의 종료를 기다려야 하는 경우
- interrupt를 기다려야 해서 내려오는 경우
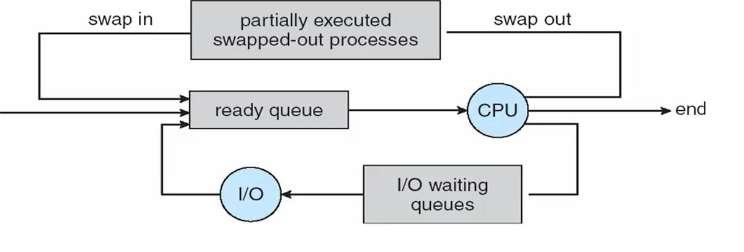
CPU Scheduler
-
CPU Scheduler는 ready queue에 있는 process 중에서 선택된 하나의 process에
CPU core를 할당하는 것이다.
-
Long-term scheduler:
어떤 process를 main memory에 올려야 할지를 정하는 scheduler.
(요즘 main memory는 용량이 크기 때문에 Long-term scheduler는 잘 쓰지 않는다.) -
Short-term scheduler:
어느 것을 main memory로 올리고, 어느 것을 HDD로 내릴 것인지 정하는 scheduler.
main memory로 올리는 것을
main memory에 올라와 있는 Process들 중에 어떤 process를 CPU에 할당할지 정하는 scheduler. -
Mid-term scheduler(chat 9에서 자세히..) :
어느 것을 main memory로 올리고, 어느 것을 HDD로 내릴 것인지 정하는 scheduler.
main memory로 올리는 것을 Swap in,
HDD로 내리는 것을 Swap out,
통칭하여 Swapping 이라고 한다.
대부분 Short-term scheduler로 올려서 관리하려고 하는데,
process가 너무 많아지면 main memory에 있는 상태로
HDD나 다른 저장메모리에 Dump형태로 저장한다.
main memory(GB 단위)가 아무리 커도 HDD(TB)나 SSD가 훨씬 용량이 크기 때문에
보조 메모리에 영역을 할당하여 마치 main memory처럼 사용한다.
이러한 기법을 가상 메모리라고 한다.
그 중에 main memory가 64GB라면 그 64GB는 매우 빠를 것이고,
나머지 보조 메모리에 있는 process는 상대적으로 느릴 것이다.
-
Multitasking in Mobile Systems
- startphone은 main memory를 4, 6GB 정도로 쓴다.
그에 비해 보조 메모리도 넉넉하지 않다.
그래서 PC가 하듯이 OS를 scheduling을 할 수 없다. (Swap out으로도 모자라다)
game하다가 나가서 딴거 하다가 game 다시 들어가도, 실행됨.
➡️백그라운드 응용: 메모리에 남아 있지만 화면에 보이지 않는 응용
하지만 너무 오래 기다려지면 없애버린다. 처음부터 다시 실행됨. reset.
Operation on Processes
Process Creation
-
process가 실행되는 동안에,
process는 여러 개의 새로운 process를 생성할 수 있다. -
parent process: process를 생성하는 process. -
child process: 생성된 새로운 process. -
pid: 정수 형태의 process 식별자. pid는 각 process에 고유한 값을 가지도록 할당한다.
-
process가 새로운 process를 생성할 때,
두 process를 실행시키는 데 두 가지 방법이 존재한다.- 부모는 자식과 동시에(병행하게) 실행을 계속한다.
- 부모는 일부 또는 모든 자식이 실행을 종료할 때까지 기다린다.
-
새로운 process들의 주소 공간 측면에서 볼 때 다음과 같은 두 가지 가능성이 있다.
- 자식은 부모의 복사본이다(부모와 똑같은 program과 data를 가진다)
- 자식은 자신에게 적재될 새로운 program을 가지고 있다.
-
부모와 자식의 Resoure sharing 방법 :
- 모든 자원을 공유하는 경우
- 일부만 공유하는 경우
- 공유하지 않는 경우
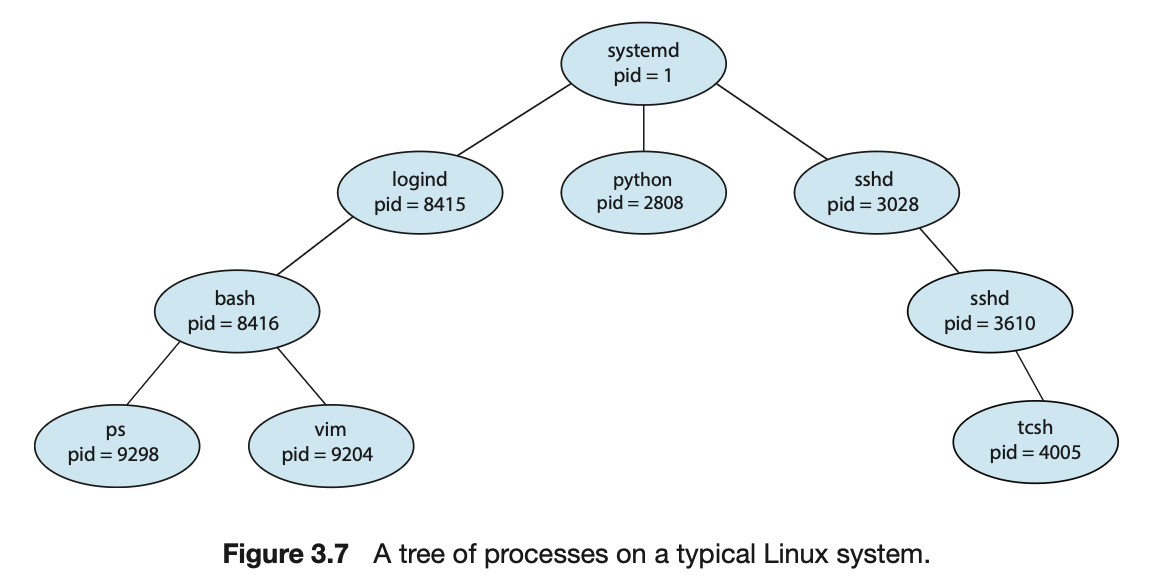
A Tree of Process in Linux
- 다음은
Linux의 process tree이다.
보통 OS는 커널이 동작할 때 초기 process를 생성하고,
이후엔 그 process가 그 다음 process를 만드는 형태로 진행됨 - 언제나 pid가 1인 systemd process는
시스템이 boot될 때 생성되는 첫 번째 user process이다.
모든 user process의 root parent process 역할을 수행하고,
시스템이 booting되면 systemd process는 다양한 user process를 생성한다.
C program Forking Separate Process
-
fork() : 자식 process를 생성하는 함수. (kernel mode로 연결돼서 동작함)
fork() 이하에서 자식과 부모는 각각 따로 따로 동작한다.

- 똑같은 process를 만들어서 총 2개의 process가 된다.
만든 결과르 pid에게 return한다.
(둘 중 하나를 부모로 만들고 하나는 자식으로 만듦(어느 걸 골라도 관계 X)) - 한 process에는 pid=0을 준다. ➡️ child process
- 한 process에는 pid != 0인 pid를 준다. ➡️ parent process
만약 pid가 음수라면 fork() error이다.
- 똑같은 process를 만들어서 총 2개의 process가 된다.
-
위의 코드를 그림으로 도식화하면 다음과 같다.
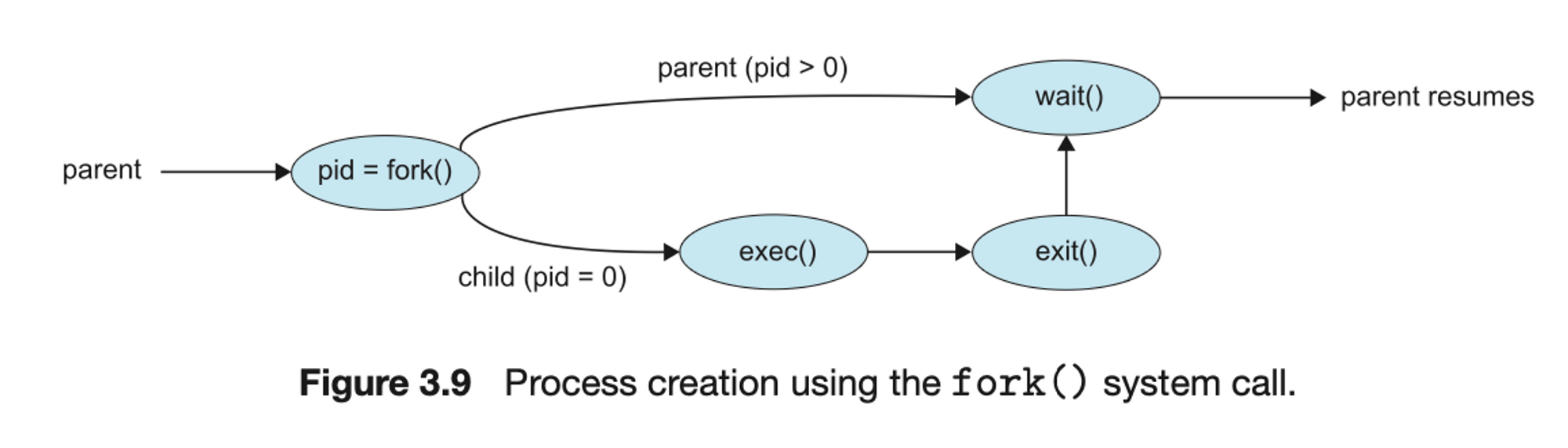
- 부모는 자식이 끝날 때까지 기다리고 있다가,
자식 process가 끝나면 운영체제가 exit()을 알려주고, 그 다음 일을 수행하게 된다.
- 부모는 자식이 끝날 때까지 기다리고 있다가,
Process Termination
- process 마지막 문장의 실행을 끝나고 나면,
exit()라는 System Call을 사용하여, OS에게 process 삭제를 요청한다.
-
이 시점에 process는 자신을 기다리고 있는 부모 process에게
wait()라는 System Call을 통해 상태값을 반환할 수 있다. -
물리 메모리와 가상 메모리, 열린 파일, 입출력 버퍼를 포함한 process의 모든 자원이 할당 해제되고 OS로 반납된다.
-
부모는 다음과 같은 이유로 자식 process의 실행을 종료시킬 수 있다.
- 자식이 자신에게 할당된 자원을 초과하여 사용할 때
- 자식에게 할당된 task가 더 이상 없을 때
- 부모가 exit하는데, OS는 부모가 exit한 후에도 자식이 실행을 계속하는 것을 허용하지 않을 때
(일반적으로 OS는 이러한 상황을 허용하지 않고, 이를cascading termination이라 한다.)
-
process가 종료하면 사용하던 자원은 OS가 되찾아 간다.
그러나 process의 종료 상태가 저장되는 process table 항목은 부모 process가 wait()를 호출할 때까지 남아 있게 된다.
process는 종료되었지만 부모 process가 아직 wait()를 호출하지 않은 process를
zombie process라고 한다. -
부모 process가 wait()를 호출하는 대신 종료했을 때, 혼자 놓여진 자식 process를
orphan process라고 부른다.
UNIX에서는 orphan process의 새로운 부모 process로 init process를 지정함으로써 문제를 해결한다.
Interprocess Communication (IPC)
-
Interprocess Communication:
두 개 이상의 process들이 협업하기 위한 process들의 communication.
process가 시스템에서 실행 중인 다른 process에 영향을 주거나 받는다면,
이는 협력적인 process들이다.- independant process : 독립하는 process들.
- cooperating process : 협업하는 process들.
-
Interprocess를 제공하는 이유
- Information sharing
- Computation speedup : 계산 가속화.
- Modularity : 모듈성. 다른 데에서 재활용.
-
하지만 문제가 생길 수도 있어 주의를 해야함 (나중에 공부 ...)
IPC model
- Interprocess Communication에는 2가지 model이 존재한다.
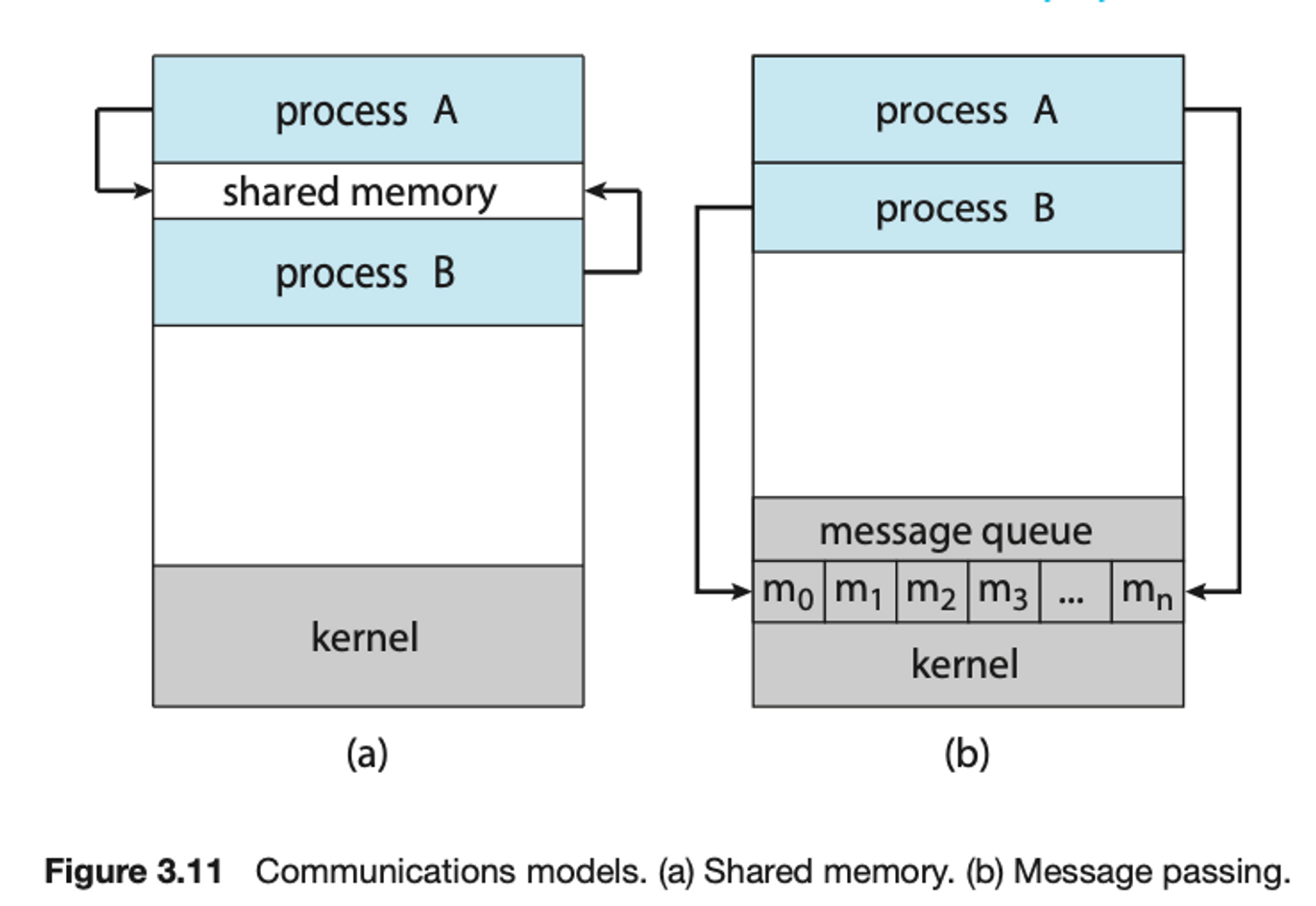
Shared memory: memory를 공유하는 방법.
두 process만 접근할 수 있는 memory 공간을 할당하여
그 memory에 data를 읽고 쓴다.Message passing: message(신호)를 주고 받는 방법.
약속된 Queue가 있다. 보통 OS의 Queue를 이용하는데,
process가 Queue에서 data를 읽고 쓴다.
1. Shared memory model
-
Shared memory model을 사용하는 IPC에서는
통신하는 process들이 shared memory 영역을 구축해야 한다. -
Producer-Consumer Model은 Shared Memory Model의 가장 기본적인 형태이다.
Producer-Consumer Model은 다음과 같다.
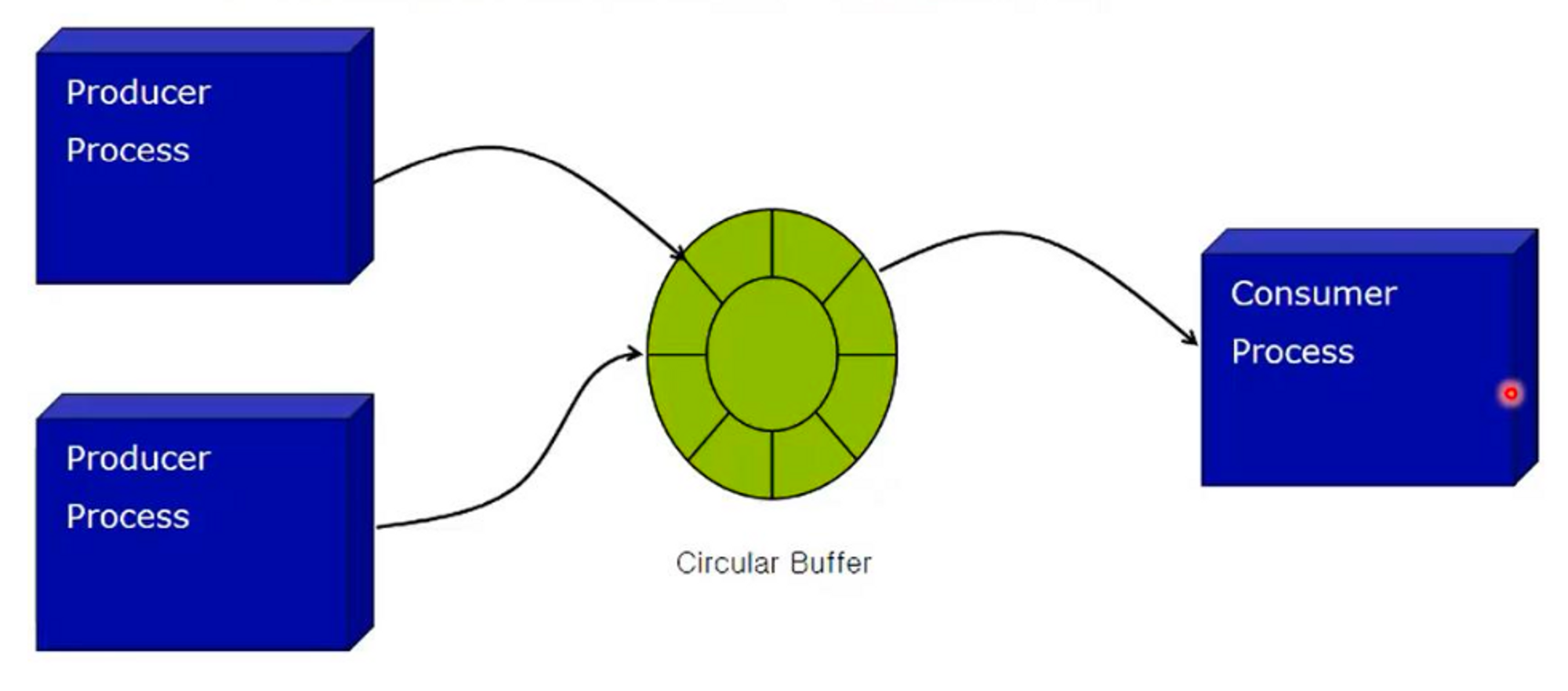
producer process: data를 생성하는 process.consumer process: data를 사용하는 process.
- Circular Buffer(Queue)는 Bounded Buffer(유한 버퍼)라고 가정한다.
Producer-Consumer Model Algorithm
-
공유 buffer는 2개의 pointer
in과out를 갖는 Circular Queue로 구현된다.- in == out; 일 때 buffer는 비어있는 상태이다.
- ((in+1) % BUFFER_SIZE == out) 이면 buffer는 꽉 차있는 상태이다.

-
다음은
Producer의 code이다.

- Producer process는 in만 증가시킴.
(data를 생성하여 buffer에 쓰면 in은 1 증가)
- while((in+1)%BUFFER_SIZE == out) ; 일 때 blocking(무한루프)
➡️ In과 Out이 같아지면 buffer가 비워지니까 넣지 않고 기다려야 한다
➡️ 그런데 consumer process가 buffer에 있는 data를 가져가서 out을 증가시킨다면,
무한루프를 깨고 나와서 data를 다시 생성하여 buffer에 넣을 수 있게 된다.
- Producer process는 in만 증가시킴.
-
다음은
Consumer의 code이다.

- Consumer process는 out만 증가시킴
(data를 buffer에서 읽으면 out은 1 증가)
- while(in == out) ; 일 때 blocking(무한루프)
➡️ data가 없을 때이기 때문에 data를 못 가져오게 막는다.
➡️ 그런데 producer process에서 data를 생성하여 in을 1 증가시킨다면 무한루프를 깨고 나와 data를 다시 가져올 수 있게 된다.
- Consumer process는 out만 증가시킴
서로 무한루프에서 대기하고 있다가
서로가 서로를 무한루프에서 풀어주면 빠져나와 자신의 일을 한다.
중간에 Shared memory가 있기 때문에, 상호 협력적으로 처리가 가능하다.
2. Message Passing model
-
Message Passing model은 Sharing memory model과 달리
주소 공간을 공유하지 않고도 process들이 통신할 수 있고, 그들의 동작을 동기화할 수 있도록 허용하는 기법을 제공한다. -
Message Passing model은 최소한 두 가지 연산을 제공한다.
- send(message)
- receive(message)
Direct / Indirect Communication
-
만약 process P와 Q가 통신을 원하면, 이들 사이에 communication link가 설정되어야 한다.
communication link를 설정하는 논리적인 구현은 다음의 방법들이 존재한다.Direct communication에서, 각 process는 송, 수신자 이름을 명시해야 한다.- 통신을 원하는 각 process들의 쌍들 사이에 연결이 자동으로 구축된다.
- process들은 통신하기 위해 상대방의 identity만 알면 된다.
- Communication은 정확히 두 process 사이에만 연관된다.
➡️ send(P, message) : process P에 message를 송신한다.
➡️ send(Q, message) : process Q로부터 message를 수신한다.
Indirect communication에서, message들은 mailbox 또는 port로 송, 수신한다.- 각 mailbox는 고유의 id를 갖는다.
- 정해진 process는 없고, 접근할 수 있는 누구든 가져갈 수 있음
➡️ send(A, message) : message를 mailbox A로 송신한다.
➡️ send(A, message) : message를 mailbox A로부터 수신한다.
Synchronization(Blocking)
-
shared memory model도 동기화 문제가 생기지만,
message passing model도 동기화 문제가 생긴다. -
message passing model에서
동기화란 blocking을 의미하고,
비동기화란 nonblocking을 의미한다.- Blocking sending: sending하는 process는 수신 process에 의해 receiving될 때까지 기다린다.(전화통화와 같은 느낌)
- Unblocking sending : sending하는 process는 message를 보내고 작업을 재시작한다. (카톡 같은 느낌)
- Blocing receiving : message가 이용 가능할 때까지 receiving process가 봉쇄된다.
- Unblocking receiving : sending하는 process가 유효한 message를 받는다.
-
sending process와 receiving process 모두 blocking 방식이면,
랑데부 프로토콜(rendezvous protocol)이라고 한다.
➡️ 1:1로 연결이 돼야 send와 receive가 이루어진다.
➡️ 그러면 보내느쪽과 받는쪽이 명확해 진다.
➡️ 중간에 buffer가 필요없다 (= Zero capacity)
Buffering
Zero Capacity: Queue의 최대 길이가 0이다.
sending process는 receiving process가 receiving할 때까지 기다려야 한다.Bounded Capacity: Queue는 유한한 길이 n을 가진다.
즉, 최대 n개의 message가 그 안에 들어 있을 수 있다.
Queue가 꽉 찼다면, sending process는 반드시 blocking된다.Unbounded Capacity: Queue는 잠재적으로 무한한 길이를 가진다.
따라서 message들이 얼마든지 Queue 안에서 대기할 수 있다.
sending process는 절대 blocking되지 않는다.
➡️ 일반적인 mailbox는 Bounded Capacity의 buffer가 필요하다.
Communications in Client-Server Systems
- Communication은 process끼리의 통신 뿐만 아니라 Computer끼리도 일어난다.
- Sockets (Socket만 간단하게 살펴볼 것임)
- Remote Procedure Calls
- Pipes
- Remote Method Invocation
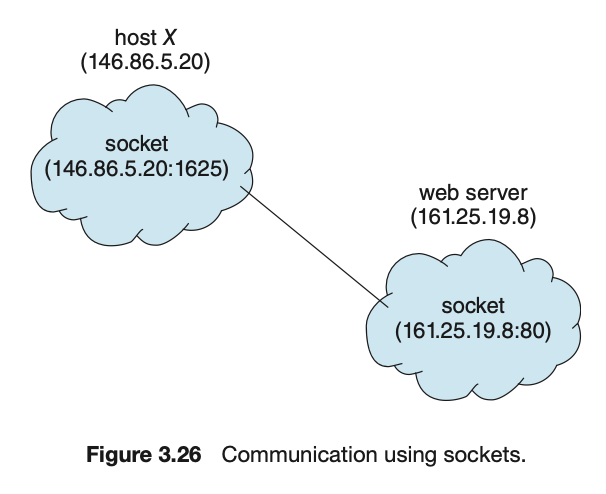
Socket
socket은 통신의 극점(endpoint)을 뜻한다.- 각 socket은 IP 주소와 port 번호 두 가지를 접합해서 구별한다.
- 일반적으로 socket은 client-server 구조를 사용한다.
- server는 지정된 port에 client 요청 message가 도착하기를 기다리게 된다.
- 요청이 수신되면 server는 client socket으로부터 연결 요청을 수락함으로써 연결이 완성된다.
- 해당 IP주소를 가지는 컴퓨터의 몇 번 port(경로번호)를 이용하는 process에게
”data를 보내겠다”라고 하고,받는 쪽에서도 해당 port를 열어놓고 있으면,
data를 주고 받을 수 있음. - 보통 포트번호는 2 bytes이다.
Summary
-
Process는 실행 중인 Program이며
Process의 현재 활동 상태는 Program Counter와 다른 register로 나타난다. -
memory에서 process의 논리적(!=물리적)layout은
(1) text, (2) data, (3) heap, (4) stack, 네 가지 section으로 표시된다. -
process가 실행되면 state(상태)가 변경된다.
process의 일반적인 상태는
(1)new, (2)ready, (3)waiting, (4)running, (5)terminated 이다. -
PCB(Process Control Block)은 OS의 process를 나타내는 kernel data 구조이다.
-
process scheduler의 역할은 CPU에서 실행할 수 있는 사용 가능한 process를 선택하는 것이다.
-
OS는 한 process running에서 다른 process running으로 전환할 때 Context Switching을 수행한다.
