Delving Into Cluttered Prohibited Item Detection for Security Inspection System
[Paper Review] ETC
Paper Info.

Abstract
- (서론)
X-Ray baggage(수하물) image에서 prohibited item detection은 사회적 안전과 안정을 효율적으로 보장할 수 있다.
DL의 발전으로 CV task에서 특정 방법을 prohibited item detection에 적용하는 것이 유망한 전망을 보여주고 있으며, 이로 인해 개발된 지능형 보안 검사 system은 인적 검사의 한계를 효과적으로 해결 할 수 있다.
여러 DL 기반 방법들이 이 연구 분야를 발전시키기 위해 제안되었지만, 여전히 탐구되지 않은 두 가지 문제가 남아있다.
(문제제기)- most of them suffer from the shortage of dataset and collection of massive and well-annotated sampels is extremely laborious(힘드는) and costly.
(한마디로 dataset 부족) - 현재 금지된 물품 탐지 방법의 backbone module 설계는 object detection에서 사용되는 것과 유사한 아이디어를 공유한다.
하지만 대부분의 금지된 물품이 overlapped(겹쳐져 있고) and cluttered(어지럽게 배치)하다는 특성에 대한 고려는 거의 이루어지지 않았다.
- most of them suffer from the shortage of dataset and collection of massive and well-annotated sampels is extremely laborious(힘드는) and costly.
- (방법제안)
이러한 한계를 극복하기 위해, 본 논문은 a cluttered prohibited item detection method for security inspection system을 제안한다.
구체적으로, 우리의 방법은 먼저 각 training mini-batch에서 training sample을 사용해
cut-and-paste strategy를 통해 synthetic X-Ray images를 생성한다.
이 전략은 dataset을 효과적이고 효율적으로 aguments하며, synthetic samples의 quality를 보장할 수 있다.
그 다음, high-order dilated convolution module을 개발하여 feature의 representation ability를 강화하고,
겹쳐져서 복잡한 금지 물품의 위치를 더 잘 파악할 수 있도록 촉진한다.
실험 결과, 제안된 방법이 다양한 dataset에 잘 일반화되며, SOTA 방법에 비해 명확한 성능 향상을 달성할 수 있음을 보여준다.
1. Introduction
-
security inpsecion은 X-Ray images를 통해 수하물 내 금지된 물품을 확인하는 것을 목표로 하며, terrorist 공격을 방지하고 사회적 안전을 보장하는 중요한 역할.
traditional security inspection은 inspectors(검사자들)이 scan된 X-Ray image를 monitor로 감시해야 하지만, 이 과정에서 human-error가 발생할 수 있으며,
overlapped or cluttered items (겹치거나 복잡하게 배치된 물품)들은 식별하기 어렵다. -
(이전 연구)
최근 몇 년 동안, Deep CNNs의 발전과 함께 일부 연구들은 object detection방법을 prohibited item detection에 적용하려는 시도를 해왔으며, 이러한 방법과 관련 dataset들은 유망한 성능을 보여주고 있다.- GDXray [5]는 the first public prohibited item detection dataset으로, 세 가지 서로 다른 금지된 물품을 포함하고 있다.
- SIXray [6]는 GDXray를 기반으로 dataset의 sample 수와 금지된 물품의 categories를 확장하였고,
class-balance loss function을 사용해 class-balanced hierarchical refinement module로 easy ngative samples로 인한 noise를 처리했다. - 금지 물품의 특성을 고려하기 위해 Wei et al. [7]은 occluded and cluttered dataset인 OPIXray를 구축했으며, X-Ray images는 전문 보안 감시자들이 주석을 달았다.
또한, 금지 물품의 보이지 않는 부분의 가장자리(edge) 정보와 보이는 부분의 질감(texture) 정보를 강조하기 위해 deocclusion attention module이 제안되었다. - 이와 유사하게, HiXray [8]은 실제 공항 보안 검사 시나리오에서 구축되었다.
Tao et al. [8]은 OPIXray와 비슷하게 lateral inhibition module을 배치해 겹치는 영역의 noise를 억제하고 식별 정보를 강조했다. - HiXray를 넘어 PIDray와 PIXray는 detection and segmentation annotations을 포함하는 첫 두가지 datasets으로,
- PIDray는 금지된 12가지 categories를 포함하며 공간 및 channel 측면에서 feature의 localization ability를 강화하기 위해 selective dense attention network가 설계되었다.
- PIXray는 처음으로 15가지 서로 다른 categories를 수집하고, 정확하고 자동화된 segmentation을 위해 deoverlap(중첩해제) attention snake를 구현했다.
- (이전 연구의 문제점)
위에서 언급한 방법들이 large-scale prohibited item dataset에 대한 수요를 완화하고
정확한 prohibited item detection을 위해 attention mechanism을 기반으로 정교하게 설계된 module을 배치하려고 노력했지만, 여전히 두 가지 limitations을 겪고 있다.- datasets 수집은 특히 X-Ray images를 위해 매우 힘들고 비용이 많이 듦.
X-Ray images는 X-Ray inspector machine과 professional annotation이 필요하기 때문.
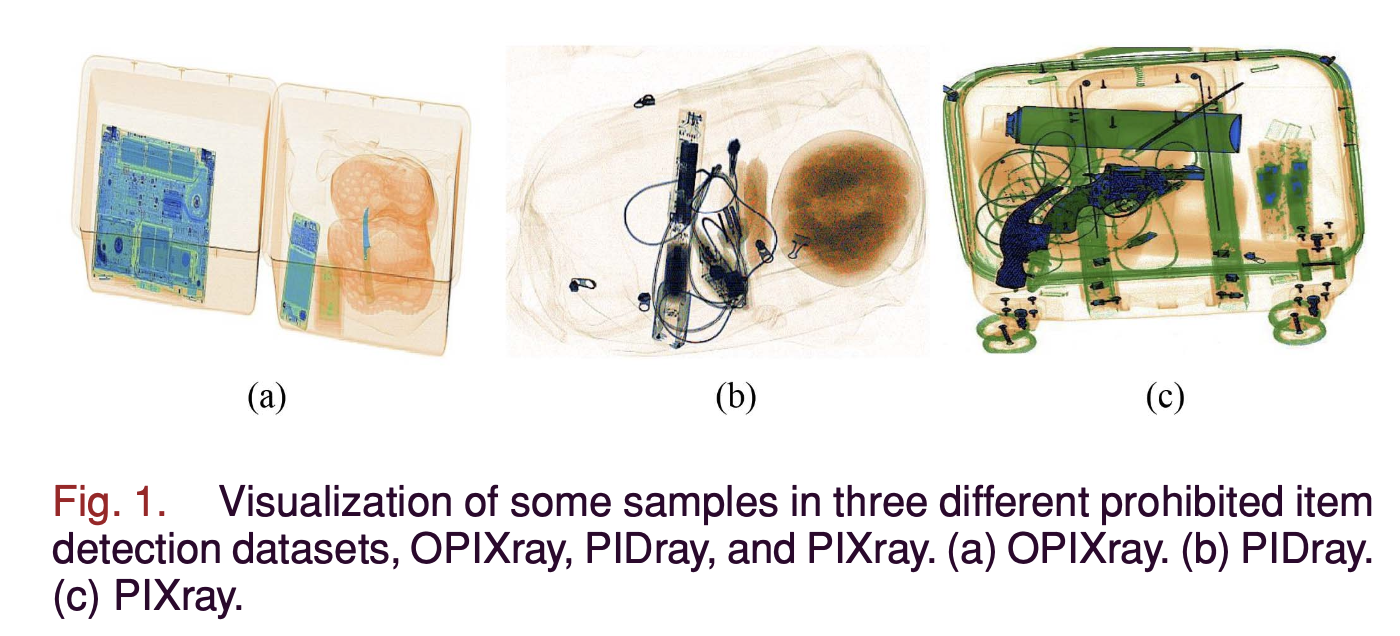
Fig. 1에서 볼 수 있듯이, X-Ray images는 natural image에 비해 narrow(좁은) color distribution and simple texture(질감) information을 갖는 속성을 갖는다.
현재 dataset을 기반으로 합성 images를 생성함으로써 training samples을 얻는 것이 또 다른 large-scale dataset을 annotation하는 거보다 더 쉽고 효율적일 것이다.
- 또한 현재 방법들은 detection pipeline에 attentino module을 도입하는 데 중점을 두고 있지만, 적절한 backbone model에 대한 설계에 대한 고려는 거의 이루어지지 않았다.
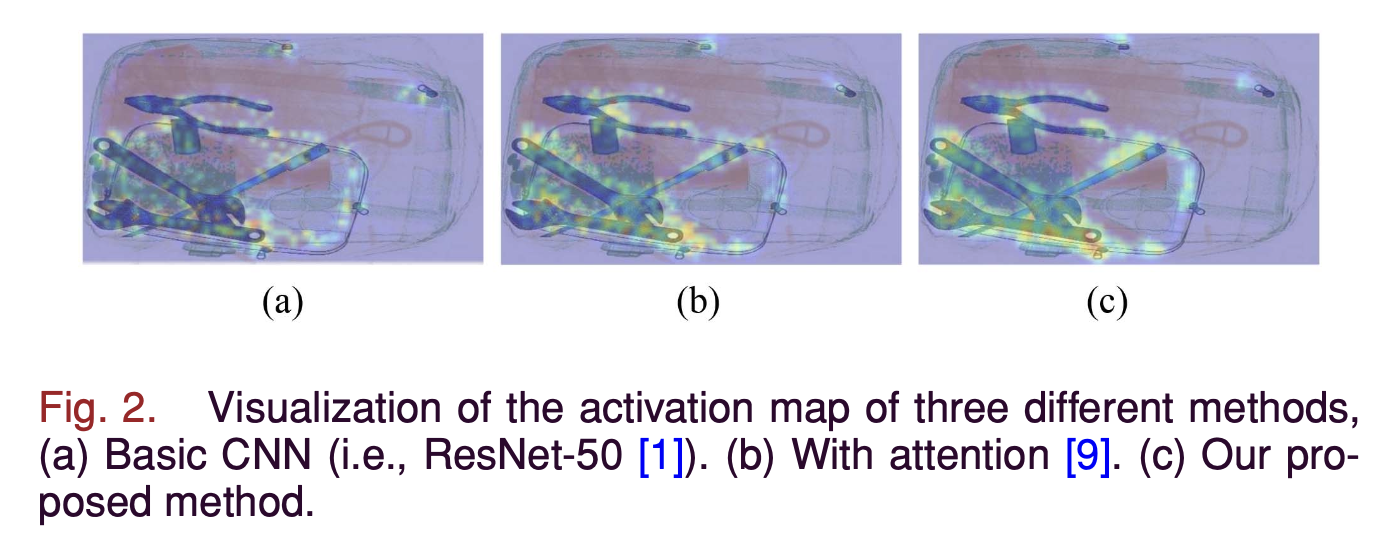
Fig. 2(a)와 (b)에서 볼 수 있듯이, activation map에서 attention module이 localization ability를 향상시키는 데 도움을 주지만,
feature discriminative ability(판별력)와 receptive field는 여전히 탐구가 필요하다.
특히, smal and dense overlapped prohibited items (e.g., hammers)를 탐지하는 데는 더욱 그렇다.
- datasets 수집은 특히 X-Ray images를 위해 매우 힘들고 비용이 많이 듦.
- (해결방법 제안)
위 문제를 해결하기 위해, 본 논문은 보안 검사 system을 위한 a novel Cluttered Prohibited Item Detection method(CPID)를 제안한다.
구체적으로, 우리는 online random cut-and-paste (ORCP) strategy를 활용하여 training 과정에서 합성 training samples을 생성함으로써 dataset을 증강한다.- training minibatch에 있는 X-Ray images를 제공받으면,
우리의 ORCP는 먼저 detection item을 segmentation mask에 따라 cut한 후,
같은 minibatch에 있는 background images 위에 random하게 paste한다.
마지막으로 training samples의 annotation이 update된다.
분명히, 자연 image와 비교할 때, X-Ray image는 narrow color distribution and simple texture information을 갖기 때문에 cut된 item과 pasted background images 간의 context coherence(일관성)과 consistency(일치)를 엄격히 보장할 필요가 없다.
random하게 cut된 prohibited item을 배치함으로써 실제 보안 검사 시나리오의 혼잡한 상황을 모방할 수 있으며, 생성된 hard samples은 detection model의 localization robust를 향상시킨다.
주목할 점은, ORCP는 synthetic samples이 단일 dataset에만 기반할 수 있는 제한을 벗어나 cut items과 pasted background images가 서로 다른 dataset에서 올 수 있도록 synthetic image를 증강한다는 점이다.
또한, object detection에서 high-order statistics의 성공에 영감을 받아 금지 물품 탐지 framework에서 high-order representation을 채택했다.
추가로, high-order statistics에 dilated convolution을 통합하여 최종 high-order dilated convolution(HDC) module을 제안했다.
HDC는 high-order statistics에서 more discriminative informative representations을 활용할 수 있을 뿐만 아니라, dilated convolution이 가져오는 larger receptive field도 발굴할 수 있다.
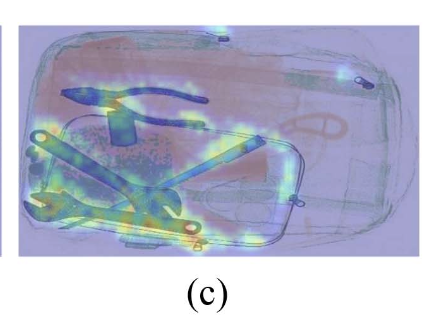
Fig. 2(c)에 나타난 바와 같이, HDC는 small and dense overlapped prohibited items(i.e., guns)에 대해 더 나은 localization ability를 보여주며, receptive field가 크게 확대될 수 있다.
 CPID의 효과를 검증하기 위해, 우리는 CPID를 서로 다른 two-stages detection 방법에 구축하고,
CPID의 효과를 검증하기 위해, 우리는 CPID를 서로 다른 two-stages detection 방법에 구축하고,
다양한 backbone model을 사용하여 금지 물품 dataset과 general object detection datsets에서 실험을 수행했다.
- training minibatch에 있는 X-Ray images를 제공받으면,
- 본 연구의 주요 contribution은 다음과 같이 요약된다 :
- 우리는 금지 물품 탐지를 위한 online data augmentation based on cut-and-paste와
dilated convolutionHDC module을 제안했다. - 우리가 아는 한, dilated convolution을 high-order statistics와 통합하고, 금지 물품 탐지에 대해 다른 dataset에 걸쳐 online data augmentation을 적용한 첫 번째 시도를 했다.
- 다양한 금지 물품 dataset과 detection backbone model을 대상으로 extensive experiments를 수행했으며,
그 결과 CPID가 상당한 성능 향상을 가져올 수 있음을 입증했다.
또한, 이를 general object detection dataset(e.g. COCO and PASCAL VOC)에 적용한 후에도 경쟁력 있는 성과를 달성할 수 있었다.
- 우리는 금지 물품 탐지를 위한 online data augmentation based on cut-and-paste와
2. Related Works
(skip)
3. Proposed Methods
- 이 section에서, 우리는 우리가 제안한 CPID method를 소개할 것이다,
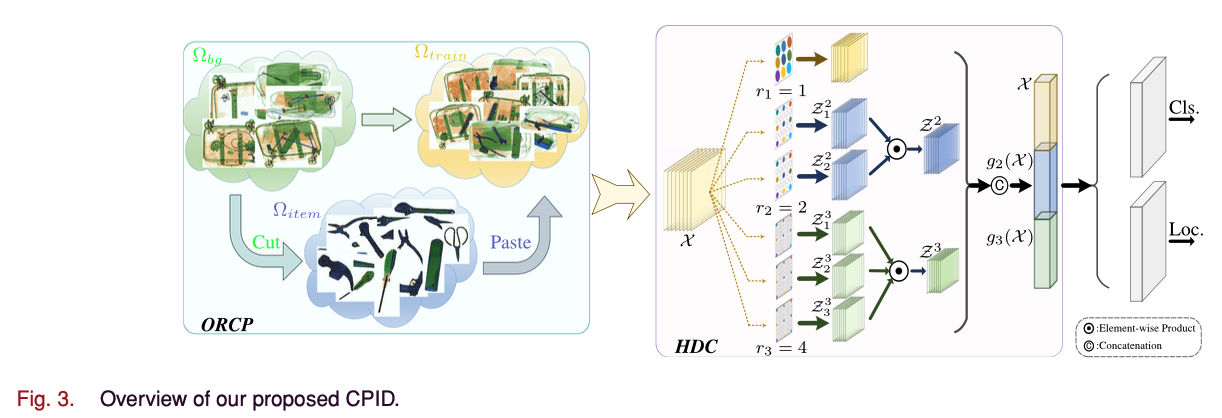
CPID의 overview는 Fig. 3에 그려져있다.
우리는 data augmentation을 위한 ORCP strategy를 먼저 설명하고 나서,
receptive field와 feature의 discriminative ability를 향상시키기 위한 HDC module의 세부사항을 설명할 것이다.
A. Online Random Cut-and-Paste
-
cut-and-paste strategy는 object detection에서 유망한 data augmentation 방법이며,
우리는 cust-and-paste 방법을 prohibited item detection task에 처음으로 도입했다. -
구체적으로, 우리의 ORCP(Online Random Cut-and-Paste)는 segmentation mask annotation에 따라 금지 물품을 cut(잘라내고) 금지 물품 candidate set 을 만든다.
그 다음, 에서 여러 물품을 random하게 선택해 에서 가져온 background image에 paste한다.
pasted location , size , 그리고 rotation angle 은 모두 random하게 생성되어 실제 보안 검사 시나리오, 특히 overlapped and cluttered 시나리오를 모방한다
training minibatch 와 금지 물품 candidates 은 서로 다른 dataset에서 수집될 수 있다.
synthetic samples의 품질을 향상시키기 위해 boundary artifacts(경계 인공물)을 smooth하게 처리하는 Gaussian blurring도 적용된다.
실제 시나리오에서는 특정 category가 특정 context 속성(e.g. horse는 초원에 있고 airplane은 하늘에 있는 것)과 관련이 있는 반면, 금지 물품 탐지를 위한 X-Ray image는 제한된 category, 좁은 색상 분포, 단순한 배경 맥락 정보를 갖는다.
서로 다른 category의 금지 물품은 거의 동일한 일반적인 맥락 속성을 포함하고 있기 때문에, cut된 금지 물품과 paste된 backgroun image 간의 맥락 일관성과 합리성을 엄격히 보장할 필요가 있다.
이러한 이유ㄹ, 잘라낸 물품의 pasted parameters(i.e., locations, size, and rotation angle)을 random하게 생성할 수 있으며, 특히 overlapped and cluttered situation에 대한 training samples의 다양성을 더욱 증가시킬 수 있다.
마지막으로, 생성된 minibatch 은 detector를 훈련하는 데 사용된다.
ORCP의 detailed steps은 Algorithm 1에 요약되어 있다.
-
기존의 data augmentation 방법은 training iamge에 horizontal flipping, multiscale strategy, patch crop과 같은 geometrical transformations(기하학적 변환)을 수행하여 공간 구조를 다양화했다.
그러나 이러한 방법들은 imagee의 visual content를 거의 바꾸지 못해 training dataset의 다양성이 부족하다.
기존의 data augmentation 방법과 비교했을 때, ORCP는 다음과 같은 여러 이점을 제공한다.- ORCP는 실제 보안 검사 시나리오, 특히 overlapped and cluttered 상황을 모방하여 synthetic sample diversity를 강화할 수 있다.
- 금지 물품 탐지를 위한 X-Ray image는 제한된 category, 좁은 색상 분포, 단순한 배경 맥락 정보를 갖는다.
서로 다른 category의 금지 물품은 거의 동일한 일반적인 맥락 속성을 포함하고 있어,
cut 물품과 paste bg image 간의 맥락 일관성과 합리성을 보장할 필요가 없다. - ORCP는 synthetic samples을 단일 dataset에만 기반하여 생성하는 제한에서 벗어나, 서로 다른 dataset에서 잘라낸 물품과 bg image로 synthetic image를 증강할 수 있다.
-
Fig. 4에서 보여진 바와 같이, 우리는 네 가지 다른 방식으로 생성된 synthetic image를 설명한다.
여기에는 동일한 dataset에서 잘라낸 물품과 붙인 bg image(즉, (b) PID2PID 및 (e) PIX2PIX)뿐만 아니라, 서로 다른 dataset에서 가져온 경우(즉, (c) PIX2PID 및 (f) PID2PIX)가 포함된다.
앞서 언급한 바와 같이, X-Ray image는 좁은 색상 분포와 단순한 맥락 정보를 가지고 있어, 서로 다른 dataset에서 잘라낸 물품과 붙인 bg image라도 random하게 붙이는 방식이 synthetic image의 품질을 보장할 수 있다.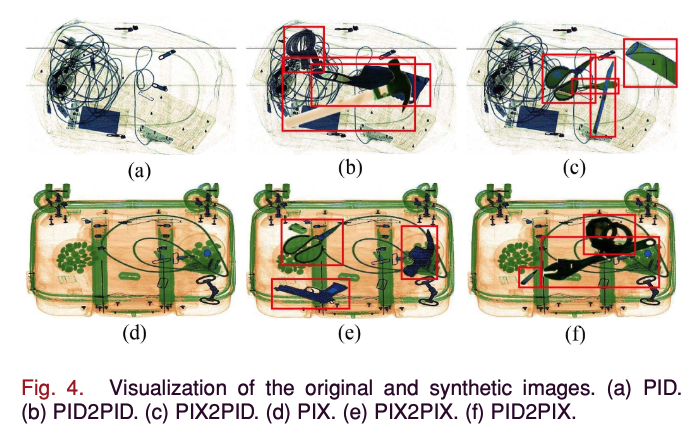
B. HDC Module
-
간단한 first-order representation에 비해,
high-order statistics는 더 많은 discriminative 정보를 포함하고 있어 detection task에서 classification and localization ability를 향상시킨다.
동시에, dilated convolution은 features의 ERFs(Effective Receptive Fields?)를 많이 개선할 수 있으며, 이는 겹치고 작은 item들을 localizing하는 데 유용하다.
우리는 이 두 가지 요소를 통합하여 prohibited item detection task에서 dense overlapped and cluttered issues를 해결하기 위해 HDC module을 제안한다. -
MLKP[13], [14]의 polynomial(다항) kernel approximation 방법에서 영감을 받아, 차의 linear predictor 는 다음과 같이 수식화할 수 있다:
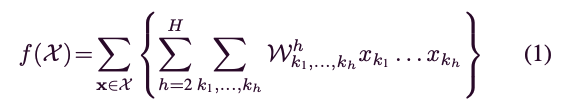 여기서 는 차수의 수이며, 는 output feature 의 번째 element를 나타낸다.
여기서 는 차수의 수이며, 는 output feature 의 번째 element를 나타낸다.
는 차 representation로, rank-1 tensor decomposition(e.g., )로 근사할 수 있으며, (1)은 다음과 같이 재정의할 수 있다:
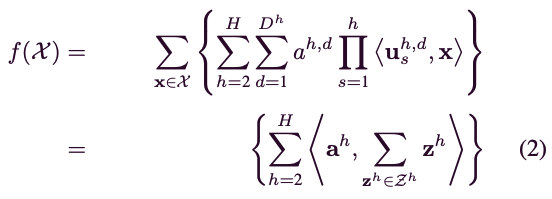 여기서 는 the inner product of the elements를 나타내며,
여기서 는 the inner product of the elements를 나타내며,
with 로 정의된다.
지금까지, parameter and 를 기반으로 임의 참수의 representation을 계산할 수 있다.
[13]에 의해 동기부여되어, 우리는 를 로 정의하고,
는 channel을 갖는 차 1x1 conv layer를 수행하여 얻을 수 있다.
여기서 와 는 각각 차수와 tensor의 rank를 나타낸다.
우리는 여기서 다양한 dilated rates 을 사용하여 dilated convolution을 배치하고, dilated convolution은 다음과 같이 수행된다:
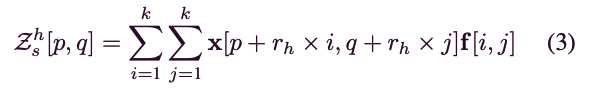 여기서 는 의 spatial location을 나타내며, 는 dilated convolutional kerel with size 이다.
여기서 는 의 spatial location을 나타내며, 는 dilated convolutional kerel with size 이다.
여기서 이다.
이는 전통적인 conv kernel 의 convolutional kernel에서 인접 요소 사이에 0을 삽입하여 구현된다.
전통적인 convolution은 고정된 크기의 receptive field를 가지지만, dilated convolution은 추가적인 computation cost 없이 다른 dilated rates를 설정함으로써 다양한 receptive field를 가진 feature map을 얻을 수 있다.
또한, dilated convolution은 small size items에 대한 유용한 정보를 capture하는 능력을 촉진하여 multiscale and overlapped issue를 더욱 잘 완화한다. -
끝으로, 제안된 HDC module은 다음 단계로 얻을 수 있다.
주어진 input feature map 에 대해, 우리는 먼저 차 dilated convolution operation을 channels과 dilated rate 로 수행하여 차 성분 를 계산한다.
(i.e., )
그런 다음, high-order output representations 는 모든 성분의 elementwise production으로 얻어진다.
마지막으로, 서로 다른 차수의 representations()을 연결하여 high-order output representation을 생성한다:
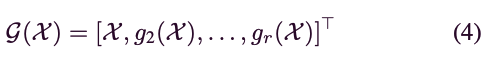 여기서 은 concatenation을 의미, 는 transpose 연산을 나타냄.
여기서 은 concatenation을 의미, 는 transpose 연산을 나타냄.
분명하게, 우리의 HDC는 high-order statistics과 dilated convolution의 최대 장점을 활용할 수 있고,
이는 feature discriminative ability와 receptive field을 향상시킬 수 있다.
Critique
마지막으로, 이 제가 생각한 이 논문의 단점입니다.
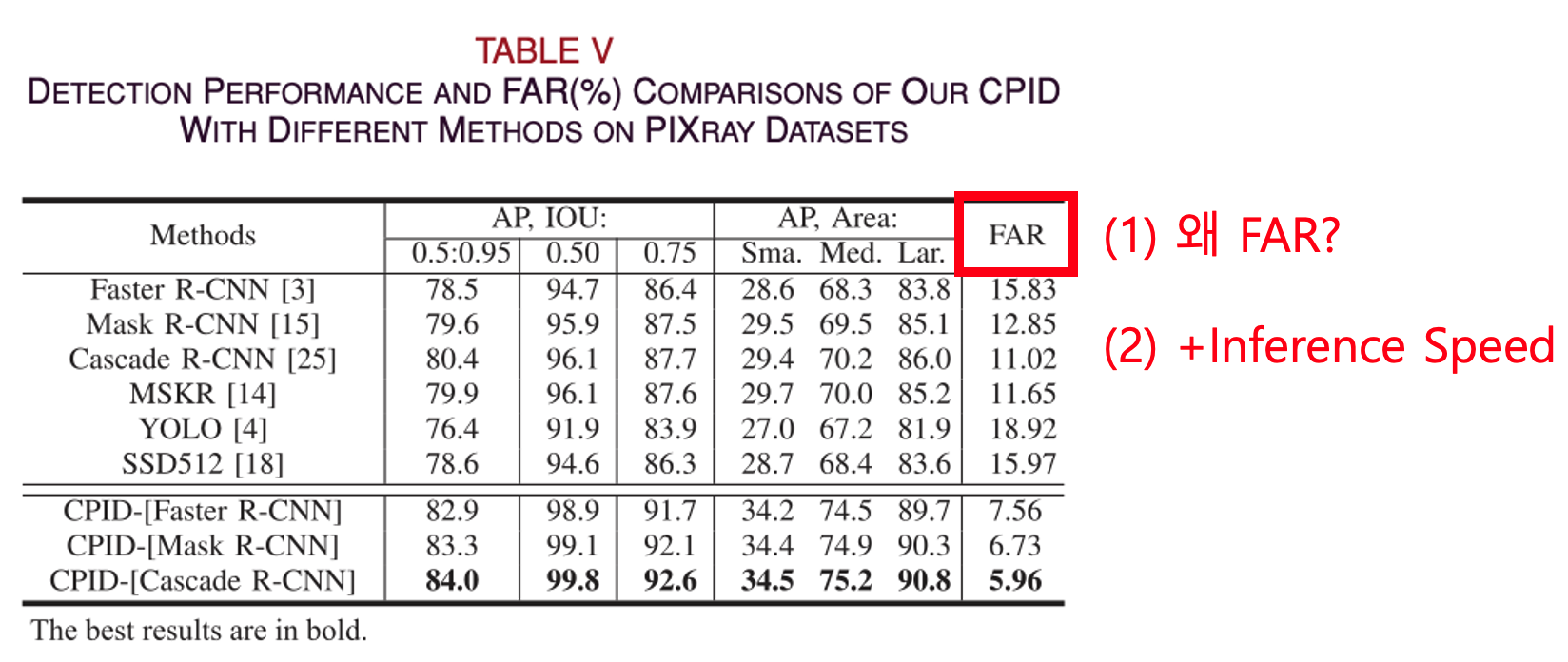
첫번째로는 FAR(Flase Alarm Rate) metric 말고 다른 metric을 사용했으면 더 좋았을 것 같습니다.
앞서 말씀드렸다시피, FAR metric은 실제로 금지 품목이 없는데 금지 품목이 있다고 잘못 탐지하는 비율을 나타냅니다.
그런데 금지 물품 탐지에서 금지 품목이 없는데 있다고 탐지하는 것보다, 금지 품목이 있는데 없다고 탐지하는 것이 더 위험한 상황이고 발생하면 안되는 상황이기 때문에
금지 품목이 있는데 없다고 탐지하는 비율을 측정할 수 있는 metric을 사용하여 비교하는 것이 더 적절하지 않은가 생각했습니다.
두 번째로는 이 실험에서 AP를 주요 metric으로 사용했지만, 탐지 속도, 메모리 사용량 등 다른 지표들도 함께 제시했으면 더 좋았을 것 같습니다.
정확한 탐지와 더불어 사람들이 계속해서 주입되고 빠른 처리가 필요한 보안 검색대의 특성상 탐지 속도도 중요할 것이라고 생각합니다.
- FAR(Flase Alarm Rate) metric은 실제로 금지 품목이 없는데 금지 품목이 있다고 잘못 탐지하는 비율을 나타낸다.
그런데 금지 물품 탐지에서 금지 품목이 없는데 있다고 탐지하는 것보다,
금지 품목이 있는데 없다고 탐지하는 것이 더 위험한 상황이고 발생하면 안되는 상황이기 때문에
금지 품목이 있는데 없다고 탐지하는 비율을 측정할 수 있는 metric을 사용하여 비교하는 것이 더 적절하지 않은가 생각했다... - 이 실험에서 AP를 주요 metric으로 사용했지만, 정확한 탐지와 더불어 사람들이 계속해서 주입되고 빠른 처리가 필요한 공항의 보안 검색대의 특성상 탐지 속도도 중요할 것이라고 생각한다.
그래서 inference speed도 측정해서 실험했다면 더 좋았을 것 같다.
(+ inference speed는 이미 충분히 빨라서 이를 고려하지 않은 것일 수도 있다...)
몰랐던 개념
- Oneline : 'Online'은 dat augmentation 과정이 model 학습 과정과 동시에 실시간으로 이루어진다는 것을 의미
