(simple) [GPT-1] [GPT-2] [GPT-3]

GPT-1
-
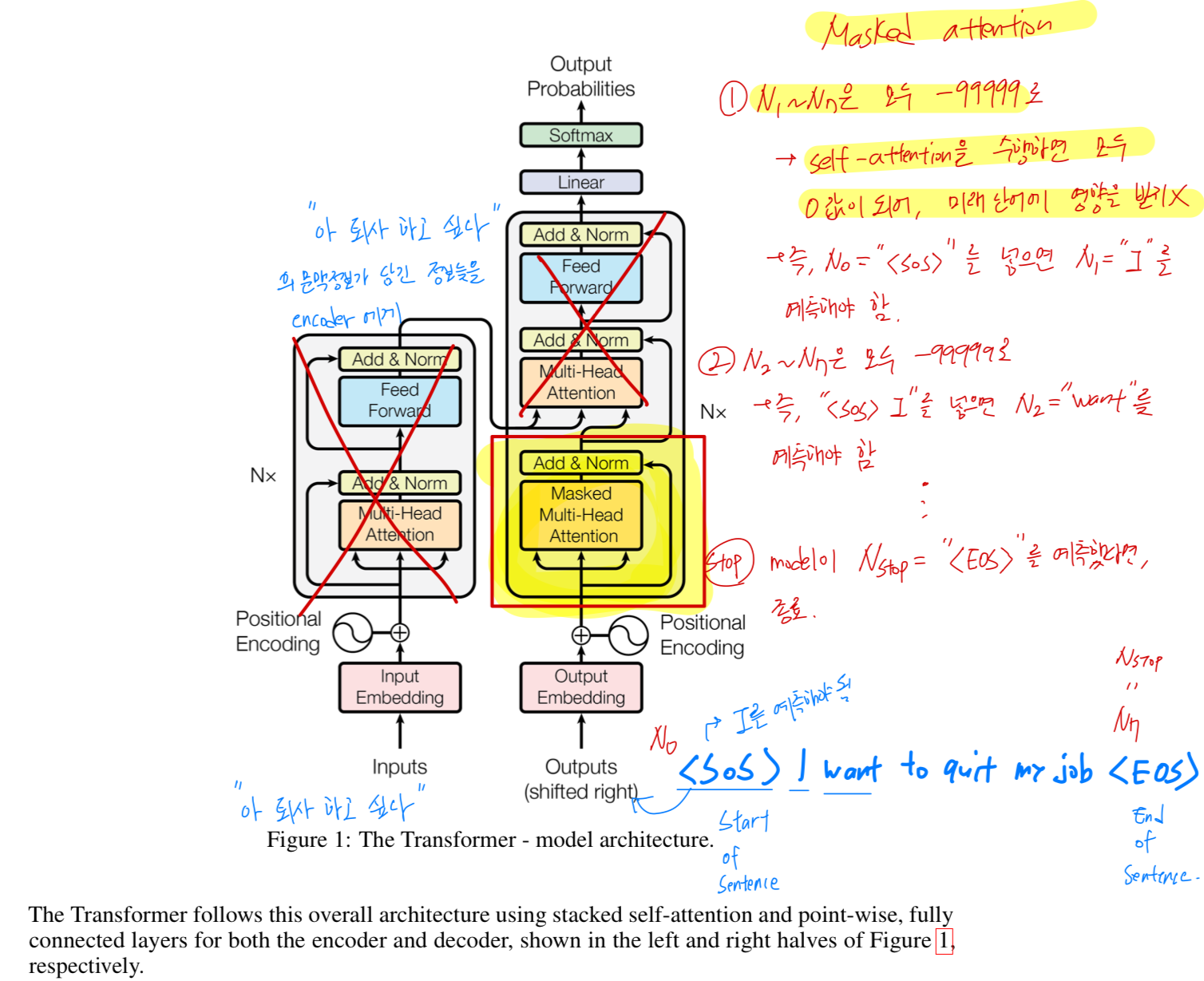
GPT1은 transformer의 decode 부분의 Masked multi-head self-attention만을 사용함.
- unlabeld corpus는 labeled corpus보다 훨씬 많으니까,
unlabeld corpus(대량 언어 데이터)에 pretraining시킨 후
특정 task에 적합하게 fine tuning함.
(그림 출처 : https://www.youtube.com/watch?v=o_Wl29aW5XM&t=1075s)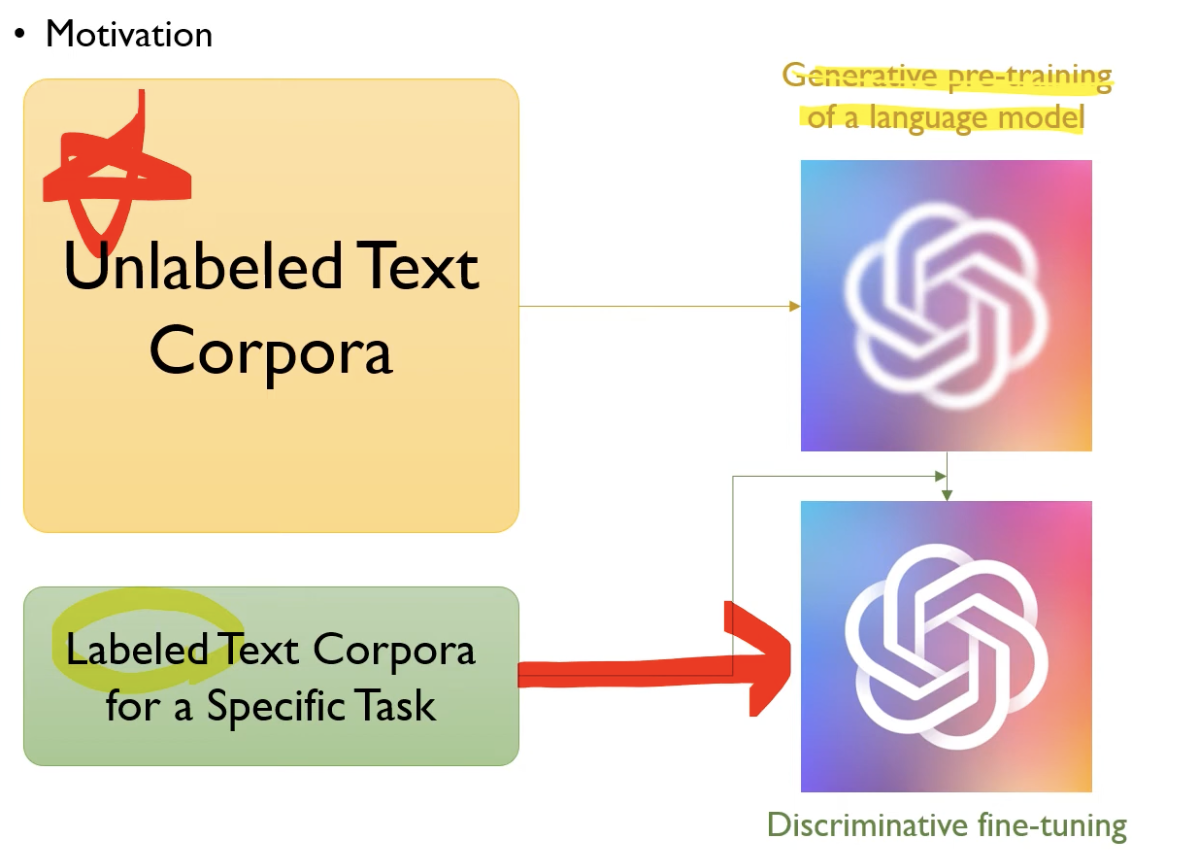
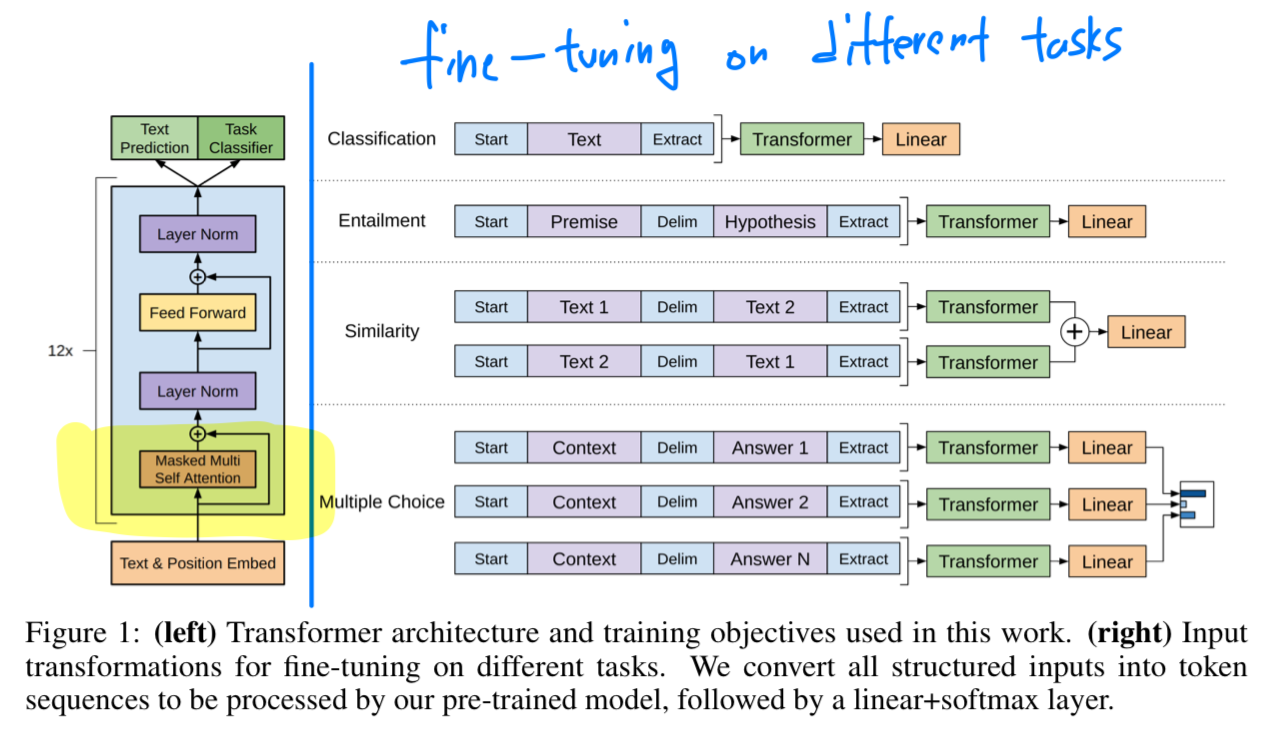
GPT-2
-
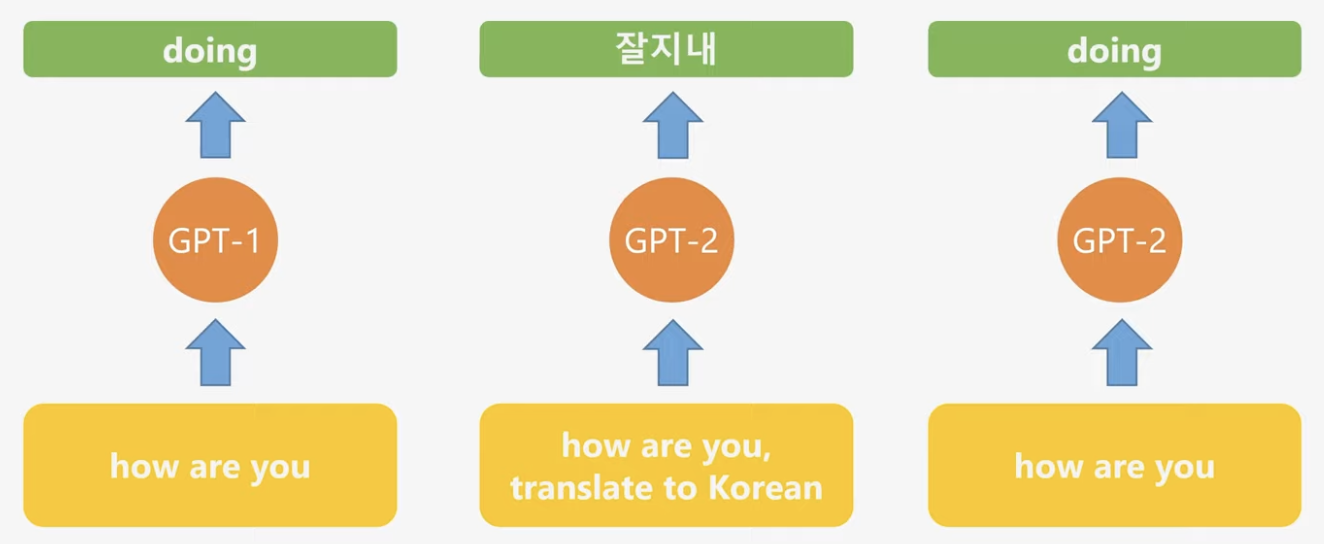
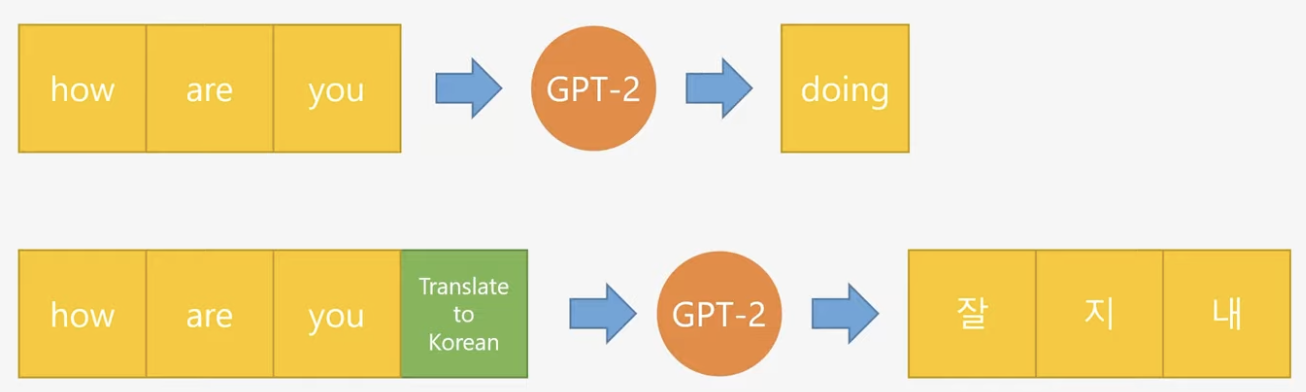
GPT2는 GPT1의 finetuning을 통째로 없앰.
(그림 출처 : https://www.youtube.com/watch?v=3n6157XNYyw&t=108s)
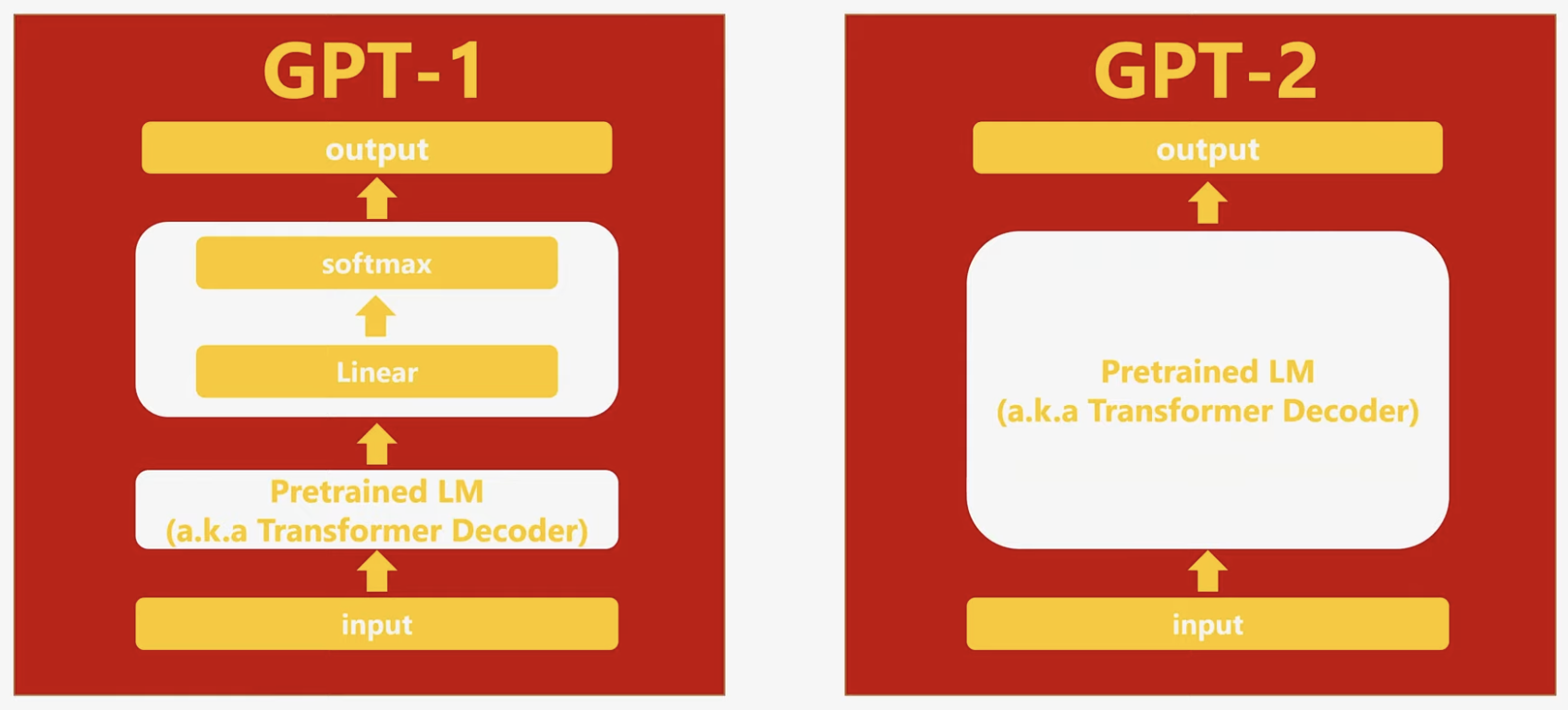
-
그래서 model이 학습하는 방식이 다름.
GPT2는 입력된 값과 수행해야 할 task를 함께 입력받아서 출력하게 되어 있음.
 위 논문의 설명을 그림으로 쉽게 설명하면,
위 논문의 설명을 그림으로 쉽게 설명하면,
((그림 출처 : https://www.youtube.com/watch?v=3n6157XNYyw&t=108s))

GPT-3
-
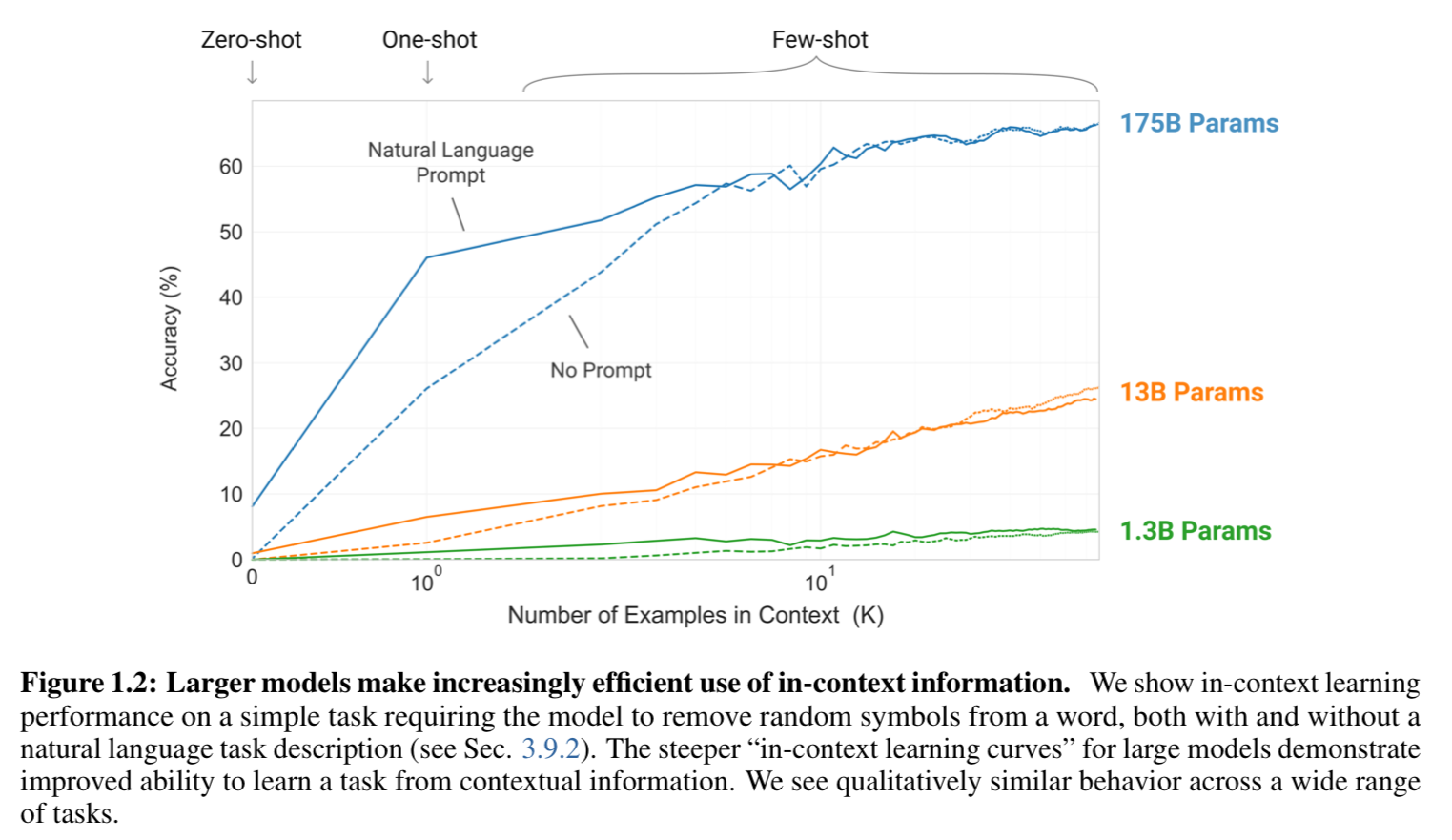
GPT-3는 few-shot learning을 통해 기존 LLM이 갖고 있던 finetuning의 한계점을 극복함

-
Few-shot learning이란?
(그림 출처 : https://www.youtube.com/watch?v=p24JUVgDkQk&t=706s)zero-shot:
젖소의 얼룩과 말이 합쳐진 말이 얼룩말이라는 것을 알고 있을 때,
얼룩말을 한 번도 보지 못했어도, 얼룩말을 처음 봤을 때 예측할 수 있음



one-shot:
원숭이를 한 번 봤으면, 또 다른 원숭이를 보고 원숭이라는 것을 알 수 있음


few-shot:
fine-tuning이 필요 없을 정도로,
"강아지 사진을 매우 많이 보여줘서, 강아지를 잘 예측할 수 있도록 하자"
-
사용한 data와 parameter를 매우 크게 늘려서 few-shot learning을 진행.
그래서 model은 fine-tuning 없이도 이미 특정 task에도 사용할 수 있도록 똑똑한 model이 됨.

Efficient Deep Learning