Linear Regression with One Variable
Regression
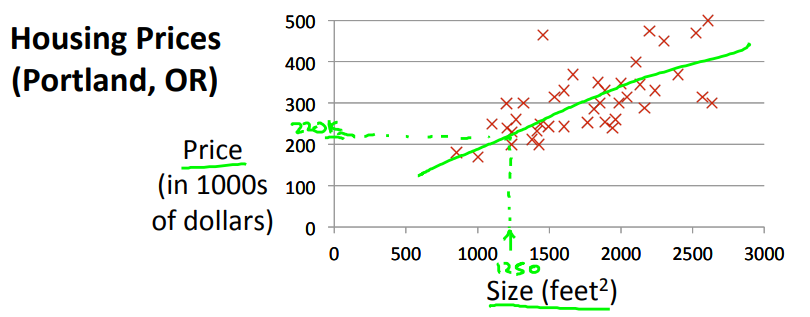
이전의 게시글에서 봤던 그래프이다.
이 그래프는 주택 평수당 가격에 대한 데이터이다.
-
여기서 1,250 의 집의 적합한 가격을 추측한다고 가정했을 때,
이런 상황에서 우리는 데이터에 맞는 모델을 찾기 위해 직선을 하나 그어서 그에 대응하는 가격을 추측할 수 있다. -
이러한 모델을 통해서 우리는 1,250 에 해당하는 적합한 가격이 $라고 예측할 수 있을 것이다.
-
이것이 Supervised Learning이라고 불리는 이유는 데이터에 대한 각각의 right answer을 받았기 때문이다.
이러한 예시가 지난 강의에서 다루었던 Supervised Learning(지도학습) 중 Regression(회귀)의 예시 중의 하나이다.
Training Set, wth Notation
Supervised Learning을 위해 주어지는 데이터를 Training Set이라고 한다.
Training Set으로부터 주택 가격을 예측하는 방법을 배우는 것이다.
➡️ 이 과정에서 우리가 사용하게 될 기호(표기 방법)를 정의한다

- : Number of Training Examples
- : Input Variable == Feature
- : Output Variable == Target
- : One Training Example
- ((), ()) : th Training Example
- ex. ((), ()) = (2104, 460)
Supervised Learning defined by Training Set
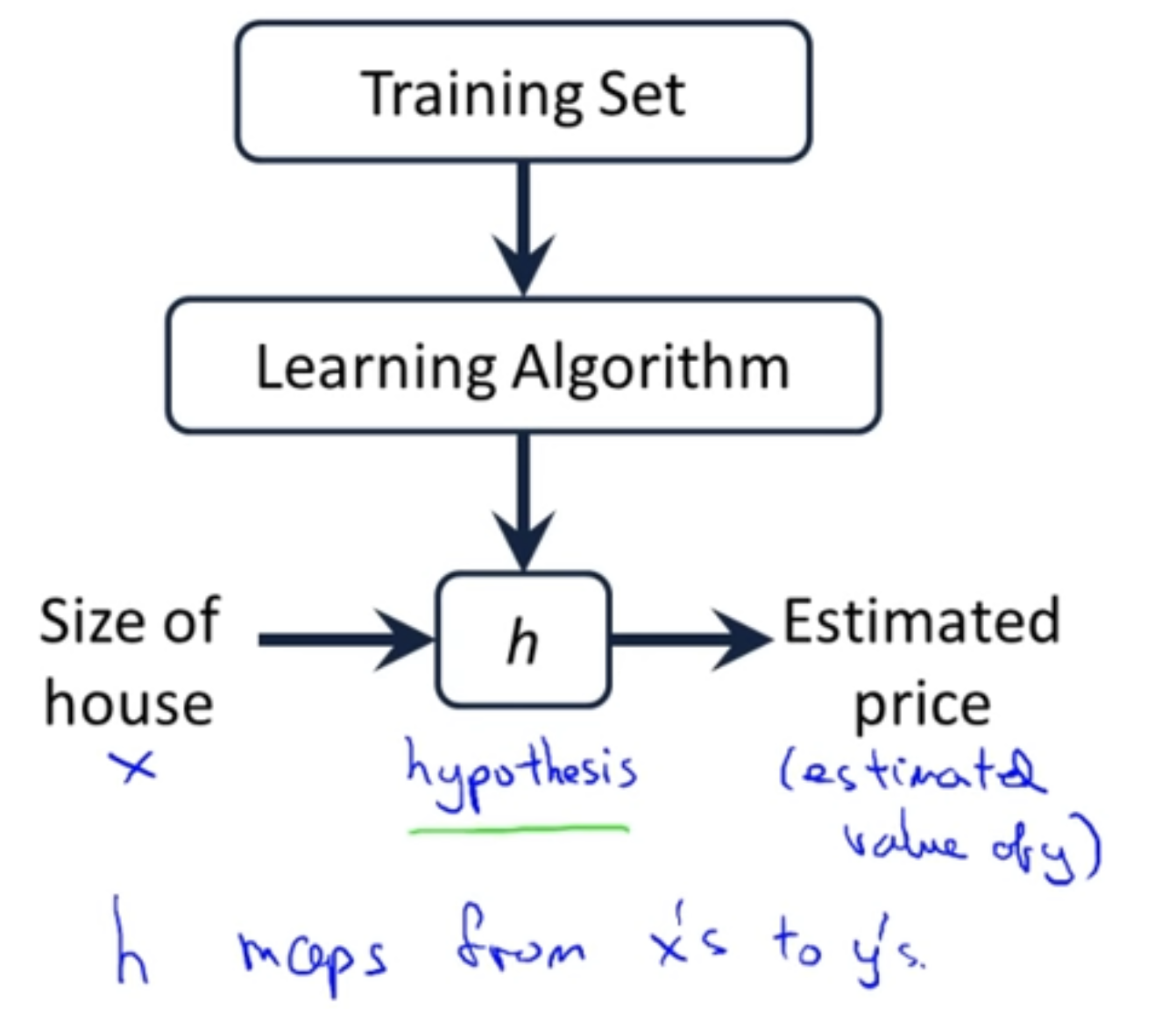
-
Supervised Learning은 Training Set을 Learning Algorithm에 적용하여 Output을 예측한다.
-
Learning Algorithm에는 일반적으로 hypothesis function이 존재한다.
-
: hypothesis function(가설 함수) : input 를 로 지도하는 역할.
Linear regression with one variable == Univariate linear regression (단순 선형회귀)
그렇다면 Hypothesis Function을 어떻게 나타낼 것인가?
➡️ 나중에 다룰 내용
우선 여기서는 (hypothesis function)를 다음과 같이 설정한다.
(shorthand) ➡️
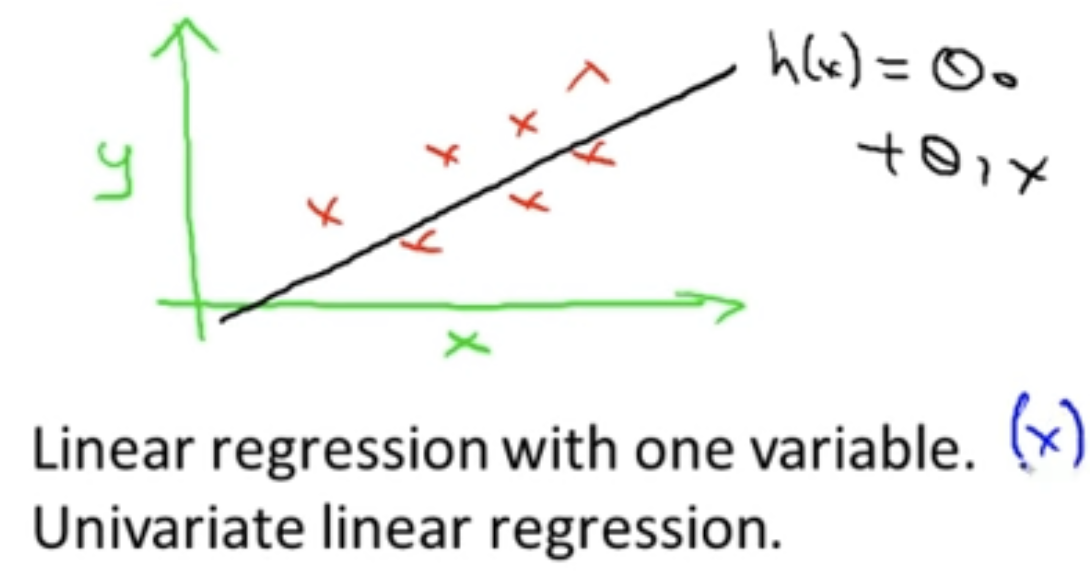
hypothesis function을 그래프로 나타내면, 다음과 같다.
-
그래프의 의미는 y가 x의 선형 함수라고 예측하는 것이다.
-
이러한 모델을
Linear Regression with one variable == Univariate Linear Regression == 단순 선형회귀라고 부른다.
Cost Function
