NeurIPS2024 - Invited Talks, Test of Time

Sepp Hochreiter - Toward Industrial Artificial Intelligence
- LSTM 만드신 분이다..
- Transformer로 LSTM은 완전히 잊혀졌지만
이번 NeurIPS2024에서 Transformer의 효율성, 효과성을 능가하는 xLSTM을 발표한다고 함.


industry : Basic development → scaling up → industrialization
AI도 3가지 phase가 있음
1. Basic Development
back propagation
CNN
RNN
LSTM
Transformer
...
2. Scaling up
이후 많은 연구들..
ResNet: big, deep neural network 가능해짐
attention mechanism, Transformer architecture:
prompt → generating video
convincing but no reality (ex. 개미 다리 4개)
LLM은 knowledge를 표현해내는 커다란 databse와 같다. (LLM은 AI를 더 발전시키진 못 할거다.)
3. Industrialization
- nXAI는 industrial를 위한 AI를 연구중. 이미 scaling up 되어 있음
industrial simulation
xLSTM? compared to transformer
- AI4Simulation: large-scale industrial simulations
AI는 industry-scale simulations을 방해하고 있다.
우리는 industry-scale을 위한 AI를 연구. (진짜 도움이 되는)
실제 physics와 똑같은 - xLSTM: efficient
Transformer disadvantages(quadratic, only pairwise interaction)
new xLSTM: LSTM limitations을 극복(https://arxiv.org/pdf/2405.04517)
(문제)revise storage decision: (해결)exponential gating
limited storage capacities: matrix memory & convariance update
no parallelization: remove memory & memory connection. update is memory indepent
- fastest. 느린 transformer보다는 embedded app에 가능성이 보임
xLSTM은 language를 넘어 industrial AI
Tom Goldstein - How to make a successful research paper

1. Ideation
- 연구의 최악은 high input low reward.
Tier-1 paper는 high reward
low input high reward면 좋지만, high input high reward도 좋음.
high reward일수록 좋음
예를 들어, Attention is all you need
2. Feedback & Literature Review
- paper 쓸 때, 관련 전문가의 조언을 꼭 들어야 한다
3. Do Research
- 실패하면 실패한 대로 paper가 될 수 있다.
왜 실패했는지? 뭐가 필요한지?
4. Write Paper
- 다른 paper의 outline을 cheating하라.
Heilmeier’s Catechism for Intros
- Why is the problem important?
- what is the problem?
- What is SOTA?
- Why is SOTA failing us?
- Describe what your solution is?
- Describe how your solution works
- Explain why your solution corrects the failure, summarize results
Creating the abstract
- Same as intro
but keep your methods, results, and SOTA numbers (concrete)
Titles and method names
use a dry and scientific title.
good ideas sell themselves.
Keep it short, keep it memorable!
(Sometimes some papers deserve a dry title)
Use descriptive name
ex) Random Token Dropout Loss(RTDL) → Goldfish Loss
RTDL처럼 줄이지 마라.. 사람들은 뭔지 모른다
goldfish loss처럼 차라리 어떤 의미를 담고 있는지가 중요하다
One Final Rule
Don’t follow all my rules!
Kaiming He - ML Research via the Lens of ML
- ResNet, Faster R-CNN, Mask R-CNN, Focal Loss, FPN, SPP 등 유명한 논문들의 저자이며
- 현재는 Associate Professor of the Department of Electrical Engineering and Computer Science (EECS) at Massachusetts Institute of Technology (MIT)

Research is SGD in a chaotic landscape
- 우리는 skip connection이 있는 network처럼 빠르게 수렴하길 원하지만…
우리는 꼭대기에서 initialization되고, 우리의 SGD는 매우 천천히 일어난다...
우리의 연구, 현실은 불안정한 상승임
큰 그림으로 봤을 때, 우리의 연구는 아주 일부분의 landscape
stand on shoulder of giants(큰 그림을 봐라)


ML concerns Expectations, Research looks for Suprise
- ML: Generative model은 “within expectation”
- Research:
“surprise”: unexpected attempt → novel possibility
Future is the Real Test Set
우리는 time axis를 신중히 다룬다. ML research에서도 마찬가지.
→ Generalization: At the Core of ML
model complexity가 증가할수록, train loss는 줄어들지만 val/test loss는 증가하는 overfitting
model은 train set을 계속 봐왔지만 val/test는 처음 봄
“우리”도 마찬가지임
우리는 paper, baseline이라는 train set을 보지만, 우리의 연구는 future를 보기는 힘듦

- Reduce “overfitting” of your research
Less is More - validate your research on real “val” scenarios
you know what’s “post-hoc” and “pre-hoc” - Focus on the “future”
your “SOTA” is about the pas
help the community to achieve the next “sota”
On the Scaling Laws of ML Research
ResNet, 2015 8x K80 GPU에 1달 이상 걸림
ResNet,2020 1000’s A100 GPUs에 1분 미만 걸림
옛날에는 AlexNet 60M을 big models이라고 불렀지만
지금은 TinyLlama 1.1B를 small Language model(SLM)이라고 부름…
“Large/Small” should be put into context, of the history
“우리는 very small이라는 것을 나중에는 어떻게 정의하고 느낄까?”
Moore의 법칙을 적용하면,,,
GPT traing을 우리 핸드폰에서 한 시간이면 끝낼 수 있을까?
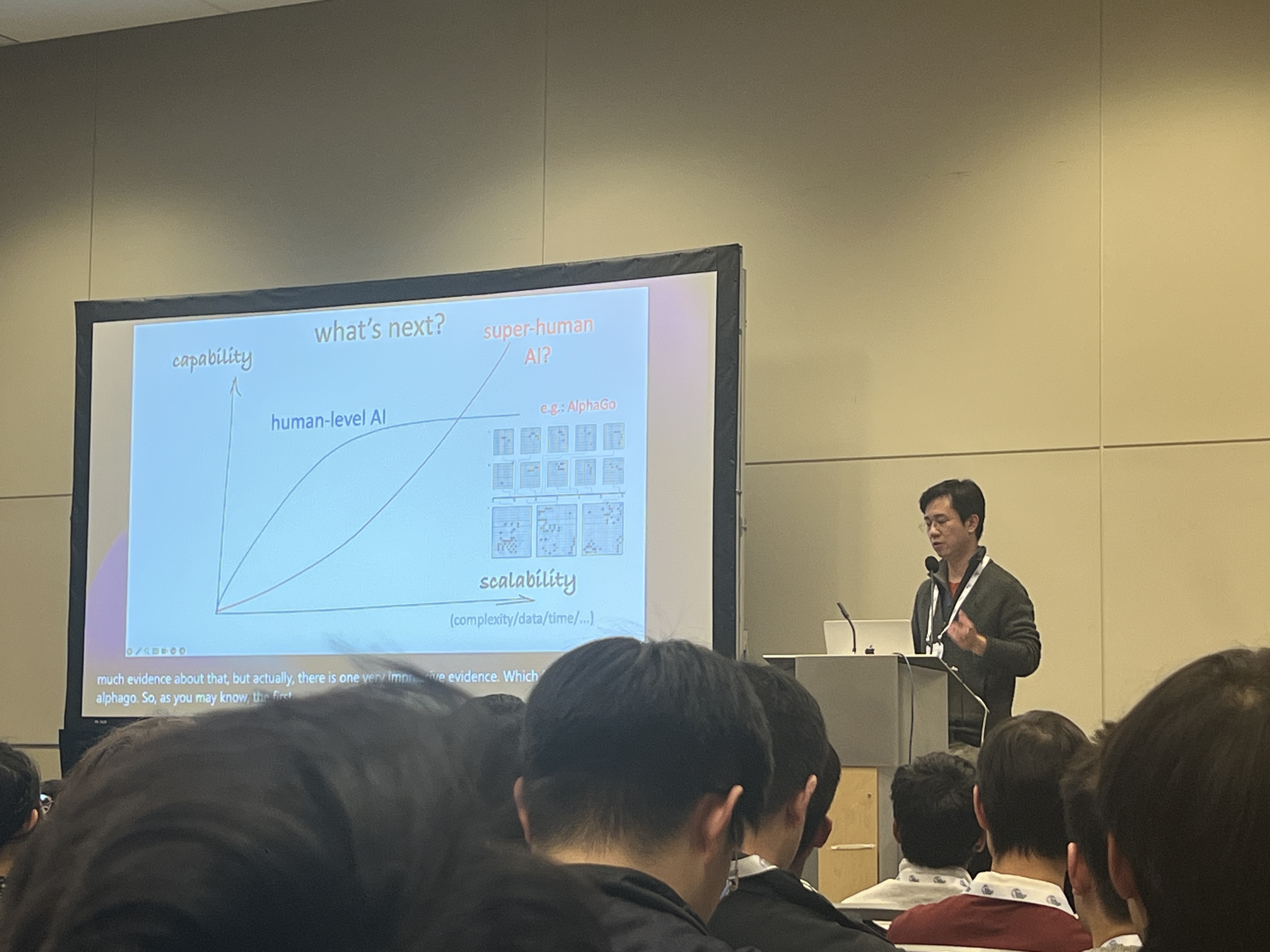
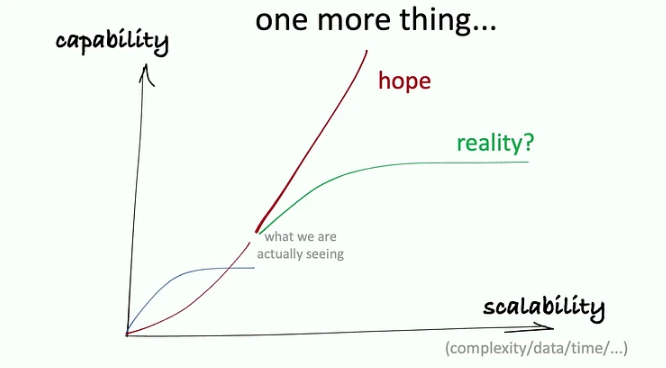
1. Alphago가 증거이고, super human AI를 넘어설 수 있을 것이다
2. ML에는 실제로 capability의 한계가 있을 것이다
Q & A
- LLM은 인간을 지배할 수 있는가?
human이 real world를 관찰하고, 표현한 것으로 LLM은 학습된다.
human은 sensor이다.
그렇기 때문에 LLM은 우리가 없으면 볼 수가 없다.
Fei-Fei Li - From Seeing to Doing: Ascending the Ladder of Visual Intelligence
ImageNet 만드신 분이다

-
understanding
human development depends on visual intelligence
real problem is generalization
That was the imagenet project rolled out in 2009
data is import for learning
representational learning:
ex) From ResNet to MAE to SiamMAE -
reasoning
What is beyond object recognition?
scene graph representation -
Next is
generation
language model 발전 전에, 우리는 Scene graph to Image: Model
3 Rung Ladder of visual intelligence
data ↔ (generation, reasoning, generation) ↔ algorithm
근본적으로 language is just documnet
“A flat earth” problem
fei fei “3D world에 대해 영감을 주고 싶었다..”
인간은 earth가 3D로 되어있다는 것을 명심해야 함.
결론: 3D understanding & reasoning, Generation을 자신의 학생들이 이번 학회에서 발표함...
Lidong Zhou - A Match Made in Silicon: The Co-Evolution of Systems and AI
-
Dr. Lidong Zhou is a Corporate Vice President at Microsoft,
Chief Scientist of the Microsoft Asia Pacific R&D Group,
and Managing Director of Microsoft Research Asia.
(https://www.microsoft.com/en-us/research/people/lidongz/) -
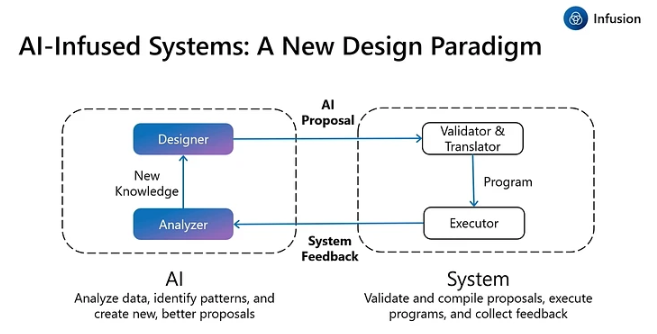
AI의 발전은 AI 기술의 발전으로만 이루어지면 안된다.
system과 공생하며 발전해야 한다.
system에서 돌아갈 수 있도록 하는 것이 우리의 궁극적인 목표...




Test ot Time
- 10년 전 NeurIPS2014에 발표한 논문들 중에서 10년 동안 큰 영향력을 준 논문들에 대한 시상

1. Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair†, Aaron Courville, Yoshua Bengio
Generative Adverserial Nets저자 중 David Warde-Farley가 강연했다.
2. Ilya Sutskever, Oriol Vinyals, Quoc V. Le
- Ilya Sutskever는 OpenAI의 공동 설립자
- 10년 전 NeurIPS2014에 발표한
Sequence to Sequence Learning with Neural Networks논문

