Input-level Feature Enhancement(blurring filter & sharpening filter)
original prediction vs. gaussian filtered prediction
- 모든 gaussian filter setting은
gaussian_teacher = transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0))
gaussian_rgb_tensor = gaussian_teacher(rgb_tensor)
results_gaussian = model([gaussian_rgb_tensor])-
원본 image를 더하지 않은 이유 : blurring을 통해 noise (small features)들을 제거하기 위한 목적이기 때문에 fitered image에 원본 image를 element-wise sum하는 것은 오히려 더 안좋은 효과를 준다.
원본 image에서 medium, large feature들에 대한 선명함을 blurring하는 효과만 부여하는 것이기 때문 -
하지만 canny filter는 element-wise를 해야 한다.
(이유는 밑에..)
Example 1
Ground Truth
- bicycle 2개
- car 2개
- bottle 3개
- ...

original vs. gaussian filtered
- original : bicycle 2개 중에 0개 detection
- gaussian : bicycle 2개 중에 1개 detection
- original : car 2개 중에 1개 detection (한 개를 중복해서 detection, 나머지 하나는 못 함)
- gaussian : car 2개 중에 1개 detection (한 개를 정확히 detection, 나저미 하나는 못 함)
- original : bottle 3개 중에 2개 detection
- gaussian : bottle 3개 중에 1개 detection
- original :
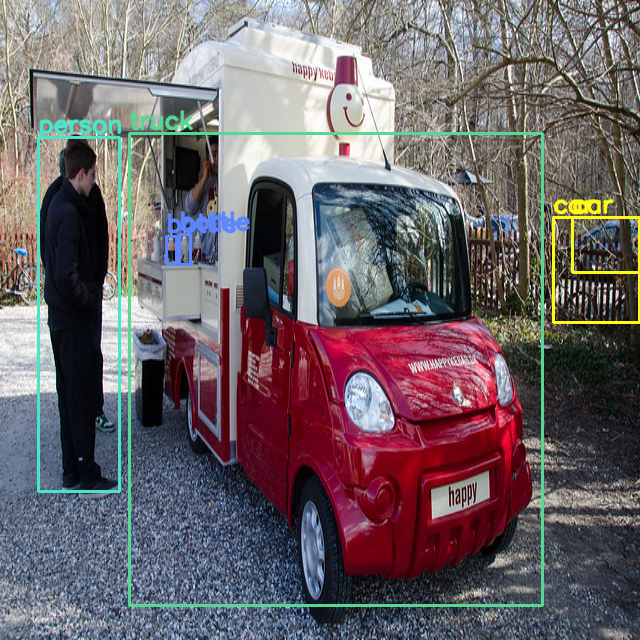
- gaussian filtered :

- original :
gaussian filter를 적용한 prediction은 noise를 제거하는 효과로 인해,
original prediction은 small box(ex. bottle)를 더 잘 detection 하고,
gaussian filtered-prediction은 medium 그리고 large box(ex. bicycle)를 더 잘 detection 한다.
Example 2
Ground Truth
- person 3
- handbag 1
- traffic light 0
- umbrella 4
- bird 10 이상

original vs. gaussian filtered
- original : person 3명 중 2명 detection (한 명을 두 명으로 detection함.)
- gaussian : person 3명 중 3명 detection
- original : handbag 1개 중 0개 detection
- gaussian : handbag 1개 중 1개 detection
- original : traffic light 0개 중 1개 detection
- gaussian : traffic light 0개 중 0개 detection
- original : umbrella 4개 중 2개 detection
- gaussian : umbreela 4개 중 1개 detection
- original : 중복 bird를 많이 detection, 하지만 person이 들고 있는 bird 2마리는 정확히 detection
- gaussian : 비교적 bird를 중복 detection하지 않음, 하지만 person이 들고 있는 bird 2마리를 dog로 detection
- original :
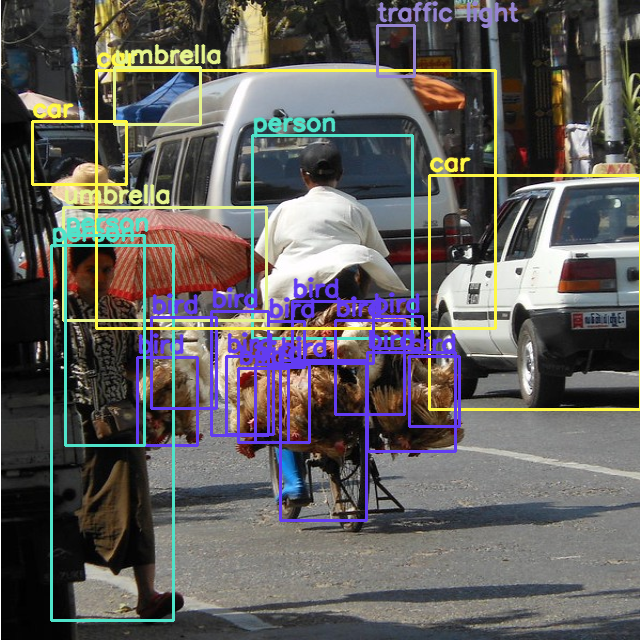
- gaussian filtered :
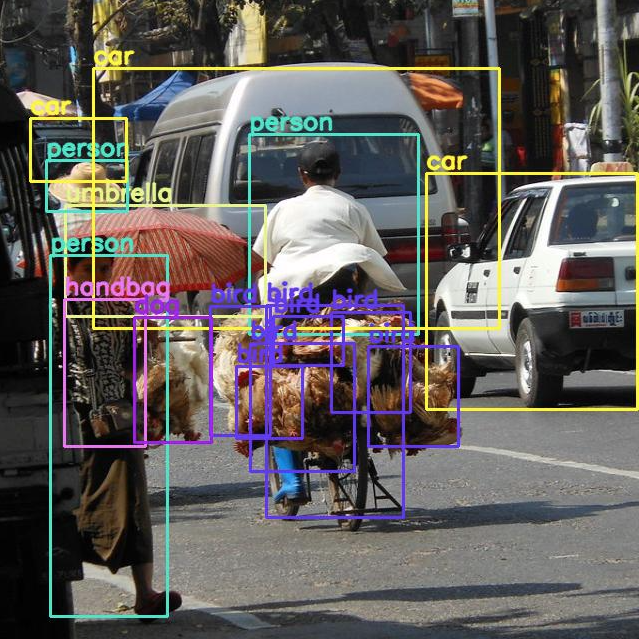
- original :
마찬가지로
gaussian filter를 적용한 prediction은 noise를 제거하는 효과로 인해,
original prediction은 small box(ex. bottle)를 더 잘 detection 하고,
gaussian filtered-prediction은 medium 그리고 large box(ex. bicycle)를 더 잘 detection 한다.
Example 4
Ground Truth

original vs. gaussian filtered
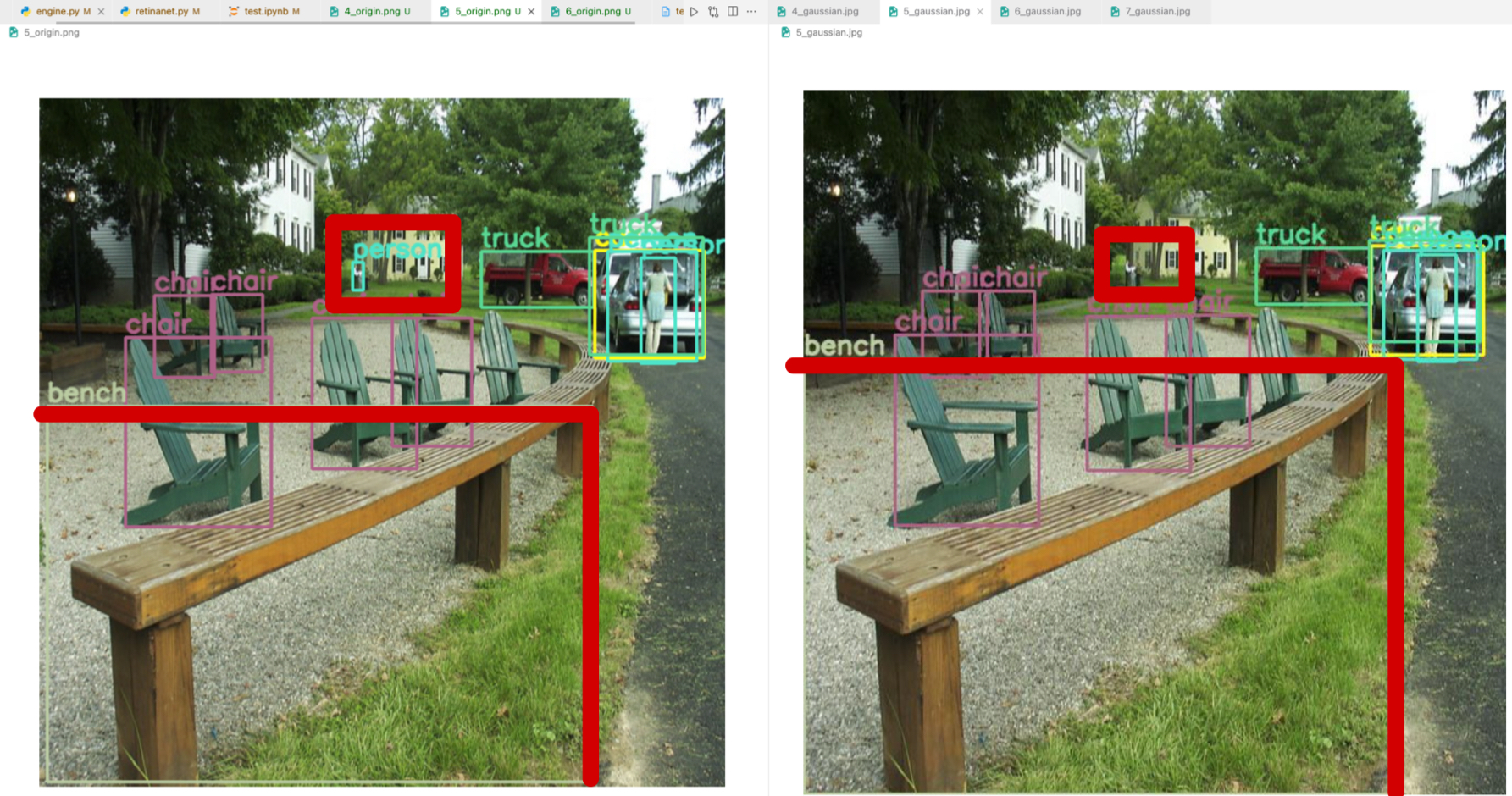
- original : bench가 더 넓지만 조금만 detection함.
- gaussian : bench를 더 넓게 detection함.
- original : person 2명 중 1명 detection
- gaussian : person 2명 중 0명 detection
마찬가지로
gaussian filter를 적용한 prediction은 noise를 제거하는 효과로 인해,
original prediction은 small box(ex. bottle)를 더 잘 detection 하고,
gaussian filtered-prediction은 medium 그리고 large box(ex. bicycle)를 더 잘 detection 한다.
Example 5
Ground Truth

original vs. gaussian filtered
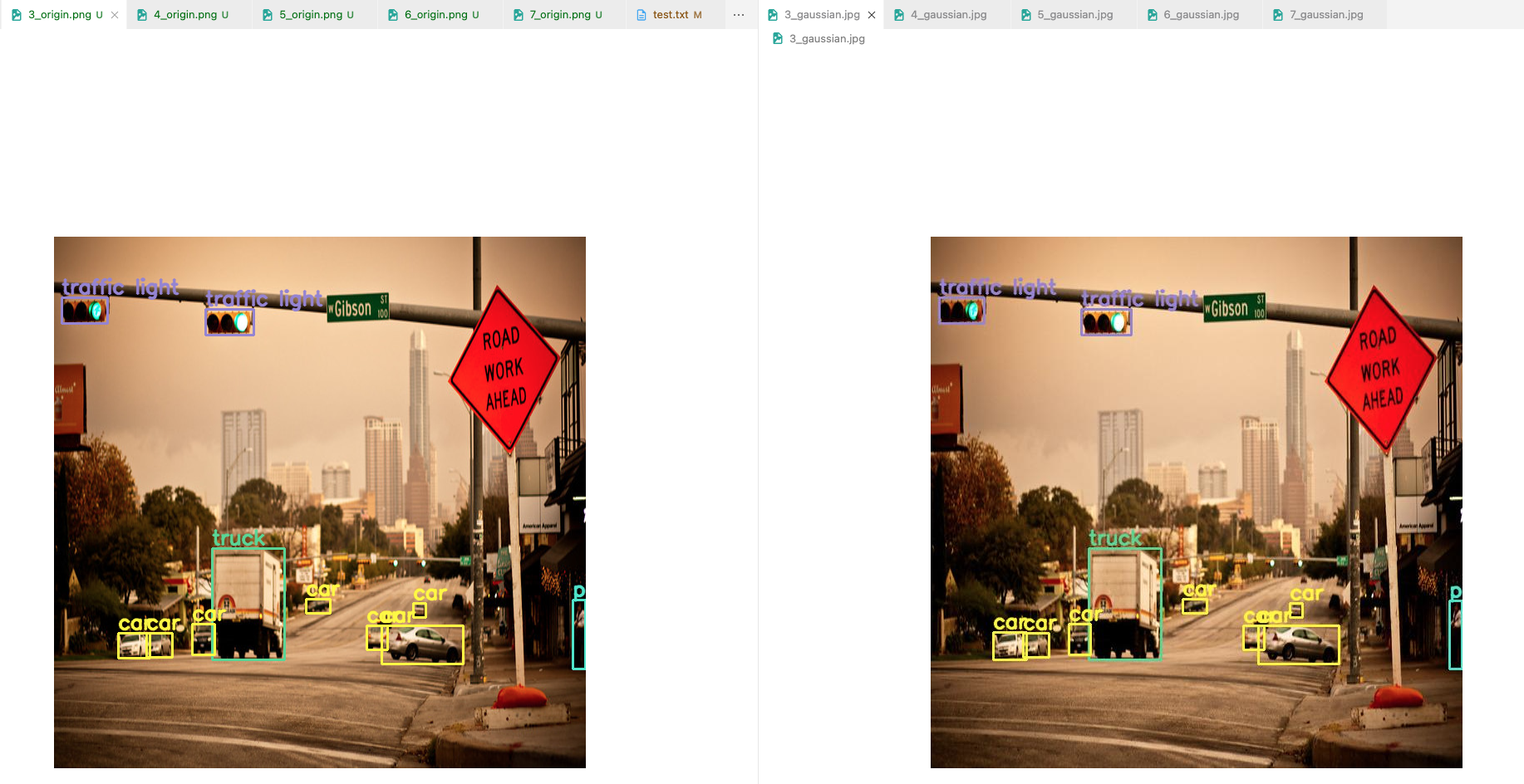
- 그렇다고, gaussian filtered prediction이 small object detection을 많이 못하는 것은 아님.
왼쪽이 original, 오른쪽이 gaussian인데
작은 box의 car들을 똑같이 잘 detection할 수 있음.
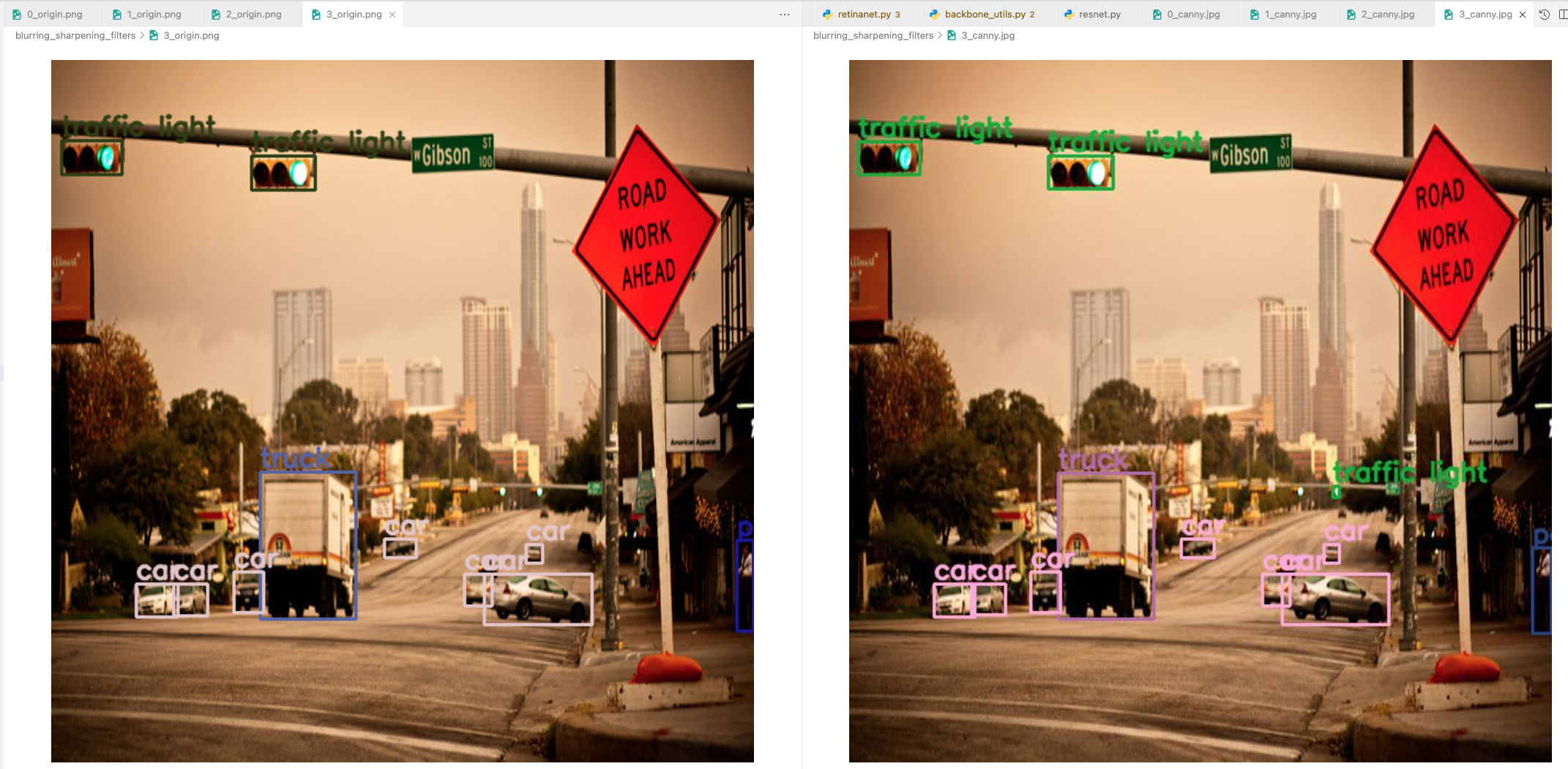
original prediction vs. Canny filtered prediction
- 모든 Canny filter setting은
rgb_tensor = torch.from_numpy(rgb_img)
canny_teacher = cv2.Canny(rgb_img, 100, 200)
canny_teacher = torch.from_numpy(canny_teacher)
# torch([640, 640]) -> torch([640, 640, 1])
canny_teacher = canny_teacher.unsqueeze(2)
rgb_tensor = rgb_tensor + canny_teacher
rgb_tensor = rgb_tensor.numpy()
results_canny = model([rgb_tensor])- 원본 image를 더한 이유 : canny filter의 결과는 다음과 같다.

- 위 small feature들만을 forward한다면 background도 object라고 인식될 수 있다
- medium, large object에 대한 정보를 완전히 잃어버린다.
그렇기 때문에 원본 image에 filtered image를 더해서 small feature가 더욱 강화되도록 만들어야 한다.
Example 1
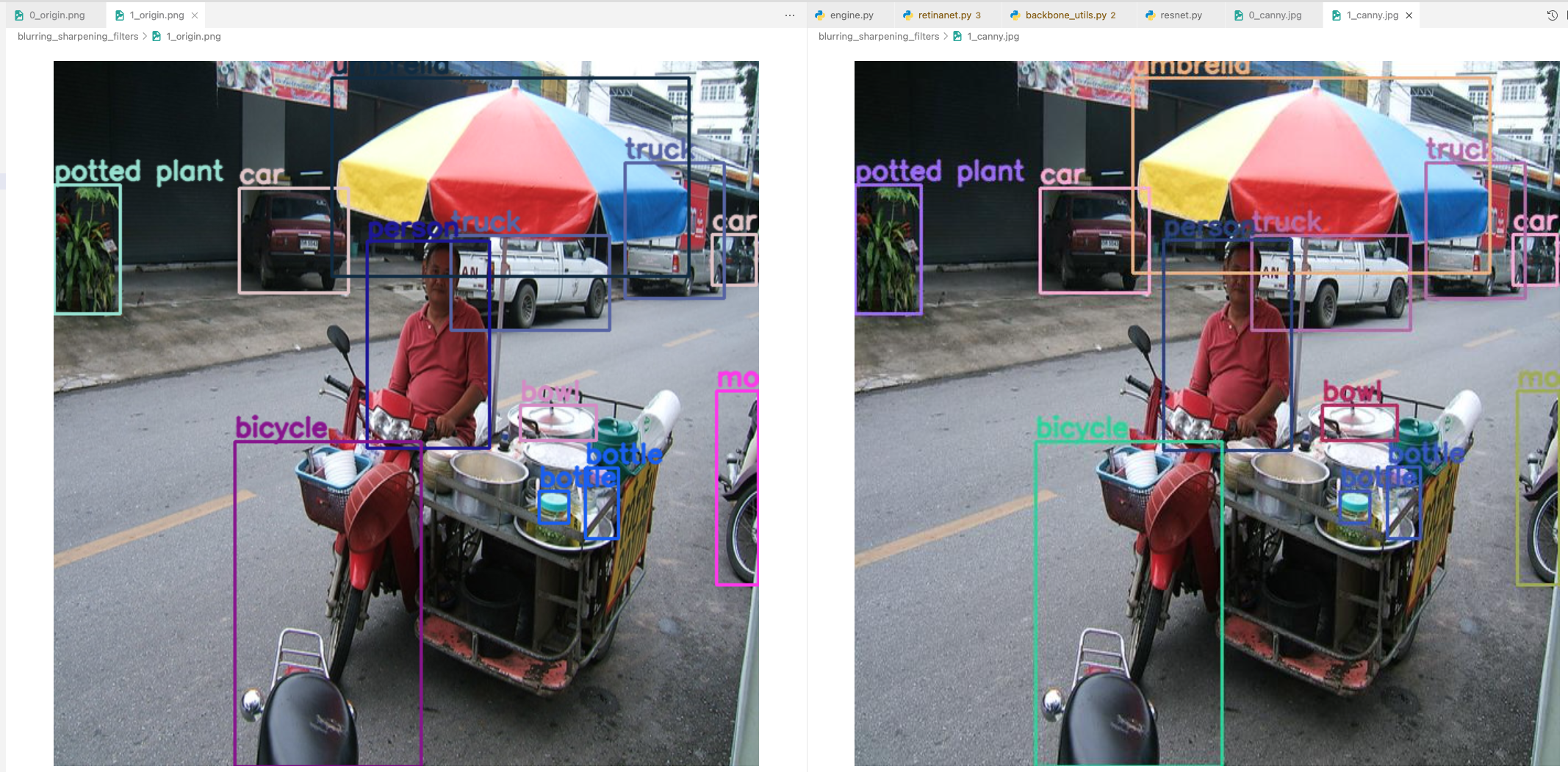
- image += Canny(image)는 person이 없는데 있다고 detection함

Example 2, 3, 4, 5
- original과 똑같이 detection해냄

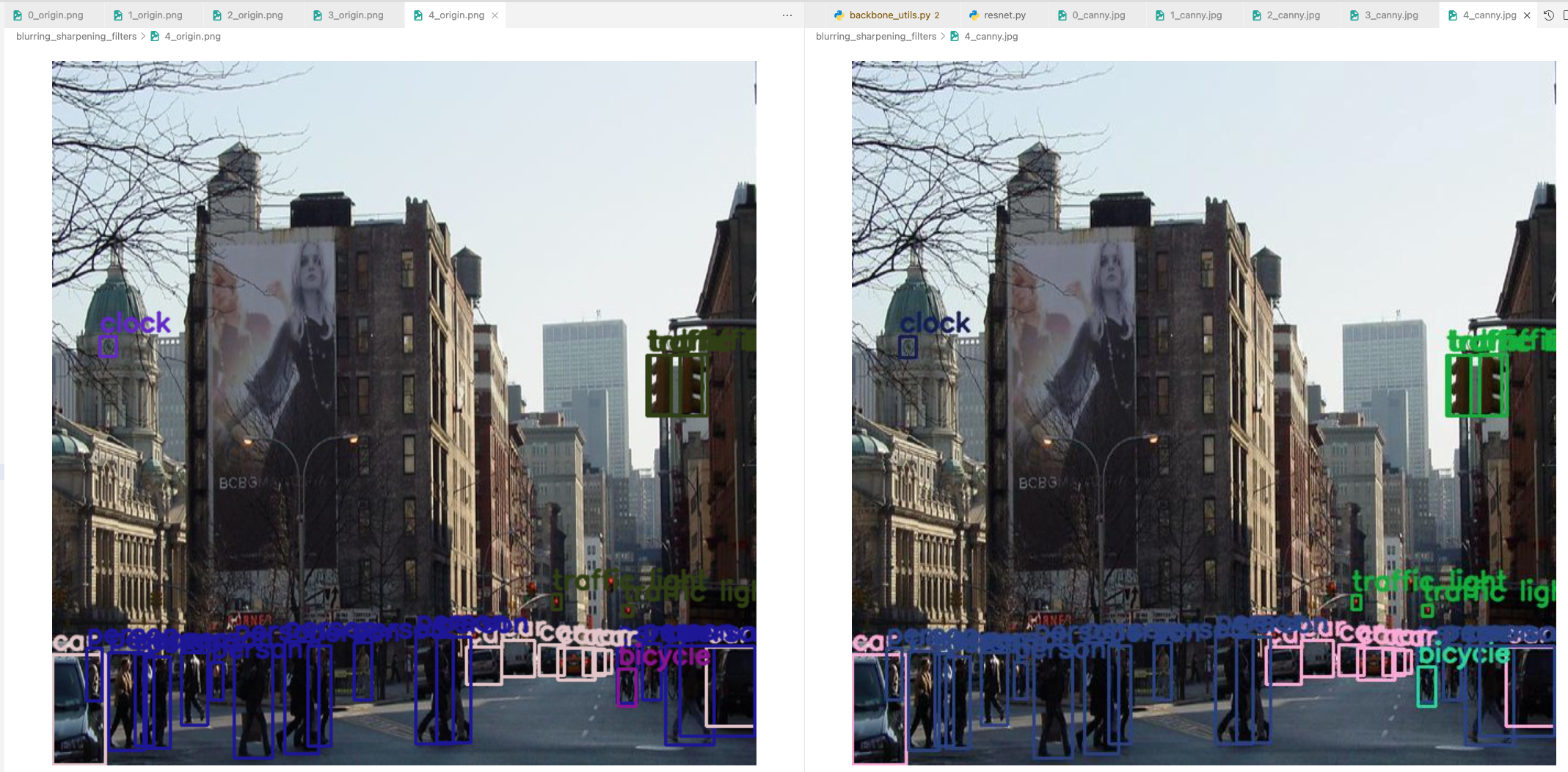
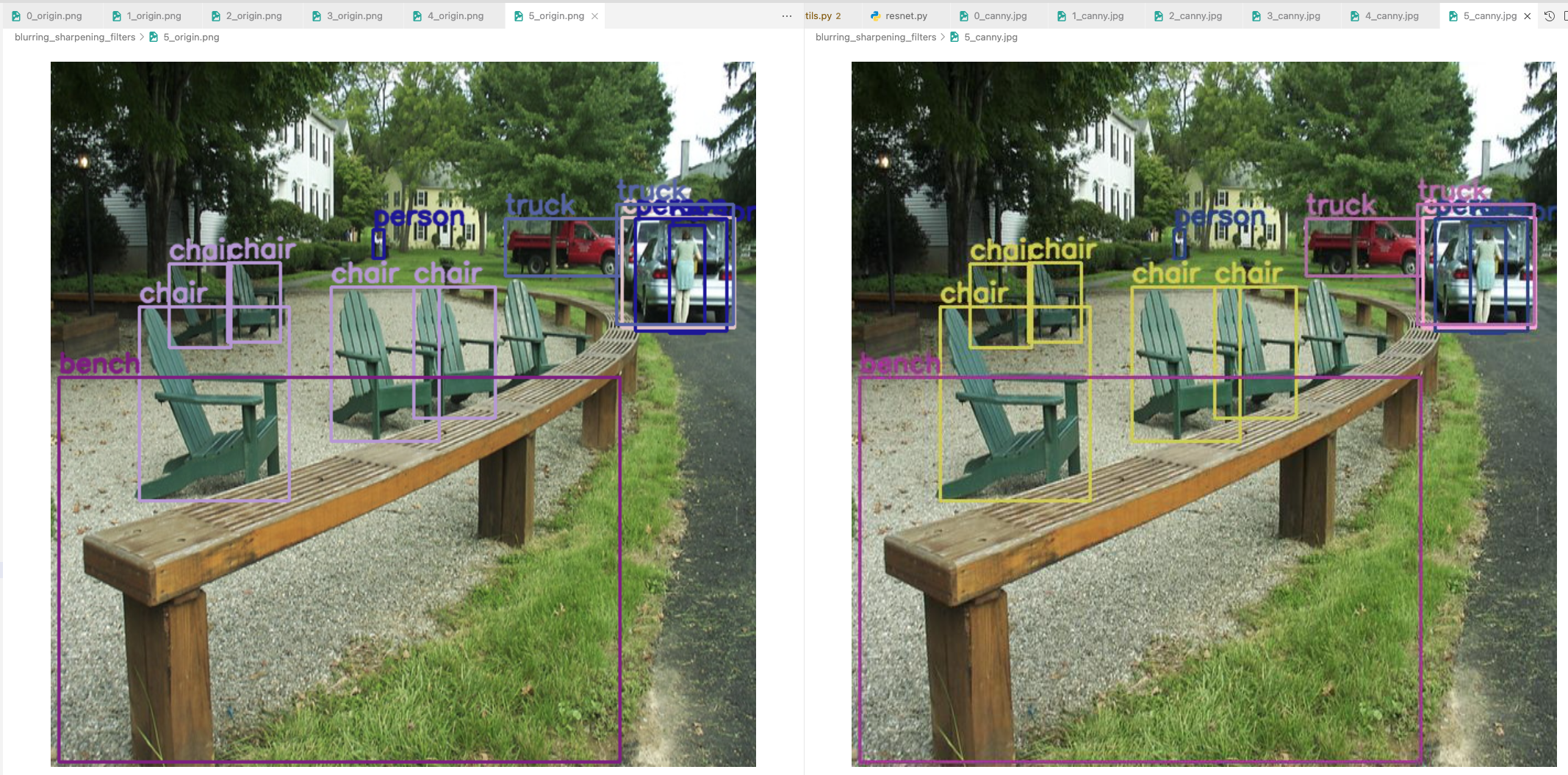
Example 6
- original에서 못찾았던 매우 작음 traffic light를 detection해냄