Supervised Learning
Supervised Learning(지도 학습)
Supervised Learning :
dataset의 모든 example에 대하여 right answer를 제공하여
이러한 right answer를 더 많이 생성하도록 하는 것이다.
즉, 기존 data를 토대로 새로운 input에 대한 output을 추측하는 것이다.
Regression(회귀)
Regression == Predict Continuous Valued Output
회귀는 연속적인 값을 예측하는 것이다.
Examples : Housing Price Prediction
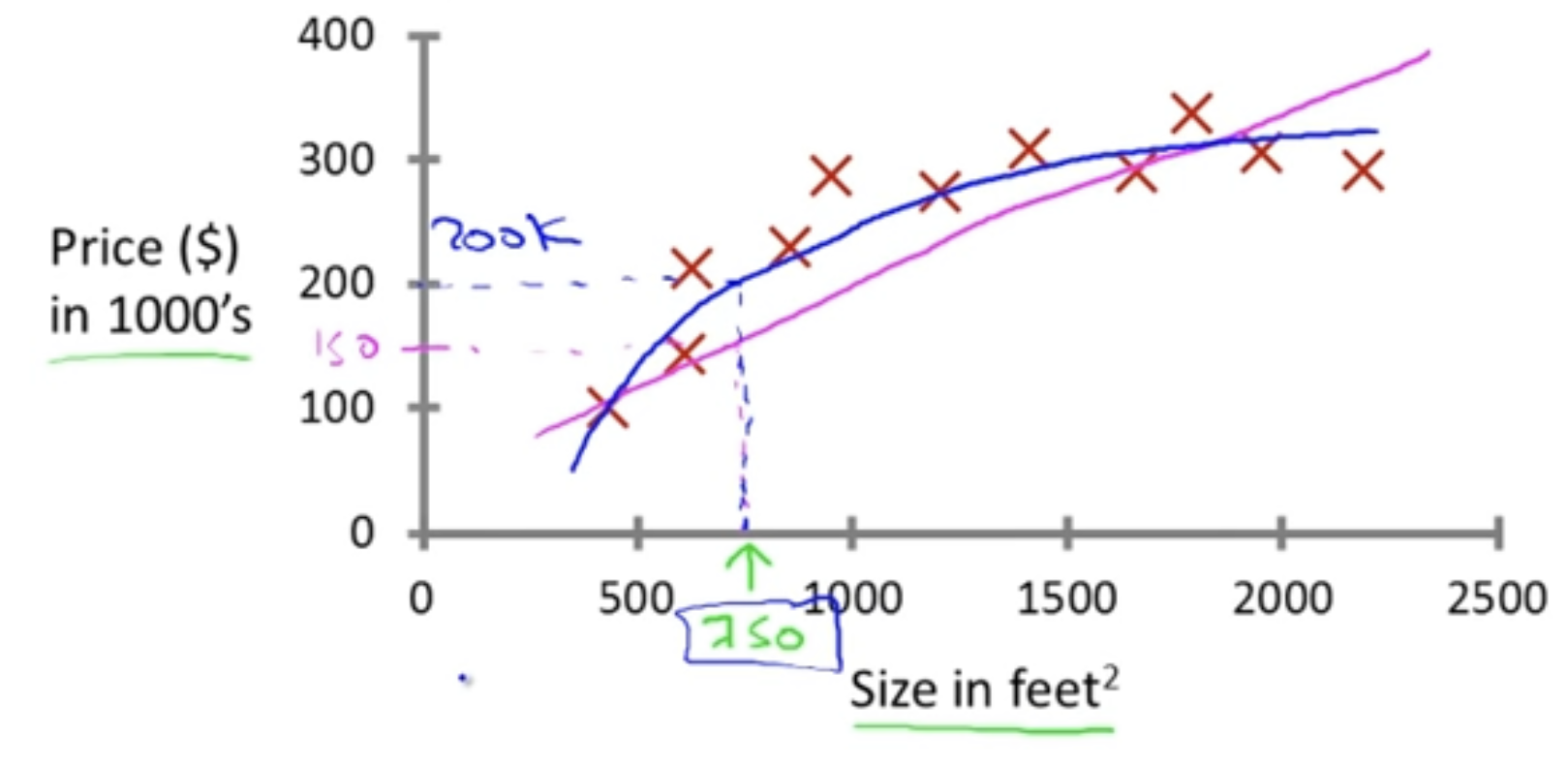
- : 주택 평수
- : 주택 가격
- X : dataset
➡️ 새로운 input data로 750의 주택 정보가 들어왔을 때, 그 주택이 약 200k$ 일 것이라는 예측을 할 수 있는 것이다.
➡️ 학습 알고리즘으로 1차함수(보라색)가 아닌 2차함수(파란색)에 데이터를 맞춘다면
더 예측을 가깝게 할 수 있을 것이다.
➡️ 이렇게 데이터를 직선에 맞출 것인지 다항 함수에 맞출 것인지에 따라 예측 정확성이 달라지니, 이를 어떻게 결정하고 고르는지에 대한 방법도 나중에 다룰 것이다.
Classification(분류)
Classification == Predict Discrete Valued Output
분류는 이산적인 값으로 예측하는 것이다.
Example : Breast Cancer
One Feature Classification
: 유방암 판단 기준 ➡️ 1. Tumor Size
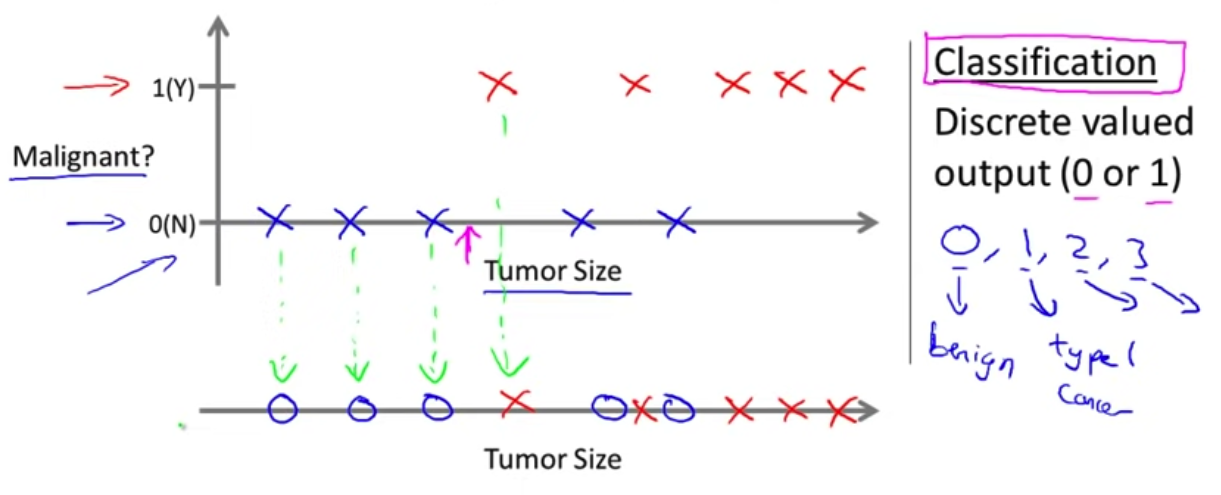
: Tumor Size(종양 크기)
: Malignant(유방암 양성? 음성?)
X : 양성
X : 음성
➡️ 새로운 input data로 ⬆️ 크기의 Tumor Size가 들어왔을 때, 그 환자가 유방암인지? 아닌지? 이산적인 결과로 예측(분류)할 수 있는 것이다.
➡️ output으로 (0 or 1) 유방암인지? 아닌지?
대신에 (0 or 1 or 2 or 3)으로 하여 유방암인지? 아닌지? 유방암이라면 어떤 Type의 유방암인지?
의 형태와 같이 분류를 2개 이상으로 결정할 수도 있다.
➡️ ⬇️로 연결된 그래프처럼 기호를 사용하여 축으로만 그래프 표현이 가능하다.
Multiple Features Classification
: 유방암 판단 기준 ➡️ 1. Tumor Size, 2. Age, ... (Infinite)
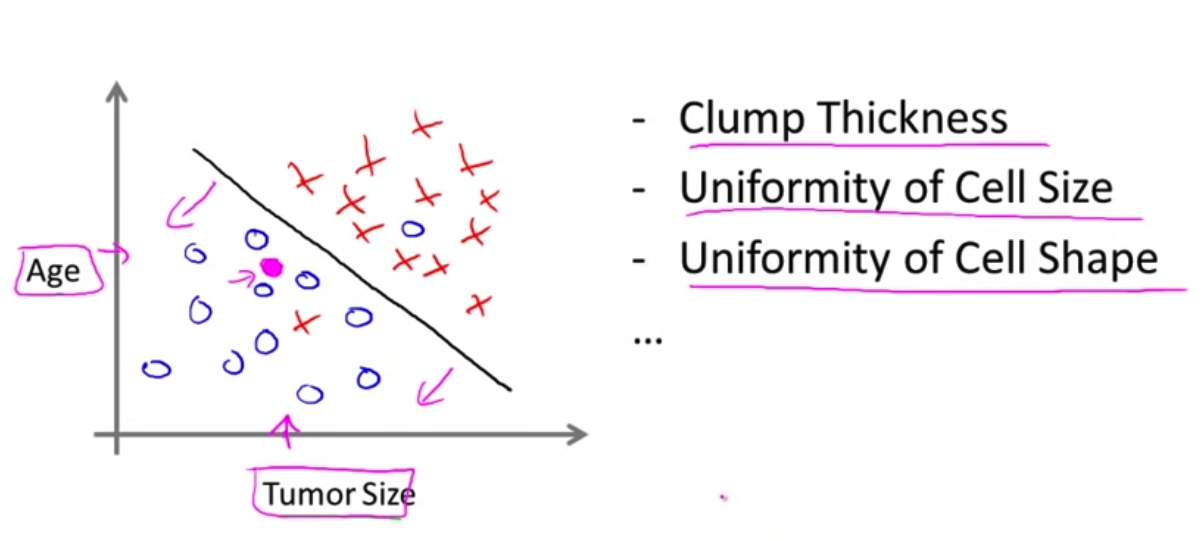
➡️ 위 그래프는 'Tumosr Size'와 'Age' Feature를 지표로 한 유방암 결과 분류이다.
➡️ 'Tumosr Size'와 'Age' Feature 말고도
'Clump Thickness(종양 두께)', 'Uniformity of Cell Size(세포 크기의 균일성)', 'Uniformity of Cell Shape(세포 모양의 균일성)' 등 여러 Feature가 복합적으로 유방암 결과를 분류할 수 있다.
➡️ 중요한 것은 무한대의 Features를 처리할 수 있는 Support Vector Machine(SVM)이라는 학습 알고리즘이 존재한다.
Quiz
: 어떤 학습 알고리즘을 적용해야하는지 판단하시오.

Answer : Treat as a Regresesion Problem

Answer : Treat as a Classification Problem (hacked? not hacked?)
