정렬
정렬이란 데이터를 특정한 기준에 따라서 순서대로 나열하는 것을 의미한다.
정렬 알고리즘으로 데이터를 정렬하면 이진 탐색(Binary Search)가 가능해진다.
이 페이지에서는 여러 정렬 알고리즘 중 퀵정렬, 병합정렬, 쉘정렬, 힙정렬, 계수정렬에 대해서 공부
- Selection Sort (선택정렬)
- Insertion Sort (삽입정렬)
- Bubble Sort (버블정렬)
- Quick Sort (퀵정렬)
- Merge Sort (병합정렬)
- Shell Sort (쉘정렬)
- Heap Sort (힙정렬)
- Count Sort (계수 정렬)
퀵정렬
설명 :
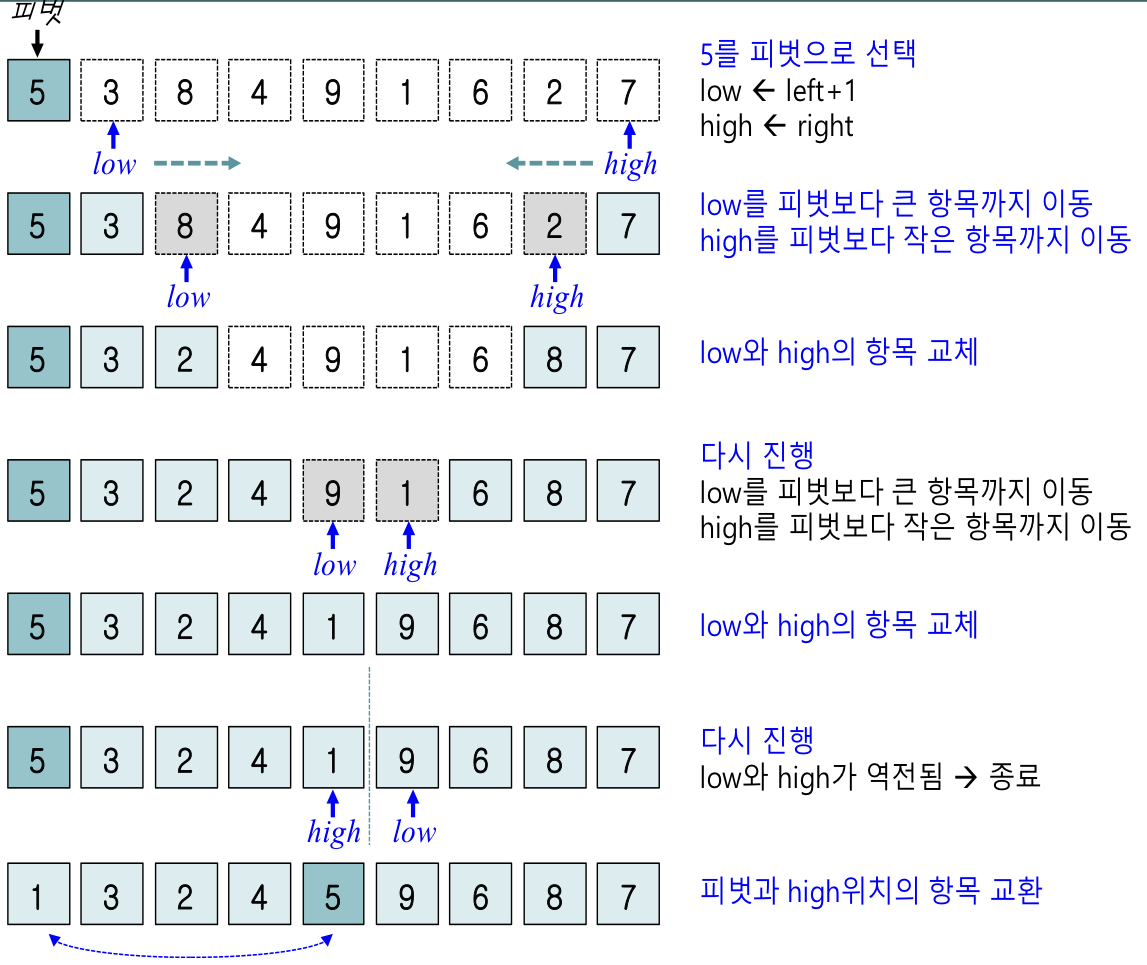
평균적으로 가장 빠른 정렬 방법
분할 정복법(Divide and Conquer) 사용
리스트를 2개의 부분 리스트로 비균등 분할하고, 각각의 부분 리스트를 다시 퀵 정렬(재귀 호출)
시간 복잡도 :
최선의 경우 : 균등한 리스트로 분할되는 경우
최악의 경우 : 불균등한 리스트로 분할되는 경우 (이미 정렬된 리스트)
전체 시간복잡도 :
단, 대부분 정렬되어 있는 리스트를 정렬할 때 으로 매우 비효율적이다
C++로 구현한 퀵정렬 :
#include <iostream>
using namespace std;
void showArr(int _arr[], int _size) {
for (int i = 0; i < _size; i++)
{
cout << _arr[i] << " ";
}
cout << endl;
}
void swap(int _arr[], int a, int b){
int temp = _arr[a];
_arr[a] = _arr[b];
_arr[b] = temp;
}
void quickSort(int _arr[], int start, int end, int _size) {
int pivot = start;
int low = start + 1;
int high = end;
if(start >= end){
return;
}
while(low <= high) {
// pivot보다 low index의 값이 더 크면 break
while((_arr[pivot] >= _arr[low]) && (low <= end)) {
low++;
}
// pivot보다 high index의 값이 더 작으면 break
while((_arr[pivot] <= _arr[high]) && (high >= start + 1)) {
high--;
}
if(low <= high){
swap(_arr, low, high);
}
cout << "pivot : " << _arr[pivot] << " ";
showArr(_arr, _size);
}
swap(_arr, pivot, high);
cout << "pivot : " << _arr[high] << " : ";
showArr(_arr, _size);
quickSort(_arr, start, high - 1, _size);
quickSort(_arr, high+1, end, _size);
}
int main(void) {
int arr[] = {5, 3, 8, 5, 9, 1, 6, 2, 7};
int size = sizeof(arr) / sizeof(arr[0]);
cout << "[before] : " ;
showArr(arr, size);
quickSort(arr, 0, size-1, size);
cout << "[after] : ";
showArr(arr, size);
return 0;
}Python으로 구현한 퀵정렬 :
arr = [5, 3, 8, 5, 9, 1, 6, 2, 7]
def quickSort(arr) :
# list가 하나 이하의 원소만 담고 있으면 종료
if len(arr) <= 1 :
return arr
pivot = arr[0]
tail = arr[1:] # 피벗을 제외한 나머지 리스트
left = [x for x in tail if x <= pivot] # 분할된 왼쪽 부분
right = [x for x in tail if x >= pivot] # 분할된 왼쪽 부분
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행하고, 전체 리스트 반환
return quickSort(left) + [pivot] + quickSort(right)
print(quickSort(arr))병합정렬
설명 :
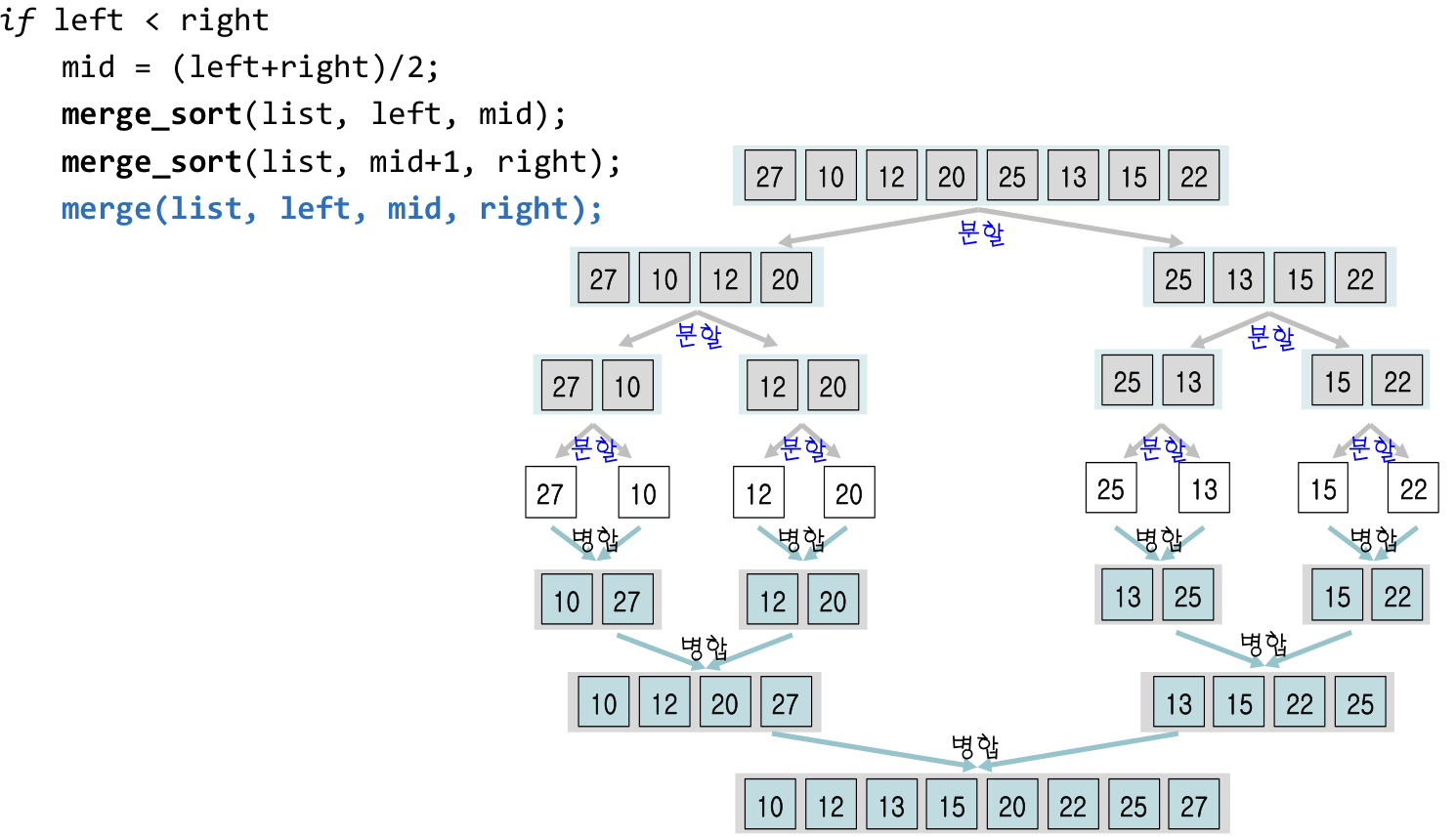
분할 정복법(Divide and Conquer) 사용
리스트를 2개의 부분 리스트로 균등 분할하고, 각각의 부분 리스트를 다시 병합정렬(재귀 호출)
시간 복잡도 :
전체 시간복잡도 :
최적, 평균, 최악의 경우 차이가 없다.
C++로 구현한 병합정렬
#include <iostream>
using namespace std;
void showArr(int _arr[], int _size) {
for (int i = 0; i < _size; i++)
{
cout << _arr[i] << " ";
}
cout << endl;
}
void swap(int _arr[], int a, int b){
int temp = _arr[a];
_arr[a] = _arr[b];
_arr[b] = temp;
}
void merge(int _arr[], int _copy[], int left, int mid, int right) {
int lidx = left;
int lstart = left;
int lend = mid;
int ridx = mid + 1;
int rstart = mid + 1;
int rend = right;
int cidx = left;
while(1) {
// lidx와 ridx가 범위를 넘어가면 종료
if(lidx > lend && ridx > rend){
break;
}
// lidx가 범위를 넘어가면 ridx만 copy 배열에 병합
if(lidx > lend) {
_copy[cidx] = _arr[ridx];
cidx++;
ridx++;
}
// ridx가 범위를 넘어가면 lidx만 copy 배열에 병합
else if(ridx > rend) {
_copy[cidx] = _arr[lidx];
cidx++;
lidx++;
}
// lidx, ridx 둘 다 범위 안에 있으면 더 작은 값부터 copy 배열에 병합
else {
if(_arr[lidx] < _arr[ridx]){
_copy[cidx] = _arr[lidx];
cidx++;
lidx++;
}
else {
_copy[cidx] = _arr[ridx];
cidx++;
ridx++;
}
}
}
// 병합하여 정렬된 리스트를 원본 배열에 복사
for (int i = left; i <= right; i++)
{
_arr[i] = _copy[i];
}
}
void mergeSort(int _arr[], int _copy[], int start, int end) {
// 더이상 분할할 수 없으면 return
if(start == end){
return;
}
// 균등 분할
mergeSort(_arr, _copy, start, (start+end)/2);
mergeSort(_arr, _copy, (start+end)/2 + 1, end);
// 병합
merge(_arr, _copy, start, (start+end)/2 , end);
}
int main(void) {
int arr[] = {5, 3, 8, 5, 9, 1, 6, 2, 7};
int size = sizeof(arr) / sizeof(arr[0]);
int* copy = new int(size);
cout << "[before] : " ;
showArr(arr, size);
mergeSort(arr, copy, 0, size-1);
cout << "[after] : ";
showArr(arr, size);
return 0;
}쉘 정렬
설명 :
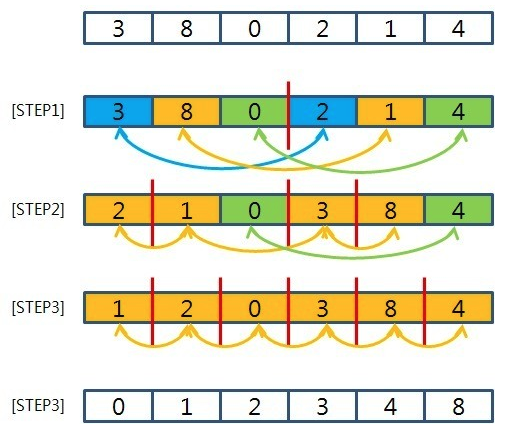
삽입정렬과 "gap"의 개념이 합쳐져서 삽입정렬의 단점을 보완한 정렬방법이다.
gap에 따라 부분 리스트에서 값이 이동할 때 더 큰 거리를 이동한다.
따라서 삽입 정렬보다는 최종 위치에 있을 가능성이 높아진다.
시간 복잡도 :
삽입정렬의 평균 시간복잡도 :
쉘정렬의 평균 시간복잡도 : O(n^1.5)
쉘정렬의 최선 시간복잡도 :
전체 시간복잡도 :
C++로 구현한 쉘정렬
#include <iostream>
using namespace std;
void showArr(int _arr[], int _size) {
for (int i = 0; i < _size; i++)
{
cout << _arr[i] << " ";
}
cout << endl;
}
void swap(int _arr[], int a, int b){
int temp = _arr[a];
_arr[a] = _arr[b];
_arr[b] = temp;
}
void shellSort(int _arr[], int _size) {
int i, j, k, gap;
for(gap = _size/2 ; gap > 0; gap/=2){
for(i = 0 ; i < gap ; i++){
for(j = i + gap ; j < _size ; j+=gap){
int me = _arr[j];
for(k = j - gap ; k>=0 ; k-=gap){
if(me < _arr[k]) {
_arr[k + gap] = _arr[k];
}
else {
break;
}
}
_arr[k+gap] = me;
showArr(_arr, _size);
}
}
}
}
int main(void) {
int arr[] = {5, 3, 8, 5, 9, 1, 6, 2, 7};
int size = sizeof(arr) / sizeof(arr[0]);
cout << "[before] : " ;
showArr(arr, size);
shellSort(arr, size);
cout << "[after] : ";
showArr(arr, size);
return 0;
}힙정렬(Max Heap)
설명 :
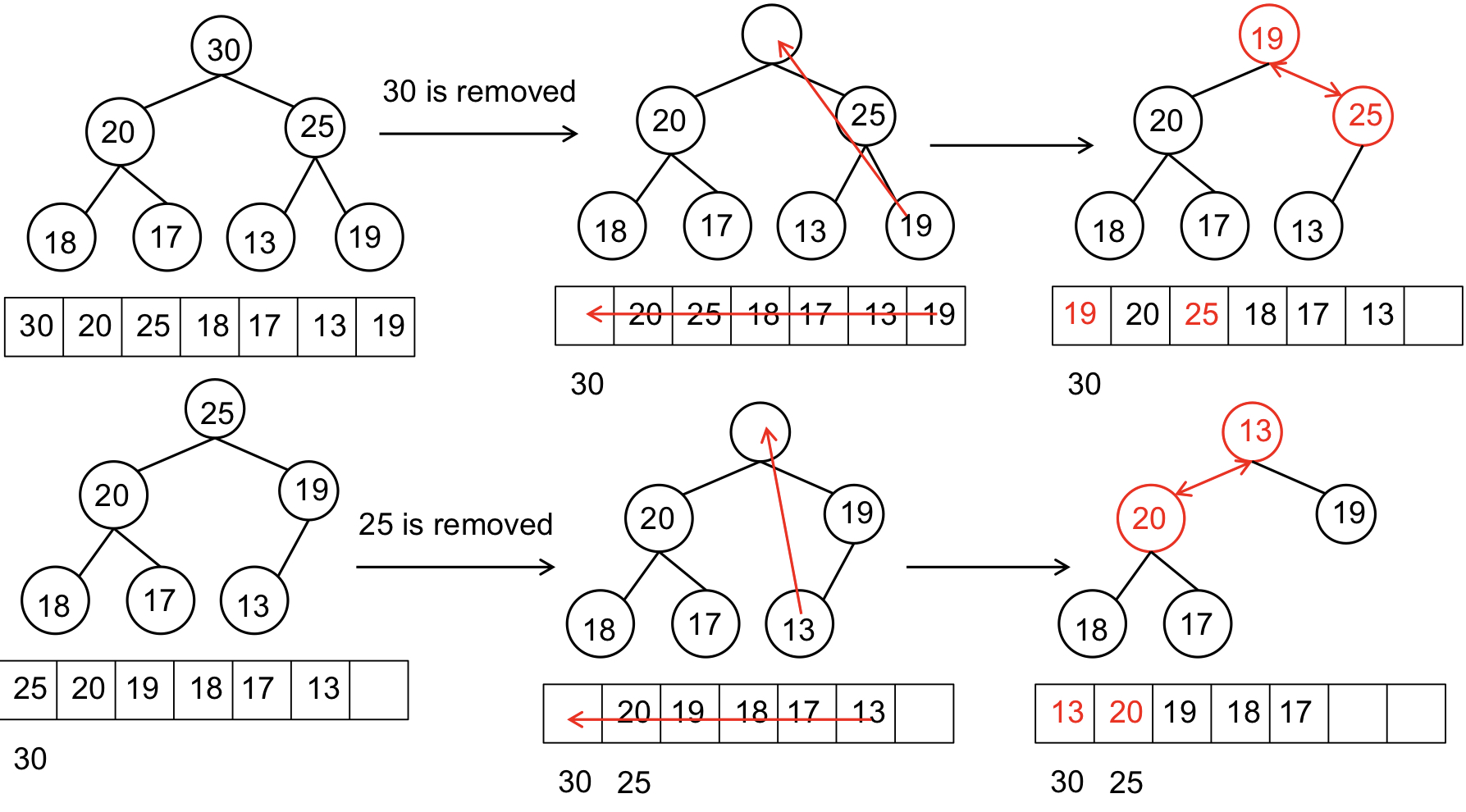
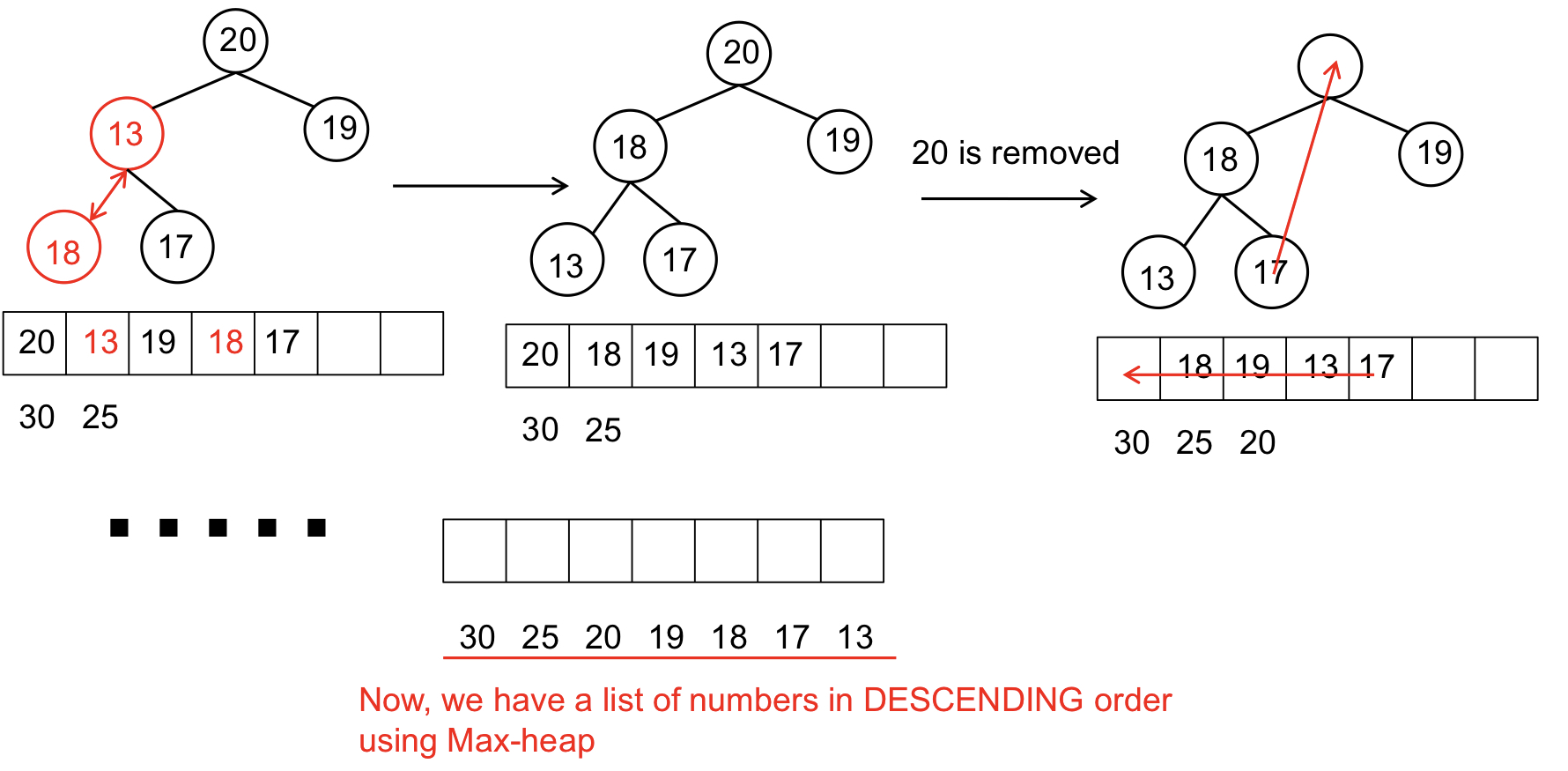
완전 이진 트리(Complete binary tree, 왼쪽부터 값을 채우는 트리)의 성질을 이용한 정렬 방법이다.
완전 이진 트리를 배열로 나타내어 구현할 수 있다.
- 부모 노드 index = (자식 노드 index) / 2
- 왼쪽 자식 노드 index = (부모 노드 index) * 2
- 오른쪽 자식 노드 index = (부모 노드 index) * 2 + 1
단, 루트 노드의 index가 0이 되면 안된다. 위의 연산을 할 수 없기 때문이다.
따라서 루트 노드의 index는 1로 한다.
시간 복잡도 :
요소의 개수가 n개라면, 힙 트리의 전체 높이가 거의 이므로 하나의 요소를 힙에 삽입하거나 삭제할 때 힙을 재정비하는 시간이 만큼 소요된다.
전체 시간복잡도 :
C++로 구현한 힙정렬 :
#include <iostream>
#define HEAP_SIZE 100
using namespace std;
int heap[HEAP_SIZE];
int hsz = 0;
void swap(int _heap[], int a, int b){
int temp = _heap[a];
_heap[a] = _heap[b];
_heap[b] = temp;
}
void enheap(int _data){
if(hsz == HEAP_SIZE - 1){
return;
}
hsz++;
heap[hsz] = _data;
int me = hsz;
int parent = me / 2;
// 방금 들어온 data가 부모 index의 data보다 커야 한다.
// heap을 재정렬
while(1){
// 루트 노드까지 왔으면 멈춘다
if(me == 1){
return;
}
// 부모 data가 더 크면 멈춘다
if(heap[parent] >= heap[me]) {
return;
}
// 자식 data가 더 크면 부모 data와 swap
else {
swap(heap, me, parent);
me = parent;
parent = me / 2;
}
}
}
int findReplacer(int _me) {
int left_child = 2*(_me);
int right_child = 2*(_me) + 1;
// 자식 노드가 deheap()하여 제거된 노드라면 == 자식 노드가 없다면
if(hsz < left_child) {
return -1;
}
// 왼쪽 자식 노드만 존재한다면
if(hsz < right_child) {
return left_child;
}
// 왼쪽 자식 노드와 오른쪽 자식 노드가 둘 다 존재한다면
else {
// 둘 중 더 큰 값을 반환해준다
if(heap[left_child] > heap[right_child]){
return left_child;
}
return right_child;
}
}
int deheap() {
if(hsz == 0){
return -999;
}
// 루트 노드의 data를 반환해준다.
int ret = heap[1];
// ret을 return하기 전에 힙 재정렬
// 임시적으로 가장 마지막 노드의 값을 루트 노드에 넣는다.
heap[1] = heap[hsz];
hsz--;
int me = 1;
// 임시적으로 루트가 된 data가 들어갈 자리를 찾으며 재정렬한다.
while(1){
// 임시적 루트가 된 me를 대신하여 올라올 대상자 선택.
// (자식 노드 중 값이 큰 것을 찾아온다)
int replacer = findReplacer(me);
// 자식 노드가 없다면 멈춤
if(replacer == -1){
return ret;
}
// 자식 노드보다 me가 더 크다면 재정렬할 필요없으니 멈춤
if(heap[me] > heap[replacer]) {
return ret;
}
// 자식 노드가 me보다 크다면, 자식과 me의 위치를 바꿔준다
else {
swap(heap, me, replacer);
me = replacer;
}
}
}
int main(void){
enheap(-1);
enheap(1);
enheap(-2);
enheap(2);
enheap(0);
enheap(3);
enheap(4);
enheap(5);
while(1){
int res = deheap();
if(res == -999){
break;
}
cout << res << " ";
}
return 0;
}계수정렬
설명 :
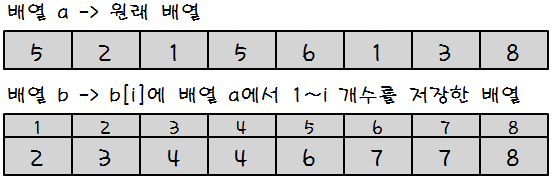
초기 배열(배열 A)을 앞에서부터 데이터를 하나씩 확인하면서 리스트에서 해당하는 인덱스의 값을 1씩 증가시킨다.
배열 A의 최대 값이 100이라면, 정수 100개를 저장할 배열B를 생성한다.
초기 배열에 있는 값들을 처음부터 끝까지 탐색하며 배열B의 index(배열 A의 값)의 값을 하나씩 증가시킨다.
출력할 때, 배열 B를 처음부터 끝까지 확인하며 값이 있는 경우 해당 index번호를 출력하여 정렬을 한다.
사용시 주의점 :
계수 정렬은 때에 따라서 심각한 비효율성을 초래할 수 있다.
예를 들어 데이터가 0과 999,999, 단 2개만 존재한다고 가정했을때,
이럴 때에도 리스트의 크기가 1,000,000개가 되도록 선언해야 한다.
따라서 항상 사용할 수 있는 알고리즘은 아니며, 동일한 값을 가지는 데이터가 여러 개가 있을 때 사용하기에 적합하다.
다시 말해, 계수 정렬은 데이터의 크기가 한정되어 있고, 데이터가 많이 중복되어 있고, 데이터값이 0 이상의 양수인 경우에만 매우 유리하다.
ex. 0~100점 성적을 정렬해야 하는 경우
시간 복잡도 :
특정한 조건이 부합할 때만 사용할 수 있지만 매우 빠른 정렬 알고리즘이다.
모든 데이터가 양의 정수인 상황에서 데이터 개수가 N, 데이터 중 최대값이 K일 때, 계수 정렬의 시간복잡도는 O(N + K)를 갖는다.
다만, 계수 정렬은 '데이터 크기 범위가 제한되어 정수 형태로 표현할 수 있을 때'만 사용할 수 있다.
일반적으로, 가장 큰 데이터와 가장 작은 데이터의 차이가 1,000,000을 넘지 않을 때 효과적으로 사용할 수 있다.
python으로 구현한 계수 정렬 :
A = [9,8,7,6,5,4,3,2,1,0,0,0,1,2,3,4,5,6,7,8,9]
# 초기 배열 A에서 최대값만큼 크기를 갖는 배열 B 생성
B = [0] * (max(A) + 1)
for i in range(len(A)) :
B[A[i]] += 1 # 배열 A의 값에 해당하는 B의 인덱스의 값을 증가
# 따라서 리스트에 음수가 있다면 계수 정렬 사용 불가
for i in range(len(B)) :
for j in range(B[i]) :
print(i, end=' ')
