서버를 따로 띄우거나 DB를 구축하지 않아도 SQL로 바로 데이터를 조회할 수 있는 방법이 있다.
이번 글에서는 AWS Athena를 이용한 S3 데이터를 조회할 것이다.
Athena란?
- 표준 SQL을 사용하여 Amazon S3에 있는 데이터를 직접 간편하게 분석할 수 있는 대화형 쿼리 서비스이다.
- 서버리스 서비스이므로 설정하거나 관리할 인프라가 없으며 실행한 쿼리에 대해서만 분석할 수 있다.
Athena 비용은 S3에서 스캔된 데이터 1TB당 5달러이다.
하지만 데이터를 압축하거나, 파티셔닝하며, Parquet와 같은 열 기반 형식을 사용하면 쿼리당 비용을 최대 90%까지 절감하면서 성능도 함께 향상시킬 수 있다.
Amazon Athena 요금
주요 특징
-
Schema-on-Read 방식:
이는 데이터를 저장할 때가 아닌, 조회(쿼리) 시점에 스키마를 적용하는 방식이며 미리 Schema를 정의하지 않아도 되며CSV,JSON,Parquet등 다양한 형식을 유연하게 처리할 수 있다. -
S3에 쿼리 결과 저장:
Athena는 쿼리 실행 후, 결과를 S3에 자동으로 저장한다
AWS Athena 사용해보기
S3 로그 버킷 생성 및 로그 업로드
버킷을 생성하고 폴더 안에 csv 파일을 S3에 업로드해준다.
sampledata.csv
Athena에서 데이터베이스 및 데이블 생성
가장 먼저 쿼리 결과를 저장할 위치를 설정해주어야한다.
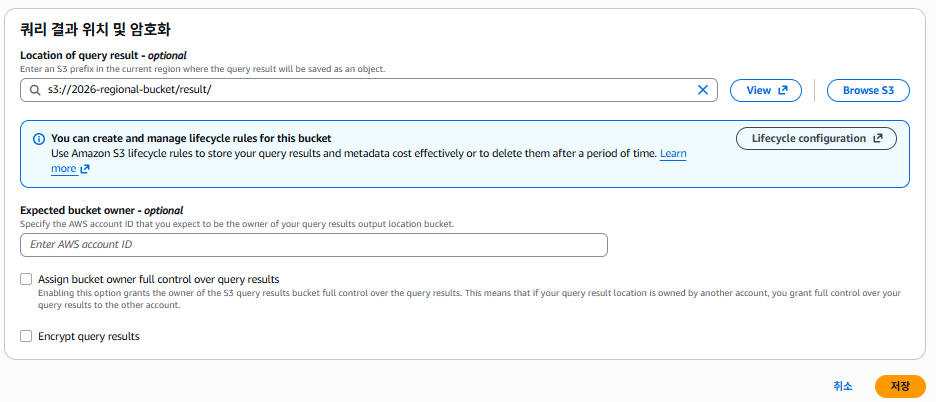
저장소 경로를 설정해주었으니, 데이터베이스를 생성해준다.
아래의 SQL문을 넣고 실행해준다.
CREATE DATABASE test좌측 사이드바에서 데이터베이스 항목을 test db로 변경해준다.
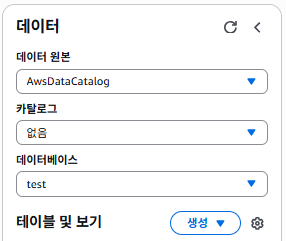
이제 테이블을 생성해준다.
아래의 SQL문을 넣고 실행해준다.
CREATE external table sales_data (
order_id int,
order_date date,
region string,
product string,
category string,
quantity int,
price int
)
row format delimited
fields terminated by ',' -- 컬럼 구분자가 쉼표(,) 라는 뜻
stored as textfile
location 's3://2026-regional-bucket/'
TBLPROPERTIES ("skip.header.line.count"="1") -- 첫 줄(header)을 건너뛰기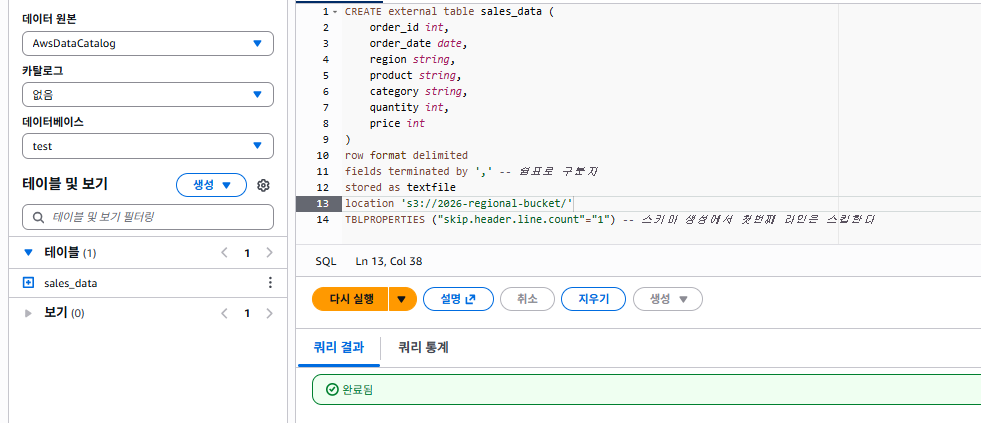
이번엔 직접 조건 조회 쿼리문을 작성하여 실행해본다.
select * from test.sales_data where region in ('Seoul', 'Busan')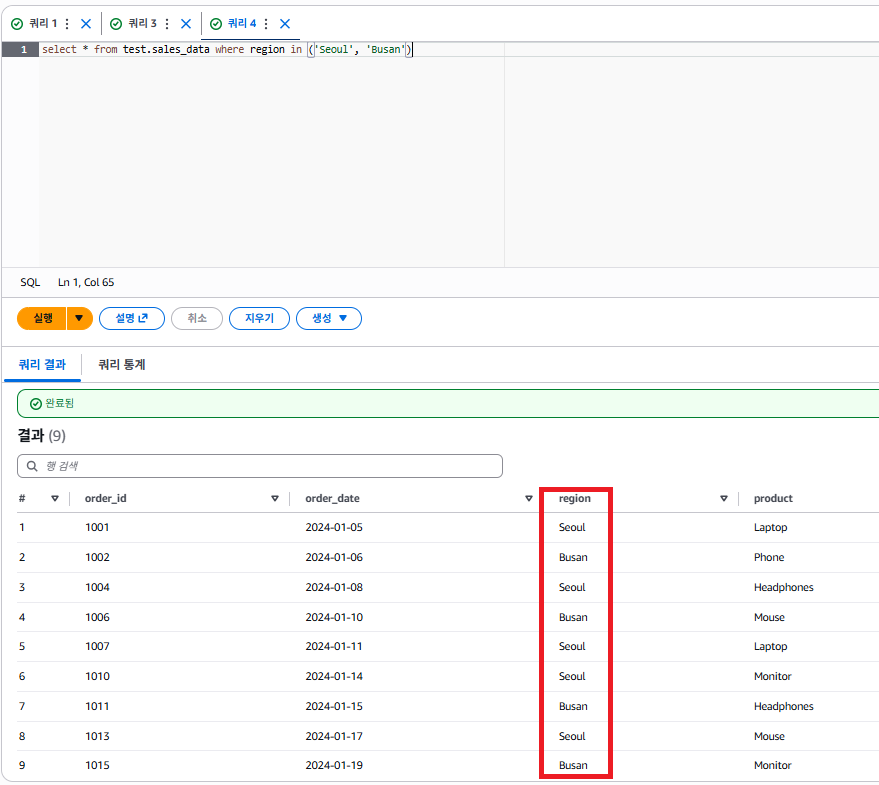
지금까지 csv 데이터 파일을 활용하여 테이블로 만들고 쿼리해봤다.
이외에도 Athena는 CSV, JSON, PARQUET 등 다양한 데이터 형식을 지원한다.
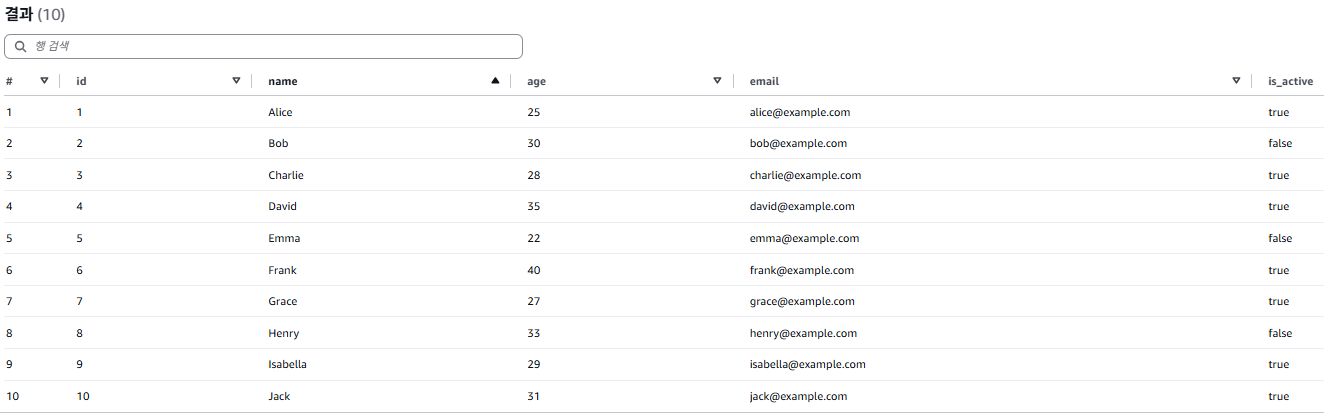
다음 JSON 데이터가 S3 버킷에 있다고 가정해본다. sampledata.json
sampledata.json
아래의 SQL문을 통해 테이블을 생성해준다.
create external table users (
id int,
name string,
age int,
email string,
is_active BOOLEAN
)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe'
stored as textfile
location 's3://2026-regional-bucket/'테이블을 조회해 보면 json 데이터가 테이블화 된거를 볼 수 있다.