
👉오늘의 정리(트리순회)
검색엔진 :
검색엔진(web search engine) 정말 많이 들어보고 사용도 해왔었는데 파이썬으로 간단히 크롤링을 할 때 자료수집에 좋네 라고만 생각하고 연관을 짓지는 못했었습니다. 책을 읽으면서 머리 속에 무분별하게 퍼져있는 잡지식들이 정리가 되는 것 같아서 작은 희열이 듭니다..(변태같음) 검색엔진은 우리가 잘 알고 있는 구글, Bing, naver 처럼 일련의 검색어를 받아 그와 관련된 웹페이지 목록을 반환하는 것 입니다.
나름 익숙한 검색 엔진에 필수 요소에 대해서 알아보겠습니다.
- 크롤링 : 웹 페이지를 다운로드하고 파싱하고 텍스트와 다른 페이지로의 링크를 추출하는 프로그램
- 인덱싱 : 검색어를 조회하고 해당 검색어를 포함한 페이지를 찾는 데 필요한 자료구조
- 검색 : 인덱스에서 결과를 수집하고 검색어와 가장 관련된 페이지를 식별하는 방법
HTML 파싱 :
웹페이지를 다운로드할 때 내용들은 HyperText Markup Language(HTML)로 작성되어 있습니다. 크롤러는 그러한 페이지에서 본문과 링크를 추출해야 합니다. 파이썬을 공부할 때 사용했던 뷰티풀수프처럼 자바에서는 오픈소스 자바 라이브러리인 jsoup를 사용한다고 합니다. 이제 HTML이 가지고 있는 DOM(Document Object Model) 구조는 노드끼리 연결되어 있는 트리구조입니다. 트리구조는 최상위의 루트노드에서 가지처럼 뻗어나가 노드간에 관계를 형성합니다.
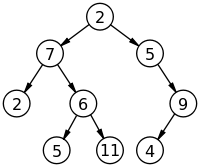 이 이미지 속에서 루트노드는 2이고 6은 7의 자식노드 7은 6의 부모노드가 됩니다. 이러한 트리구조인 HTML의 DOM 구조는 6-1의 그림으로 간단하게 표현됩니다.
이 이미지 속에서 루트노드는 2이고 6은 7의 자식노드 7은 6의 부모노드가 됩니다. 이러한 트리구조인 HTML의 DOM 구조는 6-1의 그림으로 간단하게 표현됩니다.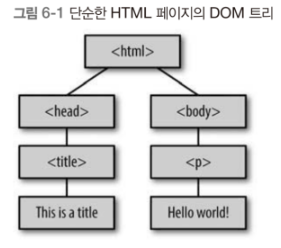
각 노드들은 자식 노드에 대한 링크를 포함하고 각 노드는 부모노드에 대한 링크를 포함하고 있어서 트리를 위아래로 탐색할 수 있습니다. 이제 기본적인 DOM구조를 알았으니 크롤링을 해보겠습니다.
jsoup 사용 :
jsoup 라이브러리를 각자 사용하는 tool에 넣고 아래의 코드로 p태그의 컨텐츠를 받아올 것입니다. 이제 본격적인 크롤링은 다음 글에 작성하겠습니다.
//문서를 다운로드하고 파싱하기
Connection conn = Jsoup.connect(url);
Document doc = conn.get();
// 내용선택후 단락 추출
Element content = doc.getElementById("mw-content-text");
Elements paras = content.select("p");