
Abstract
기존 언어모델은 많은 지식을 갖고 있지만, 필요한 정보를 정확히 꺼내거나 최신 지식을 반영하고 출처를 알려주는 데 한계가 있다.
RAG(Retrieval-Augmented Generation)는 이런 문제를 해결하기 위해 모델이 내부 지식뿐 아니라 위키피디아 같은 외부 자료도 검색해 활용하는 방식이다.
덕분에 더 정확하고 구체적이며 사실적인 답변을 만들 수 있고, 특히 질문 답변 같은 지식이 많이 필요한 과제에서 성능이 크게 향상된다.
1. Introduction
대규모 언어모델(LLM)들은 엄청나게 많은 데이터를 학습해서 마치 내부 지식 저장소처럼 작동한다. 덕분에 여러 질문에 답을 잘하지만, 단점도 있다.
- 새로운 지식을 쉽게 추가하거나 수정하기 어렵다.
- 답변의 근거를 설명하기 힘들다.
- 가끔은 사실이 아닌 내용을 지어내기도 한다.
이런 문제를 해결하기 위해 나온 아이디어가 바로 검색과 언어모델을 합친 하이브리드 모델이다.
예전에도 REALM, ORQA 같은 모델이 있었는데, 이들은 질문에 맞는 문서를 검색해서 답을 뽑아주는 방식이었다. 다만 주로 추출형 질의응답에만 쓰였다.
RAG가 새로 제안한 점
이번 논문에서 소개된 RAG(Retrieval-Augmented Generation)는 한 단계 더 나아갔다.
- 검색기(DPR) → 위키피디아에서 관련 문서를 찾아줌
- 생성기(BART) → 질문과 검색된 문서를 참고해서 답변 생성
검색한 문서를 그냥 보여주는 게 아니라, 생성 모델이 내용을 종합해서 자연스러운 답변을 만들어낸다.
실험에서 확인된 성능
- 오픈 도메인 질의응답(NQ, WebQuestions 등)에서 최신 성능 달성
- TriviaQA에서는 기존 특화 모델을 크게 앞섰음
- 문서 기반 생성 과제(MS-MARCO, Jeopardy 질문 생성)에서도 BART보다 더 사실적이고 구체적인 답변 생성
- 사실 검증(FEVER)에서도 높은 성능을 보여줌
중요한 특징
- RAG의 외부 메모리(위키피디아 인덱스)는 교체가 가능하다는 점이 인상적이었다.
- 세상이 변해도 그냥 새로운 데이터로 바꾸기만 하면 모델의 지식을 업데이트할 수 있다.
- 기존 LLM의 "업데이트 어려움" 문제를 꽤 현실적으로 해결한 느낌이다.
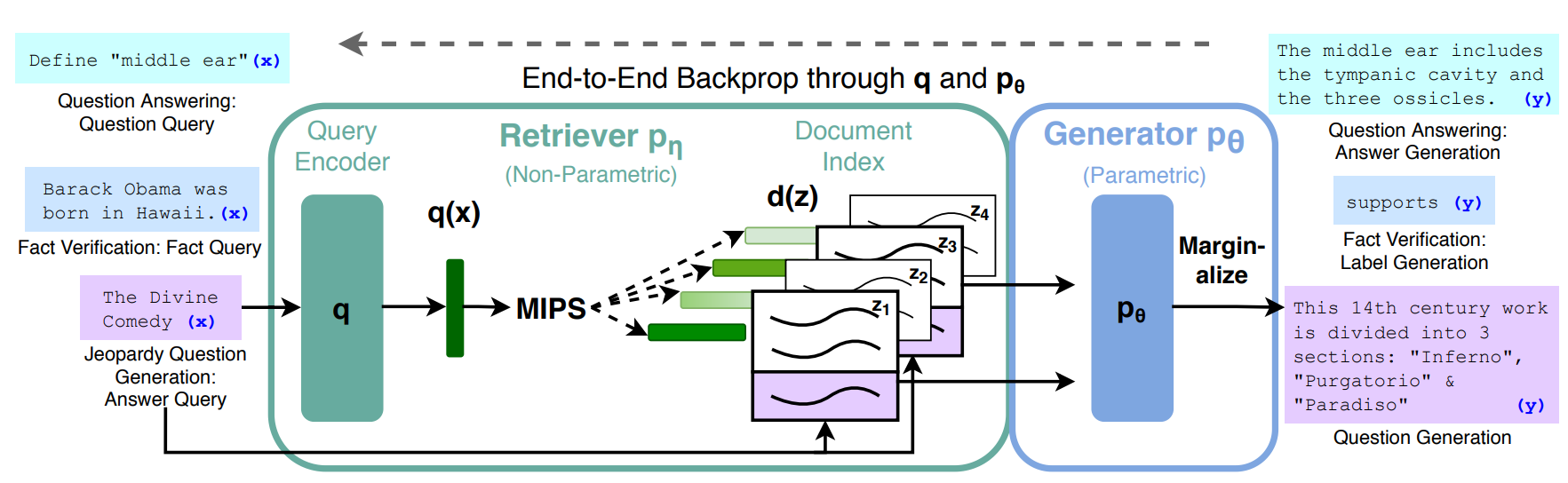
이 논문에서 제안하는 방식은 크게 두 부분으로 이루어진다.
1. 검색기(Retriever)
- 질문을 입력받아 위키피디아 같은 문서 인덱스에서 관련 있는 문서들을 찾아낸다.
- 여기서 사용되는 기법이 MIPS(Maximum Inner Product Search) 로, 질문과 문서 벡터의 유사도를 계산해 상위 K개의 문서를 뽑는다.
2. 생성기(Generator, seq2seq 모델)
- 질문과 함께 이 문서들을 참고해 답변을 생성한다.
- 이때 어떤 문서가 최종 답변에 가장 크게 기여했는지는 잠재 변수(latent variable)로 처리하고, 여러 문서 기반 예측들을 종합(marginalize)해서 최종 출력을 만든다.
결국 이 구조는 “검색기로 관련 문서를 고르고, 생성기로 답변을 만드는” 전체 파이프라인을 하나로 묶어 엔드투엔드 학습할 수 있게 해준다.
2. Methods
이 논문에서 제안하는 RAG 모델은 크게 두 가지 과정으로 이루어진다.
- 입력 질문(x) 을 받으면 검색기(Retriever)가 위키피디아 같은 문서 집합에서 관련 문서(z)를 찾아낸다.
- 생성기(Generator)가 이 문서들을 참고해서 최종 답변(y)을 만든다.
→ 검색한 내용을 추가 맥락으로 삼아 답변을 생성하는 구조
RAG에는 두 가지 방식이 있다.
- RAG-Sequence는 전체 답변을 하나의 문서에 기반해서 생성하는 방식
- RAG-Token은 각 단어를 생성할 때마다 다른 문서를 참고할 수 있는 방식이다.
→ 더 다양한 문서를 활용할 수 있어서 유연하다.
검색기 : DPR(Dense Passage Retriever) 모델 사용
이는 BERT 기반의 쌍둥이 구조(bi-encoder)로, 질문과 문서를 각각 벡터로 바꾼 뒤 두 벡터의 유사도를 계산해 가장 관련성이 높은 문서들을 고른다.
→ 이렇게 뽑힌 문서 인덱스가 바로 RAG의 “외부 메모리” 역할을 한다.
생성기 : BART-large 라는 대규모 seq2seq 언어모델 사용
입력 질문과 검색된 문서를 단순히 이어 붙여서 입력으로 주고, 이를 바탕으로 답변을 생성한다. BART는 원래 다양한 텍스트 변형 학습을 거친 모델이라 여러 생성 과제에서 강력한 성능을 보인다.
학습 : 검색기와 생성기를 동시에(end-to-end) 훈련시키지만, 어떤 문서가 반드시 정답이라는 직접적인 감독(supervision)은 주지 않는다.
대신 여러 후보 문서를 잠재 변수처럼 처리하고, 정답 출력을 잘 맞히도록 모델 전체를 조정한다.
이때 문서 인덱스 자체는 고정해 두고, 검색기의 질문 인코더와 생성기(BART)만 미세 조정한다.
추론(테스트) 단계
- RAG-Token : 일반적인 seq2seq 모델처럼 토큰마다 여러 문서를 종합해 다음 단어를 예측한다.
- RAG-Sequence : 답변 전체가 특정 문서에 기반하므로 문서별로 빔 서치를 돌리고, 나온 후보 답변들을 종합하는 방식(Thorough Decoding 또는 Fast Decoding)을 사용한다.
- Thorough Decoding : 더 정확하지만 계산이 많이 든다.
- Fast Decoding : 효율적인 대신 근사치를 사용한다.
3. Experiments
연구팀은 RAG 모델을 다양한 지식 중심 과제(knowledge-intensive tasks) 에 적용해 성능을 확인했다.
외부 지식은 위키피디아(2018년 12월 버전)를 사용했고, 각 문서를 100단어 단위로 나누어 총 2천만 개 이상의 문서 조각을 만들었다. 이렇게 만들어진 문서 벡터를 FAISS라는 빠른 검색 라이브러리로 인덱싱해, 질문마다 상위 k개의 문서를 검색하도록 했다.
-
오픈 도메인 질의응답(Open-domain QA) 실험
여기서는 질문과 답을 입력-출력 쌍으로 보고, 답을 맞히도록 모델을 훈련시켰다. 기존에는 문서에서 직접 답을 “추출”하는 방식이 많았지만, RAG는 검색과 생성을 결합해 답을 만든다. 다양한 데이터셋(Natural Questions, TriviaQA, WebQuestions, CuratedTrec)에서 기존 모델보다 좋은 성능을 보였다. -
단순 추출을 넘어서 자유로운 문장 생성(Abstractive QA) 시험
MSMARCO라는 데이터셋을 사용했는데, 여기서는 검색된 문서를 쓰지 않고 오직 질문과 답만 학습에 사용해 오픈 도메인 생성 문제로 다뤘다. 위키피디아에 없는 질문들도 있었지만, RAG는 내부 지식과 검색을 적절히 활용해 답변을 만들어낼 수 있었다. -
퀴즈쇼 Jeopardy! 형식의 질문을 만들어내는 실험
주어진 답(예: “The World Cup”)에 맞는 질문을 생성하는 방식인데, 이는 단순 질의응답보다 더 어려운 과제다. RAG로 학습시킨 결과, 기존 BART 모델보다 더 사실적이고 구체적인 질문을 만들어냈다는 평가를 받았다. 이는 자동 점수(Q-BLEU)뿐 아니라 사람 평가에서도 확인되었다. -
사실 검증(Fact Verification) 과제인 FEVER 데이터셋 실험
여기서는 어떤 문장이 위키피디아 근거에 의해 “참”, “거짓”, 또는 “판단 불가”인지 분류해야 한다. 대부분의 기존 모델은 정답 근거 문장을 직접 알려주는 감독 학습을 필요로 했지만, RAG는 그런 추가 신호 없이도 분류 성능을 낼 수 있었다.
4. Results
RAG는 다양한 지식 중심 과제에서 기존 방법들을 뛰어넘는 성능을 보여줬다.
-
오픈 도메인 질문답변(QA) 실험
모든 주요 데이터셋(NQ, TriviaQA, WebQuestions, CuratedTrec)에서 새로운 최고 성능을 기록했다. 단순히 문서에서 답을 “추출”하는 방식과 달리, RAG는 문서 단서만 있어도 정답을 만들어낼 수 있고, 심지어 정답 문서가 검색되지 않은 경우에도 일부를 맞출 수 있었다. -
생성형 질문답변(Abstractive QA)
MS-MARCO 데이터셋에서 BART보다 높은 점수를 기록했다. 정답 문서가 주어지지 않아도 합리적인 답을 내며, 환각(hallucination) 현상이 줄고 사실적인 답변을 더 자주 생성했다. -
Jeopardy 질문 생성 실험
RAG-Token 모델이 가장 좋은 성능을 보였다. 사람 평가에서도 RAG가 BART보다 훨씬 더 사실적이고 구체적인 질문을 만들어낸다고 평가되었다. 특히 여러 문서를 조합해 질문을 만들 수 있다는 점이 강점으로 작용했다. -
사실 검증(Fact Verification, FEVER)
RAG는 복잡한 파이프라인 구조 없이 단순 모델로 강력한 성능을 냈다. 정답 근거를 따로 주지 않아도 스스로 문서를 찾아 분류할 수 있었다.
추가 분석에서는 몇 가지 흥미로운 결과가 나왔다.
- RAG가 만든 문장은 BART보다 더 다양했고, 검색기를 학습하지 않고 고정해 두면 성능이 떨어지는 것도 확인됐다.
- BM25 같은 전통적인 검색 방식과 비교했을 때, RAG의 신경망 기반 검색이 대부분의 과제에서 더 강력했다.
- RAG는 외부 문서 인덱스를 교체하는 것만으로 세계 지식을 업데이트할 수 있다.
ex) 위키피디아 2016 버전을 쓰면 2016년 지도자에 대해 맞추고, 2018 버전을 쓰면 최신 지도자 정보를 맞출 수 있었다. 모델을 다시 훈련할 필요가 없다. - 테스트할 때 검색 문서 개수를 늘리면 성능이 더 올라가는 경우가 많아 유연하게 조절할 수 있음도 확인됐다.

다음 그림은 RAG-Token 모델이 Jeopardy 질문을 생성할 때, 각 단어를 만들기 위해 어떤 문서를 참고했는지를 보여준다.
입력이 “Hemingway”일 때, 모델은 “A Farewell to Arms”라는 단어를 생성할 때는 문서 1을 강하게 참고했고, “The Sun Also Rises”를 생성할 때는 문서 2를 더 의존했다.
단어마다 다른 문서를 선택해서 답변을 만들어가는 과정을 시각적으로 보여준다.
5. Related Work
이 연구는 RAG가 어떤 점에서 기존 연구와 연결되고, 또 어떤 차별성을 가지는지를 설명한다.
-
단일 과제에서의 검색 활용 연구들
오픈 도메인 질의응답, 사실 검증, 위키피디아 글 생성, 대화 시스템, 번역 등 다양한 분야에서 검색 기능을 붙이면 성능이 좋아진다는 게 입증됐다.
하지만 대부분은 한 가지 과제에만 맞춰져 있었다.
RAG는 이런 성과들을 하나로 묶어, 하나의 검색 기반 구조로 여러 과제를 잘 수행할 수 있음을 보여줬다. -
범용 NLP 아키텍처 연구
GPT-2, BART, T5 같은 모델들이 대표적인데, 이들은 검색 없이도 다양한 과제를 잘 풀 수 있는 강력한 언어모델이다.
하지만 RAG는 여기에 검색 모듈을 붙여 지식 중심 과제까지 확장할 수 있게 만든다. -
학습된 검색 모듈에 관한 연구
어떤 연구는 질문에 맞는 문서를 잘 찾도록 검색기를 따로 최적화했고, 강화학습이나 잠재 변수 방식으로 학습하기도 했다.
RAG 역시 비슷한 아이디어를 활용하지만, 중요한 차이는 단일 구조로 여러 과제에 쓸 수 있다는 점이다. -
메모리 기반 아키텍처와의 연관성
기존에도 뉴럴넷에 외부 메모리를 붙이는 시도가 있었는데, RAG는 위키피디아 같은 원문 텍스트 자체를 메모리로 삼는다는 특징이 있다.
덕분에 사람이 읽고 쓸 수 있고, 필요할 때 메모리를 교체해 지식을 업데이트할 수 있다. -
Retrieve-and-Edit 방식과 닮음
이는 비슷한 예시를 찾아 편집하는 접근인데, 번역이나 의미 분석 등에서 성과가 있었다. 다만 RAG는 단순 편집이 아니라, 여러 문서를 모아 종합적으로 답변을 만드는 쪽에 가깝다. 향후 RAG를 이런 영역에 적용하면 더 발전할 가능성이 있다.
6. Discussion
이 연구에서는 내부 지식(파라미터 메모리)과 외부 지식(검색 기반 메모리)을 함께 활용하는 하이브리드 생성 모델, RAG를 제안했다.
실험 결과
- RAG는 오픈 도메인 질의응답에서 최고 성능을 기록했고, 사람 평가에서도 기존 BART보다 더 사실적이고 구체적인 답변을 만든다고 인정받았다.
- 검색 모듈이 효과적으로 작동한다는 점을 확인했고, 단순히 검색 인덱스를 교체하는 것만으로도 모델 지식을 업데이트할 수 있음을 보여줬다.
사회적 영향 측면
- RAG는 사실적 근거에 기반해 환각(hallucination)이 줄어들고, 답변의 신뢰성과 해석 가능성이 높다는 장점이 있다.
ex) 의료 지식 베이스를 붙이면 의료 질문에 더 신뢰성 있는 답변을 줄 수 있고, 다양한 분야에서 업무 효율을 높일 수도 있다.
위험
- 외부 지식원(예: 위키피디아) 자체가 불완전하거나 편향될 수 있으며, 언어모델 특유의 위험성(가짜 뉴스, 스팸/피싱 자동화, 악용 가능성 등)이 존재한다.
→ AI를 이용해 허위정보와 자동화된 악용을 방어하는 방향의 노력 필요.
