
Abstract
YOLOv3는 이전 YOLO 버전에서 여러 가지 작은 디자인 변화들을 더해서 성능을 개선했다고 한다.
네트워크 자체는 전보다 조금 더 커졌지만 그만큼 정확도가 높아졌고, 속도는 여전히 빠른 게 특징이다.
예를 들어 320×320 크기의 입력 이미지에서 YOLOv3는 한 장을 처리하는 데 약 22ms밖에 걸리지 않는다. 이때 정확도(mAP)는 28.2인데, 이건 SSD(Single Shot MultiBox Detector, yolo와 같이 single network를 사용한 object detection 모델)랑 거의 같은 수준의 정확도이면서도 세 배나 빠르다고 한다. 속도와 정확도를 동시에 잡은 셈이다.
또한 예전부터 많이 쓰였던 IoU 0.5 기준(AP50)으로 평가했을 때도 좋은 성능을 보인다. Titan X GPU에서 YOLOv3는 57.9 AP50을 달성하는데, 걸린 시간은 단 51ms. 반면 RetinaNet은 57.5 AP50을 얻는 데 198ms나 걸린다. 성능은 비슷한데 YOLOv3가 약 3.8배나 더 빠른 것이다.
1. Introduction
YOLOv3 논문의 Introduction은 딱딱하지 않고 솔직하다.
저자는 연구를 많이 안 했고, 트위터나 GANs(Generative Adversarial Networks (적대적 생성 신경망) 이라는 딥러닝 모델)에 시간을 쓰면서 YOLO에 몇 가지 작은 개선을 했다고 한다.
끝부분에서는 논문의 흐름을 안내하는데,
1. YOLOv3 핵심 설명
2. 방법(Method) 소개
3. 실패한 시도 공유
4. 의미 정리
이 네 가지로 구성되어 있음을 알려준다.
2. The Deal
완전히 새로운 걸 발명했다기보다는, 기존에 효과 좋다고 검증된 아이디어들을 모아서 YOLO 스타일로 재구성한 게 이번 버전이라고 한다.
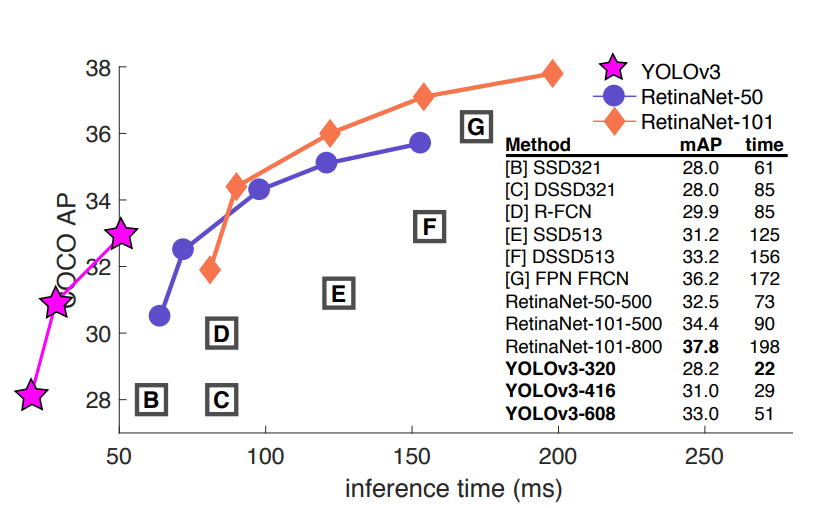
YOLOv3는 비슷한 성능을 내는 다른 객체 탐지 모델들보다 훨씬 빠르게 동작한다. 실험에 사용한 GPU는 M40이나 Titan X인데, 사실상 성능은 거의 비슷하다고 한다.
2.1. Bounding Box Prediction
YOLOv3가 물체를 찾는 핵심 방법은 바로 바운딩 박스(bounding box) 예측이다.
YOLO9000에서 이어져 온 anchor box 방식을 사용한다.
YOLOv3는 미리 여러 크기의 박스를 기본 박스(anchor box)로 준비해둔다.
그리고 네트워크가 이 기본 박스를 조금씩 보정(offset)해서 최종 박스를 만드는 방식이다.
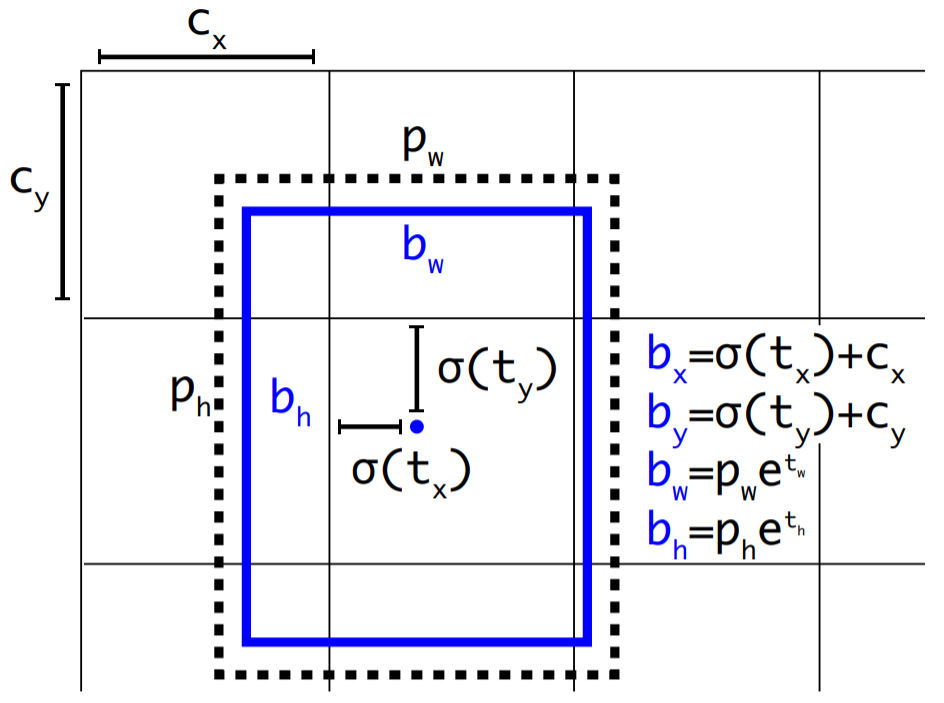
네트워크가 예측하는 값은 tx, ty, tw, th 네 가지이다.
- tx, ty: 박스 중심 좌표를 조정하는 값
- tw, th: 박스의 너비와 높이를 조정하는 값
최종 좌표는 다음과 같이 계산한다.
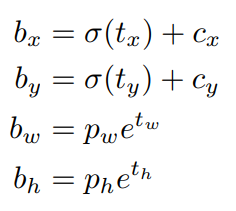
- (cx, cy): 셀(cell)이 이미지의 왼쪽 위에서 떨어진 거리
- (pw, ph): anchor box의 기본 너비와 높이
- σ: 시그모이드(sigmoid) 함수
YOLOv3는 anchor box를 기준으로 중심은 시그모이드로 정규화, 크기는 지수(exp)로 조정한다.
학습 방식 (Loss)
훈련할 때는 간단하게 제곱 오차(sum of squared error)를 사용한다.
예측값과 실제 정답값(ground truth) 차이를 계산해서 그라디언트로 학습한다.
어떤 좌표 예측에 대해, 그라디언트는 𝑡^∗−𝑡∗ 형태로 계산된다. (여기서 𝑡^∗는 ground truth box에서 얻은 값)
Objectness Score (객체 존재 확률)
각 박스는 단순히 위치와 크기만 예측하는 게 아니라, “이 박스 안에 물체가 있는지”도 함께 예측한다.
이를 objectness score라고 하며, 로지스틱 회귀(logistic regression, 0~1 사이의 확률을 출력하는 분류 모델)로 계산한다.
만약 이 박스가 실제 객체와 가장 많이 겹치면(object prior overlap) → score = 1
가장 잘 맞는 박스는 아니지만 어느 정도 겹치면(IoU > 0.5) → 무시(ignore)
전혀 겹치지 않으면 → score = 0
그리고 YOLOv3는 하나의 객체에 딱 하나의 anchor만 할당한다.
선택받지 못한 anchor는 좌표나 클래스 손실은 계산하지 않고, objectness만 학습한다.
2.2. Class Prediction
YOLOv3는 각 바운딩 박스마다 그 안에 어떤 클래스(사람, 강아지, 자동차 등)가 들어 있을지 예측한다.
YOLOv3는 기존 방식(Softmax) 대신 멀티라벨 분류(multi-label classification)를 사용했다.
보통 분류 문제에서는 Softmax를 써서 “여러 클래스 중 하나”를 고르도록 한다.
하지만 YOLOv3는 Softmax를 쓰지 않고, 각 클래스별로 독립적인 로지스틱 분류기를 둔다.
→ 각 클래스마다 있다/없다를 개별적으로 판단하는 구조이다.
사람? → 있다 (1)
여성? → 있다 (1)
자동차? → 없다 (0)
고양이? → 없다 (0)
훈련할 때는 Binary Cross Entropy Loss (이진 교차 엔트로피 손실)를 사용하여 클래스별로 독립적인 확률을 예측하고, 정답과 비교해서 손실을 계산한다.
이 접근법은 특히 복잡한 데이터셋에서 강력하다.
복잡한 데이터셋에서는 하나의 객체에 여러 라벨이 동시에 붙을 수 있기 때문이다.
예시: “Woman”과 “Person”은 동시에 성립할 수 있는 라벨
Softmax는 “하나의 박스 = 정확히 하나의 클래스”라는 제약을 걸지만, 현실은 그렇지 않다.
YOLOv3는 멀티라벨 방식을 택해서 겹치는 라벨을 자연스럽게 표현할 수 있게 만들었다!
2.3. Predictions Across Scales
YOLOv3의 큰 특징 중 하나는 3가지 다른 스케일에서 박스를 예측한다는 점이다.
YOLOv3는 작은 물체부터 큰 물체까지 골고루 잘 잡아내도록 설계되었다.
YOLOv3는 Feature Pyramid Networks(FPN) 아이디어를 응용했다.
기본 특징 맵(feature map)에서 여러 단계로 컨볼루션(convolution) 연산을 수행한다.
마지막 레이어에서 3D 텐서를 예측하는데, 이 안에는
- 4개의 박스 좌표(offset)
- 1개의 objectness (물체가 있을 확률)
- 80개의 클래스 확률 (COCO 기준)
이렇게 총 [4 + 1 + 80] 값이 들어간다.
그리고 스케일마다 3개의 anchor box를 예측하므로,
최종 텐서 크기 = N × N × [3 × ( 4 + 1 + 80 )] 이다.
YOLOv3는 단순히 한 스케일만 쓰지 않는다.
먼저, 2단계 전 레이어의 feature map을 2배 업샘플링하고, (깊은 층의 feature map을 확대해서 해상도를 높임.)
거기에 더 앞쪽(얕은 층)의 feature map과 concat(합치기)
이렇게 하면 업샘플된 feature가 가진 의미적 정보(semantic features) + 얕은 층이 가진 세밀한 정보(fine-grained features)를 함께 활용할 수 있다.
이 과정을 반복해서, 총 3단계 예측을 수행한다.(큰 물체용 스케일, 중간 크기 물체용 스케일, 작은 물체용 스케일)
YOLOv3는 k-means 클러스터링을 이용해 anchor box 크기를 정한다.
9개의 클러스터를 뽑고, 이를 3개의 스케일에 고르게 나눠서 사용한다.
COCO 데이터셋에서 나온 9개의 anchor 크기:
(10×13), (16×30), (33×23), (30×61), (62×45), (59×119), (116×90), (156×198), (373×326)
이 값들이 각각 작은 물체부터 큰 물체까지 커버할 수 있도록 배치된다.
2.4. Feature Extractor
Darknet-53
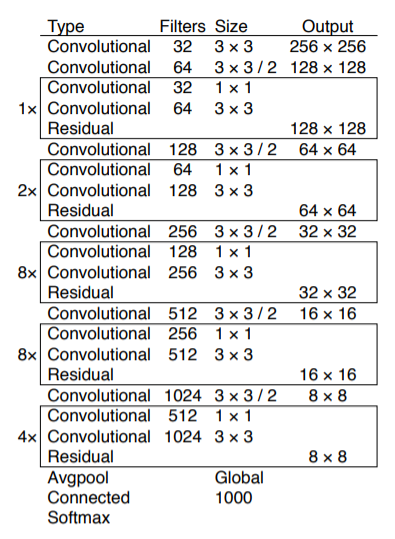
YOLOv3는 단순히 탐지만 잘하는 게 아니라, 그 밑단에서 이미지의 특징(feature)을 얼마나 잘 뽑아내느냐도 중요하다.
그래서 YOLOv3는 새로운 네트워크, Darknet-53을 도입했다.
YOLOv2에서는 Darknet-19라는 비교적 작은 네트워크를 사용했었다.
YOLOv3는 여기서 한 단계 업그레이드하여 ResNet에서 가져온 Residual Connection 아이디어를 합쳤다.
구조는 3×3, 1×1 컨볼루션을 반복하면서도, 중간중간 shortcut(스킵 연결)이 들어간 형태이다.
총 53개의 컨볼루션 레이어로 이루어져 있다.
성능 비교 (ImageNet 기준)
Darknet-53은 단순히 크기만 커진 게 아니라, 실제 성능도 강력하다.
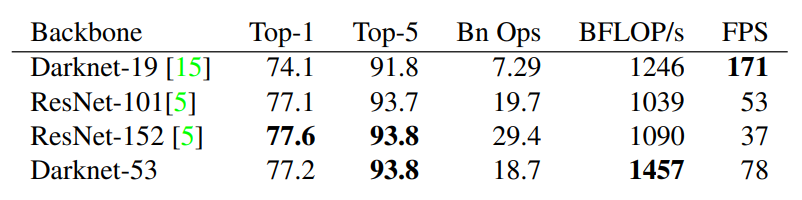
정확도
(Top-1 : 모델이 예측한 1위 클래스가 정답일 확률 (%),
Top-5 : 모델이 예측한 상위 5개 클래스 중 정답이 포함될 확률 (%))
ResNet-152가 Top-1, Top-5 정확도에서 가장 좋음 (77.6 / 93.8)
Darknet-53도 거의 비슷한 성능 (77.2 / 93.8)
연산량
(Bn Ops : 십억 번의 연산, Billion Operations)
ResNet-152: 29.4 (연산량 가장 많음 → 무거움)
Darknet-53: 18.7 (ResNet-101보다 살짝 많지만 ResNet-152보다는 훨씬 가벼움)
연산 효율(BFLOP/s)
: 초당 실행되는 부동소수점 연산 수 (연산 효율, 높을수록 좋음)
Darknet-53이 최고 (1457) → GPU 활용도가 가장 좋음
속도(FPS)
: 초당 처리할 수 있는 이미지 수 (속도, 높을수록 빠름)
Darknet-19가 가장 빠르긴 하지만 정확도가 낮음
Darknet-53은 ResNet-152와 비슷한 정확도를 유지하면서 2배 이상 빠름 (78 vs 37 FPS)
2.5. Training
어떤 모델들은 성능을 높이려고 하드 네거티브 마이닝 같은 복잡한 기법을 쓰기도 하는데, YOLOv3는 그냥 전체 이미지를 그대로 사용해서 학습한다.
다음과 같은 딥러닝에서 흔히 쓰는 표준적인 기법들은 모두 적용했다.
- 멀티 스케일 트레이닝: 훈련 중에 이미지 크기를 계속 바꿔가며 학습 → 다양한 크기에도 잘 대응
- 데이터 증강(Data Augmentation): 이미지에 변형(회전, 색상 변화 등)을 줘서 데이터 다양성 확보
- 배치 정규화(Batch Normalization): 학습 안정화와 속도 향상
훈련과 테스트에는 YOLO의 전용 프레임워크인 Darknet을 사용했다.
3. How We Do
YOLOv3 논문에서는 다양한 객체 탐지 모델들과 성능을 비교한다.
아래 표는 그 결과이다.
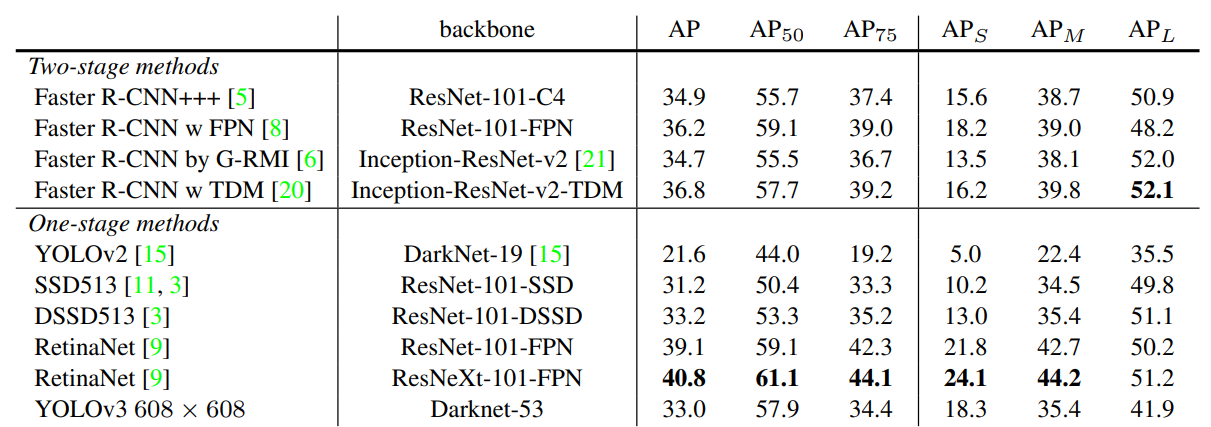
지표 설명
AP: COCO 공식 mAP (IoU 0.5~0.95 평균) → 엄격한 기준
AP50: IoU=0.5 기준 정확도 → 박스가 “대충” 맞으면 인정
AP75: IoU=0.75 기준 정확도 → 박스가 더 정밀하게 맞아야 인정
APS / APM / APL: 작은 물체 / 중간 물체 / 큰 물체 성능
결과 해석
Two-stage (Faster R-CNN 계열)
- AP는 35~37 수준 → 여전히 강력
- 작은 물체(APS)는 15~18 정도, 큰 물체(APL)는 50 이상으로 안정적
One-stage
- YOLOv2: 낮은 성능 (AP=21.6)
- SSD/DSSD: 중간 성능 (AP=31~33)
- RetinaNet: 최고 성능 (AP=39~40, AP50=61.1)
- YOLOv3 (608×608): AP=33.0 → SSD보다 낫지만 RetinaNet보다는 낮음
- AP50=57.9: RetinaNet과 거의 비슷 (박스를 대충 맞추는 능력은 강력)
- APS=18.3: 작은 물체 성능이 YOLOv2/SSD 대비 확실히 개선됨
- APM / APL: 중간·큰 물체는 RetinaNet보다 성능이 떨어짐
YOLOv3는 SSD보다 좋고 RetinaNet보다는 약한 성능을 가진다.
하지만 AP50에서는 RetinaNet과 거의 비슷하다.
작은 물체 성능은 크게 개선되었지만, 중간·큰 물체 성능은 아쉽다.
4. Things We Tried That Didn’t Work
YOLOv3를 만들면서 연구진은 여러 가지 시도를 해봤지만, 성능이 잘 나오지 않은 경우도 많았다.
1. Anchor box x, y 오프셋을 선형으로 예측하기
원래 YOLOv3는 시그모이드 함수를 사용해 x, y 좌표를 예측한다. 이를 박스 크기의 비율에 선형 값을 곱하는 방식으로 바꿔봤지만, 모델이 불안정해지고 성능이 떨어졌다.
2. Logistic 대신 Linear로 x, y 예측
x, y 좌표를 선형 활성화 함수로 직접 예측하는 방식을 시도했다. 그 결과 mAP가 몇 포인트 떨어졌고, logistic 방식이 훨씬 안정적임을 확인했다.
3. Focal Loss 적용
RetinaNet에서 성능 향상에 크게 기여한 Focal Loss도 적용해봤다. 하지만 YOLOv3에서는 오히려 mAP가 2포인트 하락했다. YOLOv3는 objectness 예측과 클래스 예측을 분리하는 구조라서, 원래부터 클래스 불균형 문제에 어느 정도 강한 것으로 보인다.
4. Dual IoU Thresholds 적용
Faster R-CNN에서는 훈련 시 IoU 기준을 2개 둔다. IoU가 0.7 이상이면 양성, 0.3~0.7이면 무시, 0.3 미만이면 음성으로 처리한다. YOLOv3에서도 이를 따라 해봤지만, 성능이 잘 나오지 않았다.
5. What This All Means
YOLOv3는 빠르고 정확한 탐지기다.
COCO의 엄격한 mAP 지표에서는 최신 모델보다 부족하지만, AP50 기준에서는 RetinaNet에 근접한 강력한 성능을 보인다.
저자는 “사람도 IoU 0.3과 0.5 차이를 잘 구분 못하는데, 지표가 정말 그렇게 중요한가?”라는 의문을 던진다. 더 나아가, 이 기술이 기업이나 군사적인 목적으로 잘못 쓰일 위험도 지적하면서 연구자가 사회적 책임을 가져야 한다고 강조한다.
결국 YOLOv3 논문은 단순한 기술 보고서를 넘어, 빠르고 좋은 모델을 만들었다 → 그런데 이걸 어디에, 어떻게 써야 할까?라는 고민으로 마무리된다.
(그리고 저자는 트위터를 그만두었다고 한다.)
