
코드 수정을 반복하는 데이터 전처리 Agent
클로드
클로드(Claude)는 앤트로픽(Anthropic)에서 개발한 대규모 언어 모델(LLM) 기반의 인공지능 챗봇으로, 사람과의 대화, 글쓰기, 요약, 코드 작성 등 다양한 작업을 수행할 수 있는 생성형 AI이다.
클로드(Claude)의 이름은 인공지능의 선구자 클로드 섀넌(Claude Shannon)에서 따왔으며, “헌宪법 기반 AI(constitutional AI)” 접근법을 적용해 안전성과 투명성을 강화한 것이 특징이다.
인간의 직접적인 지시보다는 미리 정해둔 원칙과 가이드라인을 통해 스스로 출력을 조율하도록 설계되었기 때문에, 사용자가 안심하고 활용할 수 있는 대화형 AI이다.
import getpass
import os
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")
_set_env("ANTHROPIC_API_KEY")from langchain_core.tools import tool
import pandas as pd@tool
def describe_data(csv: str) -> str:
"""Describe the date column in the dataframe.
Args:
csv: csv data path string
"""
df = pd.read_csv(csv)
describe_str = f"""Data: {csv}""" + df.describe(include='all').to_string()
return describe_strtools = [describe_data]!pip install langchain_openai!pip install langchain_anthropicfrom langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
llm_gpt = ChatOpenAI(model="gpt-5-nano")
llm_with_tools = llm_gpt.bind_tools(tools, tool_choice="any")response = llm_with_tools.invoke(
"https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diabetes.csv 이 데이터의 전처리를 해주세요."
)response.tool_calls[0]{'name': 'describe_data',
'args': {'csv': 'https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diabetes.csv'},
'id': 'call_VLcYSy8dVc9G9Wwyt4rsOPfC',
'type': 'tool_call'}response.tool_calls[0]['args']{'csv': 'https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diabetes.csv'}from pydantic import BaseModel, Field
class code(BaseModel):
"""Schema for code solutions."""
prefix: str = Field(description="Description of the problem and approach")
imports: str = Field(description="Code block import statements")
code: str = Field(description="Code block not including import statements")from langchain_core.prompts import ChatPromptTemplate
GENERATE_CODE_TEMPLATE = """
Given the following pandas `describe()` output of a dataset,
write a **directly executable Python code** to:
1. handle missing values,
2. convert categorical columns,
3. ...any additional preprocessing needed,
4. prepare the dataset for machine learning.
Here is the describe result of the dataset:
\n ------- \n {context} \n ------- \n
Do not wrap the code in a function and the response in any backticks or anything else. The code should be written as a flat script, so that it can be run immediately and any errors will be visible during execution.
Ensure any code you provide can be executed \n
with all required imports and variables defined. Structure your answer with a description of the code solution. \n
Then list the imports. And finally list the functioning code block.
"""
code_gen_prompt = ChatPromptTemplate.from_messages(
[
("user", GENERATE_CODE_TEMPLATE),
]
)from langchain_anthropic import ChatAnthropic
llm_claude= ChatAnthropic(model="claude-sonnet-4-20250514")response.tool_calls[0]['args']{'csv': 'https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diabetes.csv'}tool_result = describe_data.invoke(response.tool_calls[0]['args'])
print(tool_result)Data: https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diabetes.csv Number of times pregnant Plasma glucose concentration a 2 hours in an oral glucose tolerance test Diastolic blood pressure (mm Hg) Triceps skin fold thickness (mm) 2-Hour serum insulin (mu U/ml) Body mass index (weight in kg/(height in m)^2) Diabetes pedigree function Age (years) Class variable
count 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000
mean 3.845052 120.894531 69.105469 20.536458 79.799479 31.992578 0.471876 33.240885 0.348958
std 3.369578 31.972618 19.355807 15.952218 115.244002 7.884160 0.331329 11.760232 0.476951
min 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.078000 21.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000 27.300000 0.243750 24.000000 0.000000
50% 3.000000 117.000000 72.000000 23.000000 30.500000 32.000000 0.372500 29.000000 0.000000
75% 6.000000 140.250000 80.000000 32.000000 127.250000 36.600000 0.626250 41.000000 1.000000
max 17.000000 199.000000 122.000000 99.000000 846.000000 67.100000 2.420000 81.000000 1.000000generated_code = llm_claude.invoke(
code_gen_prompt.format_messages(context=tool_result)
)
print("generated_code", generated_code)generated_code content='## Description\n\nThis code will preprocess the diabetes dataset for machine learning by:\n1. Loading the data from the provided URL\n2. Handling missing values that are encoded as zeros (common in medical datasets)\n3. Applying appropriate imputation strategies for different types of features\n4. Scaling numerical features for better model performance\n5. Splitting the data into training and testing sets\n\nThe dataset appears to have missing values encoded as zeros for several medical measurements (glucose, blood pressure, skin fold thickness, insulin, BMI), which need to be properly handled as true missing values and imputed.\n\n## Imports\n\n```python\nimport pandas as pd\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.impute import SimpleImputer\n```\n\n## Code\n\n```python\nimport pandas as pd\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.impute import SimpleImputer\n\n# Load the dataset\nurl = "https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diabetes.csv"\ndf = pd.read_csv(url)\n\nprint("Original dataset shape:", df.shape)\nprint("\\nFirst few rows:")\nprint(df.head())\n\n# Display column names for reference\nprint("\\nColumn names:")\nfor i, col in enumerate(df.columns):\n print(f"{i}: {col}")\n\n# Handle missing values encoded as zeros\n# These columns should not have zero values in medical context\ncolumns_with_zero_as_missing = [\n \'Plasma glucose concentration a 2 hours in an oral glucose tolerance test\',\n \'Diastolic blood pressure (mm Hg)\',\n \'Triceps skin fold thickness (mm)\',\n \'2-Hour serum insulin (mu U/ml)\',\n \'Body mass index (weight in kg/(height in m)^2)\'\n]\n\n# Replace zeros with NaN for these columns\nfor col in columns_with_zero_as_missing:\n df[col] = df[col].replace(0, np.nan)\n\nprint("\\nMissing values after converting zeros to NaN:")\nprint(df.isnull().sum())\n\n# Separate features and target\nX = df.drop(\'Class variable\', axis=1)\ny = df[\'Class variable\']\n\n# Handle missing values with median imputation (robust to outliers)\nimputer = SimpleImputer(strategy=\'median\')\nX_imputed = pd.DataFrame(imputer.fit_transform(X), columns=X.columns)\n\nprint("\\nMissing values after imputation:")\nprint(X_imputed.isnull().sum())\n\n# Check for any remaining missing values\nif X_imputed.isnull().sum().sum() > 0:\n print("Warning: Still have missing values after imputation")\nelse:\n print("All missing values handled successfully")\n\n# Split the data into training and testing sets\nX_train, X_test, y_train, y_test = train_test_split(\n X_imputed, y, test_size=0.2, random_state=42, stratify=y\n)\n\nprint(f"\\nTraining set shape: {X_train.shape}")\nprint(f"Testing set shape: {X_test.shape}")\nprint(f"Training set class distribution:\\n{y_train.value_counts()}")\n\n# Scale the features\nscaler = StandardScaler()\nX_train_scaled = scaler.fit_transform(X_train)\nX_test_scaled = scaler.transform(X_test)\n\n# Convert back to DataFrames for easier handling\nX_train_scaled = pd.DataFrame(X_train_scaled, columns=X_train.columns, index=X_train.index)\nX_test_scaled = pd.DataFrame(X_test_scaled, columns=X_test.columns, index=X_test.index)\n\nprint("\\nFeature scaling completed")\nprint("Training set statistics after scaling:")\nprint(X_train_scaled.describe().round(3))\n\nprint("\\nDataset is now ready for machine learning!")\nprint(f"Final training features shape: {X_train_scaled.shape}")\nprint(f"Final testing features shape: {X_test_scaled.shape}")\nprint(f"Target variable shape - train: {y_train.shape}, test: {y' additional_kwargs={} response_metadata={'id': 'msg_014J5VsjRBEX3Ukc6W7SuL7s', 'model': 'claude-sonnet-4-20250514', 'stop_reason': 'max_tokens', 'stop_sequence': None, 'usage': {'cache_creation': {'ephemeral_1h_input_tokens': 0, 'ephemeral_5m_input_tokens': 0}, 'cache_creation_input_tokens': 0, 'cache_read_input_tokens': 0, 'input_tokens': 756, 'output_tokens': 1024, 'server_tool_use': None, 'service_tier': 'standard'}, 'model_name': 'claude-sonnet-4-20250514'} id='run--7c9badc9-71cd-4140-8c65-3990e19f815f-0' usage_metadata={'input_tokens': 756, 'output_tokens': 1024, 'total_tokens': 1780, 'input_token_details': {'cache_read': 0, 'cache_creation': 0, 'ephemeral_5m_input_tokens': 0, 'ephemeral_1h_input_tokens': 0}}code_structurer = llm_gpt.with_structured_output(code)
code_solution = code_structurer.invoke(generated_code.content)
print("code_solution", code_solution)code_solution prefix="Preprocess the diabetes dataset by loading it from the provided URL, treating medically implausible zeros as missing values, imputing missing values, scaling numerical features, and splitting into train/test sets. The dataset may use different target column names (e.g., 'Outcome' or 'Class variable'), so the code detects the target column robustly. Only the medically invalid zeros in Glucose, BloodPressure, SkinThickness, Insulin, and BMI are replaced with NaN before imputation." imports='import pandas as pd\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.impute import SimpleImputer' code='# Load the dataset\nurl = "https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diabetes.csv"\ndf = pd.read_csv(url)\n\n# Detect target column robustly\nif \'Outcome\' in df.columns:\n target_col = \'Outcome\'\nelif \'Class variable\' in df.columns:\n target_col = \'Class variable\'\nelse:\n raise ValueError("Target column not found. Expected \'Outcome\' or \'Class variable\'.")\n\ny = df[target_col]\nX = df.drop(columns=[target_col])\n\n# Identify columns where zeros are considered missing (medical context)\nzero_as_missing_cols = [\'Glucose\',\'BloodPressure\',\'SkinThickness\',\'Insulin\',\'BMI\']\n\n# Replace zeros with NaN for these columns when present\nfor col in zero_as_missing_cols:\n if col in X.columns:\n X[col] = X[col].replace(0, np.nan)\n\nprint("Missing values per column before imputation:")\nprint(X.isnull().sum().sort_values(ascending=False))\n\n# Impute missing values (median is robust to outliers) for numeric features\nimputer = SimpleImputer(strategy=\'median\')\nX_imputed = pd.DataFrame(imputer.fit_transform(X), columns=X.columns)\n\nprint("\\nMissing values after imputation:")\nprint(X_imputed.isnull().sum())\n\n# Verify there are no remaining missing values\nif X_imputed.isnull().sum().sum() > 0:\n print("Warning: Still have missing values after imputation")\nelse:\n print("All missing values handled successfully")\n\n# Split the data into training and testing sets\nX_train, X_test, y_train, y_test = train_test_split(\n X_imputed, y, test_size=0.2, random_state=42, stratify=y\n)\n\nprint(f"\\nTraining set shape: {X_train.shape}")\nprint(f"Testing set shape: {X_test.shape}")\nprint(f"Training set class distribution:\\n{y_train.value_counts()}")\n\n# Scale numerical features\nscaler = StandardScaler()\nX_train_scaled = scaler.fit_transform(X_train)\nX_test_scaled = scaler.transform(X_test)\n\n# Convert back to DataFrames for easier handling\nX_train_scaled = pd.DataFrame(X_train_scaled, columns=X_train.columns, index=X_train.index)\nX_test_scaled = pd.DataFrame(X_test_scaled, columns=X_test.columns, index=X_test.index)\n\nprint("\\nFeature scaling completed")\nprint("Training set statistics after scaling:")\nprint(X_train_scaled.describe().round(3))\n\nprint("\\nDataset is now ready for machine learning!")\nprint(f"Final training features shape: {X_train_scaled.shape}")\nprint(f"Final testing features shape: {X_test_scaled.shape}")\nprint(f"Target variable shape - train: {y_train.shape}, test: {y_test.shape}")\n'print(code_solution.imports)import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputerprint(code_solution.code)# Load the dataset
url = "https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diabetes.csv"
df = pd.read_csv(url)
# Detect target column robustly
if 'Outcome' in df.columns:
target_col = 'Outcome'
elif 'Class variable' in df.columns:
target_col = 'Class variable'
else:
raise ValueError("Target column not found. Expected 'Outcome' or 'Class variable'.")
y = df[target_col]
X = df.drop(columns=[target_col])
# Identify columns where zeros are considered missing (medical context)
zero_as_missing_cols = ['Glucose','BloodPressure','SkinThickness','Insulin','BMI']
# Replace zeros with NaN for these columns when present
for col in zero_as_missing_cols:
if col in X.columns:
X[col] = X[col].replace(0, np.nan)
print("Missing values per column before imputation:")
print(X.isnull().sum().sort_values(ascending=False))
# Impute missing values (median is robust to outliers) for numeric features
imputer = SimpleImputer(strategy='median')
X_imputed = pd.DataFrame(imputer.fit_transform(X), columns=X.columns)
print("\nMissing values after imputation:")
print(X_imputed.isnull().sum())
# Verify there are no remaining missing values
if X_imputed.isnull().sum().sum() > 0:
print("Warning: Still have missing values after imputation")
else:
print("All missing values handled successfully")
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X_imputed, y, test_size=0.2, random_state=42, stratify=y
)
print(f"\nTraining set shape: {X_train.shape}")
print(f"Testing set shape: {X_test.shape}")
print(f"Training set class distribution:\n{y_train.value_counts()}")
# Scale numerical features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Convert back to DataFrames for easier handling
X_train_scaled = pd.DataFrame(X_train_scaled, columns=X_train.columns, index=X_train.index)
X_test_scaled = pd.DataFrame(X_test_scaled, columns=X_test.columns, index=X_test.index)
print("\nFeature scaling completed")
print("Training set statistics after scaling:")
print(X_train_scaled.describe().round(3))
print("\nDataset is now ready for machine learning!")
print(f"Final training features shape: {X_train_scaled.shape}")
print(f"Final testing features shape: {X_test_scaled.shape}")
print(f"Target variable shape - train: {y_train.shape}, test: {y_test.shape}")
!pip install langgraphfrom langgraph.graph import StateGraph, MessagesState
class State(MessagesState): # messages
"""
Represents the state of our graph.
Attributes:
error : Binary flag for control flow to indicate whether test error was tripped
context: Data summary
generation : Code solution
iterations : Number of tries
"""
error: str # yes or no
context: str
generation: str
iterations: int
graph_builder = StateGraph(State)from langchain_core.tools import tool
import pandas as pd
@tool
def describe_data(csv: str) -> str:
"""Describe the date column in the dataframe.
Args:
csv: csv data path string
"""
df = pd.read_csv(csv)
describe_str = f"""Data: {csv}""" + df.describe(include='all').to_string()
return describe_strllm_with_tools = llm_gpt.bind_tools(tools=[describe_data], tool_choice="any")def chatbot(state: State):
print("##### HI ! #####")
response = llm_with_tools.invoke(state["messages"])
print("첫번째 LLM 호출 결과 : ", response)
return {"messages": [response]}
graph_builder.add_node("chatbot", chatbot)<langgraph.graph.state.StateGraph at 0x797cc45bcd70>def add_context(state: State):
print("##### ADD CONTEXT #####")
if messages := state.get("messages", []):
message = messages[-1] # 마지막 message
else:
raise ValueError("No message found in input")
for tool_call in message.tool_calls:
for tool in tools:
if tool.name == tool_call['name']:
describe_str = tool.invoke(tool_call['args'])
# Get context from describe_data tool
print("데이터 통계 (context) : ", describe_str[:100])
return {"context": describe_str}
graph_builder.add_node("add_context", add_context)<langgraph.graph.state.StateGraph at 0x797cc45bcd70>from langgraph.graph import END
def guardrail_route(
state: State,
):
"""
Use in the conditional_edge to route to the ToolNode if the last message
has tool calls. Otherwise, route to the end.
"""
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "add_context"
return END
graph_builder.add_conditional_edges(
"chatbot",
guardrail_route,
{"add_context": "add_context", END: END},
)<langgraph.graph.state.StateGraph at 0x797cc45bcd70>from pydantic import BaseModel, Field
class code(BaseModel):
"""Schema for code solutions."""
prefix: str = Field(description="Description of the problem and approach")
imports: str = Field(description="Code block import statements")
code: str = Field(description="Code block not including import statements")from langchain_core.prompts import ChatPromptTemplate
GENERATE_CODE_TEMPLATE = """
Given the following pandas `describe()` output of a dataset,
write a **directly executable Python code** to:
1. handle missing values,
2. convert categorical columns,
3. ...any additional preprocessing needed,
4. prepare the dataset for machine learning.
Here is the describe result of the dataset:
\n ------- \n {context} \n ------- \n
Do not wrap the code in a function and the response in any backticks or anything else. The code should be written as a flat script, so that it can be run immediately and any errors will be visible during execution.
Ensure any code you provide can be executed \n
with all required imports and variables defined. Structure your answer with a description of the code solution. \n
Then list the imports. And finally list the functioning code block.
"""
code_gen_prompt = ChatPromptTemplate.from_messages(
[
("user", GENERATE_CODE_TEMPLATE),
]
)def generate(state: State):
print("##### GENERATING CODE SOLUTION #####")
context = state["context"]
generated_code = llm_claude.invoke(
code_gen_prompt.format_messages(context=context)
)
code_structurer = llm_gpt.with_structured_output(code)
code_solution = code_structurer.invoke(generated_code.content)
messages = [
(
"assistant",
f"{code_solution.prefix} \n Imports: {code_solution.imports} \n Code: {code_solution.code}",
)
]
return {"generation": code_solution, "messages": messages}
graph_builder.add_node("generate", generate)<langgraph.graph.state.StateGraph at 0x797cc45bcd70>def code_check(state: State):
print("##### CHECKING CODE #####")
code_solution = state["generation"]
imports = code_solution.imports
code = code_solution.code
# Check imports
try:
exec(imports)
except Exception as e:
print("---CODE IMPORT CHECK: FAILED---")
error_message = [("user", f"Your solution failed the import test: {e}")]
print("에러 메시지 : ", error_message)
return {
"generation": code_solution,
"messages": error_message,
"error": "yes",
}
# Check execution
try:
exec(imports + "\n" + code)
except Exception as e:
print("---CODE BLOCK CHECK: FAILED---")
error_message = [("user", f"Your solution failed the code execution test: {e}")]
print("에러 메시지 : ", error_message)
return {
"generation": code_solution,
"messages": error_message,
"error": "yes",
}
# No errors
print("---NO CODE TEST FAILURES---")
return {
"generation": code_solution,
"error": "no",
}
graph_builder.add_node("code_check", code_check)from langchain_core.prompts import ChatPromptTemplate
reflect_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""
You are given an error message that occurred while running a Python script, along with the original code that produced the error.
Provide a corrected version of the original code that resolves the issue.
Ensure the code runs without errors and maintains the intended functionality."""
),
(
"user",
"""
--- ERROR MESSAGE ---
{error}
--- ORIGINAL CODE ---
{code_solution}
----------------------
Ensure any code you provide can be executed \n
with all required imports and variables defined. Structure your answer with a description of the code solution. \n
Then list the imports. And finally list the functioning code block.""",
)
]
)def reflect(state: State):
print("---REFLECTING CODE SOLUTION---")
error = state["messages"][-1].content
code_solution = state["generation"]
code_solution = f"{code_solution.prefix} \n Imports: {code_solution.imports} \n Code: {code_solution.code}"
corrected_code = llm_claude.invoke(reflect_prompt.format_messages(error=error, code_solution=code_solution))
code_structurer = llm_gpt.with_structured_output(code)
reflections = code_structurer.invoke(corrected_code.content)
print("수정된 코드 : ", reflections)
messages = [
(
"assistant",
f"{reflections.prefix} \n Imports: {reflections.imports} \n Code: {reflections.code}",
)
]
return {"generation": reflections, "messages": messages, "iterations": state["iterations"] + 1}
graph_builder.add_node("reflect", reflect)<langgraph.graph.state.StateGraph at 0x797cc45bcd70>max_iterations = 5def decide_to_finish(state: State):
error = state["error"]
iterations = state["iterations"]
if error == "no" or iterations == max_iterations: # 에러가 없거나 max_iterations에 도달하면 종료
print("---DECISION: FINISH---")
return "end"
else:
print("---DECISION: RE-TRY SOLUTION---")
return "reflect"from langgraph.graph import START, END
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("add_context", "generate")
graph_builder.add_edge("generate", "code_check")
graph_builder.add_conditional_edges(
"code_check",
decide_to_finish,
{
"end": END,
"reflect": "reflect"
},
)
graph_builder.add_edge("reflect", "code_check")
graph = graph_builder.compile()
graph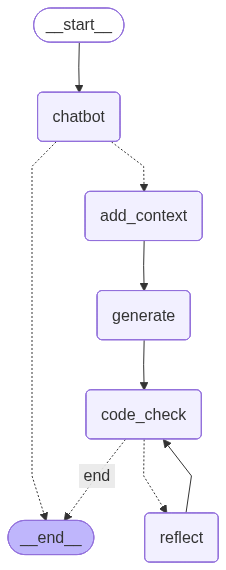
question = 'titanic.csv 데이터의 전처리를 부탁해요~'solution = graph.invoke({"messages": [('user', question)], 'iterations': 0, 'error': ''})##### HI ! #####
첫번째 LLM 호출 결과 : content='' additional_kwargs={'tool_calls': [{'id': 'call_82Jcpo1aDVM3eaZldLQnluXv', 'function': {'arguments': '{"csv":"titanic.csv"}', 'name': 'describe_data'}, 'type': 'function'}], 'refusal': None} response_metadata={'token_usage': {'completion_tokens': 282, 'prompt_tokens': 148, 'total_tokens': 430, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 256, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-5-nano-2025-08-07', 'system_fingerprint': None, 'id': 'chatcmpl-CGExd3sG5Ia70S9H89R5sxzhO8gvI', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None} id='run--ffc1533e-6677-40ca-b29f-d8cfe577f362-0' tool_calls=[{'name': 'describe_data', 'args': {'csv': 'titanic.csv'}, 'id': 'call_82Jcpo1aDVM3eaZldLQnluXv', 'type': 'tool_call'}] usage_metadata={'input_tokens': 148, 'output_tokens': 282, 'total_tokens': 430, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 256}}
##### ADD CONTEXT #####
데이터 통계 (context) : Data: titanic.csv PassengerId Survived Pclass Name Sex Age
##### GENERATING CODE SOLUTION #####
##### CHECKING CODE #####
---CODE BLOCK CHECK: FAILED---
에러 메시지 : [('user', 'Your solution failed the code execution test: unexpected indent (<string>, line 9)')]
---DECISION: RE-TRY SOLUTION---
---REFLECTING CODE SOLUTION---
수정된 코드 : prefix="You're seeing an unexpected indent error likely due to inconsistent indentation and an incomplete code block. Below is a cleaned, complete Titanic preprocessing pipeline with consistent 4-space indentation and a working baseline logistic regression model." imports='import pandas as pd\nimport numpy as np\nfrom sklearn.preprocessing import LabelEncoder, StandardScaler\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.impute import SimpleImputer\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import accuracy_score' code='# Load the dataset\ndf = pd.read_csv(\'titanic.csv\')\n\nprint("Original dataset shape:", df.shape)\nprint("\\nMissing values:")\nprint(df.isnull().sum())\n\n# Handle missing values\n# Age: Fill with median\ndf[\'Age\'].fillna(df[\'Age\'].median(), inplace=True)\n\n# Embarked: Fill with mode (most frequent value)\ndf[\'Embarked\'].fillna(df[\'Embarked\'].mode()[0], inplace=True)\n\n# Cabin: Create a binary feature for cabin availability and drop original\ndf[\'Has_Cabin\'] = df[\'Cabin\'].notna().astype(int)\ndf.drop(\'Cabin\', axis=1, inplace=True)\n\n# Create new features\n# Extract title from Name\ndf[\'Title\'] = df[\'Name\'].str.extract(\' ([A-Za-z]+)\\.\', expand=False)\n\n# Group rare titles\ntitle_mapping = {\n \'Mr\': \'Mr\', \'Miss\': \'Miss\', \'Mrs\': \'Mrs\', \'Master\': \'Master\',\n \'Dr\': \'Rare\', \'Rev\': \'Rare\', \'Mlle\': \'Miss\', \'Major\': \'Rare\',\n \'Col\': \'Rare\', \'Sir\': \'Rare\', \'Don\': \'Rare\', \'Mme\': \'Mrs\',\n \'Jonkheer\': \'Rare\', \'Lady\': \'Rare\', \'Capt\': \'Rare\', \'Countess\': \'Rare\',\n \'Ms\': \'Miss\', \'Dona\': \'Rare\'\n}\ndf[\'Title\'] = df[\'Title\'].map(title_mapping)\n# If any Title is unmapped (NaN), assign \'Rare\'\ndf[\'Title\'] = df[\'Title\'].fillna(\'Rare\')\n\n# Create family size feature\ndf[\'Family_Size\'] = df[\'SibSp\'] + df[\'Parch\'] + 1\n\n# Create is_alone feature\ndf[\'Is_Alone\'] = (df[\'Family_Size\'] == 1).astype(int)\n\n# Create age groups\ndf[\'Age_Group\'] = pd.cut(df[\'Age\'], bins=[0, 18, 35, 60, 100], labels=[\'Child\', \'Young\', \'Adult\', \'Senior\'])\n\n# Create fare groups\ndf[\'Fare_Group\'] = pd.cut(df[\'Fare\'], bins=[0, 7.91, 14.45, 31, 600], labels=[\'Low\', \'Medium\', \'High\', \'Very_High\'])\n\n# Drop unnecessary columns\ncolumns_to_drop = [\'PassengerId\', \'Name\', \'Ticket\']\ndf.drop(columns=columns_to_drop, inplace=True)\n\n# Convert categorical variables to numerical\ncategorical_columns = [\'Sex\', \'Embarked\', \'Title\', \'Age_Group\', \'Fare_Group\']\n\n# Features and target\nX = df.drop(\'Survived\', axis=1)\ny = df[\'Survived\']\n\n# Train-test split\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)\n\n# Encode categorical features using LabelEncoder (fit on combined train/test to avoid unknowns)\nlabel_encoders = {}\nfor col in categorical_columns:\n le = LabelEncoder()\n combined = pd.concat([X_train[col].astype(str), X_test[col].astype(str)], axis=0).astype(str)\n le.fit(combined)\n X_train[col] = le.transform(X_train[col].astype(str))\n X_test[col] = le.transform(X_test[col].astype(str))\n label_encoders[col] = le\n\n# Impute any remaining missing values (numeric features may be int/float; after encoding, all are numeric)\nimputer = SimpleImputer(strategy=\'median\')\nX_train = imputer.fit_transform(X_train)\nX_test = imputer.transform(X_test)\n\n# Scale features\nscaler = StandardScaler()\nX_train = scaler.fit_transform(X_train)\nX_test = scaler.transform(X_test)\n\n# Convert back to DataFrame for readability (optional)\ntrain_cols = [col for col in df.drop(\'Survived\', axis=1).columns]\nX_train = pd.DataFrame(X_train, columns=train_cols)\nX_test = pd.DataFrame(X_test, columns=train_cols)\n\n# Train logistic regression model\nlogreg = LogisticRegression(max_iter=1000, random_state=42, solver=\'liblinear\')\nlogreg.fit(X_train, y_train)\n\ny_pred = logreg.predict(X_test)\nacc = accuracy_score(y_test, y_pred)\nprint("Validation accuracy:", acc)\n'
##### CHECKING CODE #####
Original dataset shape: (891, 12)
Missing values:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
Validation accuracy: 0.7988826815642458
---NO CODE TEST FAILURES---
---DECISION: FINISH---
<string>:28: SyntaxWarning: invalid escape sequence '\.'
<string>:17: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
<string>:20: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
print(solution["generation"].prefix,"\n")
print(solution["generation"].imports,"\n")
print(solution["generation"].code)You're seeing an unexpected indent error likely due to inconsistent indentation and an incomplete code block. Below is a cleaned, complete Titanic preprocessing pipeline with consistent 4-space indentation and a working baseline logistic regression model.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Load the dataset
df = pd.read_csv('titanic.csv')
print("Original dataset shape:", df.shape)
print("\nMissing values:")
print(df.isnull().sum())
# Handle missing values
# Age: Fill with median
df['Age'].fillna(df['Age'].median(), inplace=True)
# Embarked: Fill with mode (most frequent value)
df['Embarked'].fillna(df['Embarked'].mode()[0], inplace=True)
# Cabin: Create a binary feature for cabin availability and drop original
df['Has_Cabin'] = df['Cabin'].notna().astype(int)
df.drop('Cabin', axis=1, inplace=True)
# Create new features
# Extract title from Name
df['Title'] = df['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
# Group rare titles
title_mapping = {
'Mr': 'Mr', 'Miss': 'Miss', 'Mrs': 'Mrs', 'Master': 'Master',
'Dr': 'Rare', 'Rev': 'Rare', 'Mlle': 'Miss', 'Major': 'Rare',
'Col': 'Rare', 'Sir': 'Rare', 'Don': 'Rare', 'Mme': 'Mrs',
'Jonkheer': 'Rare', 'Lady': 'Rare', 'Capt': 'Rare', 'Countess': 'Rare',
'Ms': 'Miss', 'Dona': 'Rare'
}
df['Title'] = df['Title'].map(title_mapping)
# If any Title is unmapped (NaN), assign 'Rare'
df['Title'] = df['Title'].fillna('Rare')
# Create family size feature
df['Family_Size'] = df['SibSp'] + df['Parch'] + 1
# Create is_alone feature
df['Is_Alone'] = (df['Family_Size'] == 1).astype(int)
# Create age groups
df['Age_Group'] = pd.cut(df['Age'], bins=[0, 18, 35, 60, 100], labels=['Child', 'Young', 'Adult', 'Senior'])
# Create fare groups
df['Fare_Group'] = pd.cut(df['Fare'], bins=[0, 7.91, 14.45, 31, 600], labels=['Low', 'Medium', 'High', 'Very_High'])
# Drop unnecessary columns
columns_to_drop = ['PassengerId', 'Name', 'Ticket']
df.drop(columns=columns_to_drop, inplace=True)
# Convert categorical variables to numerical
categorical_columns = ['Sex', 'Embarked', 'Title', 'Age_Group', 'Fare_Group']
# Features and target
X = df.drop('Survived', axis=1)
y = df['Survived']
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# Encode categorical features using LabelEncoder (fit on combined train/test to avoid unknowns)
label_encoders = {}
for col in categorical_columns:
le = LabelEncoder()
combined = pd.concat([X_train[col].astype(str), X_test[col].astype(str)], axis=0).astype(str)
le.fit(combined)
X_train[col] = le.transform(X_train[col].astype(str))
X_test[col] = le.transform(X_test[col].astype(str))
label_encoders[col] = le
# Impute any remaining missing values (numeric features may be int/float; after encoding, all are numeric)
imputer = SimpleImputer(strategy='median')
X_train = imputer.fit_transform(X_train)
X_test = imputer.transform(X_test)
# Scale features
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Convert back to DataFrame for readability (optional)
train_cols = [col for col in df.drop('Survived', axis=1).columns]
X_train = pd.DataFrame(X_train, columns=train_cols)
X_test = pd.DataFrame(X_test, columns=train_cols)
# Train logistic regression model
logreg = LogisticRegression(max_iter=1000, random_state=42, solver='liblinear')
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print("Validation accuracy:", acc)

The light shines in the darkness.