1. Intro
- spark을 쓰기 위해서 EMR 클러스터를 띄우고 운영하는 것은 어려운 일이다.
- EMR 클러스터가 각종 이유로 장애에 빠질 수 있기 때문이다.
- 또한 효율적으로 운영하기도 힘들다.
- 아마존에는 lambda 처럼 serverless spark 서비스가 존재한다.
- aws glue 라는 서비스인데 EMR 없이 spark을 사용할 수 있다.
- serverless spark을 쓰기위한 방법을 알아보자!
1-1 Glue spark job 장점
- 복잡한 EMR 클러스터를 관리할 필요가 없다!
- scale out이 매우 쉽다.
1-2 Glue spark job 단점
- 설정에 있어 상당히 제한적이다.
- executor 메모리, core 등 설정은 glue deafult를 따라야한다.
- 디버깅이 힘들다
- 람다가 ec2보다 디버깅이 힘든이유와 같다,,,
- 비싸다
- lambda가 ec2보다 비싸듯이 EMR보다 glue가 비싸다
1-3 어떨때 Glue를 쓸까?
- emr 클러스터가 크게 필요없고, emr 관리할 전문가가 없을때
- spark 잡 수가 많지 않을때
- spark을 가끔 간헐적으로 돌리고 싶을때
1-4 어떨때 EMR을 쓸까?
- emr 클러스터 사용 대비 glue spark 비용으로 인한 추가 비용이, emr 클러스터 전문가를 채용 비용보다 훨씬 높게 나올때
- spark 잡의 복잡한 설정이 필요할때
2. Serverless Spark 소개
- serverless glue spark은 glue job이라는 서비스를 통해 이용할 수 있다.
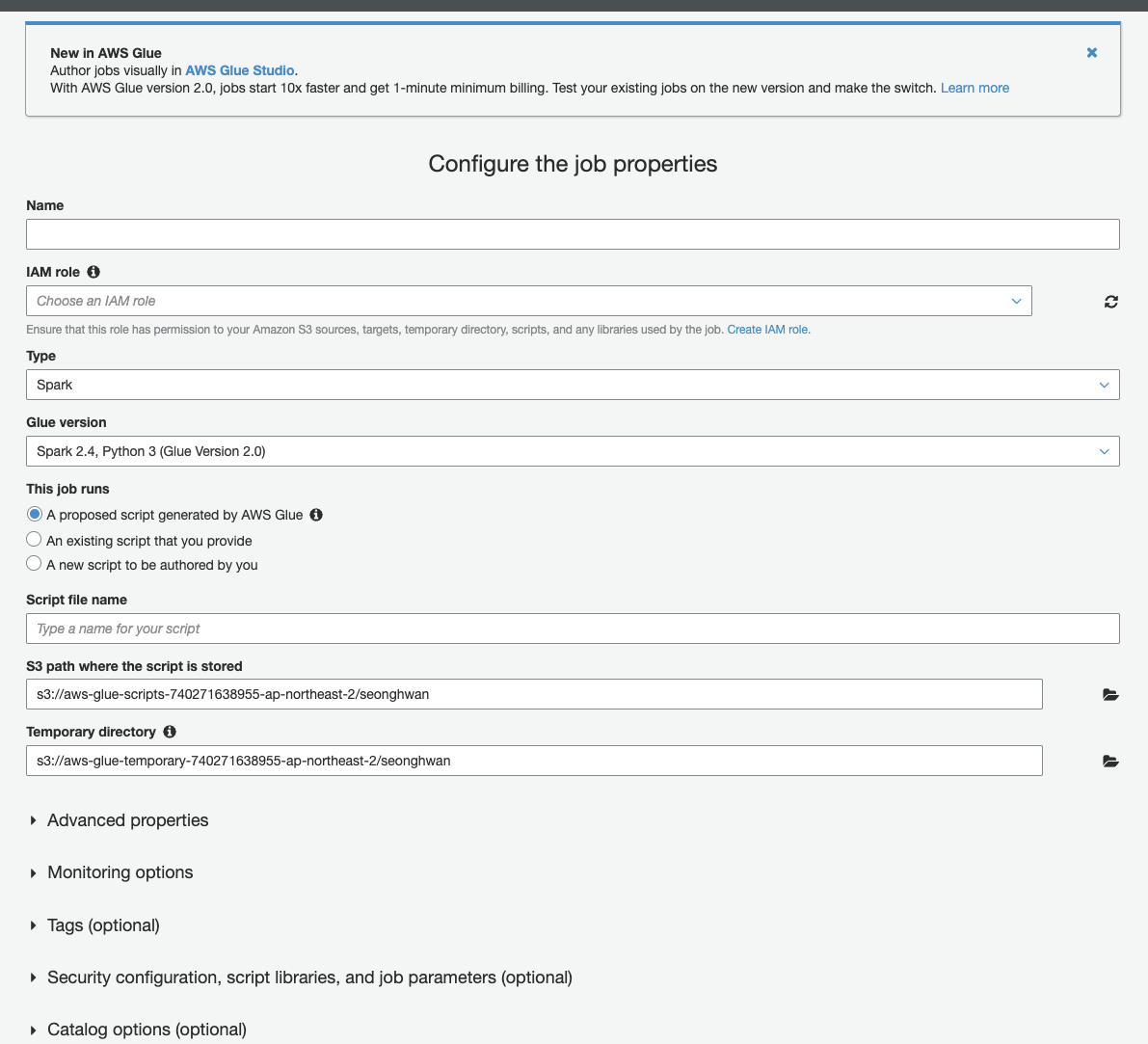
- Add Job을 클릭후 pyspark을 선택후 glue3.0 버전을 선택하여 이용할 수 있다.
- 왠만한 설정들은 거의 직관적이라 잘 설정가능하고 검색이 쉽다.
- 잡 설정 화면
- 아래와 같이 glue 코드를 RUN job 버튼을 통해 돌리면 돌아가게 된다!
- 아래와 같은 코드로 스팍세션을 가져올 수 있고 작업을 할 수 있게 된다.

spark = (SparkSession.builder
.enableHiveSupport() \
.getOrCreate())
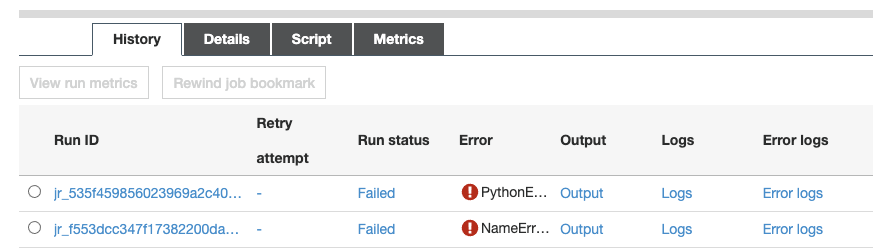
return spark- run job을 통해 돌아간 결과의 로그나 돌아가고 있는 상황도 실시간으로 UI를 통해 확인 할 수 있다.
3. Glue spark 까다로운 점
-
package dependency
- 위 처럼 간단하게 glue 스팍을 실행해보고 spark session을 통해 s3에 있는 예제를 돌리는 것 까지는 별 문제가 없다.
- glue spark을 처음 쓰게 될 때 제일 짜증나는 것은 바로 파이썬 패키지 즉 dependency 관리이다.
- 아무런 설정 없이 쓰게 되면 glue spark에 설치 되어있는 기본 패키지 밖에 못 쓰기 때문이다.
-
subnet, security group 설정
- vpc안에 있는 rdb, redis, ec2 등 각종 서버에 접속하고 싶을 수 있다.
- 이때 connection이라는 것을 설정해줘야 하는데 처음하면 어려울 수 있다.
4. Glue spark 패키지 관리
4-1 패키지 설정 방법 기본
- glue 스팍에서 패키지 인스톨 방법은 크게 2가지 방법이 있다.
- Security configuration, script libraries, and job parameters (optional)메뉴 활용

- 해당 메뉴 탭에서 위 처럼 library path를 넣을 수 있도록 해놨다.
- 위 경로에 파이썬 패키지 압축파일을 넣으면 된다.
- 이 방법 은 pure python만 된다는 아주 큰 단점이 있다.
- --additional-python-modules
- additional-python-modules 라는 파라메터로 필요한 패키지 목록을 넘기면 worker가 뜨기전에 pip3 설치를 한번 해주고 띄운다.
- 아래처럼 job paraemters 항목에서 설정해주면 된다.

- Security configuration, script libraries, and job parameters (optional)메뉴 활용
- 1번 방법은 pure python이라는 매우 제한된 경우만 가능하며 나는 tensorflowm, numpy등 다양한 c-extention을 필요로하는 패키지가 필요했다. 따라서 2번방법을 선택했다.
4-2 패키지 설정 방법 응용
- 패키지와 관련하여 2가지 문제를 생각해보자.
- pip3 install 을 glue job 실행마다 매번 해줘야 한다. 조금이라도 더 빠르게 이 과정을 넘길 수 없을까?
- pip 서버에 없는 custom 모듈 import는 어떻게 할 수 있을까?
.whl 파일 넘기기
- wheel 파일은 파이썬 패키지를 한번 빌드해 놓은 파일 .whl 확장자를 가진 파일을 말한다.
- pip install 명령어를 통해 패키지를 설치해보면 whl파일이 존재하는 경우 이를 다운로드하며, 없다면 소스파일로 부터 whl파일을 만드는 과정을 로그로 볼 수 있다.
- 따라서 whl 파일을 s3에 가지고 있다면 다운로드 속도가 향상되며 (aws 내부망이라 더 빠를 것이라 판단), 소스를 빌드하여 whl파일을 만드는 과정을 생략할 수 있다.
- 따라서 나는
requirements.txt파일을 빌드하여 whl 파일을 만들었다. 그리고 그것을 s3로 모두 올린 후 pip install 옵션으로 s3에 있는 whl 파일 리스트를 올렸다.- pip install "패키지이름" 에서 패키지 이름으로 whl 파일 경로를 넘기면 해당 whl 파일로 패키지를 설치하게 된다.
- https://aws.amazon.com/ko/blogs/big-data/building-python-modules-from-a-wheel-for-spark-etl-workloads-using-aws-glue-2-0/ 이 링크는 관련 참고 파일이다.
- 내가 위 방식을 참고하여 한 방식은 다음과 같다.
- glue 가 돌아가는 환경인 amazonlinux 도커 컨테이너를 기반으로 한다.
- 해당 컨테이너에서 필요한 우분투 패키지를 설치한다(git, pip등)
- requriments.txt경로를 바인딩하여 필요한 패키지를 pip install -w 옵셥을 통해 빌드하여 whl 파일 리스트를 얻는다.
- 이 리스트를 s3 경로로 올린다.
- boto3 glue api를 통해 glue job의 파라메터에 다음과 같이 값을 추가했다.
- "s3에 있는 whl 패키지 리스트"를 value로 "--additional-python-modules"를 key로 설정
- "s3에 있는 whl 패키지 리스트"를 value로 "--additional-python-modules"를 key로 설정
whl 파일을 통해 isntall 을 할 경우 pip install 시간이 크게는 2배까지 빨라진다. 이는 곧 이용시간으로 과금하는 glue의 비용절약이 된다.
setup.py 설정
- import 할때 프로젝트 내부에 있는 custom 모듈을 넘겨야할 수 있다.
- 이러한 경우 때문에 프로젝트에 setup.py를 만들고 해당 repo의 일부를 패키지화 했다.
- requriments.txt 에는
git+ssh://github.com/seonghwan/repo1@master와 같이 추가해줬다. - 이런식으로 하면 해당 repo의 whl파일도 같이 만들어져서 import를 할 수 있게 된다.
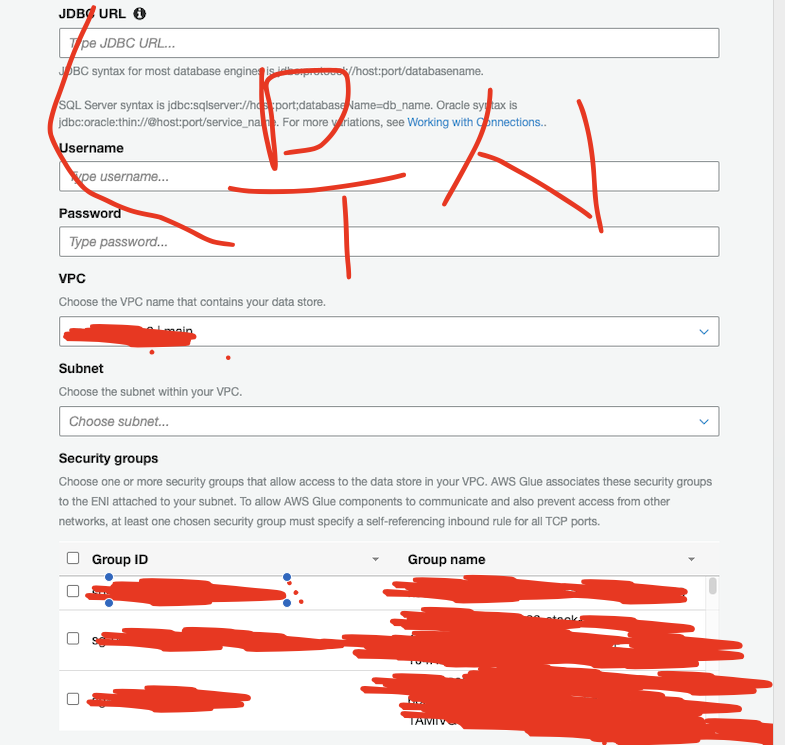
5. Connection
- 이제 VPC안에 있는 리소스에 접근하기 위한 설정을 알아보자.
- 내트워크 설정을 위해서는 connection이라는 것을 만들어주고 이를 추가하면 된다.
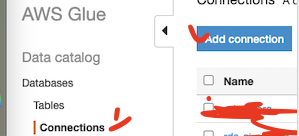
- 이때 설정창에서 JDBC니 뭐니 하면서 사람 정말 헷갈리게 만들게 된다. 검색해봐도 뭔가 이상하다..
- DB 설정밖에 못하나..?
- 서버 접속은 어떻게하지...?
- redis는..?
- 등등..
- 현재 목적에서는 이 db 관련 설정은 별로 안 중요하고, VPC, subnet, security group 만 잘 설정해주면 된다.
- 주의할 점은 glue는 public ip를 만들어주지 않는다. 따라서 subnet 설정에 따라 외부 접속이 안 될수 있으니 명심하자.
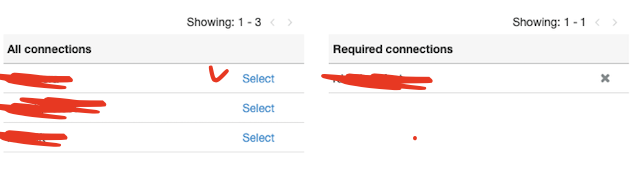
- connection을 만들었으면 glue job 설정에서 아래 처럼 connection을 붙여주면 된다.
- 이렇게 connection을 붙여주면 설정에 따라 security 그룹내 리소스에 잘 접속할 수 있게된다!! ㅎ
6. 결론
- aws 서비스중 하나인 glue가 간단한 serverless spark 작업을 돌릴 수 있다는 것을 알아봤다.
- glue를 세팅할때 주의할 점인 connection과 package설정을 어떻게 할 수 있는지 알아봤다!

Machine Learning Engineer: recsys, mlops