
1. DBT는 언제 쓰나?
- DB의 테이블들을 SQL로 가공하여 다시 DB로 넣고 싶을때 쓸 수 있다.
- 예를 들어 단순히 SQL을 통해 데이터를 가공하여 데이터를 다시 DB에 넣어주는 경우가 많다.
- 예를 들어 단순히 SQL을 통해 데이터를 가공하여 데이터를 다시 DB에 넣어주는 경우가 많다.
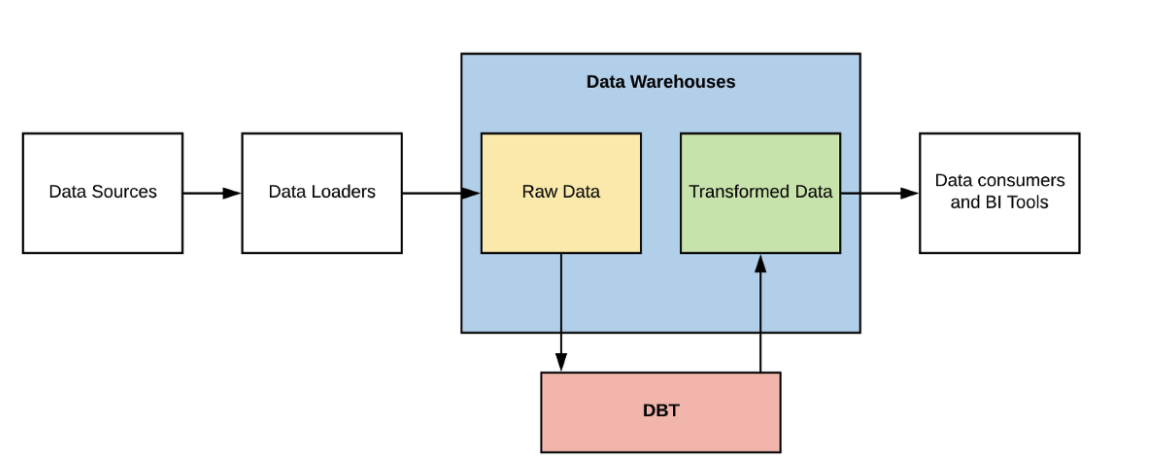
- SELECT 쿼리를 통해 data를 받아온 후 그 데이터를 INSERT를 통해 다시 넣어주는 작업
2. Why DBT?
-
테이블간의 처리 관계가 복잡해질 때 시각화하여 볼 수 있다(
Automated documentation)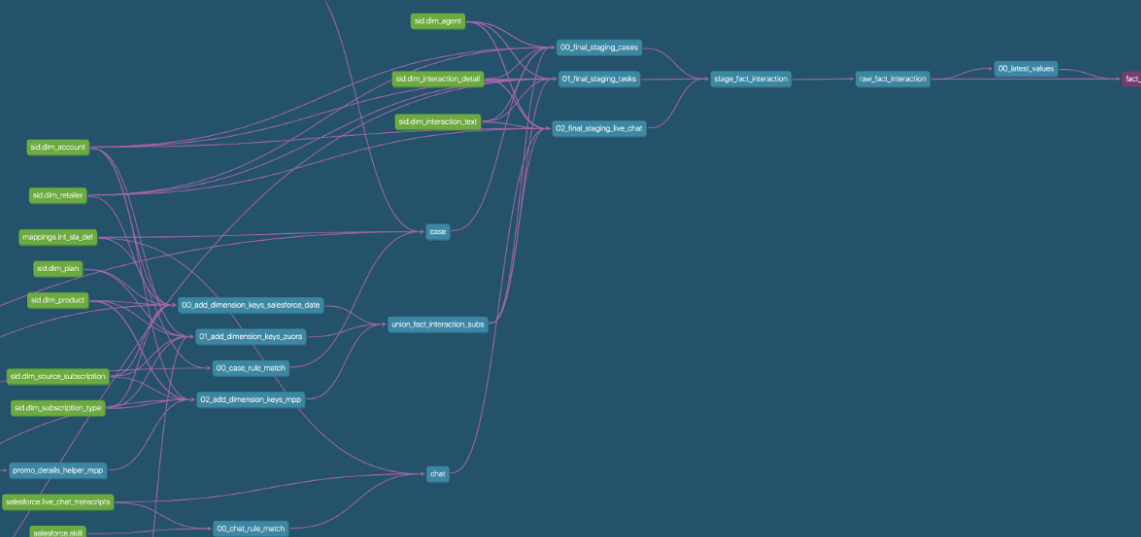
-
SQL 로직 자체에 집중할 수 있다. (ETL을 위해 쿼리 파일(.sql)외에 code 작성할 필요 없음) -
쿼리에 대한 좀더 깊은
테스트를 사전에 할 수 있다.- 기존 ETL코드에서는 SQL이 문자열이기 때문에 못하는 타입 체크, 유니크 조건등을 실행전에 테스트를 할 수 있음
-
버전 관리- 모든 테이블 정의가 코드로 이루어지기 때문에 버전 관리가 가능하다.
-
프로그래머가 아닌 사업팀에서 SQL만 알아도 원하는 데이터 파이프라인을 만들 수 있다.
3. DBT의 단점, 쓸 수 없는 경우?
**Transformation 로직이 SQL로 표현 가능해야함**- CF 추천 결과 테이블을 만들때
- 딥러닝 모델의 결과를 저장하고 싶을 때
- SQL로 표현이 힘들기 때문에 이럴때 DBT를 쓰기 힘들다.
- production 데이터와 별개의 분석용 데이터 웨어하우스에 적합함
- 모든 데이터의 copy가 데이터웨어하우스(athena)에 있어야함
- 배치 처리 데이터(real time 동작은 안 된다)
4. DBT란 무엇이며 기존 시스템과의 차이는?
- 일종의 체계적인 view 시스템
ELT: Extract→Load→Transform(NOTETL)- https://artist-developer.tistory.com/m/37(← 매우 이해하기 쉬운 좋은 글을 누군가 잘 적어둠)
- 일단 전부 Data Lake에 적재(Extract→Load)
- 어떻게 쓸지 나중에 고민(Transformation)
- BI, Analytics 팀에 적합함
- ETL
- 서빙등에 적합, 시스템이 안정적임
5. Simple Example
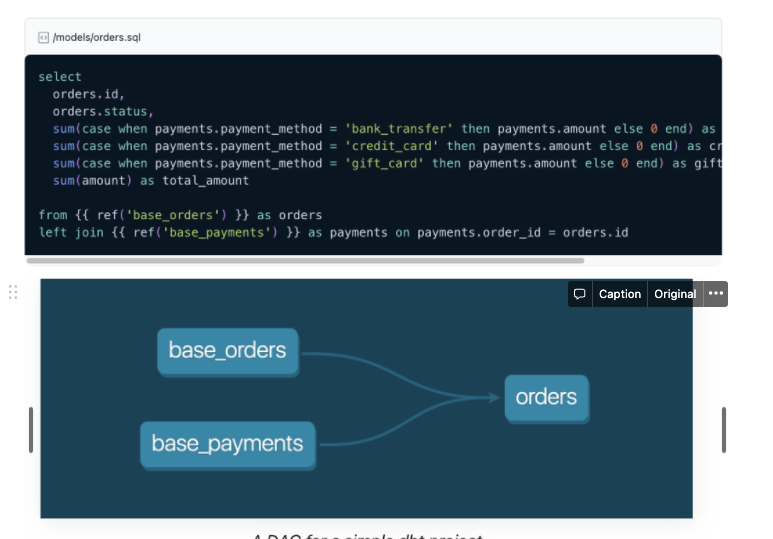
1. Jinja 템플릿 형식을 통해 SQL 파일을 작성한다.
2. UI를 통해 해당 SQL파일의 dependency등을 쉽게 파악할 수 있다.
3. Run(CLI or UI)을 실행하면 SELECT문이 실행되면서 View가 DB에 생긴다.
💡 View만 가능할까..? - default output은 View이지만 다양한 옵션이 있으며 실제 테이블을 만들어 데이터를 떨구는 것도가능 - option - view: view를 만듬, `create view as` - table: 테이블을 만듬, `create table as` - incremental: 특정 칼럼 기준 증가분을 Insert함, `INSERT INTO` - Ephemeral: 임시 테이블
6. 결론
- DBT에 대해 알아봄
- SQL쿼리로 데이터를 가공하여 테이블을 저장하고 그 관계가 복잡할 때 DBT가 airflow 같은 툴보다 좋을 수 있음

Machine Learning Engineer: recsys, mlops