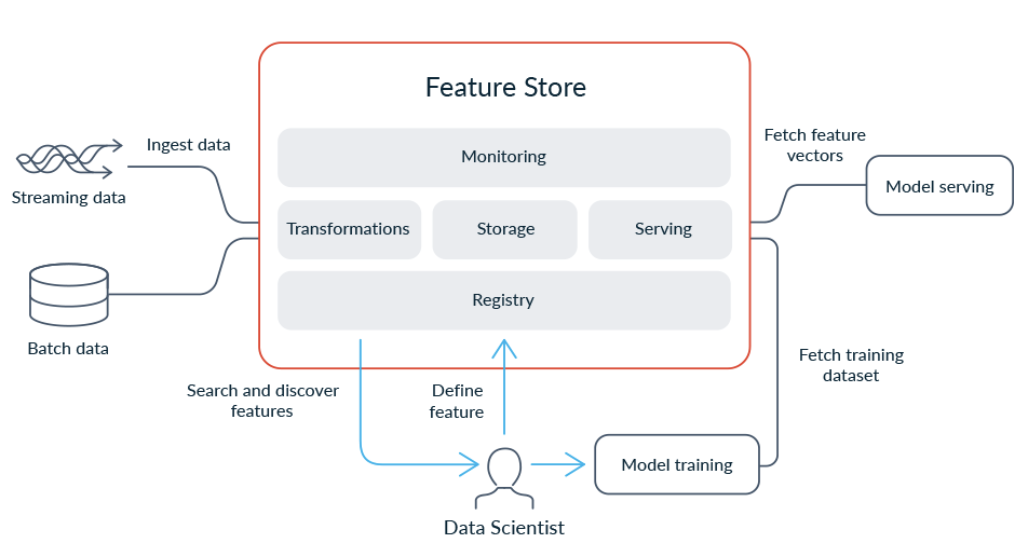
1 offline vs online
- feature store를 이해하기 위해서는 offline data, online data 개념에 대해 이해해야한다. offline, online에 대한 개념은 aws sagemaker feature store, feast, hopsworks 등 모든 feature store에 등장하는 핵심 개념이다.
2 offline data
- 머신러닝 모델을 만들때는 수십 기가 용량의 데이터를 Bigquery, redshift, spark 등을 통해서 한번에 읽어오고 한번에 가공한다. Feature를 만드는 작업도 마찬가지로 배치로 처리하기도 한다.
- Feature를 대량으로 한번에 만들어낸 다음에 이를 Raw데이터와 Join하여 모델 개발을 하게 된다.
- 모델이 실제로 Production에서 서비스를 위해 쓰이기 전 단계 즉 모델 학습, 데이터 분석 등 "대용량 배치 처리"를 위한 용도로써의 Feature 데이터 저장소를 offline이라고 부른다.
- Feature 저장시 batch 처리를 잘 하기 위해 이에 특화된 aws S3, redshift, hive 등을 사용하게 된다.
3 online data
- 배치 환경에서 만들어낸 머신러닝 모델을 Production 환경에 배포할 때는 inference 요청 한개 한개에 대해 미리 계산된 Feature들을 잘 가져와 조합한 후 모델에 요청한다.
- Production에서는 수많은 request를 처리해야하며 TPS와 latency가 매우 중요하다. inference 요청 한건 한건에 대해 offline에서 처럼 Bigquery, redshift, spark을 썼다가는 latency를 보장할 수 없고 엄청난 서버 비용이 청구될 것이다.
- Streaming환경에서 Feature를 빠른 시간안에 서빙하고 inference하기 위해서 이에 특화된 저장소인 redis, cassandra 등을 쓰게 된다.
4 offline <-> online Problem
- offline에서 계산된 feature를 online에서 쓰기 위해 (또는 반대상황에서 쓰기위해) 보통 다음일 중 하나를 선택하여 하게된다.
- offline에서 계산된 feature를 복사해서 online 스토어에 저장한다.
- offline에서 계산하는 feature 생성 로직을 똑같이 online 서빙 환경에서 구현한다. 실시간으로 inference 요청이 올때마다 feature를 빠르게 계산한다.
- online에서 계산된 feature를 큐에 쌓아두고 이를 배치로 읽어 offline 저장소에 저장한다.
- 이러한 일을 해주는 하나의 관리된 통합 툴이 없다면, online store와 offline store간의 관계 추적이 힘들 수 있고, offline에서 online으로 올려주는 반복 작업을 feature마다 구현해주게된다. 비슷한 일에 일관된 인터페이스가 없어 유지보수가 힘들다.
- 또한 feature를 계산하는 시간에 따라 feature값이 변할 수 있어, online과 offline의 feature가 서로 다르게 계산되는 실수가 발생할 여지도 크다.
5 Problem 정리
- 즉 ML production 환경 Feature는 offline, online 2가지 특성을 모두 요구한다.
- offlien일 때와 online일 때 요구하는 기능이 서로 완전히 다르기 때문에 2가지 저장소(mysql+redis, s3+redis 등)를 사용할 수 밖에 없다.
- 2가지 저장소를 사용하면서 일어나는 다양한 문제들( 두 스토어 간의 정합성, offline에서 online으로 이동, 데이터 삭제, 관리, 조회 등) 이 있을 수 밖에 있다.
- 만약 위의 문제를 겪지 않는다면, Feature store를 도입할 필요는 없다고 생각한다.

Machine Learning Engineer: recsys, mlops