
⏰ OneTime?
원타임에 대해서 궁금하다면 아래를 참고해주세요!
⏰ OneTime 서비스 바로가기
📝 OneTime 소개글
🧑🏻💻 GitHub
📸 Instagram
🎬 서론
원타임의 신기능, 에브리타임 연동 기능 구현과정을 정리했던 이전 글에 이어서
구현 과정에서 발생한 트러블 슈팅 & 성능 개선 과정에 대해서도 적어보려고 한다!
감사하게도 이전 글이 반응이 좋아 트렌딩에도 올라갔다 ㅎㅎ
이번 글도 재미있게 읽어 주셨으면 좋겠다 🙏🏻
🏋🏻 부하 테스트
부하 테스트를 '왜' 했는가
사실 부끄럽게도 이번에 처음으로 부하테스트를 하게 되었다 😂
과정에서 얻은 것이 굉장히 많았기에, 앞으로도 성장과 서비스의 안정성을 위해 테스트를 해야겠다는 생각이 들었다.
우선은 부하 테스트를 하게 된 이유는 아래와 같다.
- 초기 구현 때는 하나의 요청 당 처리 속도가 3~4초 남짓이었음 -> 굉장히 긺
- 기능 배포와 동시에 이벤트를 함께 진행하기에 트래픽이 몰릴 우려가 있음 -> 크롤링 서버가 다운된다면 치명적임
테스트 이전 트러블 슈팅 🔫
🧑🏻💻 작성에 앞서 첨언하자면, 부하 테스트를 처음 해보기 때문에 적절하게 진행한 것인지에는 아직 의문이 든다..! 또한 테스트 과정 중에서도 트러블 슈팅을 한 내역이 있기에 같이 정리하고자 한다.
⚙️ 테스트 환경
- 서버: AWS EC2 (Ubuntu) t2.micro
- Flask + Selenium 기반 크롤링 API
- 부하 테스트 도구:
wrk
1️⃣ 초기 설정 및 문제 발생
원타임의 크롤링 서버는, EC2 서버에서 Flask를 컨테이너로 실행하고, 내부에서 Selenium을 이용해 크롤링하는 구조로 구성되어 있다.
wrk 라는 툴을 사용해 부하 테스트를 수행하려 했으나, 처음 wrk -t10 -c100 -d30s을 실행했을 때부터 서버가 즉시 멈추는 문제가 발생했다.
2️⃣ 서버 접속 불가 현상
다시 ssh 접속 시도 시, Connection refused 라는 오류가 발생했다.
AWS EC2 인스턴스가 과부하로 다운되거나, OOM(Out of Memory) Kill로 인해 프로세스가 종료된 것으로 추정했고, 재부팅 후 다시 wrk 부하 테스트를 실행하면서 점진적으로 부하를 올려보기로 결정했다.
🔍 당시에는 너무 많은 요청을 동시에 보냄으로써 서버가 다운되었다고 판단했다!
3️⃣ 점진적 부하 테스트
점진적으로 부하를 올리기로 결정하고, 아래와 같이 테스트를 진행했지만 또 다시 문제가 발생했다.
wrk -t2 -c5 -d10s→ 요청이 일부 정상적으로 가지만, 로그에는 4개씩만 찍힘.wrk -t2 -c5 -d30s→ 응답 속도가 너무 느리고 크롬 프로세스가 계속 남아있는 문제 발생
4️⃣ 크롬 프로세스가 종료되지 않는 문제
🔍 처음 서버가 다운되었을 때, 크롬 드라이버와 관련한 에러 로그를 보았었다.
당시에는 대수롭지 않게 여겼지만,크롬 프로세스가 계속해서 쌓이는 것을 확인하니 해당 부분이 문제일 것이라는 판단이 들었다!
ps aux | grep chrome | wc -l 명령어로 확인해보니, 크롬 프로세스가 계속 남아 있는 것을 보았다. 많이 쌓이게 되면 약 1,000개 가량이 쌓였다.
그렇기에 Selenium에서 크롤링 종료 시 driver.quit()을 수행하도록 변경하였지만 -> 여전히 문제가 해결되지 않았다.
5️⃣ 해결 시도 및 코드 수정
finally블록을 활용해driver.quit()이 반드시 실행되도록 수정psutil을 활용해 크롬 프로세스를 강제 종료하는 코드 추가
🔍 위와 같은 방법들을 시도하면서,
어떻게 하면 사용한 크롬 프로세스를 제거할 수 있을까?에 대한 고민이 이어졌다.
그렇게 여러 블로그도 뒤져 보고 지피티에게도 물어보며 사투를 한 결과,아래의 답을 찾을 수 있었다.
6️⃣ Docker 컨테이너 실행 시 --init 옵션 추가 ✅
답은 바로 도커 컨테이너 실행 시 --init 옵션을 추가하는 것이었다.
sudo docker run -d --init --name {컨테이너 명} -p {port}:{port} {이미지명:버전}위처럼 컨테이너를 만들 때 해당 옵션을 붙여주면, 자동으로 좀비 프로세스를 제거해준다고 한다!
그렇게 만들고 나니..
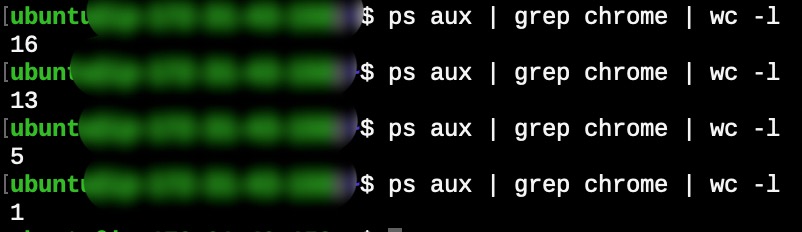
이렇게 쓰임이 다 한 프로세스들이 알아서 제거되어 관리되는 모습을 볼 수 있었다!
💡 도커를 쓰면서
--init옵션을 써 본 것은 처음이었는데 알게 되어 좋았다 😄
드디어 이제 다시 부하테스트를 할 수 있는 환경이 되었다.
부하 테스트 진행
📌 테스트 진행 내역 및 결과 분석
| 테스트 조건 | 요청 수 (wrk) | 평균 응답 시간 | 초당 처리량 (Req/Sec) | CPU 사용률 | 메모리 사용량 |
|---|---|---|---|---|---|
| 10명 동시 요청 (-c10) | 30초 | 9.57초 | 1.00 | 10% | 520MB |
| 20명 동시 요청 (-c20) | 30초 | 23.73초 | 0.66 | 10% | 510MB |
| 30명 동시 요청 (-c30) | 30초 | 28.99초 | 1.00 | 0% | 510MB |
| 50명 동시 요청 (-c50) | 30초 | 요청 실패 | 0.00 | 0% | 510MB |
| 50명 동시 요청 (-c50) + 60초 테스트 | 60초 | 49.35초 | 0.83 | 0% | 510MB |
| 100명 동시 요청 (-c100) + 120초 테스트 | 120초 | 1.69분 | 0.84 | 0% | 510MB |
여기서 알게 된 문제점은 아래 2가지였다.
🚨 성능 문제
1. 글 초반부에 말한 것처럼 시간표 추출을 할 때마다 약 4초 정도가 소요되었다. 유저 입장에서 4초나 기다리게 되는 것은 사용성을 해칠 수 있다.
2. 평균 응답 시간을 보면, 요청 수에 따라 계속해서 증가한다. 이는 비동기 처리가 되어 있지 않기 때문이다.
결론부터 말하면 2번 비동기 처리까지는 구현하지 못 했다..! Flask가 아닌 Fast API가 비동기 처리에 특화되어 있다고는 하는데 도입을 하던 중 시간이 너무 부족해 제대로 구현하지 못 했다.
이 부분은 다음에 다시 도전해보아야 할 듯하다 😂
그래도 1번은 꽤나 해결이 되었는데, 이는 아래 내용에서 이어진다.
🚀 성능 개선
문제 및 원인 파악
부하 테스트 결과를 분석해 보면, 서버의 CPU 사용률은 상대적으로 낮았지만 요청이 몰릴 때 응답 시간이 급격히 증가하는 문제가 발생했다.
이러한 현상의 주요 원인은 Selenium WebDriver의 실행 비용이 크기 때문이라고 판단했다.
즉, 기존에는 크롤링을 수행할 때마다 새로운 WebDriver 인스턴스를 생성하고 종료하는데, 이 과정에서 불필요한 리소스 소모가 발생한다고 보았다.
해결 방안 ✅
해결 방안은 생각보다 간단했다. WebDriver 인스턴스를 재사용(WebDriver 풀링)하는 방식으로 변경하여 해결할 수 있었다!
기존
기존 코드
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
import math
from collections import defaultdict
def crawl_schedule(url):
# ✅ Chrome WebDriver 옵션 설정
chrome_options = Options()
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--window-size=1920x1080")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--headless") # 백그라운드 실행
chrome_options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
# ✅ WebDriver 실행
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
# ✅ 페이지가 완전히 로드될 때까지 대기
try:
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, "tablebody")))
except:
driver.quit()
return {"code": "400", "message": "페이지를 불러올 수 없습니다.", "is_success": False}
# ✅ `tablehead` 찾기 (요일 추출)
try:
tablehead = driver.find_element(By.CLASS_NAME, "tablehead")
days = [td.text.strip() for td in tablehead.find_elements(By.TAG_NAME, "td") if td.text.strip()]
except:
driver.quit()
return {"code": "400", "message": "요일 정보를 찾을 수 없습니다.", "is_success": False}
# ✅ `tablebody` 찾기 (시간표 블록들 가져오기)
try:
tablebody = driver.find_element(By.CLASS_NAME, "tablebody")
subjects = tablebody.find_elements(By.CLASS_NAME, "subject")
except:
driver.quit()
return {"code": "400", "message": "시간표 데이터를 찾을 수 없습니다.", "is_success": False}
# ✅ 요일별 스케줄 저장용
schedules = defaultdict(list)
# ✅ 블록 정보 분석
for subject in subjects:
style = subject.get_attribute("style")
# ⏳ height, top 값 추출
height_match = re.search(r'height:\s*(\d+)px', style)
top_match = re.search(r'top:\s*(\d+)px', style)
if not height_match or not top_match:
continue
height = int(height_match.group(1))
top = int(top_match.group(1))
# **시작 시간 계산**
start_total_minutes = ((top - 450) // 25) * 30
start_hour = 9 + (start_total_minutes // 60)
start_minute = start_total_minutes % 60
# **종료 시간 계산**
duration_total_minutes = math.ceil((height - 1) / 25) * 30
end_total_minutes = start_total_minutes + duration_total_minutes
end_hour = 9 + (end_total_minutes // 60)
end_minute = end_total_minutes % 60
# ⏳ 변환 완료
start_time = f"{int(start_hour):02}:{int(start_minute):02}"
end_time = f"{int(end_hour):02}:{int(end_minute):02}"
# 📌 **요일 찾기**
parent_td = subject.find_element(By.XPATH, "./ancestor::td")
td_index = list(parent_td.find_element(By.XPATH, "./ancestor::tr").find_elements(By.TAG_NAME, "td")).index(parent_td)
day = days[td_index] if td_index < len(days) else "알 수 없음"
schedules[day].append((start_time, end_time))
driver.quit()
# ✅ **시간 정제: 연속된 시간 합치기 & 30분 단위 변환**
final_schedules = []
for day, times in schedules.items():
times.sort()
merged_times = set()
for start, end in times:
start_h, start_m = map(int, start.split(":"))
end_h, end_m = map(int, end.split(":"))
current_h, current_m = start_h, start_m
while (current_h, current_m) < (end_h, end_m):
merged_times.add(f"{current_h:02}:{current_m:02}")
current_m += 30
if current_m >= 60:
current_h += 1
current_m = 0
sorted_times = sorted(merged_times)
final_schedules.append({
"time_point": day,
"times": sorted_times
})
return {
"code": "200",
"message": "유저 고정 스케줄 조회에 성공했습니다.",
"payload": {
"schedules": final_schedules
},
"is_success": True
}
👎🏻 기존 방식
- 요청이 들어올 때마다 webdriver.Chrome()을 새로 생성
- 요청이 끝나면 WebDriver를 종료
- 동시 요청이 많아질 경우 크롬 프로세스가 계속 생성되고 종료되면서 오버헤드가 발생
- 결과적으로 응답 시간이 불필요하게 길어짐
변경
변경 코드
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
import math
import os
import psutil
from collections import defaultdict
from threading import Lock
# ✅ WebDriver 전역 인스턴스 & 락 설정 (멀티쓰레드 대응)
driver = None
driver_lock = Lock()
def get_webdriver():
"""이미 실행된 WebDriver를 반환하거나, 없으면 새로 생성"""
global driver
with driver_lock:
if driver is None:
chrome_options = Options()
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--window-size=1920x1080")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--headless")
chrome_options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
service = Service("/usr/bin/chromedriver")
driver = webdriver.Chrome(service=service, options=chrome_options)
return driver
def crawl_schedule(url):
# ✅ 기존 실행 중인 WebDriver를 재사용
driver = get_webdriver()
try:
# ✅ 요청한 URL로 이동
driver.get(url)
# ✅ 공개되지 않은 시간표 감지 (존재하면 즉시 404 반환)
try:
WebDriverWait(driver, 3).until(EC.presence_of_element_located((By.CLASS_NAME, "empty")))
return {
"code": "400",
"message": "공개되지 않은 시간표입니다.",
"is_success": False
}
except Exception:
pass # 계속 진행
# ✅ 특정 요소가 로드되면 바로 크롤링 진행
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, "tablebody")))
# ✅ `tablehead` 찾기 (요일 정보 가져오기)
tablehead = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, "tablehead")))
days = [td.text.strip() for td in tablehead.find_elements(By.TAG_NAME, "td") if td.text.strip()]
# ✅ `tablebody` 찾기 (시간표 블록들 가져오기)
tablebody = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, "tablebody")))
subjects = tablebody.find_elements(By.CLASS_NAME, "subject")
# ✅ 요일별 스케줄 저장 (딕셔너리 형태로 저장)
schedules = defaultdict(list)
# ✅ 블록 정보 분석 (스타일 속성에서 시간 정보 추출)
for subject in subjects:
style = subject.get_attribute("style")
# ⏳ height, top 값 추출 (위치 기반으로 시작/종료 시간 계산)
height_match = re.search(r'height:\s*(\d+)px', style)
top_match = re.search(r'top:\s*(\d+)px', style)
if not height_match or not top_match:
continue
height = int(height_match.group(1)) # 블록 높이 (수업 길이)
top = int(top_match.group(1)) # 블록 위치 (시작 시간)
# ✅ 시작 시간 계산 (픽셀 → 분 단위 변환)
start_total_minutes = ((top - 450) // 25) * 30
start_hour = 9 + (start_total_minutes // 60)
start_minute = start_total_minutes % 60
# ✅ 종료 시간 계산 (수업 길이를 반영)
duration_total_minutes = math.ceil((height - 1) / 25) * 30
end_total_minutes = start_total_minutes + duration_total_minutes
end_hour = 9 + (end_total_minutes // 60<)
end_minute = end_total_minutes % 60
# ⏳ 최종 변환된 시작/종료 시간
start_time = f"{int(start_hour):02}:{int(start_minute):02}"
end_time = f"{int(end_hour):02}:{int(end_minute):02}"
# 📌 요일 찾기 (해당 블록이 위치한 요일 추출)
parent_td = subject.find_element(By.XPATH, "./ancestor::td")
td_index = list(parent_td.find_element(By.XPATH, "./ancestor::tr").find_elements(By.TAG_NAME, "td")).index(parent_td)
day = days[td_index] if td_index < len(days) else "알 수 없음"
# ✅ 요일별 시간 추가
schedules[day].append((start_time, end_time))
# ✅ 시간 정제: 연속된 시간 합치기 & 30분 단위 변환
final_schedules = []
for day, times in schedules.items():
times.sort()
merged_times = set()
for start, end in times:
start_h, start_m = map(int, start.split(":"))
end_h, end_m = map(int, end.split(":"))
current_h, current_m = start_h, start_m
while (current_h, current_m) < (end_h, end_m):
merged_times.add(f"{current_h:02}:{current_m:02}")
current_m += 30
if current_m >= 60:
current_h += 1
current_m = 0
sorted_times = sorted(merged_times)
final_schedules.append({
"time_point": day,
"times": sorted_times
})
# ✅ 최종 JSON 반환
return {
"code": "200",
"message": "유저 고정 스케줄 조회에 성공했습니다.",
"payload": {
"schedules": final_schedules
},
"is_success": True
}
except Exception as e:
return {"code": "500", "message": f"서버 오류: {str(e)}", "is_success": False}
👍🏻 개선 방식
- WebDriver 인스턴스를 미리 하나 생성한 후, 모든 요청이 이 인스턴스를 공유하도록 변경
- 다중 스레드 환경에서도 동기화를 보장하기 위해 Lock을 적용
- WebDriver를 지속적으로 유지하면서 불필요한 생성/종료 비용을 절감
🌈 기대 효과
- 처리 속도 개선
- 서버 안정성 증가
- 크롬 프로세스의 불필요한 생성·종료가 줄어들어 리소스 사용량 최적화
- 확장성 향상
- 동시 요청이 많아져도 WebDriver 인스턴스를 재사용하므로 안정적으로 처리 가능
결과
결론적으로 약 3~4초가 걸리던 크롤링이 1초 내외로 단축되었다!
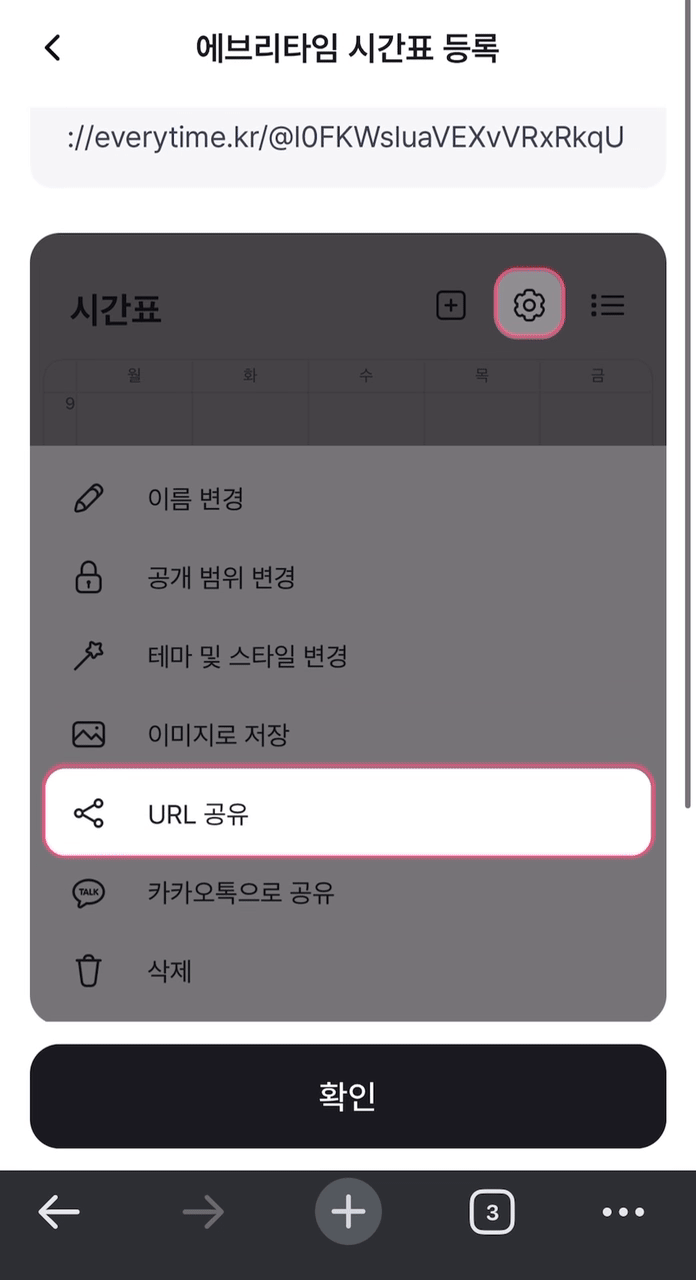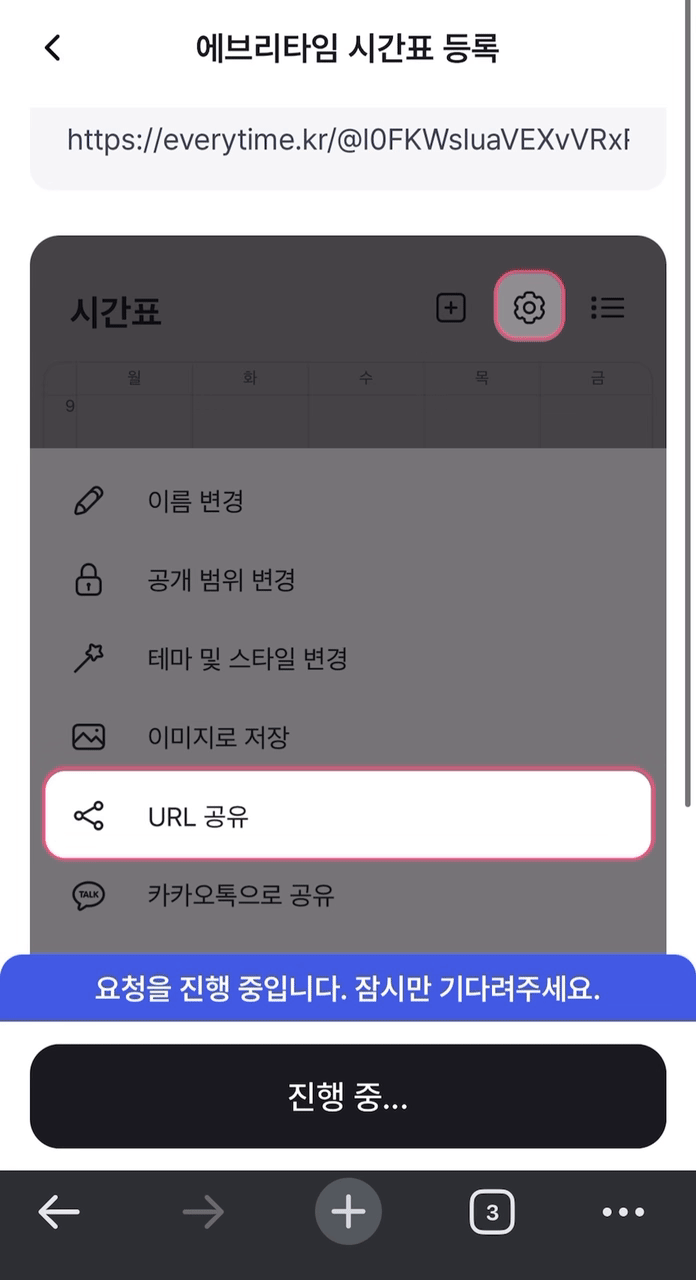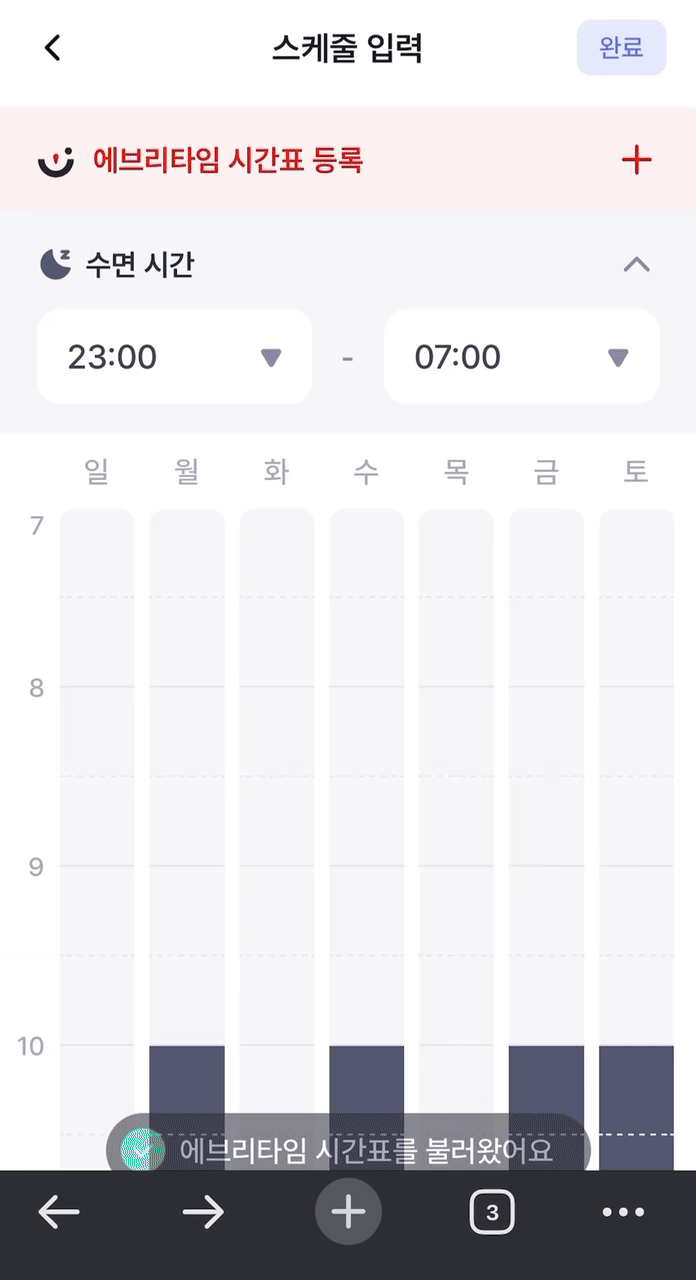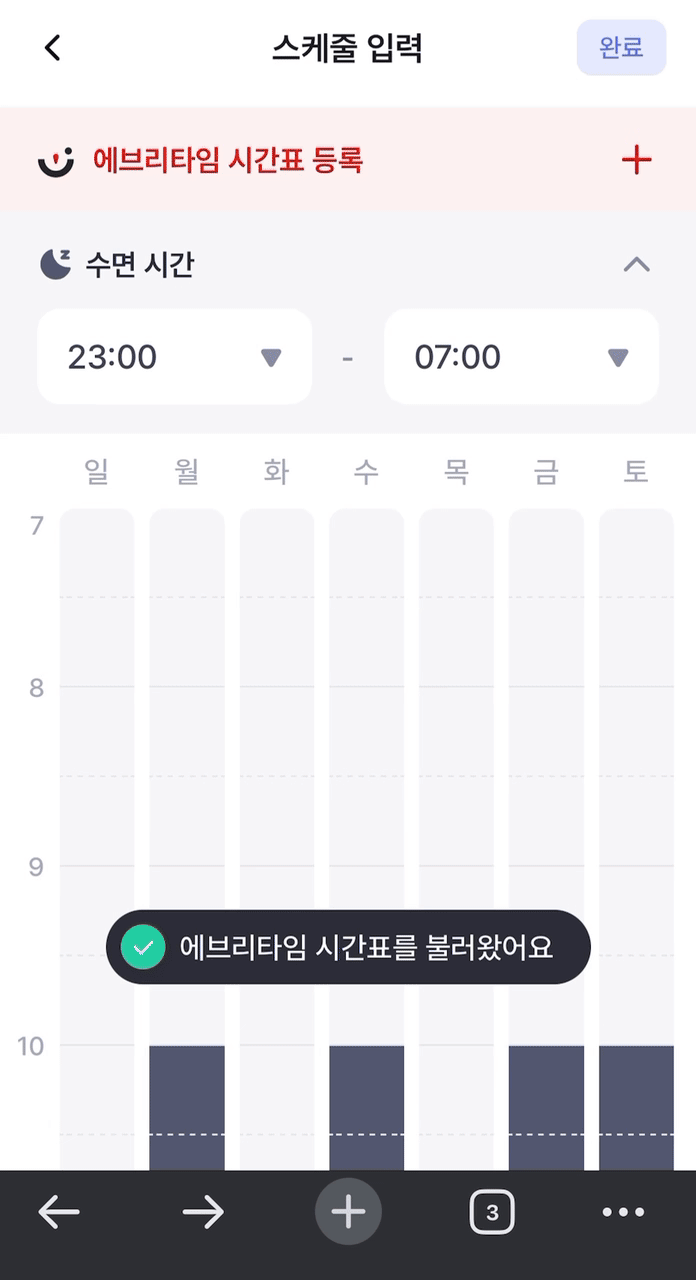 개선 이전 개선 이전 |  개선 이후 개선 이후 |
|---|
위 두 가지를 비교해서 보아도 확실히 개선 후에 속도가 빨라진 것을 볼 수 있다!
🏁 마무리
이렇게 원타임 신기능의 부하테스트와 성능 개선 내용을 정리해보았다.
실제로 유저가 사용하는 기능을 조금 더 사용성 좋게 만들었다는 데에 큰 의의를 두고, 앞으로 이러한 부분들을 더 신경쓰는 개발자가 될 수 있도록 노력해야겠다!
👋🏻 모두들 OneTime 많이 사용해주세요!


와 멋있다 나도 이런 글 써보고 싶다