모니터링
HPA를 위해서는 metrics-server를 이용하면 되고, 일반적인 모니터링을 위해서는 Prometheus Operator를 이용하면 된다. metrics-server에는 데이터베이스가 없다. metrics-server는 데이터를 저장하지 않고 실시간으로만 측정이 가능하다. 우리가 확인할 수 있는 모든 데이터는 실시간 데이터로, HPA를 위해서만 존재한다고 볼 수 있다.
하지만 로그의 기록과 저장은 매우 중요한 일이다. 이럴 때 사용하는 것이 프로메테우스이다. 프로메테우스는 쿠버네티스 모니터링의 거의 표준처럼 사용된다. 혹은 AWS의 CloudWatch 같은 서비스를 이용할 수도 있다.
- 힙스터(heapster)
github
만료된 서비스이다. 힙스터는 쿠버네티스의 모니터링 도구이다. 다른 대체제가 있기도 하고, 쿠버네티스 내에서 모니터링까지 신경쓸 수 없었기 때문에 만료되었다. influxDB라는 TSDB(Time Series Database)를 사용한다. 모니터링 도구는 일반적인 RDBMS에 저장하면 효율성이 떨어진다. 결국 모니터링은 시간에 따라 변하기 때문이다. 이런 시간에 따른 데이터를 저장하는데 특화되어 있는 데이터베이스인 TSDB를 사용한다.
프로메테우스
프로메테우스는 쿠버네티스에서 거의 표준처럼 사용되는 오픈소스 모니터링 도구이다. 프로메테우스는 원래 쿠버네티스만을 모니터링하는 도구가 아니라, 일반적인 리눅스 시스템이나 하드웨어 장치, 어플리케이션 등 여러가지 다양한 종류의 모니터링이 가능하다.
프로메테우스는 확장을 고려하지 않고 만들었기 때문에, 로그의 장기간 보관이 힘들다. 이런 문제점을 해결하기 위해 프로메테우스의 장기간 보관용 스토리지 프로젝트인 Cortex와 Thanos가 만들어졌다.
프로메테우스 구성요소
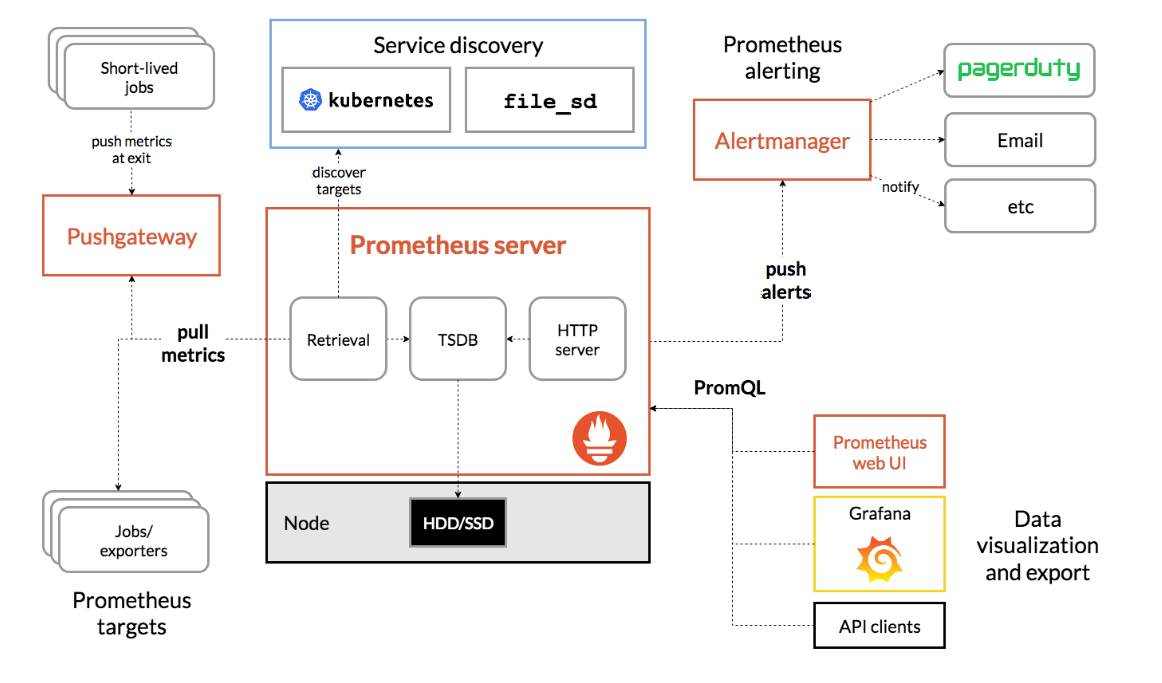
붉은 부분이 프로메테우스의 구성 요소이다. 모두 파드로 띄워져 있다.
-
Prometheus Server
가장 중요한 곳으로, 모니터링하는 곳이다.- Retrieval
exporter, 즉 모니터링 타겟을 대상으로 데이터를 가져온다. - TSDB
Time Series Database이다. - HTTP Server
자체적인 HTTP 서버이다. 기본적으로 여러 그래프를 확인할 수 있다.
- Retrieval
-
Short-lived jobs
생명주기가 매우 짧은 잡이다. 이들은 메트릭을 수집하기 전에 이미 실행되고 종료되어 버리는 경우가 있기 때문에 Pushgateway에 메트릭을 쌓아두고 한 번에 가져온다. -
서비스 디스커버리
프로메테우스가 측정할 목록이다. 쿠버네티스 API 서버로부터 측정해야 할 목록을 가져온다. -
Prometheus web UI
프로메테우스의 자체적인 http 서버를 보여주는 웹 서버이다. 모니터링 용도가 아닌 프로메테우스 서버를 테스트하고 확인하고 개발하기 위한 용도로 쓰인다. -
PromQL
SQL과 같이 프로메테우스 서버에 저장된 데이터를 쿼리하기 위해 만들어진 데이터이다. -
Grafana
보통 프로메테우스와 함께 설치하는 다른 오픈소스이다. PromQL을 사용해 프로메테우스의 데이터를 가져와 시각화해준다. -
Alertmanager
알림을 보내는 용도로 쓰인다.
프로메테우스 설치
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
kubectl create ns monitor #인프라를 위한 인프라이므로 다른 네임스페이스에 설치하는 것이 좋다.차트 저장소의 charts 에서 추가한 charts의 목록을 볼 수 있다. 이들을 개별로 설치하는 것이 아니라 kube-prometheus-stack을 통해 한 번에 설치할 수 있다. kube-prometheus-stack는 패키지가 패키징되어 있는 것이라고 할 수 있다.
values.yaml을 확인해 보면 grafana를 확인할 수 있다. grafana를 모니터링 하기 위해 기본 ClusterIP 타입인 grafana의 서비스 타입을 바꿔야 한다.
grafana:
service:
type: LoadBalancerhelm install prometheus prometheus-community/kube-prometheus-stack -n monitor -f prometheus-grafana.yaml
kubectl get all -n monitor
kubectl get svc -n monitor각 노드에 node-exporter가 데몬셋으로 배치되어 있는 것을 확인할 수 있다. 여기서 노드의 모든 메트릭을 측정해서 가져온다. grafana 역시 원래는 관리 목적이므로 외부에 노출시키면 안 된다.
로드밸런서의 IP인 192.168.56.201으로 접속할 수 있다. 그라파나의 기본 계정은 admin / prom-operator 이다. ID와 비밀번호로 로그인하면 모니터링할 수 있다.
좌측의 Dashboard에 있는 Browse에 들어가면 대시보드 목록을 확인할 수 있다.
General은 분류일 뿐이고, 실제 대시보드는 Kubernetes/Compute Resources/Cluster 등이다.
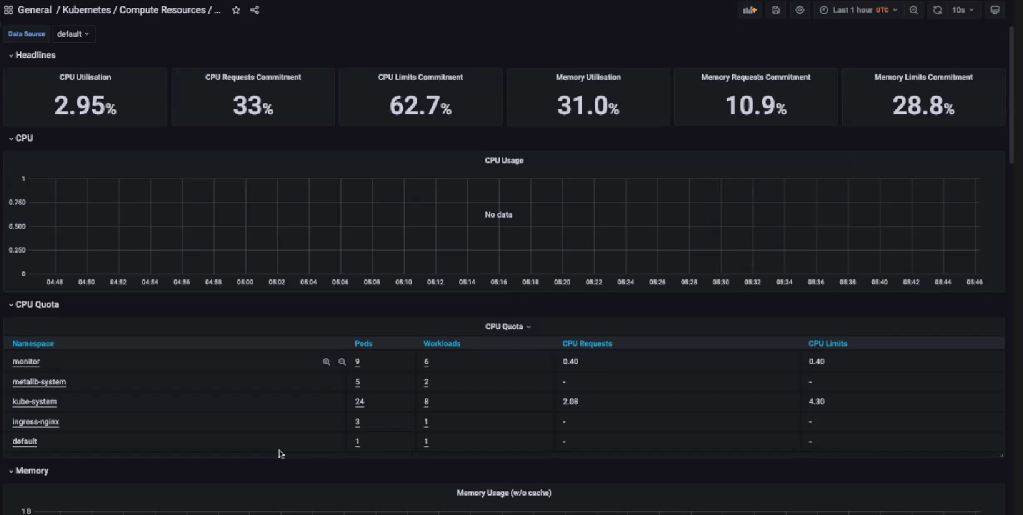
대시보드에선 시각화된 모니터링 정보를 확인할 수 있다. 다른 곳에서는 다른 정보를 확인 가능하다. kube-prometheus-stack을 사용하여 설치했으므로 Kubernetes에 관한 대시보드를 쉽게 확인할 수 있다.
로깅
쿠버네티스에는 기본적으로 kubectl logs 명령어로 log를 확인할 수 있다. 로그는 노드마다 /var/log/pods와 /var/log/containers에 남는다. 하지만 파드가 삭제되면 로그도 삭제된다. 따라서 로그를 따로 저장할 필요가 있다. 이런 로그 파일들을 통합해서 관리해야 한다.
로그 통합 저장 관리를 위해 사용하는 기법이 여러가지가 있다. 이 중 대표적인 것들이 ELK, EFK, Elastic Stack이다. 로그 수집기가 각각 노드에 있는 로그를 가져와 저장소에 저장시킨다. 이 저장된 로그를 ElasticSearch로 검색한다. 쿼리문을 통해 프로메테우스로 정보를 가져와 검색하고 이 로그들을 Kibana로 시각화 한다.
-
ELK
ElasticSearch + Logstash + Kibana. ElasticSearch는 검색엔진이다. 로그를 검색할 수 있도록 한다. Logstash는 로그 수집기이다. Kibana는 데이터를 시각화해 준다. 세 가지 모두 Elastic이라는 회사가 만들었다. Logstash가 무겁다. -
EFK
ElasticSearch + Fluentd + Kibana. 가장 선호되는 조합이다. Fluentd가 로그 수집기이다. 무거운 Logstash를 대신해 사용한다. Fluentd는 CNCF 프로젝트이다. 이 Fluentd를 경량화한것이 FluentBit이다. Fluentd의 가공과 필터 기능을 거의 제거한 것이다. -
Elastic Stack
ElasticSearch + Beats + Kibana. Beats가 로그 수집기이다. Beats는 Elastic에서 만든 Logstash의 경량화 버전이다.
EFK는 통합되어 있는 스택은 없고 따로 설치해 줘야 한다. logging이라는 namespace를 만들어 설치를 진행하였다.
ElasticSearch 설치
helm repo add elastic https://helm.elastic.co
helm repo updateElasticSearch는 8버전과 7버전이 유지되고 있는데, 8버전은 상용 버전이라 작동 방식이 완전히 달라져 설치하면 작동하지 않는다. 따라서 7버전을 설치해야 한다.
helm show values --version 7.17.3 elastic/elasticsearch > elasticsearch-value.yaml옛날 버전을 설치하기 위해 버전을 지정해 주었다. 또한 ElasticSearch는 용량을 많이 잡아먹기 때문에 리소스를 가볍게 커스터마이징한다.
replicas: 1
minimumMasterNodes: 1
...
resources:
requests:
cpu: "1000m"
memory: "1Gi"
limits:
cpu: "1000m"
memory: "1Gi"helm install elasticsearch elastic/elasticsearch --version 7.17.3 -f elasticsearch-value.yaml -n loggingFluentBit 설치
FluentBit는 기본적으로 데몬셋으로 작동한다.
helm repo add fluent https://fluent.github.io/helm-charts
helm repo update
helm install fluent-bit fluent/fluent-bit -n loggingKibana 설치
Kibana 역시 7 버전으로 커스텀하여 설치해 줘야 한다. 또한 대시보드의 역할을 하기 때문에 ClusterIP를 LoadBalancer로 바꿔 설치해야 한다.
helm show values --version 7.17.3 elastic/kibana > kibana-value.yaml:set nu
49 resources:
50 requests:
51 cpu: "1000m"
52 memory: "1Gi"
53 limits:
54 cpu: "1000m"
55 memory: "1Gi"
...
119 service:
120 type: LoadBalancerhelm install kibana elastic/kibana --version 7.17.3 -f kibana-value.yaml -n logging설치 확인 및 접속
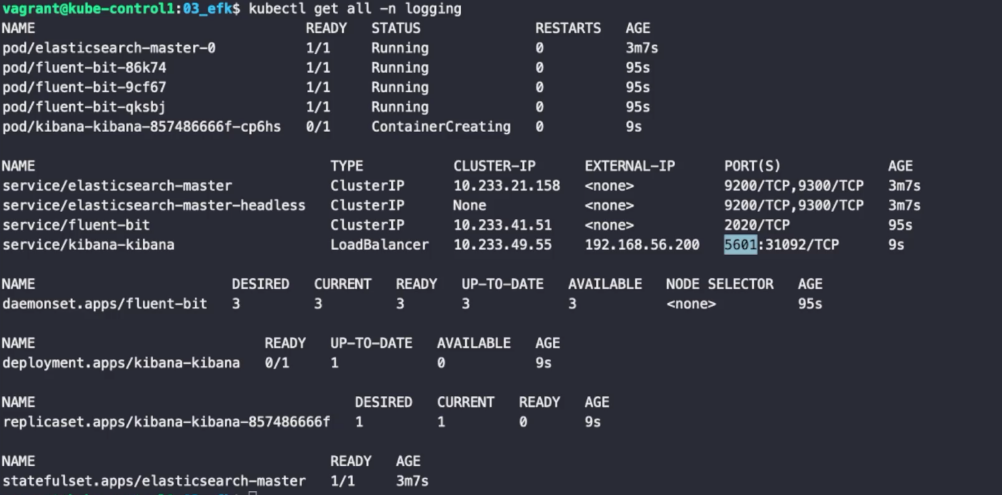
모두 설치가 잘 된 것을 확인할 수 있다. http://192.168.56.200:5601으로 접속하면, 다음과 같은 화면을 확인할 수 있다.
로깅 확인 방법
-
Welcome 페이지: Explorer on my own 버튼
-
좌측 상단 햄버거 매뉴: Management -> Stack Management 선택
-
Kibana -> Index Patterns 선택
-
Create Index pattern 선택
-
Name: logstash-* 입력
-
Temestamp filed: @timestamp 선택
-
Create index pattern 버튼
-
좌측 햄버거 메뉴 -> Analytics -> Discover
-
로그 검색