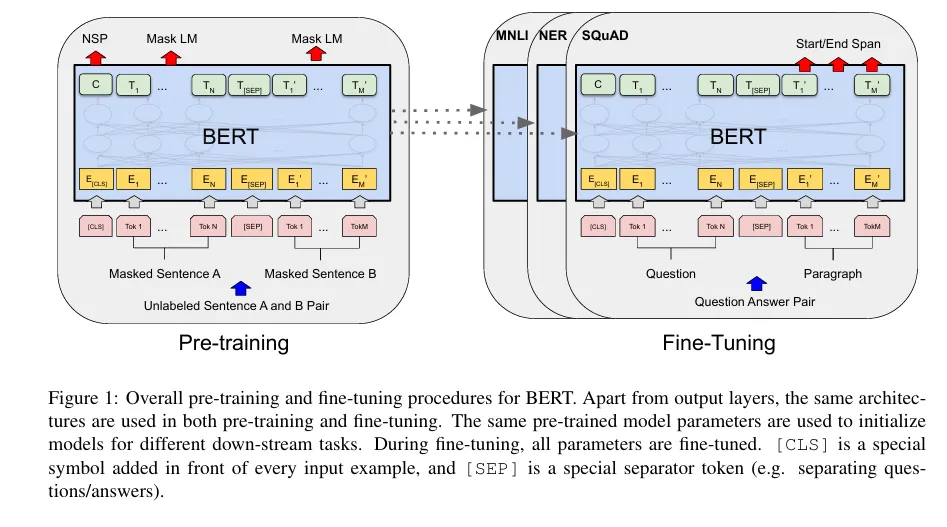
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
국민대학교 인공지능학회 (XAI)

BERT(Bidirectional Encoder Representations from Transformers)는 2018년에 구글이 공개한 사전 훈련된 모델입니다. BERT라는 이름은 세서미 스트리트라는 미국 인형극의 케릭터 이름이기도 한데, 앞서 소개한 임베딩 방법론인 ELMo와 마찬가지로 세서미 스트리트의 케릭터 이름을 따온 것이기도 합니다.
ABSTRACT
기존의 언어 모델들과 달리 BERT는 레이블이 없는 텍스트로부터 Deep bidirectional representations을 pre-train하도록 설계되었습니다.
즉 문장의 왼쪽과 오른쪽 문맥을 동시에 고려해서 학습합니다.
그래서 이렇게 사전학습된 BERT는 추가적인 출력 레이어 하나만 붙이면 질문응답, 문장 추론과 같은 다양한 task에서 성능을 낼 수 있습니다. (작업에 따라 아키텍처를 바꿔야할 때 크게 바꿀 필요도 없다.)
1. Introduction
들어가기 전에 feature-based 와 fine-tuning 의 차이점부터 살펴보자
feature-based = 기존 모델은 고정하고 위에 새 모델을 쌓음
fine-tuning = 기존 모델 전체를 조금씩 수정
모델을 요리사로 비유를 하자면 BERT 같은 사전학습 모델은 이미 요리법(지식)을 배워둔 요리사이다.
1️⃣ Feature-based = 요리사의 실력은 그대로, 위의 스킬만 추가
- 기존 BERT 요리사의 요리법은 건들지 않는다.
- 그냥 BERT가 뽑아준 결과(벡터)를 받아서 그걸 이용해 새로운 요리를 만든다.
문장을 BERT에 넣어서 CLS 토큰 벡터만 뽑고 그 벡터를 입력받아 새로운 작은 모델을 따로 학습시킴 이때 BERT 내부 파라미터는 freeze 되어 있다.
2️⃣ Fine-tuning = 요리사 전체를 조금씩 수정
- 기존 BERT 요리사가 갖고 있는 모든 기술(embedding, attention, layer 등)을 조금씩 업데이트한다.
- 그래서 BERT 내부의 모든 파라미터가 학습 대상이다.
- 대신 조금씩만 바꿔야한다. BERT는 이미 완벽(똑똑)하니까
감정 분석 task에서 전체 BERT 모델을 불러온 뒤 전체 파라미터를 학습 가능하게 하고, 그 위에 분류기 하나 얹어서 다 같이 학습시킨다.
| 항목 | Fine-tuning | Feature-based |
|---|---|---|
| BERT 파라미터 | 학습함 (조금씩 업데이트) | 고정함 (학습 안 함) |
| 학습 범위 | 전체 모델 | 새로 쌓은 레이어만 |
| 장점 | 최적 성능 가능 | 빠르고 계산 효율적 |
| 단점 | 메모리/시간 부담 | 성능이 약간 떨어질 수도 |
pre-training의 효과
최근 연구들은 언어 모델을 pre-training 하는 것이 다양한 nlp 작업 성능 향상에 효과적이라는 것을 보여준다.
기존 방식은 단방향 한계가 존재
- 기존 모델들은 unidirectioanl 언어 모델이다. GPT는 왼쪽 → 오른쪽 방향으로만 문맥을보는데 이건 문장 전체를 이해하는 작업(질문 응답) 같은 곳에서는 문맥 정보가 부족하다.
해결책 제안: BERT = 양방향 + 마스크 언어모델
그래서 BERT는 문제를 해결하기 위해
- Masked Language Model(MLM)이라는 사전학습 목표를 사용한다. 문장 중 일부 단어를 [MASK]로 가리고 양쪽 문맥을 모두 활용해서 복원한다. 이 방식 덕에 Bidirectional 학습이 가능해졌다.
- 문장 관계를 학습하기 위한 Next Sentence Prediction(NSP) task도 함께 사용한다.
2. Related Works
1. Unsupervised Feature-based Approaches
- 전통적인 단어 임베딩(Word2vec, Glove)
- 문맥을 적혀 고려하지 않은 정적 벡터를 사용
- ELMO
- 좌→우 + 우→좌 두 개의 LSTM을 따로 학습한 후, 출력 벡터를 단순 연결(concatenate)한다. 문맥은 반영하지만 깊은 양방향 표현은 아니다.
- Feature-based 방식 : 임베딩만 고정해서 다른 모델에 추가적으로 사용
2. Unsupervised Fine-tuning Approaches
- GPT-1
- 왼→오 Transformer 기반 언어 모델
- 사전 학습 후 전체 파라미터를 fine-tuning
- 다양한 task에서 높은 성능을 보이지만 단방향이라는 단점이 있다.
3. Supervised Transfer Learning
- SNLI, NLI 같은 대규모 라벨 데이터 기반 전이 학습
- 지도 데이터 기반 전이학습도 가능하지만 라벨 비용이 크다.
Related work에서 말하고 싶은것은 “기존 모델들은 단방향이거나 얕은 양방향인데 BERT는 깊은 양방향 표현을 MaskedLM, NSP)해서 성능이 더 좋다”를 말하고 싶은 것 같았다.
3. BERT
3.1 BERT의 전체 학습 프로세스
위에서 언급한 것처럼 BERT는 2단계로 학습된다.
- pre-training
- 라벨이 없는 텍스트를 기반으로 BERT를 먼저 학습함
- 사전 학습때 사용되는 두 가지 사전학습 태스크
- Masked Language Model(MLM)
- Next Sentence Prediction (NSP)
- fine-tuning
- 사전학습된 BERT를 다양한 다운스트림 태스크에 맞게 조금만 추가학습 (마지막 layer층에 붙여서 태스크에 맞게 조정 하는듯)
- 이때는 전 파라미터를 업데이트한다.
3.1.1 TASK #1 : Masked LM
BERT는 사전 훈련을 위해서 인공 신경망의 입력으로 들어가는 입력 텍스트의 15%의 단어를 랜덤으로 Masking합니다. 그리고 인공 신경망에게 이 가려진 단어들을 (Masked words) 예측하도록 합니다. 중간에 단어들에 구멍을 뚫어 놓고 구멍에 들어갈 단어들을 예측하게 하는 식입니다.
더 정확히는 전부 [MASK]로 변경하지는 않고, 랜덤으로 선택된 15%의 단어들은 다시 다음과 같은 비율로 규칙이 적용됩니다.
- 80%의 단어들은 [MASK]로 변경한다. Ex) The man went to the store → The man went to the [MASK]
- 10%의 단어들은 랜덤으로 단어가 변경된다. Ex) The man went to the store → The man went to the dog
- 10%의 단어들은 동일하게 둔다. Ex) The man went to the store → The man went to the store
이렇게 하는 이유는 [MASK]만 사용할 경우에는 [MASK] 토큰이 파인 튜닝 단계에서는 나타나지 않으므로 사전 학습 단계와 파인 튜닝 단계에서의 불일치가 발생하는 문제가 있습니다. 이 문제를 완화하기 위해서 랜덤으로 선택된 15%의 단어들의 모든 토큰을 [MASK]로 사용하지 않습니다.
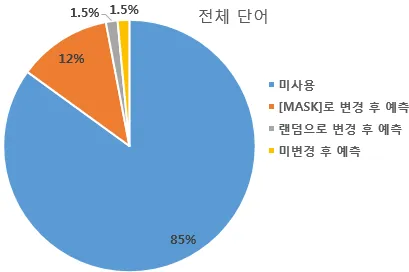
전체 단어의 85%는 마스크드 언어 모델의 학습에 사용되지 않습니다. 마스크드 언어 모델의 학습에 사용되는 단어는 전체 단어의 15%입니다. 학습에 사용되는 12%는 [MASK]로 변경 후에 원래 단어를 예측합니다. 1.5%는 랜덤으로 단어가 변경된 후에 원래 단어를 예측합니다. 1.5%는 단어가 변경되지는 않았지만, BERT는 이 단어가 변경된 단어인지 원래 단어가 맞는지는 알 수 없습니다. 이 경우에도 BERT는 원래 단어가 무엇인지를 예측하도록 합니다.
예시를 통해 이해해봅시다. 'My dog is cute. he likes playing'이라는 문장에 대해서 마스크드 언어 모델을 학습하고자 합니다. 약간의 전처리와 BERT의 서브워드 토크나이저에 의해 이 문장은 ['my', 'dog', 'is' 'cute', 'he', 'likes', 'play', '##ing']로 토큰화가 되어 BERT의 입력으로 사용됩니다. 그리고 언어 모델 학습을 위해서 다음과 같이 데이터가 변경되었다고 가정해봅시다.
- 'dog' 토큰은 [MASK]로 변경되었습니다.
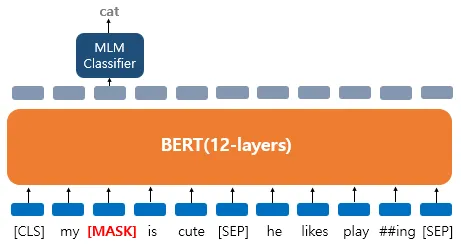
위 그림은 'dog' 토큰이 [MASK]로 변경되어서 BERT 모델이 원래 단어를 맞추려고 하는 모습을 보여줍니다. 여기서 출력층에 있는 다른 위치의 벡터들은 예측과 학습에 사용되지 않고, 오직 'dog' 위치의 출력층의 벡터만이 사용됩니다. 구체적으로는 BERT의 손실 함수에서 다른 위치에서의 예측은 무시합니다. 출력층에서는 예측을 위해 단어 집합의 크기만큼의 밀집층(Dense layer)에 소프트맥스 함수가 사용된 1개의 층을 사용하여 원래 단어가 무엇인지를 맞추게 됩니다. 그런데 만약 'dog'만 변경된 것이 아니라 다음과 같이 데이터셋이 변경되었다면 어떨까요? 이번에는 세 가지 유형 모두에 대해서 가정해봅시다.
- 'dog' 토큰은 [MASK]로 변경되었습니다.
- 'he'는 랜덤 단어 'king'으로 변경되었습니다.
- 'play'는 변경되진 않았지만 예측에 사용됩니다.
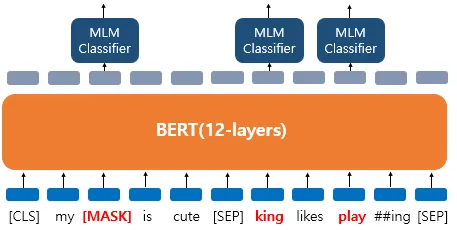
BERT는 랜덤 단어 'king'으로 변경된 토큰에 대해서도 원래 단어가 무엇인지, 변경되지 않은 단어 'play'에 대해서도 원래 단어가 무엇인지를 예측해야 합니다. 'play'는 변경되지 않았지만 BERT 입장에서는 이것이 변경된 단어인지 아닌지 모르므로 마찬가지로 원래 단어를 예측해야 합니다. BERT는 마스크드 언어 모델 외에도 다음 문장 예측이라는 또 다른 태스크를 학습합니다.
3.1.2 TASK #2 Next Sentence Prediction (NSP)
BERT는 두 개의 문장을 준 후 이 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 훈련시킵니다.이를 위해 50:50 비율로 실제 이어지는 2개의 문장과 랜덤으로 이어붙인 두 개의 문장을 주고 훈련시킵니다. 이를 각각 Sentence A와 Sentence B라고 했을때
- 이어지는 문장의 경우 Sentence A : The man went to the store Sentence B : He bough a gallon of milk Label = IsNextSentence
- 이어지는 문장이 아닌 경우 Sentence A : The man went to the store Sentence B : dogs are so cute Label = NotNextSentence
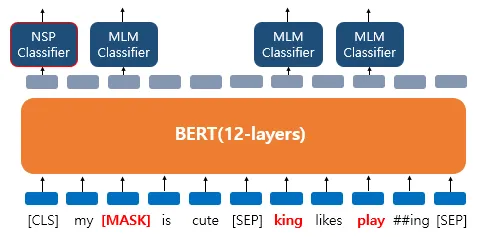
3.2 모델 아키텍처 (Architecture)
- BERT는 Transformer 인코더 구조(12,24) 사용
- 양방향(Bidirectional) self-attention을 전 계층에 적용
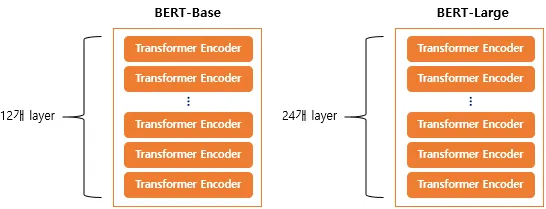
BERT의 기본 구조는 트랜스포머의 인코더를 쌓아올린 구조입니다. Base 버전에서는 총 12개를 쌓았으며, Large 버전에서는 총 24개를 쌓았습니다. 그 외에도 Large 버전은 Base 버전보다 d_model의 크기나 셀프 어텐션 헤드(Self Attention Heads)의 수가 더 큽니다. 트랜스포머 인코더 층의 수를 L, d_model의 크기를 D, 셀프 어텐션 헤드의 수를 A라고 하였을 때 각각의 크기는 다음과 같습니다.
- BERT-Base : L=12, D=768, A=12 : 110M개의 파라미터
- BERT-Large : L=24, D=1024, A=16 : 340M개의 파라미터
3.3 입력 표현 (Input Representation)
입력 토큰은 다음 세 가지 임베딩을 더해서 사용:
- Token Embedding:
- WordPiece 토큰 임베딩
- 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개.
- Segment Embedding:
- 문장 A/B를 구분
- 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
- Position Embedding:
- 토큰의 순서를 표현
- 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
→ [CLS]는 문장의 대표 벡터로 사용, [SEP]은 문장 구분자
Token Embedding : Wordpiece
BERT는 단어보다 더 작은 단위로 쪼개는 서브워드 토크나이저를 사용합니다. BERT가 사용한 토크나이저는 WordPiece 토크나이저로 Byte Pair Encoding의 유사 알고리즘입니다. 동작 방식은 BPE와 조금 다르지만 글자로부터 서브워드를 병합해가는 방식으로 최종 단어 집합(Voacabulary)을 만드는 것은 BPE와 유사하다.
서브워드 토크나이저는 기본적으로 자주 등장하는 단어는 그대로 단어 집합에 추가하지만 자주 등장하지 않는 단어의 경우에는 더 작은 단위인 서브워드로 분리되어 서브워드들이 단어 집합에 추가된다는 아이디어로르 갖고있습니다. 이렇게 단어 집합이 만들어지고 나면 이 단어 집합을 기반으로 토큰화를 수행한다.
BERT의 서브워드 토크나이저도 이와 마찬가지로 동작한다.
준비물 : 이미 훈련 데이터로부터 만들어진 단어 집합
1. 토큰이 단어 집합에 존재한다.
=> 해당 토큰을 분리하지 않는다.
2. 토큰이 단어 집합에 존재하지 않는다.
=> 해당 토큰을 서브워드로 분리한다.
=> 해당 토큰의 첫번째 서브워드를 제외한 나머지 서브워드들은 앞에 "##"를 붙인 것을 토큰으로 한다.예를 들어 embeddings이라는 단어가 입력으로 들어왔을 때, BERT의 단어 집합에 해당 단어가 존재하지 않았다고 해봅시다. 만약, 서브워드 토크나이저가 아닌 토크나이저라면 여기서 OOV 문제가 발생합니다. 하지만 서브워드 토크나이저의 경우에는 해당 단어가 단어 집합에 존재하지 않았다고 해서, 서브워드 또한 존재하지 않는다는 의미는 아니므로 해당 단어를 더 쪼개려고 시도합니다. 만약, BERT의 단어 집합에 em, ##bed, ##ding, #s라는 서브 워드들이 존재한다면, embeddings는 em, ##bed, ##ding, #s로 분리됩니다.
여기서 ##은 이 서브워드들은 단어의 중간부터 등장하는 서브워드라는 것을 알려주기 위해 단어 집합 생성 시 표시해둔 기호입니다. 이런 표시가 있어야만 em, ##bed, ##ding, #s를 다시 손쉽게 embeddings로 복원할 수 있을 것입니다.
포지션 임베딩(Position Embedding)
트랜스포머에서는 포지셔널 인코딩(Positional Encoding)이라는 방법을 통해서 단어의 위치 정보를 표현했습니다. 포지셔널 인코딩은 사인 함수와 코사인 함수를 사용하여 위치에 따른 다른 값을 가지는 행렬을 만들어 이를 단어 벡터들과 더하는 방법입니다. BERT에서는 이와 유사하지만, 위치정보를 사인,코사인 함수로 만드는 것이 아닌 학습을 통해서 얻는 포지션 임베딩(Position Embedding)이라는 방법을 사용한다.
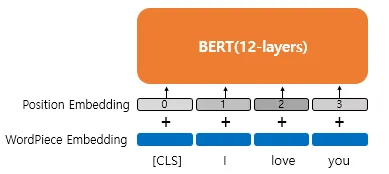
위의 그림은 포지션 임베딩을 사용하는 방법을 보여줍니다. 우선, 위의 그림에서 Wordpiece Embedding은 우리가 이미 알고ㅇ있는 단어 임베딩으로 실질적인 입력입니다. 그리고 이 입력에 포지션 임베딩을 통해서 위치 정보를 더해주어야 합니다. 포지션 임베딩의 아이디어는 위치 정보를 위한 임베딩 층(Embedding layer)을 하나 더 사용합니다. 문장의 길이가 4라면 4개의 포지션 임베딩 벡터를 학습시킵니다. 그리고 BERT의 입력마다 다음과 같이 포지션 임베딩 벡터를 더해주는 것입니다.
- 첫번째 단어의 임베딩 벡터 + 0번 포지션 임베딩 벡터
- 두번째 단어의 임베딩 벡터 + 1번 포지션 임베딩 벡터
- 세번째 단어의 임베딩 벡터 + 2번 포지션 임베딩 벡터
- 네번째 단어의 임베딩 벡터 + 3번 포지션 임베딩 벡터
실제 BERT에서는 문장의 최대 길이를 512로 하고 있으므로, 총 512개의 포지션 임베딩 벡터가 학습된다. 결론적으로 현재 설명한 내용을 기준으로 BERT에서는 총 2 개의 임베딩 층이 사용된다. 단어 집합의 크기가 30522개인 단어 벡터를 위한 임베딩 층과 문장의 최대 길이가 512이므로 512개의 포지션 벡터를 위한 임베딩 층입니다.
세그먼트 임베딩(Segment Embedding)
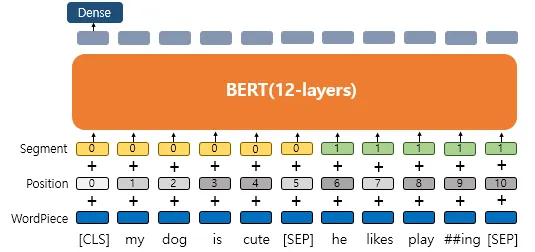
앞서 언급했듯이 BERT는 QA 등과 같은 두 개의 문장 입력이 필요한 태크스를 풀기도 한다. 문장 구분을 위해서 BERT는 세그먼트 임베딩이라는 또 다른 임베딩 층을 사용합니다. 첫번째 문장에는 Sentence 0 임베딩, 두번째 문장에는 Sentence 1 임베딩을 더해주는 방식이며 임베딩 벡터는 두 개만 사용된다.
Attention Mask
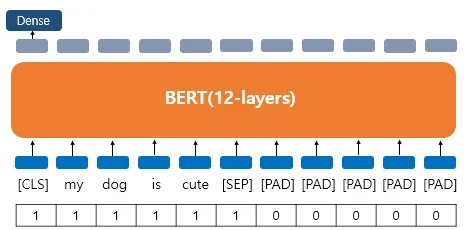
BERT를 실제로 실습하게 되면 어텐션 마스크라는 시퀀스 입력이 추가로 필요합니다. 어텐션 마스크는 BERT가 어텐션 연산을 할 때, 불필요하게 패딩 토큰에 대해서 어텐션을 하지 않도록 실제 단어와 패딩 토큰을 구분할 수 있도록 알려주는 입력입니다. 이 값은 0과 1 두 가지 값을 가지는데, 숫자 1은 해당 토큰은 실제 단어이므로 마스킹하지 않는다는 의미이고, 숫자 0은 해당 토큰은 패딩 토큰이므로 마스킹을 한다는 의미입니다.
Conlusion
BERT는 양방향 Transformer 인코더 구조를 기반으로 사전학습된 언어 모델로 다양한 NLP 탯크에서 뛰어난 성능을 보여준다. 사전학습 단계에서는 마스크드 언어 모델(MLM)과 다음 문장 예측(NSP)을 통해 문맥 이해 능력을 학습합니다. 이후 파인튜닝을 통해 전체 모델을 조금씩 조정하거나, feature-based 방식으로 고정된 표현만을 활용해 다양한 작업에 적용할 수 있다. 특히 BERT는 양방향 문맥 정보를 효과적으로 활용함으로써 기존 단방향 모델의 한계를 극복했습니다.
reference
- https://wikidocs.net/115055
- https://happy-obok.tistory.com/23
- https://hyunsooworld.tistory.com/entry/%EC%B5%9C%EB%8C%80%ED%95%9C-%EC%9E%90%EC%84%B8%ED%95%98%EA%B2%8C-%EC%84%A4%EB%AA%85%ED%95%9C-%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-1
- https://arxiv.org/pdf/1810.04805
