근무중인 회사에서, 전자지갑의 트랜잭션을 확인하여 DAU와 일일 거래액을 확인해야 할 일이 생겼다. Pandas나 Spark로 충분히 처리할 수 있지만, 추후에 생길 PG서비스의 아키텍처 구성을 연습할겸, Redshift를 사용해보기로 했다.
지난 포스트에서, S3에 업로드한 파일을 크롤링하여 데이터베이스에 담아, parquet 포맷으로 변경하는 작업을 했었다. 예쁘게 정리된 파일을 이제 Redshift로 분석하기만 하면 된다.
1. AWS Redshift 페이지
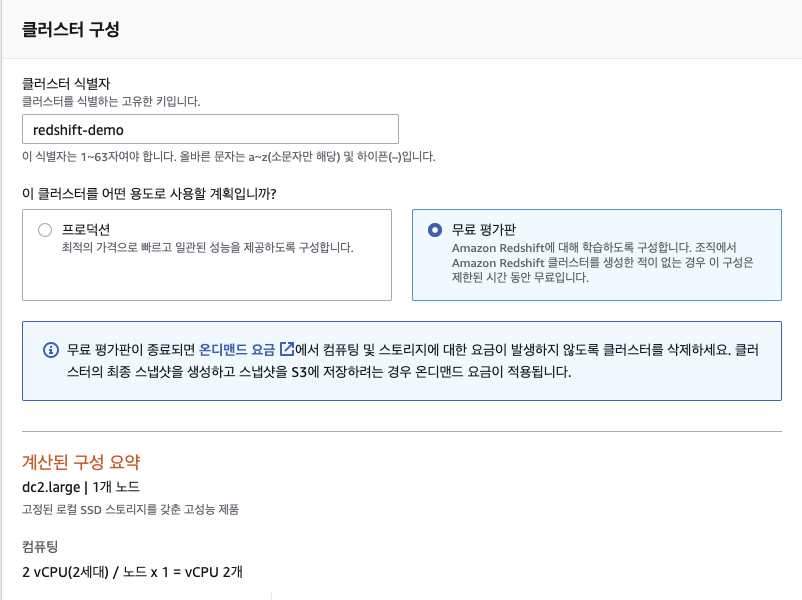
데모용이고, 처리하고자 하는 데이터의 크기가 크지 않으므로 무료 평가판으로 실습한다
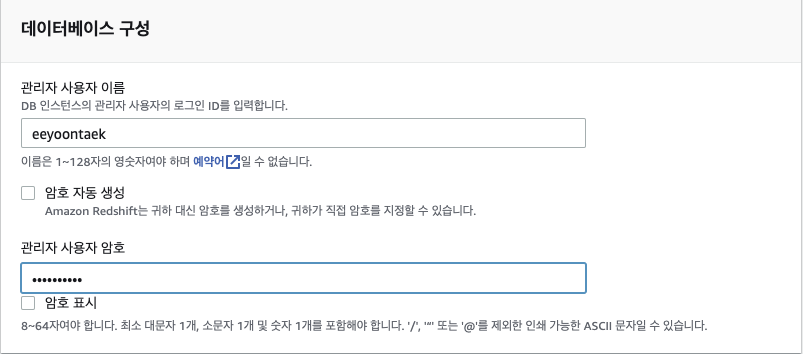
2. Redshift에서 사용할 데이터베이스 구성
3. 네트워크 설정

내 경우에, 그냥 쿼리편집기로 들어가서 데이터를 로딩하고자 했을 때 접속문제가 났다. 구글링 결과 퍼블릭 액세스 문제로 확인되어 퍼블릭 액세스는 활성화 시켜준다
4. 데이터베이스의 테이블 생성

테이블을 생성하여 사용할 칼럼들을 정의해준다
5. 데이터 로드
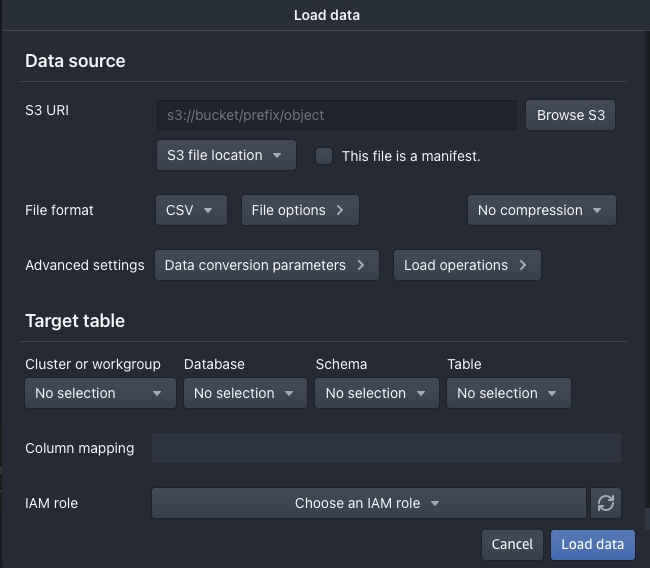
분석할 parquet파일이 있는 디렉토리로 이동하여, 해당 파일을 업로드 한다. 이 때, 파일 포맷과 타겟 테이블, IAM 역할을 올바르게 등록하도록 한다

데이터 엔지니어로 전향중인 백엔드 개발자입니다