카프카는 분산 Application으로, 서버에 물리적인 장애가 발생하는 경우에도 높은 가용성을 보장한다.
카프카에서는 리플리케이션(Replication)을 통해 데이터의 복제본을 가지며 운영중인 브로커가 죽더라도 데이터를 유지할 수 있다
Replication Factor
- 각 Topic에 대한 replication factor (복제본 갯수)를 설정한다
- 각 토픽 파티션에 대해 message log가 replication factor의 수 만큼 복제
vim /usr/local/kafka/config/server.properties
# 여기서 값 수정 가능
default.replication.factor = 2Peter 토픽 - 2개의 리플리케이션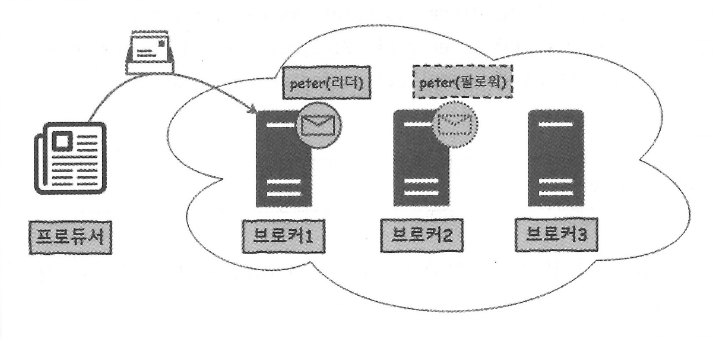
- 리더 : 원본
- 읽기/쓰기 수행
- 팔로워 : 복제본
- 읽기/쓰기 모두 불가. 리더의 데이터를 그대로 복제
브로커1 다운 -> 리더 변경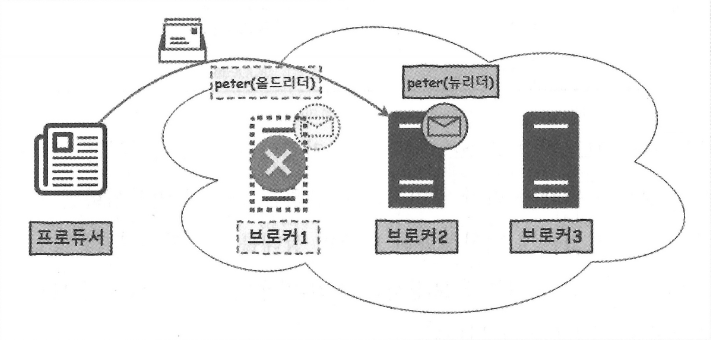
- 브로커2에 있는 peter 토픽의 팔로워가 새로운 리더가 됨 -> 이제부터 브로커2에서 프로듀서 요청에 응답
리플리케이션 단점
- 토픽 사이즈의 n(replication factor의 수)배 크기의 저장소 필요
- 브로커의 리소스 사용량 증가
- 비활성화된 토픽의 상태 체크를 하는 등의 작업 필요
만약, 리더로부터 데이터를 가져오지 못하면서 정합성이 맞지 않는 경우가 발생한다면??
팔로워가 새로운 리더로 바뀌어야 하는데, 데이터의 정합성 때문에 문제 발생
- In Sync Replica(ISR) : 데이터 불일치 방지를 위한 개념
- 현재 리플리케이션 되고 있는 리클리케이션 그룹
- ISR에 속해있는 구성원만이 리더의 자격을 가질 수 있음
만약, 모든 브로커가 다운된다면??
- 마지막 리더가 살아나기를 기다린다
- 살아난다면 메시지 손실 없이 요청들을 처리하며 서비스 사용 가능
- 마지막 리더가 반드시 살아나야 하므로, 장애 복구 시간이 길어질 수 있음
- ISR에서 추방되었지만 먼저 살아나면 자동으로 리더가 된다
- 마지막 리더가 아닌 ISR에서 추방당한 팔로워가 리더가 되는 경우 메시지 손실이 발생할 수 있음

데이터 엔지니어로 전향중인 백엔드 개발자입니다