자료구조란, 여러 데이터들의 묶음을 어떻게 저장하고 사용할 것인지 정의한 것이다. 여기서 데이터(data)란, 문자, 숫자, 소리 등 실생활을 구성하고 있는 것들을 말한다
자료구조는 형태에 따라 선형 구조, 비선형 구조로 나눌 수 있다.
선형 구조
스택(Stack)
- 직역 그대로 스택은 자료(data)를 쌓는 자료구조
- 후입선출(LIFO)
- 실사용 예: 브라우저에서 뒤로가기, 앞으로 가기 기능
const stack = [];
stack.push(1);
stack.push(2);
stack.push(3);
stack.push(4);
stack.push(5);
console.log(stack); // [1, 2, 3, 4, 5]
stack.pop();
stack.pop();
console.log(stack); // [1, 2, 3]큐(Queue)
- 스택의 반대 개념. '줄을 서서 기다리다'
- 선입선출(FIFO)
- 자료가 입력된 순서대로 처리해야 할 필요가 있는 상황에서 사용
- 실사용 예: 프린터의 문서 인쇄 작업
// const array = new Array() 미리 정의된 Array 객체를 사용합니다.
const queue = [];
queue.push(1);
queue.push(2);
queue.push(3);
queue.push(4);
queue.push(5);
console.log(queue); // [1, 2, 3, 4, 5]
queue.shift();
queue.shift();
console.log(queue); // [3, 4, 5]비선형 구조
그래프(Graph)
여러개의 점들이 서로 복잡하게 연결되어 있는 관계를 표현한 자료구조
여기서 점은 정점(vertex)로, 선은 간선(edge)로 표현한다.
알아둬야 할 개념
- 유향 그래프, 무향 그래프
간선이 방향성을 갖는지 갖지 않는지에 따른 분류
- 진입 차수(in-degree) / 진출 차수(out-degree)
한 정점에 들어오고 나가는 간선의 개수
- 인접(adjacency)
두 정점간에 간선이 직접 이어져 있다면 서로 인접
- 자기 루프(self loop)
정점에서 진출하는 간선이 곧바로 자기 자신에게 진입하는 경우
- 사이클(cycle)
한 정점에서 출발하여 다시 해당 정점으로 돌아가는 것
그래프는, 두 가지의 표현 방식이 있다.
1. 인접 행렬
인접행렬은, 정점들간의 인접함을 표시해 주는 행렬으로 2차원 배열의 모습을 가진다.
한 개의 표와 같은 모습을 하기 때문에 두 정점 사이에 관계가 있는지, 없는지 확인하기에 용이하다. 주로 가장 빠른 경로를 찾고자 할 때 사용된다.
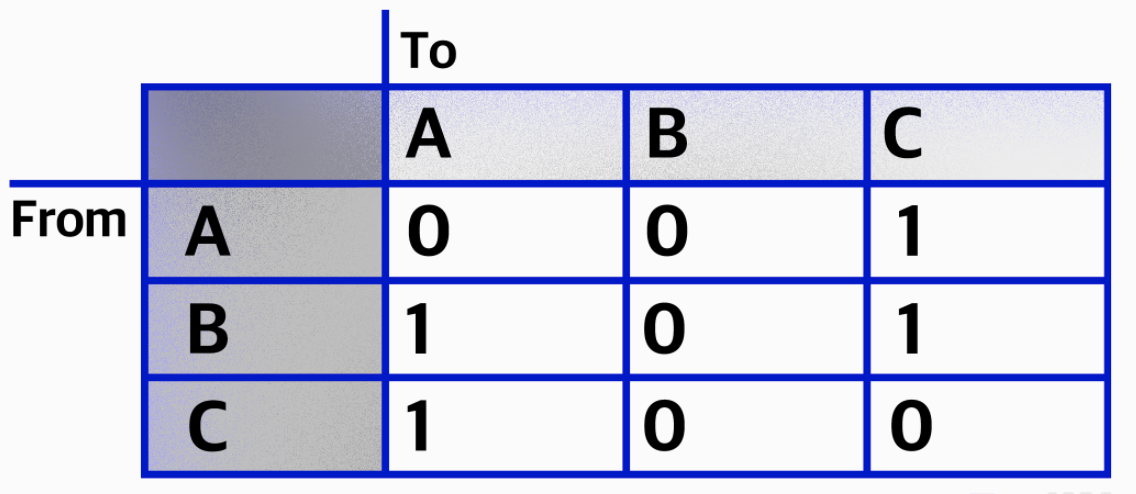 출처 : Code States
출처 : Code States
2. 인접 리스트
인접 리스트는 각 정점이 어떤 정점과 인접한지 리스트의 형태로 볼 수 있는 표현 방식이다. 각 정점마다 하나의 리스트를 가지고 있으며, 이 리스트에는 자신과 인접한 다른 정점들이 담겨 있다.
인접 행렬은 모든 경우의 수를 저장하기 때문에 메모리를 많이 차지한다. 따라서 메모리를 효율적으로 사용하고 싶다면 인접 리스트를 사용한다.
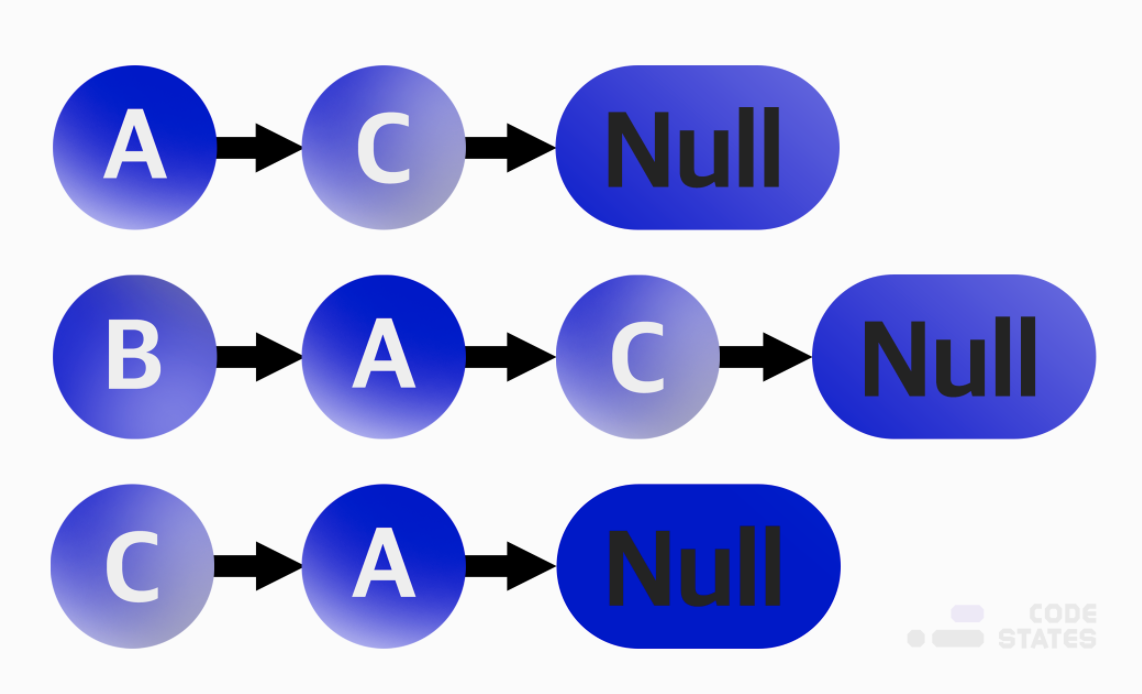 출처 : Code States
출처 : Code States
3. BFS & DFS
:그래프를 탐색하는 방법
1)BFS(너비 우선 탐색)
- Breadth-Frist Search
- 가까운 정점부터 탐색하고, 더 이상 탐색할 수 없을 때 다음 정점으로 이동하여 탐색
- 큐를 이용하여 구현
- 시간 복잡도
- 인접 리스트 : O(n+e)
- 인접 행렬 : O(n^2)
2)DFS(깊이 우선 탐색)
- Depth-First Search
- 한 정점으로부터 특정 경로를 끝까지 탐색한 뒤, 더 이상 탐색할 수 없을 때 옆으로 이동하여 탐색
- 재귀 함수 혹은 스택으로 구현
- 시간 복잡도
- 인접 리스트 : O(n+e)
- 인접 행렬 : O(n^2)
트리(Tree)
데이터가 바로 아래에 있는 하나 이상의 데이터에 단방향으로 연결되는 계층적 자료구조
- 루트(Root) : 최상위 노드
- 부모 노드(Parent Node) : 상위 노드
- 자식 노드(Child Node) : 하위 노드
- 리프 노드(Leaf Node): 자식 노드가 없는 최하위 노드
- 형제 노드(Sibling Node) : 같은 레벨에 나란히 있는 노드
트리에서는 높이와 깊이를 잴 수 있는데, 루트에서 자신에게 걸리는 거리를 레벨(Level)이라고 부르고, 루트는 Level 1로 설정한다. 루트로부터 가장 안쪽에 있는 노드까지의 레벨을 트리의 높이라고 하고, 특정 노드부터 시작하여 루트까지의 레벨을 노드의 깊이라고 표현한다.
실사용 예: 컴퓨터의 디렉토리 구조, 가계부, 조직도 등
이진 탐색 트리(Binary search tree)
1. 이진 트리
- 자식 노드가 최대 두 개인 노드들로 구성된 트리
- 이진 트리 종류
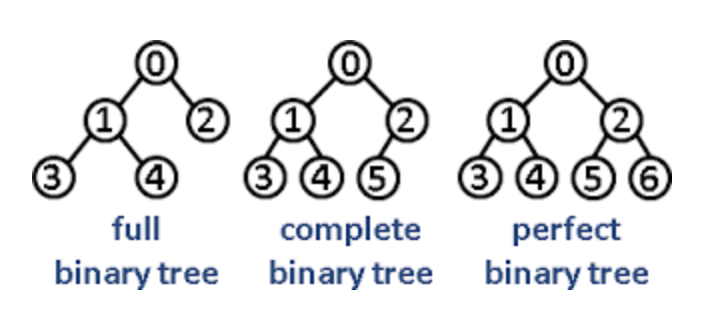 출처:https://greatzzo.tistory.com/m/14?category=662799
출처:https://greatzzo.tistory.com/m/14?category=662799
- 완전 이진 트리(Full binary tree) : 마지막 레벨을 제외한 모든 노드가 가득 차 있고, 적어도 마지막 레벨 노드의 왼쪽이 채워져 있는 트리
- 정 이진 트리(Complete Binary Tree) : 모든 노드의 자식이 없거나 두 개인 트리.
- 포화 이진 트리(Perfect Binary Tree) : 완전 이진 트리이면서, 정 이진 트리인 트리
2. 이진 탐색 트리(Binary search tree)
- 모든 왼쪽 자식들이 부모보다 작은 값을 가지고, 모든 오른쪽 자식들은 부모보다 큰 값을 가지는 이진 트리
- 루트 값에 따라 트리가 불균형하게 치우칠 수 있기 때문에, 노드를 수정할 때마다 트리를 재조정 해야함.
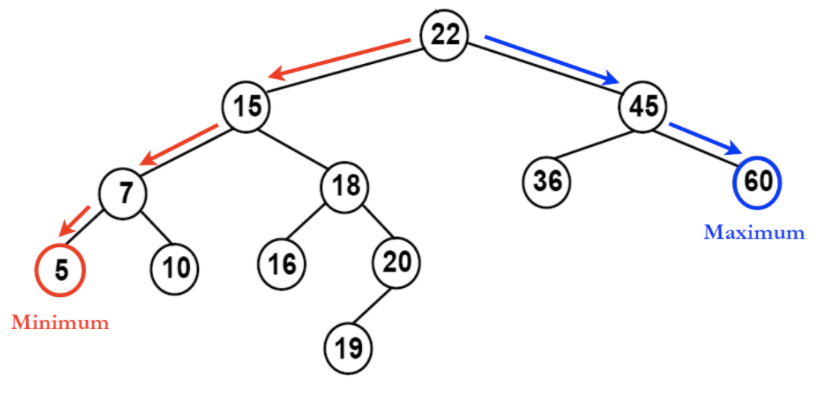 출처:https://ratsgo.github.io/data%20structure&algorithm/2017/10/22/bst/
출처:https://ratsgo.github.io/data%20structure&algorithm/2017/10/22/bst/
3. 트리 순회(Tree traversal)
- 전위 순회(Preorder) : 루트를 방문한 뒤, 루트를 기준으로 왼쪽의 노드들을 둘러보고, 왼쪽 노드 탐색이 끝나면 오른쪽 탐색
- 중위 순회(Inorder) : 제일 왼쪽 끝에 있는 노드부터 순회하여, 루트를 기준으로 왼쪽에 있는 노드 순회가 끝나면 루트를 거쳐 오른쪽에 있는 노드로 이동하여 탐색 마무리
- 후위 순회(Postorder) : 제일 왼쪽 끝에 있는 노드부터 순회하여, 루트를 거치지 않고 오른쪽으로 이동해 순회한 뒤 제일 마지막으로 루트 방문
