1. 제네릭
1-1. 정의
- 컴파일 타임에 타입을 지정해서 타입 안정성을 보장하고 코드 재사용성을 높이는 기능이다.
- 클래스, 인터페이스, 메서드에 사용할 수 있다.
- 타입을 명시하지 않고도 다양한 데이터 타입을 처리하는데 사용할 수 있다.
1-2. 기본 형태
- , <?> 등 <> 내부에 자료형 등을 명시(생략 가능)한다.
- 컬렉션 표현, 람다 표현식 등과 조합되어서 이용한다.
1-3. 제네릭 이전의 방식
1-3-1. 기존 방식
- 새로운 형태의 객체를 추가해야 할 때마다 새로운 클래스를 만든다.
1-3-2. 기존에 사용한 해결 방식
- 필드를 모든 자바 클래스의 최상위 클래스인 Object 타입으로 선언한다.
- 데이터 저장 시 제약 조건이 없음
- 데이터를 읽어올 때는 저장된 형태(해당 객체의 타입)로 캐스팅해야 함
1-4. 제네릭을 도입한 이유
- 기존 방식은 약한 타입 체크를 수행하기 때문에 컴파일 시점에는 캐스팅 오류 발생 여부를 확인할 수 없다.
- 캐스팅 오류 발생 시, 실행 시점에 인스턴스의 타입에 따라 오류가 발생하며, 이를 ClassCastingException이라 함.
- 실행 시점에 발생하는 캐스팅 오류를 예방하기 위해 강한 타입 체크를 수행해야 함
- 제네릭 클래스와 제네릭 인터페이스를 사용해서 강한 타입 체크가 될 수 있도록 한다.
1-5. 제네릭 클래스와 제네릭 인터페이스 정의하기
참고) 제네릭 타입 변수는 사용자 임의로 지정할 수 있으나, 관례적으로 사용하는 짝이 있다.
- Type -> T
- Key -> K
- Value -> V
- Number -> N
- Element -> E
1-5-1. 제네릭 클래스
- 일반 클래스처럼 class 키워드를 사용한다.
- 여러 개의 제네릭 타입 변수를 사용할 수 있으며, 콤마(,)로 구분한다.
// 제네릭 타입 변수를 1개만 사용하는 제네릭 클래스
접근지정자 class 클래스명 <제네릭 타입 변수> {
제네릭 타입 변수를 사용하는 코드;
}
// 제네릭 타입 변수를 2개 이상 사용하는 제네릭 클래스
접근지정자 class 클래스명 <제네릭 타입 변수, 제네릭 타입 변수, ... , 제네릭 타입 변수> {
제네릭 타입 변수를 사용하는 코드;
}1-5-2. 제네릭 인터페이스
- 일반 인터페이스처럼 interface 키워드를 사용한다.
- 여러 개의 제네릭 타입 변수를 사용할 수 있으며, 콤마(,)로 구분한다.
// 제네릭 타입 변수를 1개만 사용하는 제네릭 클래스
접근지정자 interface 인터페이스명 <제네릭 타입 변수> {
제네릭 타입 변수를 사용하는 코드;
}
// 제네릭 타입 변수를 2개 이상 사용하는 제네릭 클래스
접근지정자 interface 인터페이스명 <제네릭 타입 변수, 제네릭 타입 변수, ... , 제네릭 타입 변수> {
제네릭 타입 변수를 사용하는 코드;
}1-5-3. 제네릭 클래스의 객체 생성
- 제네릭 클래스는 타입이 정해져있지 않으므로, 객체 생성 시 제네릭 타입 변수에 실제 타입을 대입한다.
- 만약 실제 제네릭 타입을 생략한다면 제네릭 타입은 Object로 정해진다.
- 제네릭을 활용해서 클래스를 생성하면 강한 타입 체크를 사용하므로, 컴파일 시점에 캐스팅 오류를 확인할 수 있다.
// 기본
클래스명<실제 제네릭 타입> 참조변수명 = new 클래스명<실제 제네릭 타입>;
// 일부 축약
클래스명<실제 제네릭 타입> 참조변수명 = new 클래스명<>;1-6. 제네릭 메서드
1-6-1. 정의
- 리턴타입 또는 매개변수 타입을 제네릭 타입으로 선언하는 메서드이다.
- 접근지정자 <매개변수 타입> 반환타입 메서드명(매개변수) 형태를 가진다.
1-6-2. 선언
- 제네릭을 사용하는 위치, 매개변수 존재 여부 등을 고려해야 한다.
// 제네릭 타입 변수가 1개인 경우
접근지정자 <T> T 메서드명(T t) { ... };
// 제네릭 타입 변수가 2개 이상인 경우
접근지정자 <T, V, ... , Z> T 메서드명(T t, V v, ... ,Z z) { ... };
// 매개변수에만 제네릭이 사용되는 경우
접근지정자 <T> 반환타입 메서드명(T t) { ... }
// 반환타입에만 제네릭이 사용되는 경우
접근지정자 <T> T 메서드명(매개변수) { ... }1-6-3. 제네릭 메서드 호출하기
- 호출할 메서드 앞에 <실제 제네릭 타입>을 붙여준다.
- 매개변수 값으로 제네릭 타입 유추가 가능한 경우에는 제네릭 타입 지정을 생략할 수 있다.
// 기본
참조하는객체.<실제 제네릭 타입>메서드명(매개변수);
// 타입 생략
참조하는객체.메서드명(매개변수);1-6-4. 제네릭 타입 범위 제한(bound)
- 제네릭 메서드는 기본적으로 Object에서 상속받은 메서드만 사용 가능하다.
- 그렇기 때문에 캐스팅 등을 필요로 할 수 있다.
1-6-4-1. bound의 정의
- 제네릭 타입으로 올 수 있는 실제 타입의 종류를 Object 타입보다 더 작은 타입으로 제한한다.
- 타입 범주를 추가함으로써 메서드 내부에서 사용할 수 있는 메서드의 증가를 기대할 수 있다.
1-6-4-2. 선언 방법
// 제네릭 클래스 타입 제한
접근지정자 class 클래스명 <제네릭 타입 extends 클래스/인터페이스명> { ... }
// 제네릭 메서드 타입 제한
접근지정자 <T extends 클래스/인터페이스명> T 메서드명(T t) { ... }1-6-5. 메서드 매개변수일 때 제네릭 클래스의 타입 제한
- 클래스 객체가 메서드 매개변수일 때 타입 제한을 할 수 있다.
- 방법
방법 1. 제네릭 타입음 명시한 타입만 사용할 수 있다.
방법 2. 제네릭 타입의 대상은 모든 타입이다.
방법 3. 제네릭 타입은 명시한 클래스나 해당 클래스의 자식 클래스 타입만 지정할 수 있다.
방법 4. 제네릭 타입은 명시한 클래스나 해당 클래스의 부모 클래스 타입만 지정할 수 있다.
// 방법 1
리턴타입 메서드명(제네릭 클래스명<제네릭 타입명> 참조변수명) { ... }
ex) method(Fruit<Apple> v)
// 방법 2
리턴타입 메서드명(제네릭 클래스명<?> 참조변수명) { ... }
ex) method(Fruit<?> v)
// 방법 3
리턴타입 메서드명(제네릭 클래스명<? extends 클래스/인터페이스명> 참조변수명) { ... }
ex) method(Fruit<? extends Food> v)
// 방법 4
리턴타입 메서드명(제네릭 클래스명<? super클래스/인터페이스명> 참조변수명 { ... }
ex) method(Fruit<? super Food> v)1-6-6. 제네릭 클래스의 상속
- 제네릭 메서드도 상속이 가능하다.
- 부모 클래스가 제네릭 클래스일 때, 이를 상속한 자식 클래스도 제네릭 클래스이다.
- 제네릭 클래스를 상속한 자식 클래스는 부모 클랫의 제네릭 타입 변수를 그대로 상속받는다.
- 자식 클래스는 상속받은 제네릭 타입 변수 이외의 제네릭 타입 변수를 추가 정의할 수 있다.
- 즉, 자식 클래스의 제네릭 타입 변수의 개수는 항상 부모 클래스의 제네릭 타입 변수와 같거나 많다.
- Case
// 1. 부모 클래스와 자식 클래스의 제네릭 타입 변수 개수가 동일
class Parent<K, V> { ... }
class Child<K, V> extends Parent<K, V> { ... }
// 2. 부모 클래스보다 자식 클래스의 제네릭 타입 변수 개수가 많은 경우
class Parent<K> { ... }
class Child<K, V> extends Parent<K> { ... }2. 컬렉션
2-1. 정의
- 데이터의 저장 용량(capacity, 저장할 수 있는 최대 데이터 수)을 동적으로 관리하는 자료구조
- 리스트, 스택, 큐, 트리 등의 자료구조 + 정렬, 탐색 등의 알고리즘을 구조화 = 컬렉션 프레임워크
2-2. 컬렉션의 계층도
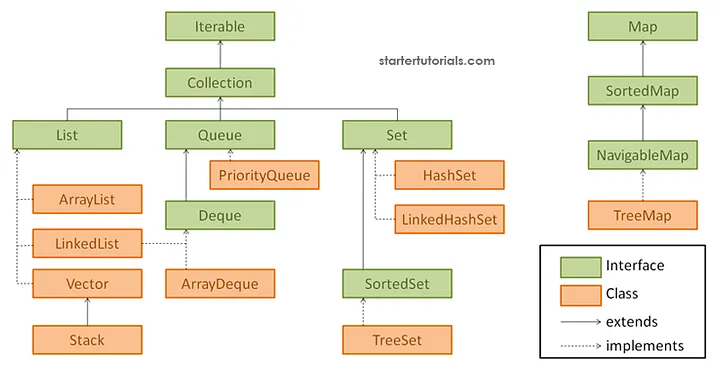
2-3. List<E> 컬렉션 인터페이스
2-3-1. 배열과의 차이점
- 크기가 동적이여서 요소 추가, 제거가 자유롭다.
- Array(배열)은 Arrays.asList()메서드로 List 타입의 참조변수에 값을 할당하며, 저장 공간을 변경할 수 없다.
- 값 추가를 시도하면 UnsupportedOperationException이 발생한다.
- Array(배열)은 Arrays.asList()메서드로 List 타입의 참조변수에 값을 할당하며, 저장 공간을 변경할 수 없다.
List<Integer> list = Arrays.asList(1, 2, 3, 4);- 다양한 메서드를 제공하기 때문에 유연하다.
- 성능, 효율성 면에서는 비교적 불리하다.
2-3-2. List<E> 인터페이스의 대표적인 구현체
- ArrayList<E> - 초기 크기를 정할 수 있고, 미지정 시에는 기본값이 자동으로 지정된다.
- Vector<E> - 초기 크기를 정할 수 있고, 미지정 시에는 기본값이 자동으로 지정된다.
- LinkedList<E> - 초기 크기 설정이 불가능하다.
2-3-3. ArrayList<E>
- List<E> 인터페이스를 구현한 구현 클래스이다.
- 수집한 원소를 인덱스로 관리하며, 저장 용량은 동적이다.
2-4. Set<E> 컬렉션 인터페이스
2-4-1. 정의
- 인덱스가 없다.
- 데이터 자체가 식별자이기 때문에 중복을 허용하지 않는다.
2-4-2. Set의 모든 데이터 가져오기
- iterator() 메서드로 Iterator<E> 객체를 반환받아서 사용한다.
- forr-each 구문을 활용한다.
2-4-3. Set<E> 인터페이스의 대표적인 구현체
- HashSet<E>
- LinkedHashSet<E>
- TreeSet<E>
2-4-4. HashSet<E>
- 서로 다른 객체 주소를 가진다면 서로 다른 객체. 값으로 인식된다.
- 일부 메서드는 오버라이드해서 사용해야 한다.
- equals()
- hashCode()
2-4-5. LinkedHashSet<E>
- HashSet<E>을 상속한 클래스이다.
- 연결 정보가 추가되어 데이터 입력 순서와 출력 순서가 동일함
2-4-6. TreeSet<E>
- 크기에 따른 정렬과 검색 기능이 추가된 컬렉션이다.
- 데이터 입력 순서와 무관하게 크기순으로 정렬되어 출력된다.
2-5. Map<E> 컬렉션 인터페이스
- Key, Value 한 쌍으로 데이터를 저장한다.
- Key는 중복 저장이 불가능하고, Value는 중복 저장할 수 있다.
2-5-1. Map<K, V> 인터페이스의 대표적인 구현체
- HashMap<K, V>
- LinkedHashMap<K, V>
- Hashtable<K, V>
- TreeMap<K, V>
2-5-2. HashMap<K, V>
- Key 값 중복 여부를 확인하는 방법
- Key 객체의 hashCode() 값이 같고, equals() 메서드가 true 반환 시 동일 객체이고, 그 외에는 다른 객체로 간주한다.
2-5-3. HashTable<K, V>
- HashMap과 유사하다.
- 동기화 메서드로 구현되어 멀티 쓰레드 환경에서 안전하게 동작한다.
2-5-4. LinkedHashMap<K, V>
- 입력 순서대로 출력한다.
2-5-5. TreeMap<K, V>
- 데이터를 Key 순으로 정렬해서 저장한다.
- Key 객체는 크기를 비교하는 기준이 필요하다.
2-6. 그 외의 컬렉션 클래스/인터페이스
- Stack<E>
- 후입선출(LIFO) 자료구조를 구현한 클래스이다.
- QueueStack<E> 컬렉션 인터페이스
- 선입선출(FIFO) 동작을 정의한다.
- 선입선출(FIFO) 동작을 정의한다.
3. 함수형 프로그램
3-1. 정의
- 프로그램을 함수의 조합으로 만드는 방식이다.
- 순수 함수를 활용한다.
3-2. 순수함수
3-2-1. 정의
- 함수의 실행 결과가 항상 동일한 함수이다.
- 결과 예측이 가능하다.
- 함수의 영향으로 값 등이 변화하지 않는다. -> Side Effect가 일어나지 않는다.
- 함수 외부에 영향을 주는 요소가 없다.
3-2-2. 특징
- 동일한 입력값을 넣으면 동일한 결과를 반환하는 함수이다. -> 값에 대한 사본을 만들어서 immutable함을 보장한다.
- 데이터나 상태를 변경하지 않고 새 값을 반환한다. -> 비상태성(stateless), 불변성(immutability)를 보장한다.
- 선언형 프로그래밍이라고도 한다. -> 무엇을 해야 하는지에 집중하고, 어떻게 하는지는 고려하지 않는다.
4. 람다식
4-1. 정의
- 객체지향 언어인 Java에서 함수형 프로그래밍 기법을 지원하는 문법이다.
- 주로 함수형 인터페이스와 함께 사용되며, 코드 블럭을 간결하게 할 수 있다.
- Java는 이미 존재하는 인터페이스의 문법을 활용해서 람다식을 표현한다.
4-2. 함수형 인터페이스
- functional interface 라고 한다.
- 하나의 추상 메서드만 가지는 인터페이스로 정의된다.
- @FunctionalInterface 어노테이션으로 함수형 인터페이스임을 명시한다.
- 컴파일러가 두 개 이상의 추상 메서드를 선언하면 오류를 반환한다.
- Runnable, Callable, Consumer<T>, Supplier<T>, Function<T, R> 등이 있다.
4-3. 함수형 인터페이스에 정의된 메서드 호출하기
4-3-1. 인터페이스의 구현 클래스 만들기
- 구현 클래스로 인터페이스를 구현한다.
- 클래스의 생성자를 이용해서 객체를 생성하고, 객체의 참조 변수로 메서드를 호출한다.
4-3-2. 익명 이너 클래스를 사용
- 익명 이너 클래스를 사용해서 객체를 생성하고, 이 객체로 메서드를 호출한다.
4-3-3. 람다식 활용
- 함수형 프로그래밍을 활용하는 방법이다.
- 익명 이너 클래스의 메서드 정의 부분을 이용해서 메서드를 정의하고, 호출한다.
4-3-4. 메서드 호출 예시
방법 1. 매개변수와 리턴값이 없는 경우
방법 2. 매개변수는 있지만 리턴값은 없는 경우
방법 3. 매개변수는 없지만 리턴값은 있는 경우
방법 4. 매개변수와 반환값이 모두 있는 경우
// 방법 1
() -> { 함수 내용 }
// 방법 2
(매개변수) -> { 함수 내용 }
// 방법 3
() -> { 리턴값 }
// 방법 4
(매개변수) -> { 리턴값 }4-3-5. 규칙
- 함수 본문이 한 줄이면 중괄호를 생략할 수 있다.
- 매개변수의 타입은 생략할 수 있다.
- 매개변수가 1개면 소괄호를 생략할 수 있다.
- 소괄호를 생략한다면 매개변수 값도 생략해야 한다.
