회사에서 담당하는 서비스에 Elasticsearch로 구현된 검색기능이 있다.
평소에는 대수롭지 않게 여겼는데 해당 기능에 이슈가 있어서 Elasticsearch에 대해 조사해보면서 더 나아가 평소에 해보고 싶었던 로그수집 시스템 구축을 위해 찾아봤던 ELK Stack에 대해서도 정리했다.
Elasticsearch

앨라스틱서치란?
- Apache Lucene 기반의 java 오픈소스 분산 검색 엔진
- 데이터 저장소가 아니라 Mysql같은 DB를 대체할 수는 없음
- 방대한 양의 데이터를 신속하고 거의 실시간으로 저장, 검색, 분석 가능
- 검색을 위해 단독으로 사용되기도 하며 ELK(Elasticsearch / Logstatsh / Kibana)스택으로 사용되기도 함
앨라스틱서치와 관계형 DB 비교
| RDBMS | Elasticsearch |
|---|---|
| schema | mapping |
| database | index |
| table | type |
| row | document |
| column | field |
평소에는 RDBMS 용어를 많이 사용하는 편인데 Elasticsearch에서는 명칭이 많이 다르다. 😅
핵심 개념
클러스터
- 클러스터는 하나 이상의 노드가 모인 것
- 이를 통해 전체 데이터를 저장하고 모든 노드를 포괄하는 통합 색인화 및 검색 기능을 제공
- 고유한 이름으로 식별, 기본 이름은
elasticsearch
노드
- 클러스터에 포함된 단일 서버
- 데이터를 저장하고 클러스터의 색익화 및 검색 기능에 참여함
- 이름으로 식별, 기본 이름은 노드에 지정되는 임의의
UUID
인덱스
- 다소 비슷한 특성을 가진 문서의 모음
- 이름으로 식별(모두 소문자)
타입
- 하나의 색인에 하나 이상의 유형 정의 가능
- 유형 : 색인을 논리적으로 분류 / 구분한 것
도큐먼트
- 색인화 할 수 있는 기본 정보 단위
- JSON 형식
샤드 & 리플리카
- 색인은 방대한 양의 데이터 저장 가능
- 색인을 샤드라는 조각으로 분할하는 기능 제공
- 클러스터의 어떤 노드에서도 호스팅 가능
- 샤딩이 중요한 이유
- 콘텐츠 볼륨의 수평 분할/확장 가능
- 작업을 여러 샤드에 분산 배치하고 병렬화함으로써 성능/처리량 향상 가능
- 샤딩이 중요한 이유
- 샤드에 대해 복사복을 생성가능한데 이것이 리플리카
- 리플리카가 중요한 이유
- 샤드/노드 오류가 발생하더라도 고가용성 제공
- 모든 리플리카에서 병렬 방식으로 검색 실행 가능
- 리플리카가 중요한 이유
ELK Stack

- Elasticsearch, Logstash, Kibana의 세 가지 프로젝트로 구성된 스택
- 사용자에게 모든 시스템과 애플리케이션에서 로그를 집계하고 이를 분석하며 애플리케이션과 인프라 모니터링 시각화를 생성하고 문제 해결하며 보안 분석을 할 수 있는 능력 제공
Logstash
- 다양한 소스로부터 데이터를 수집하고 전환하여 원하는 대상에 전송할 수 있도록 하는 오픈 소스 데이터 수집 도구 (파이프라인)
- 사용자가 데이터 유형에 관계없이 데이터를 쉽게 수집할 수 있도록 도와줌
Kibana
- 로그 및 이벤트 검토에 사용하는 데이터 시각화 및 탐색 도구
- 사용하기 쉽고 대화형 차트와 사전 구축된 집계 및 필터, 지리 공간적 지원을 제공
- Elasticsearch에 저장된 데이터를 시각화할 때 원하는 선택 가능
Beats

- 데이터 전송을 뺀 데이터 수집만을 전문적으로 하는 경량화된 데이터 수집 도구
- Beats로 다양한 데이터를 수집해서 Logstash로 데이터를 전송하는게 일반적인 사용법
로그 수집해서 시각화하기
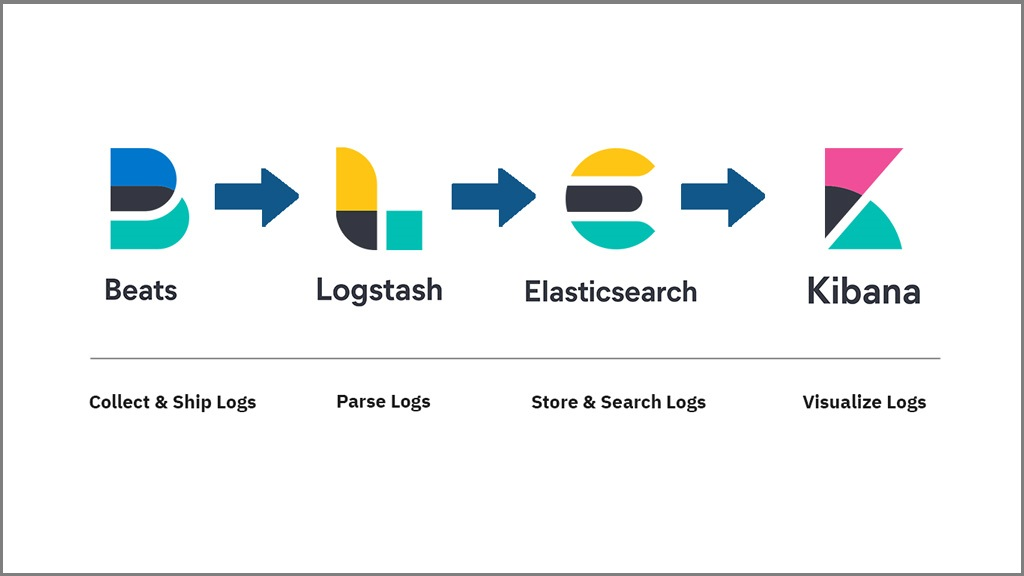
로그를 수집해서 시각화하기 위해 ELK에 Beats를 붙여서 사용한다.
간단한 플로우는 아래와 같다.
- 서버의 로그폴더를 바라보는 FileBeats를 설치한다.
- 서버에 따라 다르게 수집할 수 있다.
- FileBeats는 주기적으로 로그폴더에 생기는 로그파일을 읽어서 Logstash로 데이터를 전송한다.
- Logstash에 쌓인 데이터는 Elasticsearch로 데이터를 가공해서 전달한다.
- Elasticsearch에 쌓인 데이터는 Kibana에서 시각화해 확인한다
빨리 성장해서 팀에서 담당하는 서비스의 로그를 모두 Web UI에서 시각화하여 볼 수 있도록 해야겠다.ㅎㅎ

호기심 많은 주니어 백엔드 개발자입니다.