참고 사이트
감사합니다 감사합니다...
빅분기 준비하는 사람이라면 모를수 없는 사이트...
감사합니다... 감사합니다...
1. 데이터 정규성 검증
-
이거 왜 하나요?
정말 많은 통계적 가설 검정 방법들 예컨데, 이후에 배울t-testANOVA등이 전부 데이터가 정규 분포를 따른다는 가정을 기반으로 한다. 데이터가 정규 분포를 따르지 않으면, 이러한 검정 방법의 결과가 신뢰할 수 없게 된다.
이외에도 회귀 분석 등의 통계 모델들은 데이터가 정규성을 따라야 더 정확한 결과를 제공한다.- 그렇기 때문에 정규화 시켜주기 위해
로그 변환제곱근 변환등의 다양한 데이터 변환 기법이 적용되기도 한다.
- 그렇기 때문에 정규화 시켜주기 위해
-
정규성 검증 라이브러리 import
from scipy.stats import shapiro
일단 from scipy .stats import shpairo 를 통해 모듈 불러오고 (샤피로, 샤피로 윌크 다 같은 말임)
정규성을 검정하고자 하는 데이터를 넣어준다.
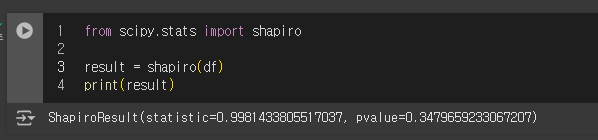
위와 같이 나온 경우에
-
statistic=0.9981
Shapiro-Wilk 검정 통계량을 의미하는 것으로
이 값은 데이터가 정규분포에 얼마나 가까운지를 나타낸다.1에 가까울수록 데이터가 정규분포에 더 가깝다는 것을 의미
-
pvalue=0.3479
데이터 정규성 검증에서 귀무가설인H0의 경우에
데이터는 정규분포를 따른다를 주장하고
대립가설인H1의 경우에
데이터는 정규분포를 따르지 않는다 를 주장한다.
본 샤피로-윌크 검정 결과p-value가 0.05(유의수준) 안으로 들어오지 못한 바,
대립가설이 채택될 수 없으므로
귀무가설이 맞다.
따라서 데이터는 정규성을 만족한다고 판단할 수 있다.
위와 반대로
이런 경우에는 정규성을 충족시키지 못한다고 할 것이다.
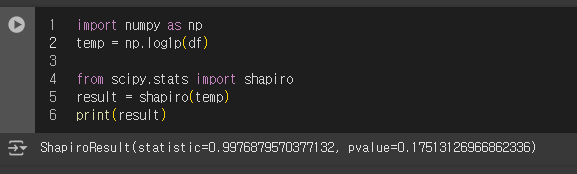
이런 경우에는 대개 아래처럼import numpy as np np.log1()를 통하여 정규화를 진행하기도 한다.
위에 사진을 보면 정규화가 되어 p-value가 유의수준을 넘겨버렸다.
(귀무가설 기각 불가)

- 다만 대부분의 경우에 샤피로-윌슨 검정에서 걸러지는 문제는 없을 것.
2. t-test (t검정)
데이터 정규성이 검증된 경우 진행하는 검정 방법이다.
T-검정(T-Test)
T-검정은 두 집단의 평균을 비교하여 차이가 유의미한지 검정하는 통계적 방법이다.
주로 두 집단 간의 평균 차이를 평가하거나
표본 평균이 특정 값과 다른지 확인할 때 사용된다.
T-검정을 통해 두 집단 간 평균 차이가 우연에 의한 것인지 확인할 수 있다.
T-검정의 종류
- 단일 표본 t-검정 (One-sample t-test):
표본 평균이 특정 값과 다른지 검정.
정규성 검정 이후 진행 (shapiro)
ex) 우리 학교 학생들의 평균 키가 전국 평균 키와 같은가?
-귀무가설 H0: 같다.
-대립가설 H1: 다르다.
from scipy.stats import ttest_1samp
result = ttest_1samp(df['키'], 165)
print(result)
# p가 유의수준 0.05 안으로 들어온 경우에 귀무가설 기각 (다르다)- 독립 표본 t-검정 (Independent two-sample t-test):
두 독립된 집단의 평균의 차이가 통계적으로 유의미한지 검정하기 위한 통계적 방법
- 두 집단이 독립적이고
- 종속변수가 연속형일 때 사용
- 정규성 검정을 하고
- 등분산 검정까지 통과해야 실시 가능
- 집단 중 하나라도 정규성이 없을 경우에 비모수 검정 실시
# 1. 먼저 정규성 각각 검정
# 2.1 정규성 검정 x => stats.manwhitneyu(A, B, alternative = 'less'
# 2.2 정규성 검정 o =>
# 귀무가설: 분산이 동일하다.
from scipy.stats import levene
result = levene(A,B)
# p-value가 0.05 넘어가야 귀무가설 채택.
# 3.1 등분산 검정 된 경우: ttest_ind
# H0: 그룹별 평균이 차이가 없다
# H1: 그룹별 평균이 차이가 있다. (A가 B보다 작다)
from scipy.stats import ttest_ind
result = ttest_ind(A,B, alternative = "less")
# p-value 확인하고 넘으면 귀무가설 채택
# 3.2 등분산 검정이 되지 않은 경우: ttest_ind 에 equal_var=False 추가
result = ttest_ind(A,B, alternative = "less", equal_var = False)
- 대응 표본 t-검정 (Paired sample t-test):
동일한 집단에서 두 조건의 평균 차이를 검정.
같은 집단의 전/후 비교라고 보면 된다.
- 정규성을 검정하고 (shapiro)
- 정규성이 검정되지 않은 경우: wilcoxon 부호 순위 검정
- 정규성이 검정된 경우에는
ttest_rel
# 1. 모집단에 대해서 정규성 검정
# 다만 이때 df['diff'] = df['before'] - df['after']
# 위 차이를 두고서 검정한다.
from scipy.stats import shapiro
result = shapiro(df['diff'])
# p-value 체크
# 2.1 정규성 검정되지 않은 경우: wilocxon 부호 순위 검정
result = stats.wilcoxon(df['diff'], alternative = 'greater')
print(result)
# p-value 체크
# 2.2 정규성 검정 된 경우
from scipy.stats import ttest_rel
result = ttest_rel(df['before'], df['after'], alternative = "less")
print(result)
# p-value 체크예시: 독립 표본 T-검정
문제 상황
두 그룹(예: A와 B)의 시험 점수가 다음과 같다고 가정합니다:
- 그룹 A: [85, 88, 90, 92, 87]
- 그룹 B: [78, 82, 85, 80, 76]
우리는 두 그룹 간의 평균 점수 차이가 통계적으로 유의미한지 확인하고자 합니다.
단계별 설명
-
귀무가설(H0)과 대립가설(H1) 설정
- H0(귀무가설): 두 그룹의 평균은 같다 ().
- H1(대립가설): 두 그룹의 평균은 다르다 ().
-
데이터 준비
import numpy as np from scipy.stats import ttest_ind # 데이터 정의 group_A = [85, 88, 90, 92, 87] group_B = [78, 82, 85, 80, 76] -
t-검정 수행
# 독립 표본 t-검정 수행 t_statistic, p_value = ttest_ind(group_A, group_B) print(f"T-statistic: {t_statistic}") print(f"P-value: {p_value}") -
결과 해석
출력 결과:T-statistic: 4.47213595499958 P-value: 0.002633974596215561 -
유의수준과 결론
- 일반적으로 유의수준(α)을 로 설정
- p-value = 는 보다 작으므로 귀무가설(H0)을 기각
- 결론: 두 그룹 간 평균 점수 차이는 통계적으로 유의미하다.
추가 설명
T-통계량 계산 공식:
- : 각 그룹의 평균.
- : 각 그룹의 분산.
- : 각 그룹의 샘플 크기.
P-value 해석:
- : 귀무가설 기각 → 두 집단 간 차이가 유의미하다.
- : 귀무가설 채택 → 두 집단 간 차이가 유의미하지 않다.
