46. Binary Tree Nodes
- 처음에 제출하고 틀린 답...
SELECT N, CASE
WHEN N NOT IN P THEN 'Leaf'
WHEN P IS NULL THEN 'Root'
ELSE 'Inner'
END AS Node
FROM BST;틀린 이유는
1.N NOT IN P에서NOT IN조건에서NULL이 포함되면 전 체조건이UNKNOWN으로 평가되어 원하지 않은 결과가 나올 수 있음
NOT IN대신NOT EXISTS사용 권장
2. 서브쿼리로 처리해줘야함
- 정답은 아래와 같음
SELECT N, CASE
WHEN P IS NULL THEN 'Root'
WHEN N NOT IN (SELECT DISTINCT P
FROM BST
WHERE P IS NOT NULL) THEN 'Leaf'
ELSE 'Inner'
END AS Node
FROM BST
ORDER BY N;47. Draw The Triangle 1
WITH numbers AS (
SELECT TOP 20 ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS RN
FROM sys.objects a
CROSS JOIN sys.objects b
)
SELECT REPLICATE('* ', 20 - RN + 1) AS StarPattern
FROM numbers
ORDER BY RN;1. ROW_NUMBER() 윈도우 함수
핵심 개념
- 결과 집합에 순차적인 번호 부여
- 반드시
ORDER BY절 필요
(정렬기준 필요 없다면ORDER BY안에SELECT NULL쓰면 됨) - 고유한 연속 번호 생성
기본 문법
ROW_NUMBER() OVER (
[PARTITION BY 컬럼] -- 선택적
ORDER BY 정렬기준 -- 필수
)주요 특징
- 동일 값에도 고유 번호 부여
- 데이터 랭킹, 페이징 처리에 활용
2. REPLICATE() 함수
목적
- 문자열을 지정된 횟수만큼 반복
- 패턴 생성에 유용
기본 문법
REPLICATE('반복문자', 반복횟수)예시
REPLICATE('* ', 5) -- "* * * * * "3. sys.objects 활용
특징
- 데이터베이스 모든 객체의 메타데이터 저장
- 행 생성을 위한 트릭으로 사용
행 생성 원리
SELECT TOP 20
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS RowNum
FROM sys.objects a
CROSS JOIN sys.objects b4. CTE (Common Table Expression)
목적
- 복잡한 쿼리를 단순화
- 임시 결과 집합 생성
기본 문법
WITH CTE이름 AS (
SELECT ...
)
SELECT ... FROM CTE이름5. CROSS JOIN
특징
- 두 테이블의 모든 행을 곱집합으로 결합
- 행 생성에 유용
예시
FROM 테이블1
CROSS JOIN 테이블2실제 문제 해결 쿼리에서 사용한 것들
(SELECT NULL): 더미 정렬 기준CROSS JOIN: 대량 행 생성ROW_NUMBER(): 순차 번호 부여REPLICATE(): 패턴 생성
성능 고려사항
- 대량 데이터 처리 시 주의
- 가능하면 실제 의미 있는 컬럼으로 정렬
48. Draw The Triangle 2
WITH NUMBER AS(
SELECT TOP 20 ROW_NUMBER () OVER(ORDER BY (SELECT NULL)) AS RN
FROM sys.objects a
CROSS JOIN sys.objects b
)
SELECT REPLICATE('* ', RN) AS StarPattern
FROM NUMBER
ORDER BY RN ASC;(47과 거의 동일)
49. Advanced Select: Occupations
되도 않는 쿼리 날렸었네요 ㅋㅋ ;;;
SELECT *
FROM OCCUPATIONS
PIVOT NAME FOR OCCUPATION IN ('Doctor', 'Professor', 'Singer', 'Actor') AS pvt;pivot을 이용한 정답은 아래와 같다.
WITH OccupationRanks AS (
SELECT
Name,
Occupation,
ROW_NUMBER() OVER (
PARTITION BY Occupation
ORDER BY Name
) AS RowNum
FROM OCCUPATIONS
)
SELECT
[Doctor],
[Professor],
[Singer],
[Actor]
FROM
(
SELECT Occupation, Name, RowNum
FROM OccupationRanks
) AS SourceTable
PIVOT
(
MAX(Name)
FOR Occupation IN ([Doctor], [Professor], [Singer], [Actor])
) AS PivotTable
ORDER BY RowNum;PIVOT 연산이 적용되면, 각 직업별로 Name이 열로 변환되는데, 이때 직업별로 여러 이름이 있을 수 있기 때문에, MAX(Name)을 사용하여 가장 알파벳 순으로 큰 값을 선택한다.
이게 무슨말이야..? 라고 묻는다면
아래 설명을 참고
결국 PIVOT 했을때
ROWNUM 별로 행이 생기는데 그 행에 들어갈DoctorProfessorSingerActor에 맞는 값들에 2개 이상이 들어가는 경우도 있는데 그걸
MAX()에서 필터링 해주는 것.

또 다른 정답
-- OCCUPATIONS 테이블 피벗 쿼리
WITH OccupationRanks AS (
-- 각 직업별로 이름을 알파벳 순으로 순위 매기기
SELECT
Name,
Occupation,
ROW_NUMBER() OVER (
PARTITION BY Occupation
ORDER BY Name
) AS NameRank
FROM OCCUPATIONS
)
-- 피벗 쿼리
SELECT
MAX(CASE WHEN Occupation = 'Doctor' THEN Name END) AS Doctor,
MAX(CASE WHEN Occupation = 'Professor' THEN Name END) AS Professor,
MAX(CASE WHEN Occupation = 'Singer' THEN Name END) AS Singer,
MAX(CASE WHEN Occupation = 'Actor' THEN Name END) AS Actor
FROM OccupationRanks
-- 가장 많은 이름을 가진 직업의 이름 수만큼 그룹화
GROUP BY NameRank
ORDER BY NameRank;위 쿼리에 대해서
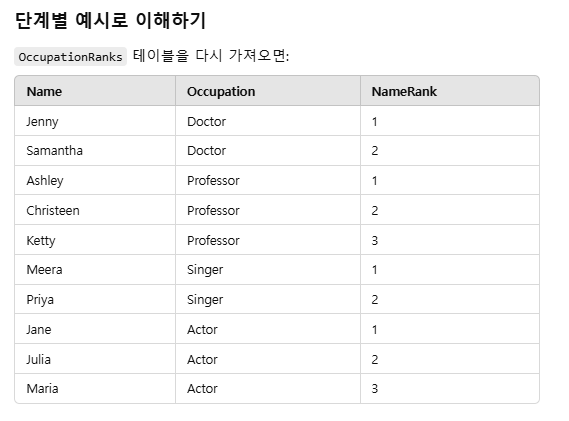
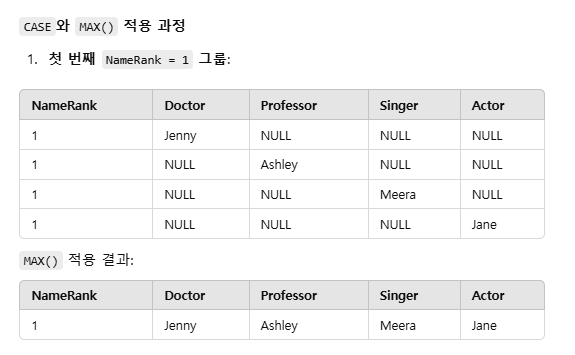
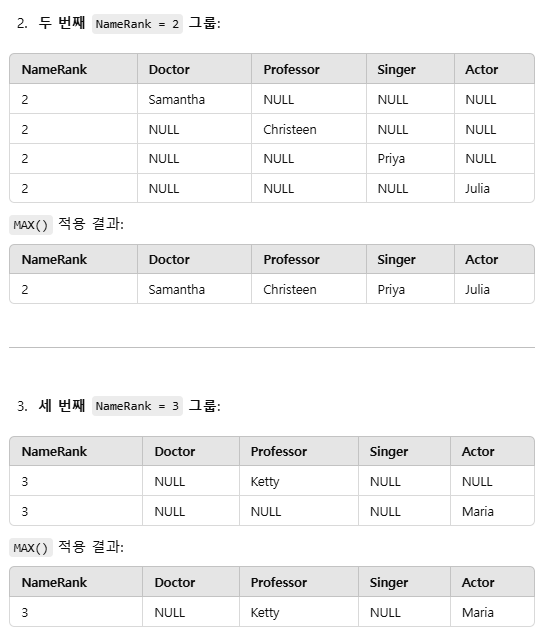
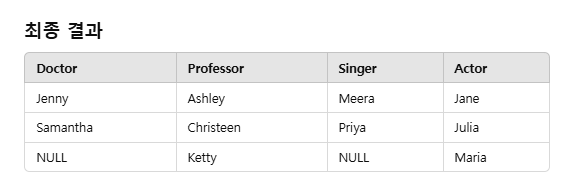
CASE 문:
특정 직업에 해당하는 값만 남기고 나머지는 NULL 처리.
MAX():
GROUP BY된 각 NameRank 그룹에서 NULL이 아닌 값 중 하나를 반환.
GROUP BY NameRank:
동일한 NameRank에 대해 각 직업별 이름을 한 행에 병합.
결과적으로 가장 큰 행 수에 맞춰 다른 열들이 부족하면 NULL로 자동 채워지는 것입니다.
- 최종적으로 내가 제출한 정답
WITH RN_OCC AS(
SELECT
Name,
Occupation,
ROW_NUMBER() OVER (PARTITION BY Occupation
ORDER BY Name) AS RN
FROM OCCUPATIONS
)
SELECT [Doctor], [Professor], [Singer], [Actor]
FROM RN_OCC
PIVOT(
MAX(Name)
FOR Occupation IN ([Doctor], [Professor], [Singer], [Actor])) AS PivotTable
ORDER BY RN;50. Advanced Select: New Companies
- 최초 작성 쿼리(으어 ;; 지저분해)
WITH TOTAL_TABLE AS (
SELECT C.company_code AS C, C.founder AS F, L.lead_manager_code AS L, S.senior_manager_code AS S, M.manager_code AS M, E.employee_code AS E
FROM Company C
INNER JOIN Lead_Manager L ON C.company_code=L.company_code
INNER JOIN Senior_Manager S ON L.lead_manager_code=S.lead_manager_code
INNER JOIN Manager M ON S.senior_manager_code=M.senior_manager_code
INNER JOIN Employee E ON M.manager_code = E.manager_code
ORDER BY C.company_code ASC)
END
SELECT (
TOTAL_TABLE.C,
TOTAL_TABLE.F,
COUNT(SELECT DISTINCT L
FROM TOTAL_TABLE),
COUNT(SELECT DISTINCT S
FROM TOTAL_TABLE),
COUNT(SELECT DISTINCT M
FROM TOTAL_TABLE),
COUNT(SELECT DISTINCT E
FROM TOTAL_TABLE)
)
FROM TOTAL_TABLE
GROUP BY C, F
ORDER BY C;이 쿼리의 문제점
1. 우선 틀림 ㅋㅋ
WITH구문에서는ORDER BY못씀
2.END이거 왜등장??
닫는 구문 없음 ;;END빼셈
3. COUNT는 하나의 값만 반환
물론 GROUP BY로 묶어주긴 했는데
COUNT구문 안에다가 서브쿼리를 넣어주면 여러 값을 반환하게 하는데 이게 아래와 같은 이유임
`COUNT()는 하나의 컬럼 또는 표현식을 대상으로 작동함. 즉, 이 함수는 단일 값 또는 단일 컬럼을 인자로 받아서 작동하는 함수이지, 서브쿼리로 여러 행을 반환할 경우에 해당 반환값을 인자로 받아 작동하는 함수가 아님.
따라서 그 여러 행으로 받는 서브쿼리의 경우에는 처리할 수 없음.
즉, 서브쿼리가 여러 값을 반환하는 경우에는 COUNT()는 이를 하나의 값으로 받아들일 수 없기 때문에 오류가 발생.

그래서 올바른 정답은 아래와 같다.
WITH TOTAL_TABLE AS (
SELECT C.company_code AS C,
C.founder AS F,
L.lead_manager_code AS L,
S.senior_manager_code AS S,
M.manager_code AS M,
E.employee_code AS E
FROM Company C
INNER JOIN Lead_Manager L ON C.company_code=L.company_code
INNER JOIN Senior_Manager S ON L.lead_manager_code=S.lead_manager_code
INNER JOIN Manager M ON S.senior_manager_code=M.senior_manager_code
INNER JOIN Employee E ON M.manager_code = E.manager_code
)
SELECT
C,
F,
COUNT(DISTINCT L) AS distinct_L,
COUNT(DISTINCT S) AS distinct_S,
COUNT(DISTINCT M) AS distinct_M,
COUNT(DISTINCT E) AS distinct_E
FROM TOTAL_TABLE
GROUP BY C, F
ORDER BY C;