
Python이란?
-
파이썬(Python)은 1990년 암스테르담의 귀도 반 로섬(Guido van Rossum)이 개발한 프로그래밍 언어
-
파이썬은 고대 신화에 나오는 파르나소스 산의 동굴에 살던 큰 뱀의 의미도 있어서 대부분 파이썬 책 표지나 아이콘에는 뱀 모양이 있있다.
왜 Python 일까?
-
파이썬은 인기가 높은 '언어'다.
-
파이썬은 다른 언어보다 '쉽다'.
-
파이썬은 '확장성'이 좋다.
Python의 공부 방법
-
Bottom up 방법
- 교과서식 차근 차근 공부 방법
- 파이썬 문법 ➡️ 데이터 분석 ➡️ 프로젝트
-
Top down 방법
- 목표를 설정한 뒤 필요한 기능을 배우는 방법
- 프로젝트 목적 설정 ➡️ 데이터 분석 방법론 정의 ➡️ 파이썬을 통한 분석 공부
⭐️ 본인 스타일에 따라 시작 방법을 설정하고 두 방법을 병행하는 것이 효과적
Python의 변수와 사칙연산
- 변수 = 특정 값을 저장하는 기호
#은 주석표시(Comment)입니다. 실행되지 않음, 코드에 설명을 추가할 때 사용
a = 1 # 숫자
b = 'name' # 문자- 사칙연산
| 연산자 | 설명 | 수식 예시 (단, a > b ) | 결과 (a = 10, b = 3) |
|---|---|---|---|
+ | 덧셈 | a + b | 13 |
- | 뺄셈 | a - b | 7 |
* | 곱셈 | a * b | 30 |
/ | 나눗셈 | a / b | 3.333… |
// | 몫(정수 나눗셈) | a // b | 3 |
% | 나머지 | a % b | 1 |
** | 거듭제곱 | a ** b | 1000 |
예시)
a = 10
b = 3
a+b # 결과: 13
b**2 # 결과: 9Python의 자료형(Type)
-
자료형(Type) = 모든 프로그래밍 언어를 다룰 때 처음에 정의하는 것 중 하나이며 변수 하나의 값이 어떤 종류인지 나타낸다.
-
파이썬의 자료형
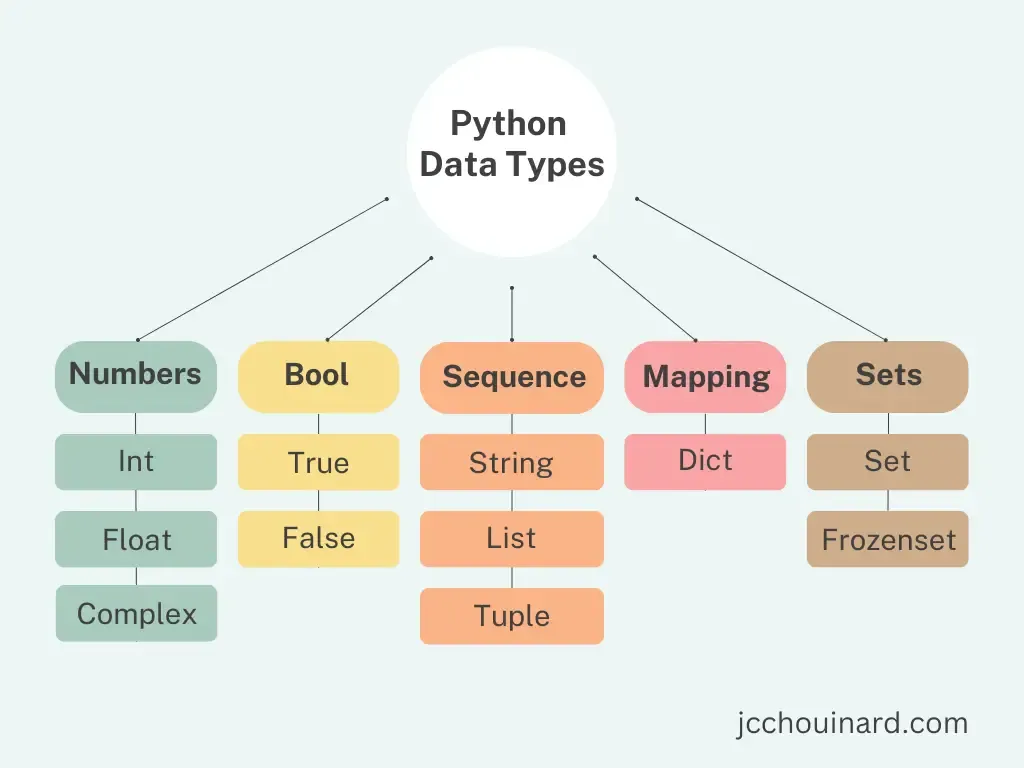
-
가장 많이 사용하는 자료형 = String, List, Dictionary
-
각 자료형의 표기법
✅ String : '' Or ""
✅ List : [ ]
✅ Dictionary : { : }
-
1. 문자열(String)
- 작은 따옴표 '' 또는 큰 따옴표 ""로 정의
- 문자형 자료는 말 그대로 '문자'를 저장
- 따옴표는 문자열의 시작과 끝을 표기하고 문자열 데이터에 포함되지 않는다.
예시)
my_str = '사과'
my_str
'''
사과
'''
print(type(my_str)) # <class 'str'>- 변수 할당
- 변수할당? 만든 자료형을 활용하기 위해 변수에 저장하는 것을 의미
- 변수명은 일반적으로 영문자로 기입하며 띄어쓰기는 허용하지 않기 때문에 언더바(_)로 대체 함
- my_str = '사과' 와 같이 정의하면 my_str변수명에 리스트 형태가 저장되며, type(my_str)라고 출력하면 str 라고 하는 자료형임을 알려줍니다.
- 인덱싱(indexing)과 슬라이싱(slicing)
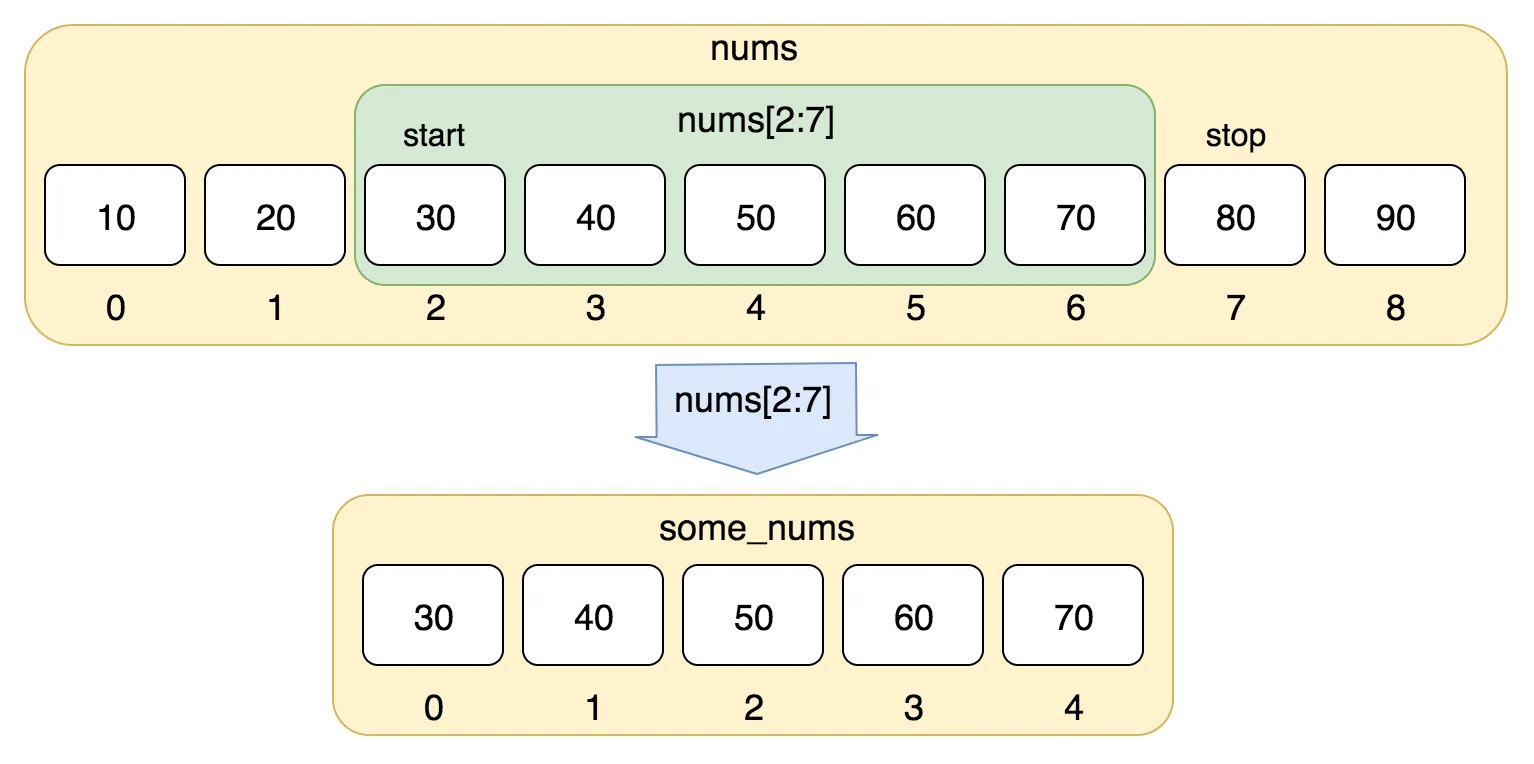
✅ 인덱스 = 자료형을 구성하는 순번
= 첫 번째 인덱스 값은 '0'이며, 마지막 인덱스 값은 '-1'이다.
= 인덱스 슬라이싱을 통해 필요한 자료를 추출할 수 있다.
예시)
my_str[0:1]
# 사- 변수 출력
- 변수출력? print 내장함수 사용
- 내장함수란? Python 창시자가 기본으로 넣어둔 함수 (반의어: 사용자 정의 함수)
- 문자열과 내장 함수
letter= 'alsidIEK39182lsie2'
# 인덱싱
letter[4] #결과값: d
letter[-1] #결과값: 2
# 슬라이싱
letter[:4] #결과 값: 'alsi'
letter[-3:-1] #결과 값: 'ie'
# 병합
let2= 'Hello Python'
output= letter + let2 #결과 값: 'alsidIEK39182lsie2Hello Python'
mul_output= let2 * 2 #결과 값: 'Hello PythonHello Python'
# upper() lower()
upps= letter.upper() # 대문자
lows= letter.lower() # 소문자
# join
','.join('adke21') # 결과값: a,d,k,e,2,1
# split() => 반환값은 리스트형태
# split() : () 를 기준으로 문자열을 쪼개어 준다.
a.split() # 공백을 기준으로 문자열을 분리 #'Hello','Python'
let3= "hello,python, Elice"
let3.split(', ') # 콤마+공백을 기준으로 분리
# ['hello,python', 'Elice']
# replace ()
let2.replace('Hello','') # 공백처리
# startswith() / endswith()
let2.startswith('H')2. 리스트(List)
- 1,2,3 이라는 자료를 담기 위해서 list()를 이용해 정의하거나 [] 대괄호를 이용해 정의할 수 있음 (후자가 더 편함)
#방법1 list 불러오기
list([1,2,3])
#방법2
my_str= [1,2,3]- 리스트와 내장 함수
a=[1,2,3,4,5]
b=['hello','life','today','happy']
c=['Hello',['python','hi'], (12,11,10) , 14]
# 인덱싱
a[4] #결과 값: 5
c[1] #결과 값: ['python', 'hi']
c[1][0] #결과 값: 'python'
# 슬라이싱
b[0:3] #결과 값: ['hello', 'life', 'today']
c[-2:] #결과 값: (12,11,10), 14
# 리스트의 덧셈과 곱셈 ( 숫자, 문자열 )
a+b #결과 값: [1, 2, 3, 4, 5, 'hello', 'life', 'today', 'happy']
b*2 #결과 값: ['hello', 'life', 'today', 'happy', 'hello', 'life', 'today', 'happy']
# len(리스트): 길이 구하기
len(a) #결과 값: 5
len(c) #결과 값: 4
a=[1,2,3,4,5]
# 리스트 삽입/수정하기
a[2]=22
a #결과 값: [1, 2, 22, 4, 5]
# insert(인덱스, 값)
a.insert(3, 33)
a #결과 값: [1, 2, 22, 33, 4, 5]
# del 리스트[인덱스]
a= [1,2,22,4,5]
del a[3:-1]
a #결과 값: [1, 2, 22, 5]
# append(값)
a.append([100])
a #결과 값: [1, 2, 22, 5, [100]]
# sorted() - 내장함수 / .sort()- 메소드
##(메소드(method): 어떤 자료형(객체)에 붙어 있는 함수)
aa=[1,4,5,2,3]
aa.sort() #결과 값: [1,2,3,4,5]
sorted(aa)
# [1,2,3,4,5]
# reverse
aa.reverse()
# remove(값)
aa=[5,4,3,2,1]
aa.remove(3) #결과 값: [5, 4, 2, 1]
# pop(인덱스)
aa=[5,4,2,1]
aa.pop()✅ sorted() vs .sort()
| 항목 | sorted() | .sort() |
|---|---|---|
| 종류 | 내장 함수 (built-in function) | 리스트 전용 메소드 (method) |
| 원본 변경 | ❌ 원본 리스트는 변경되지 않음 | ✅ 원본 리스트 자체가 변경됨 |
| 사용 대상 | 리스트뿐 아니라, 문자열, 튜플, 딕셔너리 등 반복 가능한 객체 | 리스트(list) 전용 |
- 튜플(Tuple)
- 튜플은 요소들을 '()'로 감싸고 있어 List와 비슷한 역할을 하지만 다른 특성을 가지고 있음
- '()'으로 element를 둘러싼다.
- element들의 순서가 있다.
- element의 생성, 삭제, 수정이 불가능하다
a = (1, 2, 3)
# 인덱싱
a[0]
# 슬라이싱
a[1:]
# 사칙연산
b = (3, 4)
b * 2
# 튜플의 길이
len(a)3. 딕셔너리(Dictionary)
- 딕셔너리는 key-value 형태로 정의된 자료
✅ key: 딕셔너리의 인덱스와 같은 개념이고 따라서 인덱스로 불러오기는 되지 않으며 특정 key값으로 값을 접근해야 합니다.
✅ value: 말 그대로 key와 엮어 있는 값
예시)
gdp_dict = {'한국': 3000, '미국': 4000, '대만': 3500}
print(gdp_dict)
'''
{'한국': 3000, '미국': 4000,'대만':3500}
'''- 딕셔너리와 내장함수
# 딕셔너리와 내장 함수
a = {"name": "Alice", "age": 25, "city": "Seoul"}
# 값 읽기
a["name"] #결과 값: 'Alice'
a["city"] #결과 값: 'Seoul'
# 값 추가
a["job"] = "Engineer" # 새로운 키-값 추가
a
a = {"name": "Alice", "age": 25, "city": "Seoul", "job":"Engineer"}
# 값 수정
a["age"] = 30 # 'age' 값 수정
a
# del 삭제
del a["city"] # 'city' 키-값 삭제
a
# keys() - 키만 추출
a.keys()
# dict_keys(['name', 'age', 'job'])
# values() - 값만 추출
a.values()
# dict_values(['Alice', 30, 'Engineer'])
# items() - 키-값 쌍 추출
a.items()
# dict_items([('name', 'Alice'), ('age', 30), ('job', 'Engineer')])
# clear() - 모든 요소 삭제
a.clear()
a # {}
# in 키워드 - 키 존재 여부 확인
a = {"name": "Alice", "age": 25, "city": "Seoul", "job" :"Engineer"}
"job" in a # True
"hobby" in a # False⭐️ dict_keys, dict_values는 새로운 자료형처럼 보일 수 있지만, 형태를 표현하기 위한 자료형이고 **list자료형과 유사**합니다. 따라서 **인덱싱, 슬라이싱 등 동일하게 자료를 자르고 출력할 수 있습니다.**
- Set와 딕셔너리 비교
- set는 중복을 허용하지 않는 데이터형
# Set
my_set = {1, 2, 3, 4}
# 중복 제거
my_set.add(3) # 중복된 값 추가해도 변화 없음
print(my_set) # {1, 2, 3, 4}a = [1,2,3,4,5,3,4,2,1,2,4,2,3,1,4,1,5,1]
a_set = set(a)
print(a_set) #결과 값: [1,2,3,4,5]➡️ 딕셔너리: 키-값 쌍으로 데이터를 관리하며 데이터를 검색하거나 매핑 관계를 저장하는데 효율적
➡️ 세트: 고유한 값의 집합을 관리하며, 중복 제거 및 집합 연산에 적합
