
🌻오늘의 TMI🌻
SQL 기초 강의에서 들었던 내용을 내가 이해하기 쉽게 질답형식으로 작성했는데 나에게는 이렇게 정리하는 방식이 잘 맞는 것 같다.
마지막 강의까지 정리하고 나면 굉장히 뿌듯할 것이다.
그리고 복습 또 복습! 예문 열심히 풀어서 개념을 이해하자!
데이터에 값이 없는 경우에는 어떻게 처리하나요?
데이터에 모든 값이 완벽하게 들어가 있을 것이라고 생각하면 안된다.
입력이 누락된 값도 있을 것이고 또는 사용할 수 없는 데이터도 들어있을 수 있다.
그럴 때는 데이터를 정제하는 과정을 거쳐야한다.
이전에 사용했던 모든 지식들을 동원해서 쿼리문을 작성해 볼 필요가 있다.
- Mysql에서는 사용할 수 없는 값일 때 해당 값을 연산에서 제외시켜 숫자 '0'으로 간주한다.
SELECT restaurant_name
AVG(rating) AS average_of_rating
AVG(IF(rating<>'Not given', rating, null) AS average_of_rating2
FROM food_orders
GROUP BY restaurant_name위의 예시를 설명하면
- average_of_rating 은 'Not given'이라고 표시되어 있는 값을 0으로 쳐서 해당 값까지 모든 개수를 포함해 평균 값으로 계산한 값이다.
Not given,Not given,1,2,3 이라는 순위 값이 있다면 0,0,1,2,3을 더한 값 6을 5로 나눈 값이 출력된다.
- average_of_rating2 는 'Not given' 이라고 표시되어 있는 값을 제외해서 남은 값들의 평균 값을 계산한 것이다.
마찬가지로 Not given,Not given,1,2,3 이라는 순위 값이 있다면
1,2,3만 더한 6을 3으로 나눈 값이 출력된다.
둘 중 어느 것을 사용할지는 상황을 봐가면서 사용해야한다.
엑셀처럼 이쁘게 행과 열을 정렬하고 싶을 때는 어떻게 하나요?
SQL에서도 엑셀처럼 데이터를 가공할 수 있다.
예쁜 Pivot table을 만들면 굳이 데이터를 다른 곳으로 옮겨서 처리할 필요가 없어진다.
단, 나 혼자 데이터를 편하게 볼 때만이다. 발표를 해야하거나 보고를 올릴 때는 더 예쁘게 시각화해서 보여야한다는 점 잊으면 안된다.
- Pivot table이란? 2개 이상의 기준으로 데이터를 집계할 때 보기 쉽게 배열하여 보여주는 것
<Pivot table 예시>
집계 기준: 일자, 시간
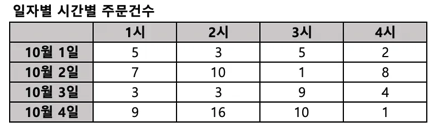
이렇게 정렬된 표를 만들어보자.
나에게 강남의 음식점 별 주문 정보와 결제 정보 두 가지의 데이터 테이블이 있다고 생각해보자.
이때 나는 음식점 별 15시부터 20시 사이의 시간의 주문 건수 데이터를 20시 주문건수 기준 내림차순으로 가져오고 싶다.
SELECT restaurant_name
,MAX(IF(hh='15', cnt_order, 0)) AS "15"
,MAX(IF(hh='16', cnt_order, 0)) AS "16"
,MAX(IF(hh='17', cnt_order, 0)) AS "17"
,MAX(IF(hh='18', cnt_order, 0)) AS "18"
,MAX(IF(hh='19', cnt_order, 0)) AS "19"
,MAX(IF(hh='20', cnt_order, 0)) AS "20"
FROM
(
SELECT restarant_name
,SUBSTR(p.time,1,2) AS hh
,count(1) AS cnt_order
FROM food_orders AS f INNER JOIN payments AS p ON f.order_id=p.order_id
WHERE SUBSTR(p.time,1,2) BETWEEN 15 and 20
GROUP BY restaurant_name
,SUBSTR(p.time,1,2) AS hh
) AS a
GROUP BY restaurant_name
ORDER BY 7 DESC갑자기 긴 쿼리문이 나와도 당황하지 말자.
하나씩 풀이하면 결국 예시문장과 같은 말이라는 것을 알 수 있다.
서브 쿼리문과 조건문, GROUP BY, 특정 문자만 가져오기, 정렬하기
등 다양한 문법이 들어가 있다.
-
서브 쿼리문에는 시간 데이터의 첫 번째 글자와 두 번째 글자만 불러 올 것이며 그걸 hh(시간) 이라고 명명한다.
-
그리고 두 가지 테이블에서 공통적으로 있는 order_id라는 데이터를 교집합으로 묶어서 데이터를 불러온다.
-
15에서 20사이에 있는 숫자의 첫 번째와 두 번째 문자만 불러온다.
-
음식점 이름과 hh(시간)로 해당 데이터를 그룹화 시킨다.
-
메인 쿼리문에서는 최대 15부터 20까지에 있는 데이터가 있을 때 참인 경우와 거짓인 경우 어떻게 데이터를 처리할 지 구분한다.
-
그리고 음식점 별 이름으로 그룹화 시키고 7번째 열에 있는 20시의 데이터만 내림차순으로 정리한다.
[예시 이미지]
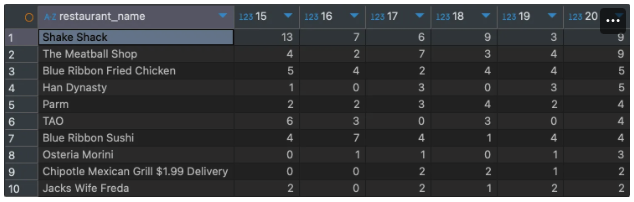
이렇게 데이터를 가지고 원하는 Pivot table을 만들 수 있다는 것을 명심하자.
항상 저렇게 긴 쿼리문을 가지고 써야하나요?
데이터를 처리하는 시간까지 생각한다면 서브쿼리문은 비효율적으로 보일 수도 있다.
그래서 SQL에서도 업무시간을 단축시켜 줄 수 있는 여러가지 문법들을 제공하고 있다.
그걸 'Window Funtion' 이라고 한다.
Window Funtion의 기본 구조는 아래와 같다.
window_function(argument) over (partition by 그룹 기준 컬럼 order by 정렬 기준)- Window_funtion : 기능명 (Rank, Sum 등)
- argument : 함수에 따라 작성하거나 생략
- partition by : 그룹을 나누기 위한 기준 (group by 절과 유사)
- order by: 정렬할 컬럼 기준
아직 이해가 잘 안간다면 간단하게 순위를 매겨보는 예시를 들어보자.
음식 타입별로 주문 건수가 가장 많은 상점 3개의 데이터를 가져오고 싶다.
SELECT cuisine_type
,restaurant_name
,order_count
,rank AS "순위"
FROM
(
SELECT cuisine_type
,restaurant_name
,RANK()OVER(PARTITION BY cuisine_type ORDER BY order_count AS c
FROM
(
SELECT cuisine_type
,restaurant_name
,conunt(1) AS order_count
FROM food_orders
GROUP BY cuisine_type
,restaurant_name
) AS a
) AS b
WHERE RANK<=3
ORDER BY 1,4더 복잡해진 것 같다?
아니 이제 내 눈에 익어야 할 구조들이 들어와야한다.
[결과 데이터]
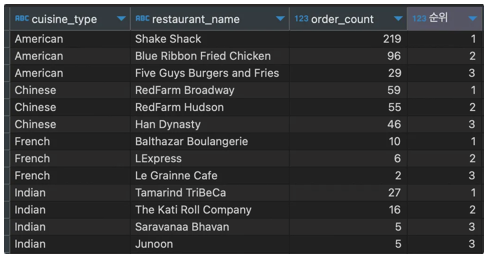
-
a 쿼리문은 음식타입과 음식점 이름별로 그루핑을 진행했다.
-
b 쿼리문은 음식타입과 음식점 이름별로 구분하고 음식타입별로 구분해서 순위를 매겼다.
-
메인 쿼리문은 음식타입, 음식점 이름, 주문 건수, 순위 데이터를 조회하였다.
-
where 조건으로 rank가 3위까지 조회 될 수 있게 하였다.
- 1,2는 3보다 작은 숫자니까 부등호가 저렇게 쓰이는 것이 옳다.
- 그리고 order by로 음식점별 이름과 순위별로 정렬될 수 있게 만들었다.
이렇게 배운 것들이 하나씩 녹아있는 예시를 많이 작성하다보면 어느새 내가 원하는 데이터를 뽑아오는 쿼리문을 작성하고 있는 나 자신을 발견하게 된다.
그러면 날짜 데이터는 어떻게 처리하나요?
데이터에 날짜를 지정하거나 조건에 날짜를 사용해야할 때는 반드시 있다.
그럴 때 사용할 수 있는 기능이 있다.
먼저 날짜 데이터에 대한 이해가 필요하다.
- 문자 타입(character), 숫자타입(decimal) 과 같이 날짜 데이터도 특정한 타입을 가지고 있다.
- 년, 월, 일, 시, 분, 초 등의 값을 모두 가지고 있으며 목적에 따라 '월', '주', '일' 등으로 포맷을 변경할 수 있다.
[예시]
yyyy-mm-dd 형식을 date type으로 변경하기
SELECT date(date) AS date_type
FROM date_table[예시2]
date type을 date_format을 이용해서 년,월,일,요일로 조회하기
- 년: Y(4자리), y(2자리)
- 월: M,m
- 일: d,e
- 요일: w
SELECT date(date) AS date_type
,date_format(date(date)), '%Y') AS "년"
,date_format(date(date)), '%m') AS "월"
,date_format(date(date)), '%d') AS "일"
,date_format(date(date)), '%w') AS "요일"
FROM date_table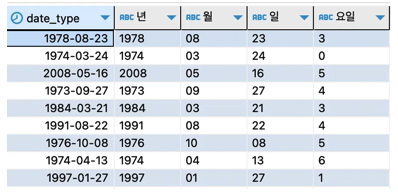
년, 월, 일, 요일로 데이터가 나뉘어서 출력된 것을 확인할 수 있다.
- 요일은 0은 일요일 1부터 6까지 월요일부터 금요일로 표기되었다.
요일 데이터를 가지고 기간 데이터를 추출하는 것도 중요하기 때문에 앞으로 잘 알아놓으면 도움이 된다.
오늘의 SQL 요약
▶ 역시나 SQL의 영역을 확장해 나가는 건 어렵다!
▶ 데이터 값이 누락됐을 때 null의 값을 포함해서 사용할 것인지 아니면 제외하고 사용할 것인지 잘 결정해야 한다.
▶ 2개 이상의 기준으로 데이터를 조회할 때는 Pivot table을 만들어서 자체적으로 가시성 있게 만들자.
▶ 쿼리문이 길다고 겁먹지 말자! 하나씩 뜯어보면 무슨 데이터를 뽑아올지 보인다.
- 그럼에도 무슨 데이터를 뽑는 건지 모를 때는 쿼리문을 작성할 때 꼭 '주석'을 달도록 하자!
▶ rank문도 써서 순위를 매길 때 잘 쓰자. 순위를 나열 할 때는 숫자 기준으로 조건문을 써야한다.
- 3위 이상의 데이터를 조회할 때
ex) WHERE RANK=<3 - 2위 미만의 데이터를 조회할 때
ex) WHERE RANK>2
▶ date_format으로 원하는 날짜 데이터도 가공할 수 있다.
