
SQL 집계함수
집계함수란?
- 데이터를 요약해서 보고 싶을 때 쓰는 함수
- 전체 데이터를 대상으로 사용하거나, 특정 컬럼을 기준으로 사용할 수 있다.
- 집계함수는 SELECT문에서 사용되며 종류는 5가지가 있다.
- COUNT : 테이블의 행 수 반환
- SUM : 테이블의 열 합계 반환
- AVG : 테이블의 열 평균 반환
- MIN : 테이블의 열 최소값 반환
- MAX : 테이블의 열 최대값 반환
✅ 집계함수는 동시에 사용하여 한눈에 데이터 셋을 볼수 있다.
✅ 데이터를 요약해서 살펴보면서 통계적 의미를 찾을 수 있다.
SQL 그룹화
그룹화란?
- 전체 데이터를 특정 기준에 따라 요약할 때 쓰는 문장
➡️ GROUP BY
- 집계함수에 그룹(기준)이 더해진 개념
- 특정 컬럼을 대상으로 데이터를 요약해서 비교하고 싶을 때 사용한다.
[작성 방법]
- SELECT 뒤 기준컬럼 작성
- 집계함수 작성(COUNT, SUM, AVG, MIN, MAX)
- WHERE 절 뒤 GROUP BY 기준 컬럼 작성(WHERE절은 생략 가능)
⭐️ SQL의 작동 순서
FROM → ON → JOIN → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY
❓GROUP BY 쓰는 법❓
▶️ 집계함수와 GROUP BY 절을 함께 사용하는 SQL문
SELECT
기준컬럼(pk),
집계함수(조건컬럼을 기준으로 여러개의 집계함수 동시사용 가능)
FROM 테이블명
WHERE 조건 #(생략가능)
GROUP BY 기준컬럼(pk)
;❓에러가 날 경우❓
▶️기준컬럼과 집계함수를 작성하고 GROUP BY를 사용하지 않을 때
select 기준컬럼, 집계함수(조건컬럼을 기준으로 여러개의 집계함수 동시사용 가능)
from 테이블명
where 조건 #(생략가능)
;➡️ HAVING
- HAVING은 GROUP BY절에 의한 결과를 필터링 할 때 사용
- SQL구문에서 GROUP BY절 뒤에 위치
⭐️ WHERE절과 HAVING의 차이
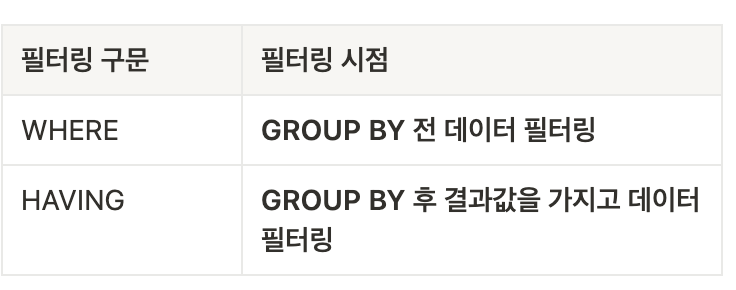
❓HAVING 쓰는 법❓
▶️집계함수, GROUP BY절, HAVING을 함께 사용하는 SQL문
SELECT
기준컬럼,
집계함수(조건컬럼을 기준으로 여러개의 집계함수 동시사용 가능)
FROM 테이블명
WHERE 조건 #(생략가능)
GROUP BY 기준컬럼
HAVING 조건식
;SQL 서브쿼리
서브쿼리란?
- 쿼리 속의 쿼리
- 컬럼들을 활용한 많은 연산을 하는 경우, SUBQERY는 이것을 순차적, 구조적으로 기록하는 역할을 수행
- 복잡한 연산을 단계적으로 진행함
✅ 서브쿼리 사용 이유
- N번의 쿼리문 실행을 1번의 쿼리문으로 실행하기 위해 쿼리의 결과값을 가지고 추가 연산을 하기 위해 사용
✅ 실행 순서
-
서브쿼리 실행(안쪽에 위치한 쿼리) → 메인쿼리(바깥쪽에 위치한 쿼리) 실행
-
쿼리의 가장 안쪽부터, 바깥쪽 쿼리를 실행하며 최종 결과값을 반환
✅ 특징
- ()안에 SELECT, FROM을 명시해줘야함
- 쿼리 마지막에 ; 기호를 사용할 수 없음
- ORDER BY를 사용할 수 없음
[서브쿼리의 종류]
➡️ 중첩(일반) 서브쿼리
- WHERE절에서 사용
- 서브쿼리의 결과에 따라 달라지는 조건절
SELECT *
FROM marketer_sql_theglory
WHERE 나이 >
(
SELECT 나이
FROM marketer_sql_theglory
WHERE 이름='홍길동'
)
;▶️해석: '홍길동'의 나이 데이터가 수정되어도 쿼리를 수정할 필요 없이 조건절에 있는 서브쿼리에 의해 값이 새롭게 갱신된다.
➡️ 스칼라 서브쿼리
- SELECT절에 사용
- 하나의 컬럼처럼 사용
- 스칼라 서브쿼리를 이용하기 위해서는 서로 다른 두 테이블이 필요
SELECT
name
,age
,(
SELECT count(*)
FROM user_basic2
WHERE user_basic1.name = user_basic2.name
) AS same_name_cnt
, (
SELECT SUM(payment)
FROM user_basic2
WHERE user_basic1.name = user_basic2.name
) AS same_name_sumamount
FROM user_basic1
;▶️ 해석:
-
user_basic1의 name과 user_basic2의 name이 일치하는 경우를 COUNT 하여 'same_name_cnt' 컬럼으로 변환
-
user_basic의 이름과 user_basic2의 name이 일치하는 경우의 결제금액(payment)을 SUM하여 'same_name_sumamount' 컬럼으로 변환
➡️ 🔥인라인 뷰🔥(가장 많이 사용)
- FROM 절에서 사용
- 하나의 테이블처럼 사용
- AS구문을 사용해서 별칭을 반드시 기재해야 함
- JOIN과 UNION시 가장 유용하게 사용
SELECT sub.age, sub.job
FROM
(
SELECT *
FROM user_basic
WHERE age >= 33
)AS sub▶️ 해석: 나이가 33세 이상인 모든 데이터 중 나이, 직업 컬럼 값 변환하기
오늘의 라이브세션 인사이트
⭐️ 집계함수, 그루핑, 서브쿼리에 대한 개념이 이해되었다.
⭐️ 과제를 통해서 개념에 대해서 이해할 수 있는 것을 기대할 수 있다. (이해 ▶︎ 응용)
