
배경 설명
굳이 잘 돌아가던 배포 시스템을 변경한 이유에 대해 말하기 전에 배경설명을 하자면, 우리 회사는 MAU가 160만이 넘는 쇼핑몰을 운영하고 있다.
따라서 무중단 배포를 할 수 있는 Blue/Green 배포 전략이 기본이 되었고 이는 CodeDeploy 에 blue target 과 green target 을 등록해 구현이 되어있었다. 즉 ECS 배포.
또한 서비스 종류가 많지 않아 MSA처럼 잘게...도 아니고 아래 이미지(출처)처럼 아예 백엔드, 프론트엔드 서버를 따로 나누지 않고 하나의 서버에 배포를 한다. (팀 자체도 백/프론트로 역할 분담이 되어 있지 않다.)
기존 배포 과정
기존엔 배포 명령어 실행 후 아래와 같은 순으로 배포가 이뤄졌다.
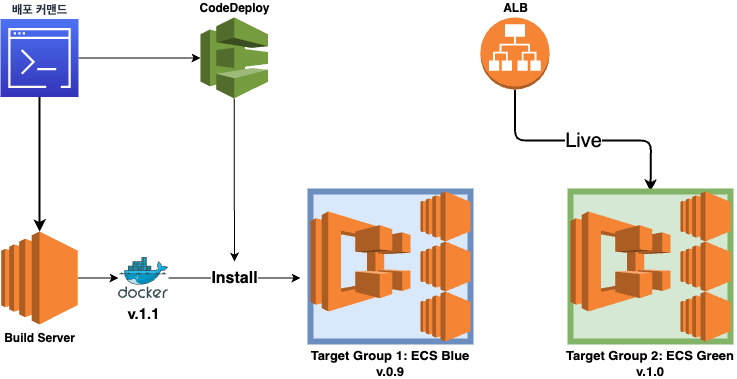
v1.0이 Green에서 live되고 있고 v1.1 을 배포하려는 상황이라 가정하면
- 빌드 서버라고 명명한 EC2 서버 한 대에서 도커 이미지 빌드
- 1 완료 후 ECS 용 task 를 작성 및 등록
- 2를 바탕으로 CodeDeploy에서 배포 실행
1) Blue용 인스턴스에 1의 도커 이미지 다운로드 및 설치
2) BeforeAllowTraffic 훅(단계)에서 마이그레이션 실시
3) Application Load Balancer(ALB) 에서 타겟 그룹을 Green에서 Blue로 전환
4) Terminate original(Green) task set
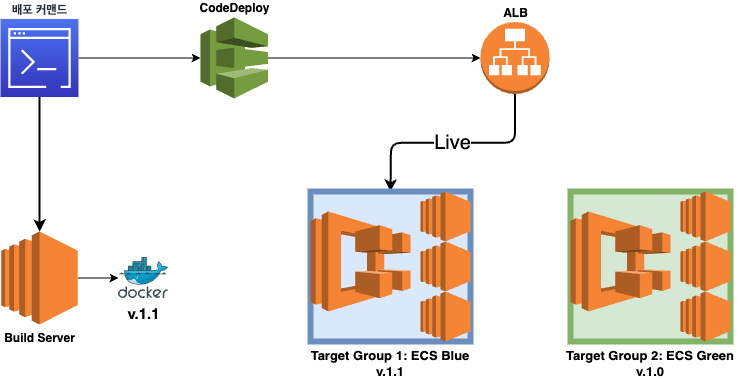
일반적인(?) Blue/Green 배포 방식에선 3-3 이전 혹은 이후에, 일부 포트를 열거나 Blue 인스턴스 일부만 열어서 동작에 문제가 없는지 검증한 후, 문제가 있다면 v1.0 으로 롤백 없으면 배포 마무리 같은 식으로 진행이 될텐데 우리 팀은 그런 세팅이 없었다.
추측하기로는 두 가지 이유가 있는데,
첫째, 3-2 과정에서 보듯 우리 팀은 모델 스키마 변경 등의 프로덕션 DB에 대한 마이그레이션을 배포 과정 중에 진행한다. 이미 마이그레이션이 일어난 상황에서 구 버전의 서비스를 운영하면 어차피 문제가 생기기 때문에 3-3 이후의 rollback은 의미가 없고,
둘째, 팀 문화 자체가 문제 예방보다는 해결 쪽에 초점이 맞춰져 있어서...라고 생각한다.
오해할까봐 첨언하는데, 배포 전에 유닛/마이그레이션/브라우저 테스트는 자동화가 되어 있다.
그래서 왜 바꾸려고??
식겁해야 알게 되는 것들..
지난 3월에 서비스를 정식으로 오픈한 이후에도 수개월 동안 기존 배포 시스템으로 잘 먹고(?) 살았다.
참고로 배포 커맨드 실행 후 완료까지 7분 정도 소요되는데 이에 대해 CTO가 배포 속도가 느리다고 종종 불만을 표출했지만, 난 딱히 문제 의식이 체감되진 않았다. 다른 회사 다니는 전직장 동료들에게 물어보니 비슷하거나 그 이상으로 걸린다고 이야기를 하고 있고.
그런데 어느날 로그 관련해 nginx 설정을 변경할 일이 있었고, 이게 문제를 일으켜 실 서비스가 먹통이 되는 일이 발생했다.
문제 파악 후 바로 재배포를 했으나 실수가 있어 다시 배포.
그렇게 배포 2회(약 15분) + 문제 파악(α)이 걸리는 동안 서비스가 중단되는 대사건을 겪고 나서야, 배포가 오래 걸리는 데 대한 리스크를 실감할 수가 있었고 배포 전략을 변경하는 데 대한 공감대가 형성되었다.
참고로 당시는 브라우저 테스트 시에 nginx까지 재시작하지는 않아 자동화된 테스트에서 걸러지지 못 했는데, 이젠 테스트도 실배포와 동일하게 돌아가서 동일한 문제가 발생하면 배포 전에 알아챌 수 있는 상황이다.
또다른 이유
추가적으로 마이너한 이유일 수도 있고 아닐 수도 있는데,
기존 blue/green 전환을 위해서는 blue 용 인스턴스와 green 용 인스턴스가 항상 켜져있어야했다. 예를 들어, 위의 그림과 같이 하나의 타겟 그룹(ECS)에 인스턴스가 3대가 필요하다면, 새로운 배포를 위해선 추가 3대가 늘 대기 상태여야했는데 그것도 낭비라면 낭비인 상황.
그리고 이건 이후 응답속도 최적화 테스트를 하다가 발견한 건데 기존엔 약간의 성능 이슈도 있는 상황이었다.
이제 어떻게 전환했는데 구체적으로 파보도록 하자.
