VIEW
- SELECT 쿼리문을 저장한 객체로 가상테이블이라고 불림
- 원본 테이블을 참조해서 보여주는 용도
- 실질적 데이터 저장X, 쿼리만 저장되어 있다.
- 실제 보여지는 것은 원본 테이블의 데이터
- 데이터를 쉽게 읽고 이해할 수 있도록 돕는 동시에, 원본 데이터 보안 유지
- 테이블을 사용하는 것과 동일하게 사용 가능
- 뷰를 통해 업데이트 하지 않는 것이 바람직 함
- 별칭을 사용할 경우, 원본 컬럼명 사용 불가 → 별칭 조회만 가능 (은닉화)
-- VIEW 생성
CREATE VIEW hansik AS
SELECT
menu_code
, menu_name
, menu_price
, category_code
, orderable_status
FROM tbl_menu
WHERE category_code = 4;
-- 생성된 VIEW 조회
SELECT * FROM hansik;
-- VIEW 삭제
DROP VIEW hansik;
- 베이스 테이블의 정보가 변경되면 VIEW의 결과도 같이 변경
VIEW를 통한 DML
-
VIEW를 통한 DML 작업은 베이스 테이블에도 영향
-
insert
- VIEW는 AUTO_INCREMENT가 없으므로 pk 컬럼의 값을 지정해 주어야 함
-
delete
-
OR REPLACE 옵션
: 테이블을 DROP하지 않고 기존의 VIEW를 새로운 VIEW로 쉽게 다룰 수 있음CREATE OR REPLACE VIEW hansik AS SELECT menu_code AS '메뉴코드' , menu_name '메뉴명' , category_name '카테고리명' FROM tbl_menu a JOIN tbl_category b ON a.category_code = b.category_code WHERE b.category_name = '한식';
-
VIEW로 DML 명령어로 조작이 불가능한 경우
- 사용된 SUBQUERY에 따라 DMB 명령어로 조작이 불가능할 수 있음
- 뷰 정의에 포함되지 않은 컬럼을 조작하는 경우
- 뷰에 포함되지 않은 컬럼 중에 베이스가 되는 테이블 컬럼이 NOT NULL 제약조건이 지정된 경우
- 산술 표현식이 정의된 경우
- JOIN을 이용해 여러 테이블을 연결한 경우
- DISTINCT를 포함한 경우
- 그룹함수나 GROUP BY 절을 포함한 경우
INDEX
- 데이터 검색 속도를 향상시키는 데이터 구조로 데이터를 빠르게 조회할 수 있는 포인터를 제공
- 데이터를 찾을 때 전체 테이블을 검색하는 대신 인덱스를 통해 검색을 하므로 속도가 더 빠름 -> 검색 성능 ↑
- 주로 WHERE절의 조건이나 JOIN 연산에 사용되는 컬럼에 생성
- 데이터 저장 공간을 차지, 데이터가 변경될 때마다 인덱스 갱신
CREATE INDEX idx_name ON phone (phone_name);
-- 복합 인덱스 생성
CREATE INDEX idx_name_price ON phone (phone_name, phone_price);
SHOW INDEX FROM phone;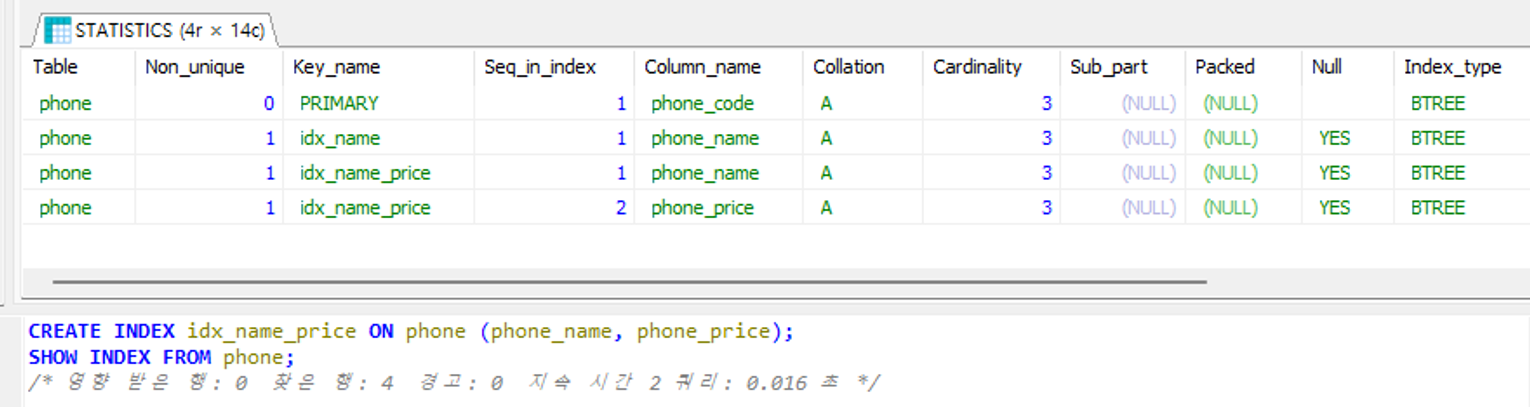
-
인덱스 단점
- 추가 작업 필요
- 추가 저장 공간 필요
- 잘못 사용하는 경우, 성능 저하
-
인덱스 최적화(재구성)
- 인덱스 최적화(재구성)은 인덱스가 파편화되었거나, 데이터의 대부분이 변경된 경우에 유용
- 인덱스의 성능을 개선하고, 디스크 공간을 더 효율적으로 사용
- 인덱스를 재구성하는 동안 해당 테이블은 잠길 수 있으므로, 주의해서 수행
- 'ALTER TABLE' 명령어를 사용해서 재구성
ALTER TABLE phone DROP INDEX idx_name; ALTER TABLE phone ADD INDEX idx_name(phone_name); - MySQL의 InnoDB 엔진을 사용하는 경우 -> OPTIMIZE TABLE 명령을 사용하여 테이블과 인덱스를 최적화 가능
OPTIMIZE TABLE phone; - 인덱스 삭제
DROP INDEX idx_name ON phone;
인덱스를 어느 Column에 사용하면 좋은지?
-
index는 where 절에서 자주 조회되고, 수정 빈도가 낮으며, 카디널리티는 높고, 선택도가 낮은 column을 선택해서 설정하는 것이 가장 좋음.
기준 적합성 카디널리티(Cardinality) 높을수록 적합 (데이터 중복이 적을수록 적합) 선택도(Selectivity) 낮을수록 적합 조회 활용도 높을수록 적합 (where 절에서 많이 사용되면 적합) 수정 빈도 낮을수록 적합 -
insert / update / delete 작업 시, 데이터에 변화가 생기기 때문에 index에서는 매번 정렬을 다시 함 -> 수정 빈도 낮을 수록 적합
-
데이터 양이 많을 수록 index로 인한 성능 향상이 더 큼
-
한 table에 index가 너무 많은면 데이터 수정시 소요되는 시간이 너무 길어질 수 있음
Index 구조
-
Btree, B+tree, Hash, Bitmap 등으로 구현
-
대표적인 구조는 B+tree
[MySQL] B-Tree로 인덱스(Index)에 대해 쉽고 완벽하게 이해하기 -
b+tree는 O(logn)으로 더 느린데 왜 index는 hash table이 아니라 b+tree로 구현 되는 이유
- hash table은 값이 정렬되어 있지 않아서 부등호를 사용하는 쿼리에 대해서는 비효율적
TRIGGER
- 테이블에서 발생하는 특정 이벤트(INSERT, UPDATE, DELETE)가 발생했을 때 자동으로 실행되는 데이터베이스 객체
- 주요 사용 목적
- 데이터의 무결성을 유지하고 복잡한 비즈니스 로직을 처리
- 단점
- 트리거가 많아질수록 데이터베이스의 복잡성과 유지 관리의 어려움 증가 + 성능 문제
- 트리거로 인한 자동화 처리가 예기치 않은 결과를 초래할 수도 있음
- 트리거의 종류
- BEFORE 트리거
- 이벤트가 발생하기 전에 실행
- 데이터의 유효성 검사나 변형에 주로 사용
- AFTER 트리거
- 이벤트가 발생한 후에 실행
- 로깅, 알림 전송 등의 작업에 적합
- BEFORE 트리거
DELIMITER //
CREATE OR REPLACE TRIGGER [트리거명]
BEFORE|AFTER [이벤트 타입]
ON [테이블명]
FOR EACH ROW
BEGIN
END//
DELIMITER ;
아뇨 소혠데요-