
RNN으로 성능이 많이 안나와서 생각해낸 방법인 LSTM을 이용해서 모델을 학습 시켜 보았다.
데이터 셋은 기존의 RNN을 이용할 때 만든 데이터셋을 사용하였다.
LSTM 학습
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.models import load_model
import tensorflow as tf
#모델 만들기
model = Sequential()
model.add(Embedding(vocab_size, 128))
model.add(LSTM(128))
model.add(Dense(26, activation='softmax'))
#모델 체크 포인트 설정
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
#모델 컴파일
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
#모델 실행
history = model.fit(X_train, Y_train, batch_size=64, epochs=5, callbacks=[es, mc], validation_data=(X_test, Y_test))실행결과

모델 실행 결과는 정확도 가 13.7퍼까지 갔다가 다시 12.7로 떨어졌다. 기존 RNN보다 아주 조금 성능이 나은 것 같고, 블로그를 작성하다 보니 내가 했던 방법에 문제점이 있다는 것을 알게 되었다.
학습 방법의 문제점
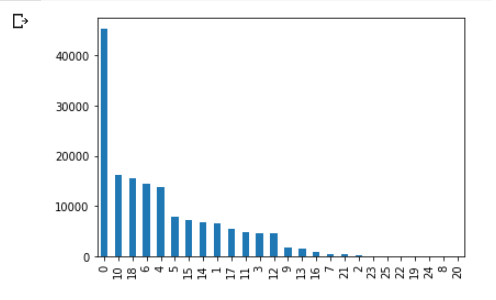
먼저 학습 데이터 셋의 정확도는 39.8퍼인데 검증 데이터 셋의 경우 12.7퍼로 차이가 많이 났다. 이유를 생각해보니, 데이터 셋의 문제점이 컸던 것 같다. 먼저 밑의 사진을 보면 장르 0번의 경우 데이터가 약 4.8만개 있는데 이 데이터가 '드라마'장르이다. 영화의 데이터가 편향 되어 있기도 하며, 학습 데이터와 검증데이터를 나눌 때 데이터셋을 섞지 않고 8대2 비율로 나눠서 학습할 때는 주로 드라마 장르와 다른 몇개의 장르를, 검증할 때는 뒤의 20퍼를 학습하게 되니 정확도가 차이 날 수 밖에 없었다. 그리고 수집한 데이터의 경우도 좋은 품질이 아닌 단순하게 데이터를 많이 모아야겠다고 생각해서 모으다 보니 질이 좋은 데이터를 가지고 학습하지 않아서 더욱 정확도가 떨어진 것 같다. 블로그를 정리하다보니 문제점을 발견했던 것 같고, 다음 프로젝트에선 이런 실수를 반복하지 말아야 겠다는 반성을 했다.

커피를 좋아하는 평범한 대학생