
학습 데이터 만들기
데이터 개수 확인
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
data = pd.read_csv('/content/gdrive/My Drive/취향저격/한석/Movie_Sentence_Data.csv') 전처리한 데이터 불러오기
print("총 문장의 개수: ", len(data)) #데이터 개수 확인

데이터의 모양을 확인하기 위해 상위 5개 출력
data[:5] #데이터의 상위 5개 출력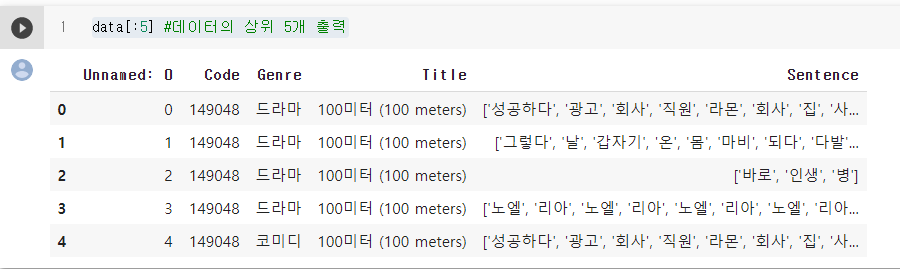
불필요한 열 제거 및 장르 라벨링
del data['Unnamed: 0'] #불필요한 'Unnamed: 0' 열을 삭제 한다
data['Genre'] = data['Genre'].replace(['드라마','판타지','서부','공포','멜로/로맨스','모험','스릴러',
'느와르','컬트','다큐멘터리','코미디','가족','미스터리','전쟁','애니메이션','범죄',
'뮤지컬','SF','액션','무협','에로','서스펜스','서사','블랙코미디','실험','공연실황'],
[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25]) # 각 장르를 숫자 라벨로 바꿔준다.
print(data[:5]) # 상위 5개 출력
열이 잘 삭제 돼었고, 사진상에선 보이진 않지만 각 장르별로 숫자 라벨링이 됐다.
드라마 -> 0, 판타지 -> 1 이런식으로 라벨링을 해주었고 순서는 네이버 영화장르의 상위에 있는 순서대로 했다.
각 문장과 라벨을 데이터에 대입
X_data = data['Sentence'] #문장
Y_data = data['Genre'] #장르
print('문장의 개수: {}'.format(len(X_data)))
print('라벨의 개수: {}'.format(len(Y_data)))X_data에 문장을 넣고, Y_data에 장르 라벨을 넣은 후 길이가 같은지 확인

각 문장의 시퀀스 화
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X_data)
sequences = tokenizer.texts_to_sequences(X_data)
print(sequences[:5]) # 시퀀스화 된 문장 상위 5개 출력
위의 이미지는 한 문장의 결과이고 잘 된 것을 확인 할 수 있다.
시퀀스 단어장
word_to_index = tokenizer.word_index
print(word_to_index)

잘 된 것을 확인할 수 있다.
훈련 데이터와 테스트 데이터 나누기
훈련 데이터, 테스트 데이터
n_of_train = int(len(sequences) * 0.8)
n_of_test = int(len(sequences) - n_of_train)
print('훈련 데이터의 개수 :',n_of_train)
print('테스트 데이터의 개수:',n_of_test)
데이터 정보
X_data = sequences
print('문장의 최대 길이 : %d' % max(len(l) for l in X_data))
print('문장의 평균 길이 : %f' % (sum(map(len, X_data))/len(X_data)))
plt.hist([len(s) for s in X_data], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()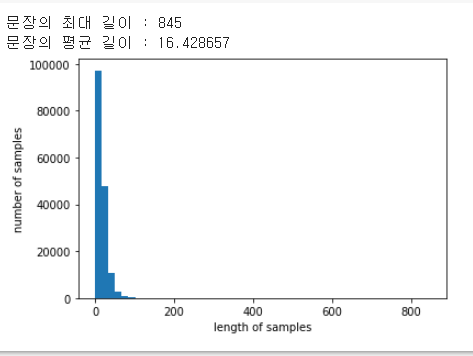
데이터 셋 길이 맞추기
max_len = 845
data = pad_sequences(X_data, maxlen = max_len) # 전체 데이터셋의 길이는 max_len으로 맞춘다.
print("훈련 데이터의 크기(shape): ", data.shape)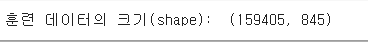
데이터의 길이는 최대 길이인 845로 맞춘다.
데이터 셋 나누기
X_test = data[n_of_train:]
Y_test = np.array(Y_data[n_of_train:], dtype=np.float32 )
X_train = data[:n_of_train]
Y_train = np.array(Y_data[:n_of_train], dtype=np.float32)RNN 학습
from keras.layers import SimpleRNN, Embedding, Dense
from keras.models import Sequential
import tensorflow as tf
model = Sequential()
model.add(Embedding(vocab_size, 128, input_length = max_len)) #Output dim = 128
model.add(SimpleRNN(128)) #은닉층의 개수 128
model.add(Dense(26, activation='softmax')) #26개의 카테고리 중 한 개의 결과가 나오도록, softmax 함수를 활용
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
history = model.fit(X_train, Y_train, epochs=4, batch_size=64, validation_split=0.2) # 4epoch(반복) , 64 batch(한 번 학습 시킬 때 올리는 양)
결과가 12% 정도로 예상 했던만큼 좋은 결과를 얻지 못했다.

커피를 좋아하는 평범한 대학생