
취향저격 프로젝트의 마무리는 Word2Vec이다. 결론을 먼저 말하면, Word2Vec을 이용한 통계 기반으로 영화 추천을 했고, 결과는 만족스러웠다.
Word2Vec은 문장을 단어 단위로 자른 후 학습 시켜서 단어와 단어간의 거리를 Vector로 표시한 것으로, 어느정도 단어의 의미가 살아 있다. 취향저격 프로젝트에서의 Word2Vec은 영화 줄거리를 이용해서 Word2Vec을 학습 시켰고, 사용자가 입력한 문장을 전처리한 후, Word2Vec에 각 전처리해서 나온 단어와 유사한 상위 5개를 뽑게 했다.
즉, 사용자가 '로봇이 나와서 전쟁하는 영화'라고 입력을 하면 전처리 과정을 거쳐서
로봇, 나오다, 전쟁, 영화이런식으로 단어가 뽑힐 것이다. 그 후 각 단어와 비슷한 단어 상위 5개를 찾는다. 영화는 의미가 없을 것으로 불용어 처리 했다.
- 로봇: 단어1, 단어2, 단어3, 단어4, 단어5
- 나오다: 단어1, 단어2, ..., 단어5
- 전쟁: 단어1, ... ,단어5
이렇게 나온 단어들을 이용해서 단어가 영화의 줄거리에 얼마나 있는지를 찾아서 영화를 찾는다. 위의 예제의 경우 단어가 총 18개 이므로 단어들이 모두 포함될 경우 18개의 단어가 모두 포함된 영화가 나올 것이다. 따라서 나온 단어가 얼마나 포함되느냐가 추천하는 영화를 결정짓게 된다. 간단한 아이디어였다. 이번 프로젝트는 개인적으로 공부를 많이 했던 공부였고 많이 부족한 상태에서 진행해서 아쉬운 부분이 없지 않아 있던 것 같다.

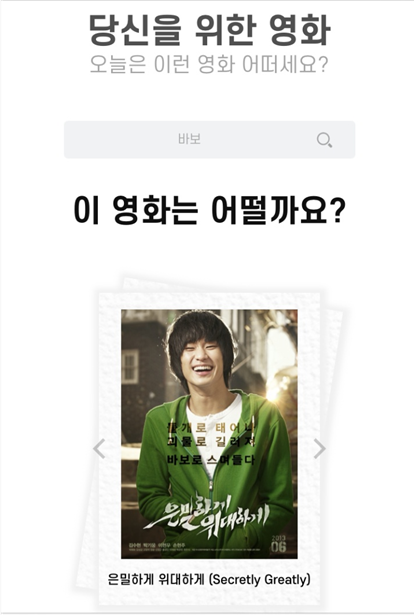
위의 사진들은 프로젝트 결과이다. 위에서 설명한 통계방식을 이용해서 영화를 추천했고, 생각보다 결과가 잘 나왔던 것 같다.
마무리
취향 저격 프로젝트를 마무리하며, 이번 블로그를 작성하면서 아쉬웠던 점은 코드를 제대로 보존하지 않아서 코드가 없다는 것이다. 앞서 설명했던 방법들 RNN, LSTM, Doc2Vec등은 사용하고 삭제를 해서, 코드가 존재하지 않았고, Word2Vec을 마지막으로 이용했음에도 코드가 상당 부분 읽지 못할 정도로 깔끔하지 못했다. 다음 프로젝트를 진행하면 git에 올려서 누구나 접근하기 쉽게 정리해서 올릴 계획이다.
딥러닝을 처음 써서 그런가 결과들이 다 좋지 못했고, 인공지능을 이용해서 추천하기 보다 통계적으로 접근하게 됐다. 프로젝트를 마무리한 시점부터 지금까지 약 한 학기동안 공부를 열심히 했고, 조만간 다른 프로젝트를 포스팅 할 계획이다. 첫 인공지능 프로젝트였고, 아쉬운점도 많고 정도 많은 프로젝트였다.
(프로젝트에 관해 궁금한 점이나 코드 일부분이라도 보고싶다면 댓글 달아주면 됩니당!)
