🔎 주목할 점
- 텍스트를 논리적형식(SQL) 변환하지 않고 바로 테이블 셀을 표시하는 방식으로 학습해 성능향상시킴
- 기존 BERT를 확장한 모델에 표데이터 인식을 도울 특수임베딩을 추가함
- 사전학습과정으로 1) 기본 텍스트로 학습된 BERT-Large, 2) Wikipedia Text-Table 쌍 추출해 상관관계 학습시켜 성능 향상시킴
- 모델의 유연성을 위해 1) scalar 값 학습을 값 도출에 필요한 셀 범위 선택과 2) Aggregation Operator(빈도, 합, 평균 등) 사용 확률분포를 결합해 정답 오차를 Hubber loss로 계산하는 weak supervision 방법으로 학습시킴
- 데이터 학습구조가 다름에도 논리형식변환 방식에 맞춰진 공개 Table QA 데이터셋을 이용해 학습함
🌵 개요
타블렛 데이터에서 질의응답하는 문제는 주로 시멘틱파싱(자연어를 논리형식으로 변환) 문제로 여겨졌다. 논리적형식으로 처리하는 작업의 비용을 축소시키기 위해 표안의 값을 가르키는 방식으로 대체하는 weak supervision으로(간접적으로) 학습하는 방법이 유행했다. 그러나 weak supervision 방식으로 시멘틱파싱을 학습하기 어려웠고 생성된 논리형식은 표시하기 위한 전단계로만 사용됨
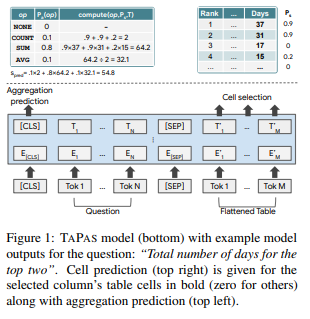
이 논문은 semantic parser로 논리형식을 생성하는 방법없이 타블렛데이터에서 질의응답하는 방법 TAPAS를 제안함. TAPAS는 테이블셀 1)선택과 (optionally) 2)셀 값들을 종합 연산 결과를 토대로 학습한다.
BERT 구조를 확장하는 방식으로 테이블을 입력으로 받고, wikipedia에서 크롤링한 텍스트와 테이블을 pair로 결합해 텍스트 테이블 상관관계를 사전학습 시킴
⇒ 요약: 기존에는 텍스트를 논리형식으로 변환해서( 가장 많이 사용된 방식은 질문을 SQL로 변경해 테이블 서치하는 구조) 테이블 QA 문제를 해결해왔으나 이는 질문을 SQL로 정확히 변환하기 위해 많은 학습데이터가 필요했기에 비효율적임. 이를 개선하기 위해 질문을 의미구조로 변경하는 작업을 생략하고 테이블 속 사용할 셀위치를 학습하는 방법을 고안함
🌵 TAPAS Model
Bert 인코더를 기반 모델에 테이블을 인식하기 위한 임베딩들을 추가한 구조이다.
테이블을 단어 시퀀스로 평면화시키고 단어들을 word pieces로 자른 뒤 질문과 테이블을 결합해 모델 입력으로 사용한다. 또한, 후처리로 2개의 분류기를 추가하는데 하나는 테이블을 셀을 선택하는 문제와 선택한 셀들을 연산하는 집계연산자(Aggregate operator)를 선택하는 문제이다.
Additional embedding
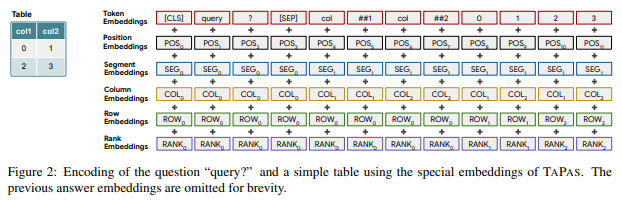
질문과 테이블 사이에 Seperator를 부여하지만 다른 연구와 달리 셀사이를 분리하는 Seperator를 넣지는 않는다. 대신에 셀들의 위치를 인지시키기 위한 positional embeddings을 추가한다.
- Position ID: 쿼리와 테이블을 합치고 평면화한 후 BERT와 동일한 순서 index 부여
- Segment ID: 쿼리와 테이블 구분하기 위한 임베딩. 쿼리는 0, 테이블은 1
- Column / Row ID: 열과 행의 위치 index. query에 속한 부분은 0
- Rank ID: 특정 열의 값이 비교가능한 숫자나 날짜일경우 같은 열에 위치한 셀의 값의 내림차순으로 인덱스를 부여. 0: 비교불가, 1: 가장 작은 수
- Previous Answer: 지금 시점의 질의응답이 이전 항목에 이어진 종속질문인지 구분하기 위해 테이블 셀이 이전 질문의 답변에 사용된 셀이면 1 그렇지 않으면 0으로 표현하는 임베딩
Cell selection
질문에 대한 답을 생성하는데에 사용되는 셀을 분류하는 모델. 곧바로 답변으로 선택되거나 Aggregation operaotr에 사용되어 답변을 생성한다.
1) 마지막 레이어 위해 선형레이어를 쌓아 각 토큰의 로짓을 계산하고, 셀 안에 속해있는 모든 토큰 로짓의 평균을 계산해 cell selection 확률값을 구한다. 최종 출력은 셀 C를 선택할 확률
2) 단일 column에서 cell을 선택하기 위해 inductive bias를 추가해 범주형 변수를 선택한다.
1)에서 계산된 셀 선택확률에서 선현레이어를 추가해 계산한다.3) column 혹은 cell을 선택하지 않는 경우의 column logit을 추가해 셀이 없는 extra column취급한다. 계층의 출력은 열 로짓에 대해 softmax를 사용
We add an additional column logit that corresponds to selecting no column or cells. We treat this as an extra column with no cells. The output of the layer is the probability p(co)_col to select column co computed using softmax over the column logits. We set cell probabilities p^(c)_s outside the selected column to 0
Aggregation operator prediction
SQL 로직으로 변환하는 Semantic parsing task들은 숫자 합, 셀 계산등의 추론이 필요하다. 이를 논리적변환 없이 수행하기 위해 TAPAS에서는 테이블 셀의 범위를 출력하는 동시에 선택적으로 종합연산자를 함께 도출한다 이 연산자들은 선택된 셀 범위에 적용하는 목적이다. 첫번째 토큰 [CLS]의 마지막 hidden vector에 추가 선형레이어를 쌓은 후 softmax로 계산되며 cell selection 결과와 함께 학습됨
Inference
TAPAS는 가장 높은 확률의 Aggregation Operator와 정답도출하는 데에 사용되는 셀의 서브셋을 예측한다. 이진 셀 예측하기 위해 cell selection확률이 0.5보다 큰 것을 선택하며, 예측된 연산자를 적용하여 답변을 검색함
🌵 Pre-training
최근 성공적인 pre-training 과정이 여러 task에 기여와 더불어 TAPAS에서는 이를 Structured data 영역으로 확장하고자 한다. wikipedia의 많은 테이블을 사전 훈련시켜 모델이 텍스트와 테이블 간, 열과 셀 그리고 헤더 사이의 다양한 상관 관계를 이해 시킬 수 있다.
wikipedia에서 텍스트-테이블 paris를 추출해 학습데이터를 생성했으며 최대 테이블 셀은 500개로 제한해 총 테이블은 6.2M 개이다. (이 조건으로 인해 모든 테이블은 헤더를 인식가능한 태그가 포함되 있음)
BERT 구조를 사용해 첫벗째 Object로 MLM을 사용했으며, 두번째로는 특정 테이블이 텍스트에 속하는지 아님 랜덤으로 선택된 것인지 예측했으나 sub-task 성능을 향상시키는데 별다른 기여는 하지 못했다. (next sentence prediction task가 별다른 효과주지 못한 것과 같은 맥락이라 생각됨)
효율적으로 학습하기 위해 총 시퀀스 길이를 제한한다. 토큰화된 관련텍스트과 테이블 길이를 이 제한에 맞추기 위해 관련텍스트에서 무작위로 8~16개의 토큰을 선택하고 테이블에서 각 열과 셀의 첫번째 단어만 추가하는 것으로 시작하여 제한에 도달할 때까지 단어를 차례대로 추가한다. 이렇게 모든 테이블에 대해 10개의 다른 정보를 생성함
버트에 사용된 masking 방법을 사용했으며 셀 일부가 마스킹된 경우 해당 셀 안의 모든 token을 마스킹하면 성능 향상에 도움되는 것을 발견함
🌵 Fine-tunning
TAPAS가 제시한 느슨한 감독 학습(weakly supervised) 방식:
주어진 학습 셋(질문, 테이블, 답변에 해당하는 셀)로 모델이 새로운 질문을 프로그램 z에 매핑시켜 알맞은 답변 셀을 도출하도록 학습시킨다. 프로그램 z는 테이블 셀들의 집합과 (선택적) 집계 연산자로 구성됨
예측 정답 셋 y는 ; 셀의 좌표 C와 y가 single sclar일경우 그 셀안의 값 s로 구성되어있음. cell selection의 경우 s는 생성되지 않으며 모델은 C를 선택하기 위해 학습한다. C는 없고 값으로 이뤄져있는 경우 모델은 집계연산자와 셀들을 선택해 s를 맞추려 노력함
Cell selection
정답 범위를 좁히는 계측정 모델을 사용한다. Column을 먼저 선택하고 그 범위 안에 있는 cell을 또한번 선택하는 방식
직접적으로 모델이 가장 점수가 높은 셀이 포함된 column을 선택하게 한다, 만약 선택된 C가 비어있다면 추가적인 빈 column을 선택
그 다음 해당 C column에 종속된 셀들 중 일부를 선택하게끔 학습
loss는 총 3 component로 구성되어 있음
1) the average binary cross-entropy loss over column selection: 모든 컬럼들에 추가로 empty column을 포함해 계산
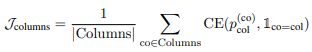
2) 1)에서 선택된 column의 cell들을 대상으로 binary cross-entropy loss
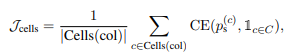
3) 집계연산자를 사용할 필요없는 cell selection의 경우 None으로 선택되며 이 로스는 아래와 같음
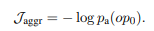
Scalar answer
이 케이스의 정답 y인 경우 테이블 안에 답변이 등장하지 않고 계산을 통해 도출해야한다. SQL으로 변환하는 경우 COUNT, AVERAGE, SUM 등으로 한정되어 있지만 TAPAS 방식은 제한이 없음
모델을 견고히 만들기 위해 명확한 aggregation type을 예측하도록 감독하지 않으며 잠재적으로 학습하도록 레이어를 추가한다. 구체적으로는 계산된(예측된)aggreation operators를 확인하는 방법은 도출된 scalar 임
주어진 cell 속 token selection 확률과 테이블 값을 각 집계연산자 종류에 맞는 계산을 수행하고 이를 합쳐 예상 스칼라 값을 도출함


그리고 이 scalar answer loss를 Hubber loss를 이용해 계산
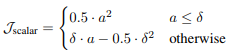
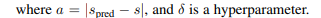
여기에 추가 조치로 scalar answer는 집계연산자가 존재하는 것을 암시하기에 집계연산자가 None class인 경우 패널티를 주는 loss도 포함해 최종 loss는 . (는 hyper-param)
학습하며 매우 큰 가 발생하는데 이는 불안정한 업데이트를 야기한다. 이를 피하기 위해 cutoff hyper-parameter를 도입해 경우 J = 0 으로 셋팅해 이런 케이스를 반영하지 않는다. 이는 outlier를 배제하는 것과 관련있음
Ambiguous answer
scalar anwser이지만 동시에 테이블 셀안에 등장하는 정답유형이 존재한다. 이런 경우 모델이 정책에 따라 지도학습 방법을 선택하도록한다. 학습 시점이 언제냐에 따라 정책은 dynamic하게 변하는데, 만약 집계연산자로 None class 선택할 확률이 Hyper parmeter S 보다 높으면 scalar answer 방법으로 학습
🌵 Experiments
WIKISQL, WIKITQ, SQA 3 데이터셋을 <question, cell coordinates, scalar answer> 형식으로 변환해 BERT-large로 학습했으며 기본 텍스트로 학습된 모델 위에 pre-training시작함. TPU v3 32개로 3일동안 학습했음
🌵 Results
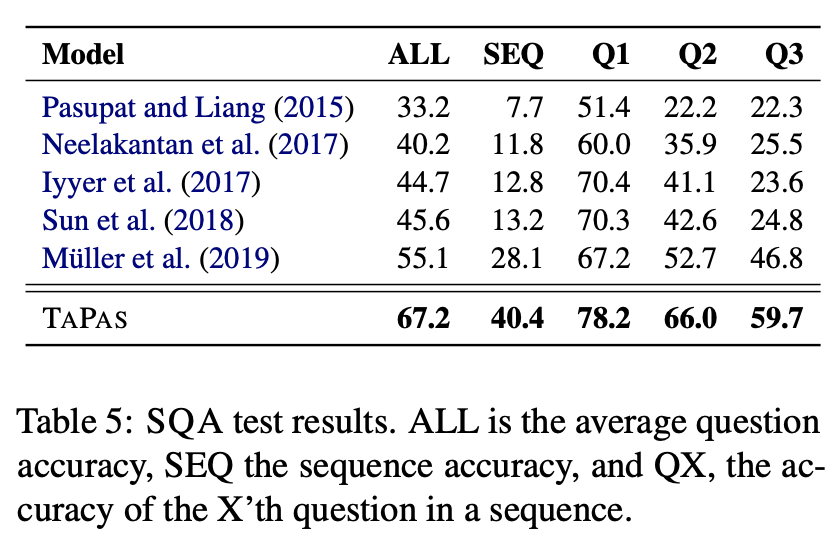
각 데이터셋에 대해 TAPAS 성능과 타 연구발표 성능 비교
*fully-supervised 는 학습할 때 aggregation type 을 명시해 학습한 것
*WIKITQ 데이터셋은 TAPAS 성능이 다른 방법에 비해 큰 효과 보이지 않음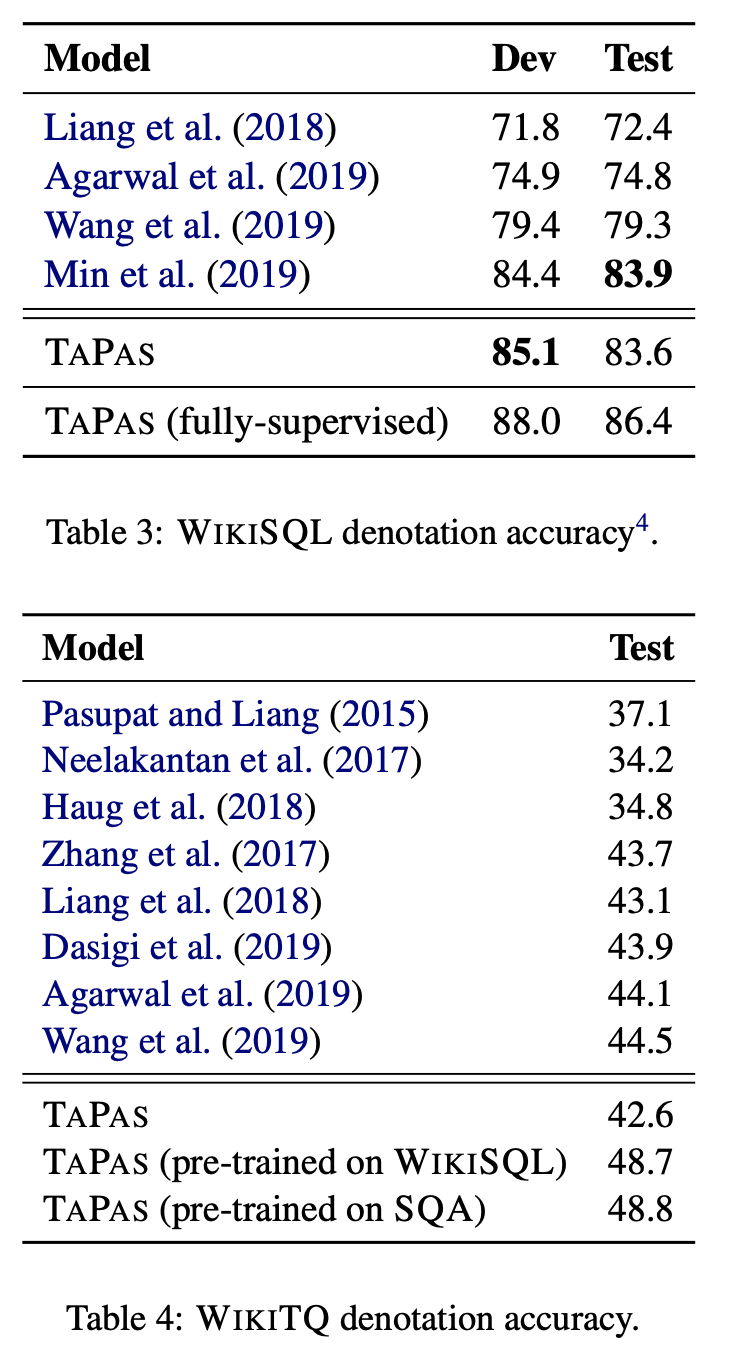
주요 트릭이 모델 성능에 끼치는 영향 분석
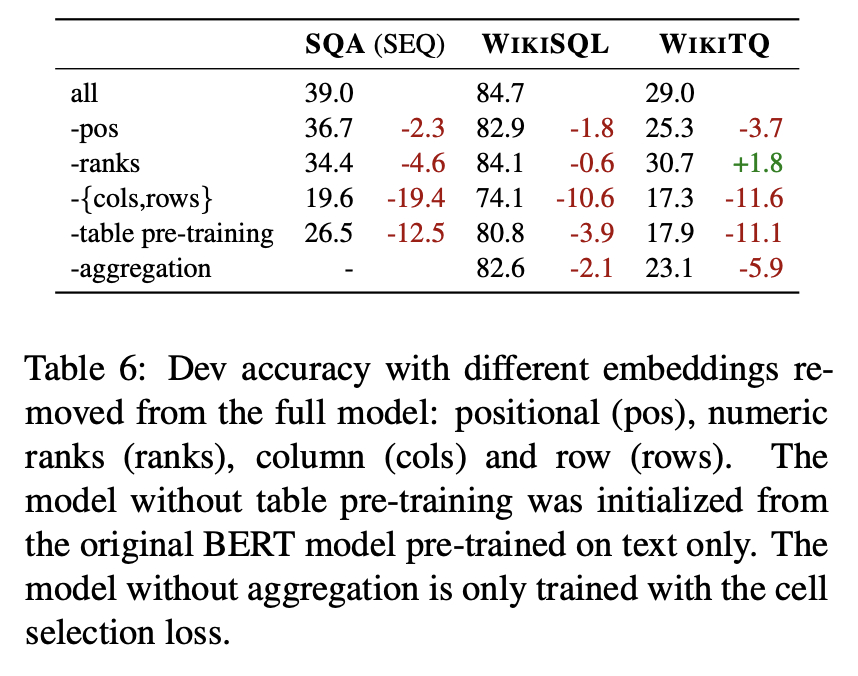
테이블 텍스트 관계를 사전학습 시키는 것과 column, row 임베딩은 매우 중요하다는 것을 발견했고 반면에, positional embeding과 rank embedding은 큰 효용은 없었음
scalar answer 와 aggregation loss를 학습과정에서 제거했을 때 WIKISQL과 WIKITQ에서 정확도가 떨어졌지만 WIKITQ에서 하락이 두드러졌고 WIKISQL에서는 미미했는데 이는 WIKISQL의 대부분의 샘플이 aggregation 이 필요없기 때문
또한 WIKITQ 퀄리티에 대해서 절차적으로 분석했으나 내용생략
Limitation
- TAPAS는 single 테이블으로 학습 범위를 정해 멀티 컬럼, 멀티로우 테이블을 적용하기 적합하지 못함
- 단일 집계연산자들만 사용해 두단계 이상 계산이 필요한 경우 (ex, "number of actors with an average rating higher than 4") 적용하지 못함
🌵 Conclusion
TAPAS는 논리적변환(Text → SQL Query)없이 테이블 데이터에 질의응답하는 방법을 제시했다. 효과적인 사전학습 방법으로 text, table pairs를 학습시키고 파인튜닝하며 성공적으로 masked words와 masked table cells를 원복시킴
앞으로 이 모델을 멀티 테이블, large 테이블에 적용할 수 있도록 확장하는 방법을 연구할 예정
