
auto scaling
파드의 CPU와 메모리 자원을 할당하는 것을 조절한다.
resource_control
request, limit, limitrange, resource_quota가 있는데 req와 limit가 중요하다.
파드를 지정할 때, 컨테이너에 필요한 각 리소스의 양을 선택적으로 지정할 수 있다. 지정할 가장 일반적인 리소스는 CPU와 메모리(RAM) 그리고 다른 것들이 있다.
파드에서 컨테이너에 대한 리소스 요청(request) 을 지정하면, kube-scheduler는 이 정보를 사용하여 파드가 배치될 노드를 결정한다. 컨테이너에 대한 리소스 제한(limit) 을 지정하면, kubelet은 실행 중인 컨테이너가 설정한 제한보다 많은 리소스를 사용할 수 없도록 해당 제한을 적용한다. 또한 kubelet은 컨테이너가 사용할 수 있도록 해당 시스템 리소스의 최소 요청량을 예약한다. request는 limit와 같을 순 있지만 더 큰 값을 가질 순 없다.
# 정보
kubectl explain pod.spec.container.resources
# req 파일
vi myapp-pod-req.yaml
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests: # 이만큼을 무조건 확보해줘야함
memory: "64Mi"
cpu: "250m"
limits: # 추가용량이 필요하면 이만큼까지만 추가로 요청가능
memory: "128Mi"
cpu: "500m" # m: milicore
# req 설정되어있는 것 확인
kubectl create -f myapp-pod-req.yaml
kubectl describe po myapp-pod-req- CPU와 메모리는 각각 리소스 타입이다. Huge page는 노드 커널이 기본 페이지 크기보다 훨씬 큰 메모리 블록을 할당하는 리눅스 관련 기능이다. 예를 들어, 기본 페이지 크기가 4KiB인 시스템에서, hugepages-2Mi: 80Mi 제한을 지정할 수 있다. 컨테이너가 40개 이상의 2MiB huge page(총 80MiB)를 할당하려고 하면 해당 할당이 실패한다.
# huge 파일로 이는 파드가 만들어지지 않는다.
vi myapp-pod-huge-req.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-huge-req
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
resources:
requests:
cpu: 4000m
memory: 4Gi- CPU와 메모리의 현재 사용율을 보여줌
kubectl top pods
kubectl top nodes
# 노드에 할당된 리소스를 확인할 수 있다
kubectl describe node kube-node1
# 해당 파드에 강제로 리소스의 부하를 준다
# 쓰레기 값을 계속 넣어서 용량을 계속해서 잡아먹는다
kubectl exec 파드이름 -- sha256sum /dev/zero
CPU 리소스 단위
CPU 리소스에 대한 제한 및 요청은 cpu 단위로 측정된다. 쿠버네티스에서, 1 CPU 단위는 노드가 물리 호스트인지 아니면 물리 호스트 내에서 실행되는 가상 머신인지에 따라 1 물리 CPU 코어 또는 1 가상 코어에 해당한다.
# 소켓이나 CPU, core 정보 확인
lscpu요청량을 소수점 형태로 명시할 수도 있다. 컨테이너의 spec.containers[].resources.requests.cpu를 0.5로 설정한다는 것은, 1.0 CPU를 요청했을 때와 비교하여 절반의 CPU 타임을 요청한다는 의미이다.
CPU 자원의 단위와 관련하여, 0.1 이라는 수량 표현은 "백 밀리cpu"로 읽을 수 있는 100m 표현과 동일하다. 어떤 사람들은 "백 밀리코어"라고 말하는데, 같은 것을 의미하는 것으로 이해된다. 1000=1core
CPU 리소스는 항상 리소스의 절대량으로 표시되며, 상대량으로 표시되지 않는다.
QOS (Quality of Service) class
Pod Quality of Service Classes
# 파드의 QOS의 클래스를 확인
kubectl describe pod 파드이름1 . BestEffort
- 가장 안좋은 것으로 limit나 request를 정의하지 않은 경우
2 . Burstable(폭발하다)
- request보다 limit이 큰 경우
- 파드 내 메모리나 CPU에 request나 limit중 하나라도 있는 경우
3 . Guaranteed
- 가장 좋은 경우로 request와 limit가 모두 존재해야함
- request와 limit에 모두 cpu와 memory가 정의되어야 하며, request의 값과 limit의 값이 모두 같아야 한다.
kubelet이 리소스 부족으로 압박을 받기 시작하면 가장 먼저 종료하는 것은 BestEffort이고 그 다음은 Burstable을 종료시킨다.
제한된 리소스에 따라 종료시킬 파드의 우선순위를 고려해서 파드를 생성해야 한다.
limit range
limit나 request와 다르게 별도의 리소스로 존재하는 것이다. 많이 사용하는 리소스는 아니다.
# 생성한 리밋레인지 보기
kubectl get limits
# 리밋레인지에 설정된 값 보기
kubectl describe limits 리밋레인지 이름vi myapp-limitrange.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: myapp-limitrange
spec:
limits:
- type: Pod
min:
cpu: 50m
memory: 5Mi
max:
cpu: 1
memory: 1Gi
- type: Container
defaultRequest: # 파드를 만들때 req의 기본값
cpu: 100m
memory: 10Mi
default: # 파드를 만들때 limit의 기본값
cpu: 200m
memory: 100Mi
min:
cpu: 50m
memory: 5Mi
max:
cpu: 1
memory: 1Gi
maxLimitRequestRatio:
cpu: 4
memory: 10
- type: PersistentVolumeClaim
min:
storage: 10Mi
max:
storage: 1Gi
kubectl create -f myapp-limitrange.yaml
# 적용사양 확인
kubectl describe limitranges myapp-limitrange - 리밋레인지에 리소스의 범위를 설정하고 해당 리소스를 생성하게되면 해당 범위에서만 생성이 가능하게 한다.
- 범위를 넘어가는 리소스는 생성되지 않는다.
- 컨테이너의 default 섹션은 만약 컨테이너를 생성할때 limit과 request를 설정하지 않으면 자동으로 해당 default의 값으로 limit과 request를 설정한다.
리소스 쿼터(ResourceQuota)
여러 사용자나 팀이 정해진 수의 노드로 클러스터를 공유할 때 한 팀이 공정하게 분배된 리소스보다 많은 리소스를 사용할 수 있다는 우려가 있다.
ResourceQuota 오브젝트로 정의된 리소스 쿼터는 네임스페이스별 총 리소스 사용을 제한하는 제약 조건을 제공한다. 유형별로 네임스페이스에서 만들 수 있는 오브젝트 수와 해당 네임스페이스의 리소스가 사용할 수 있는 총 컴퓨트 리소스의 양을 제한할 수 있다.
# 생성한 쿼터 보기
kubectl get quota - quest와 limit을 지정한 쿼터
vi myapp-quota-cpumem.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: myapp-quota-cpumem
spec:
hard:
requests.cpu: 500m
requests.memory: 200Mi
limits.cpu: 1000m
limits.memory: 1Gi- 생성가능한 리소스의 개수를 제한한 쿼터
vi app-quota-object.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: myapp-quota-object
spec:
hard:
pods: 10
replicationcontrollers: 2
secrets: 10
configmaps: 10
persistentvolumeclaims: 5
services: 5
services.loadbalancers: 1
services.nodeports: 2
nfs-client.storageclass.storage.k8s.io/persistentvolumeclaims: 2- 스토로지의 용량을 제한할 수 있다.
vi myapp-quota-storage.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: myapp-quota-storage
spec:
hard:
requests.storage: 10Gi
nfs-client.storageclass.storage.k8s.io/requests.storage: 2GiHPA(Horizontal Pod Autoscaling)
워크로드 리소스(예: 디플로이먼트 또는 스테이트풀셋)를 자동으로 업데이트하며, 워크로드의 크기를 수요에 맞게 자동으로 스케일링하는 것을 목표로 한다.
# 생성한 hpa확인
kubectl get hpa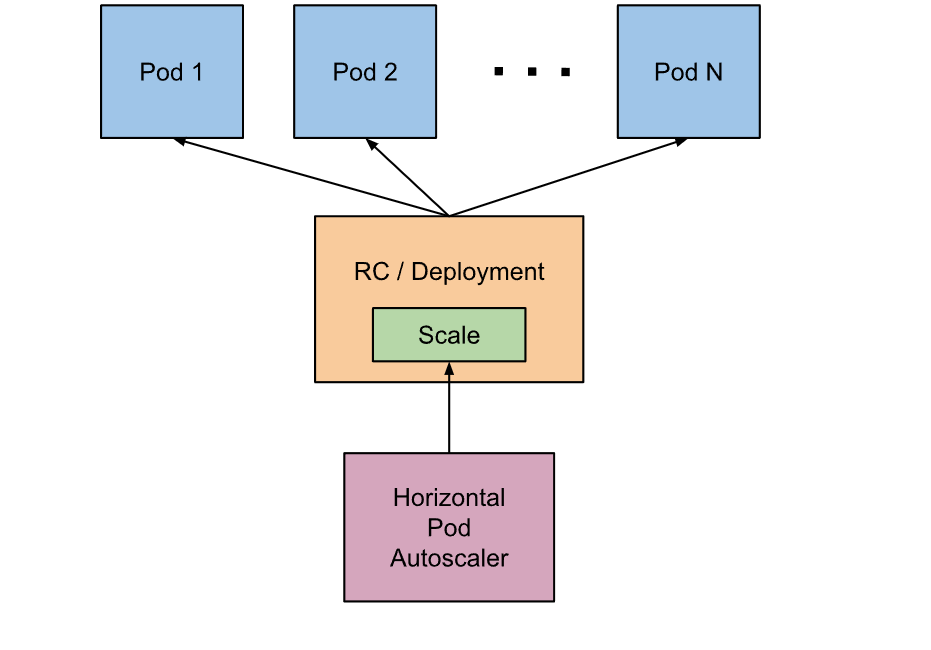
-> Deployment/rs/sts(복제본을 제공해주는 컨트롤러) 등의 리소스를 통해 파드를 생성할 때 Replicas를 지정한다.
-> HPA가 이 replicas의 수를 자동으로 조정해주는 구조이다.
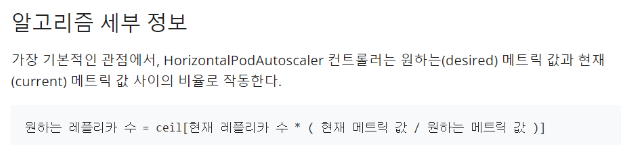 ceil: 올림
ceil: 올림
vi myapp-hpa-cpu.yaml
apiVersion: autoscaling/v2 # 버전 확인 잘하기
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa-cpu
spec:
scaleTargetRef: # replica수를 조정할 대상 설정
apiVersion: apps/v1
kind: Deployment
name: myapp-deploy-hpa
minReplicas: 2 # replica 최소값
maxReplicas: 10 # replica 최대값
metrics: # replica수를 조정할 때 참조할 지표 설정
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70 # 70퍼센트를 기준으로 스케일링 CPU Utilization : CPU 평균 사용률을 퍼센트로 나타낸 것
- v1은 metrics로 CPU Utilization만 볼 수 있는 단점 존재
-> 이를 해결하기 위한 v2는 CPU Utilization 이외에도 다른 metrics들을 참조 가능
-> CPU Utilization 70퍼센트는 request의 cpu값을 기준으로 한다. 절대 limit을 기준으로 하지 않는다
- v1으로 위의 값을 똑같이 만든 것
vi myapp-hpa-cpu-v1.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa-cpu
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-deploy-hpa
minReplicas: 2
maxReplicas: 10
targetCPUUtilizationPercentage: 70- 디플로이먼트 생성
vi myapp-deploy-hpa.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-hpa
spec:
replicas: 3
selector:
matchLabels:
app: myapp-deploy-hpa
template:
metadata:
labels:
app: myapp-deploy-hpa
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
resources:
requests: # metrics로 참조할 cpu사용률
cpu: 50m
memory: 5Mi
limits:
cpu: 100m
memory: 20Mi
ports:
- containerPort: 8080- deployment로 파드 3개를 생성하면 각 파드는 req의 수치인 최소 cpu 50m ~ limit의 수치인 최대 100m까지 사용할 수 있다.
- HPA는 3개의 파드의 CPU 사용률의 평균을 계산한다.
- HPA는 request의 cpu값을 기준으로 하기 때문에 3개의 파드의 CPU사용률이 총 150m라면 HPA는 CPU Utilization을 100%로 계산한다.
# 디플로이먼트 먼저 생성
kubectl create -f myapp-deploy-hpa.yaml
kubectl get deployments.apps
kubectl get hpa
# hpa 생성
kubectl create -f myapp-hpa-cpu.yaml
# 매트릭을 측정하기까지 시간이 좀 걸림
kubectl get hpa
tmux # 여러 터미널을 띄우기 위해 tmux를 킨다
ctrl + b + " # 창을 세개로 분할한다
# hpa의 정보를 실시간으로 본다
watch -n1 -d kubectl get hpa
# 파드의 cpu사용률을 실시간으로 본다
watch -n1 -d kubectl top pods
# 하나의 파드에 임의로 cpu용량 부하를 준다
kubectl exec 파드1 이름 -- sha256sum /dev/zero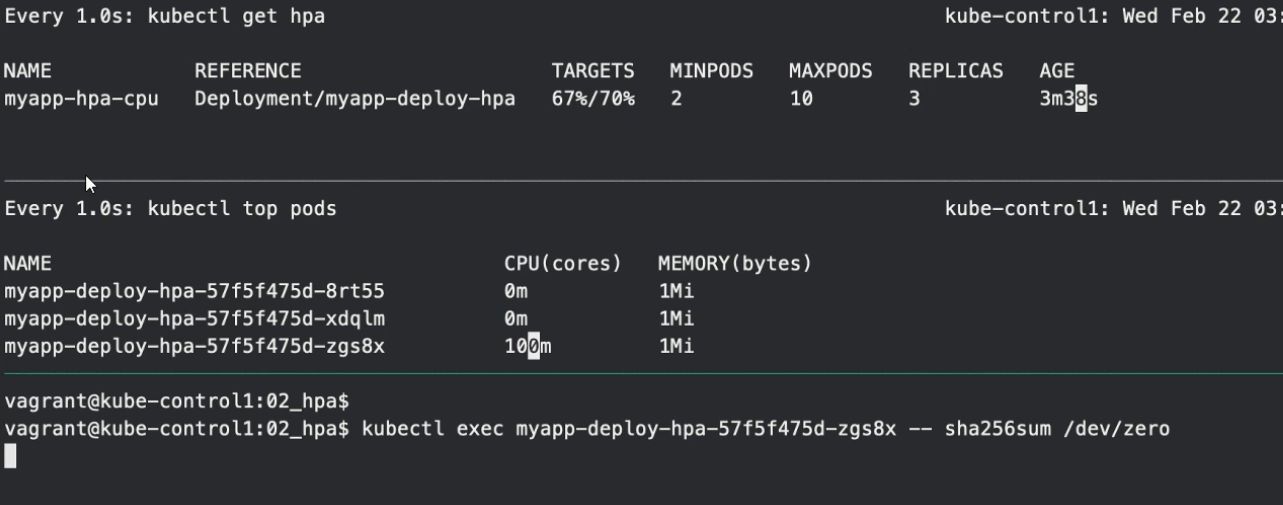
-> 만약 임의로 한 파드에 용량의 부하를 줬을 경우 파드는 최대 limit값이 100까지 cpu를 사용할 것이고, 이것은 100/150 = 66%
이기 때문에 70%를 도달하지못해 scailing을 하지 않는다.
# 추가로 하나의 파드에 임의로 cpu용량 부하를 준다
kubectl exec 파드2 이름 -- sha256sum /dev/zero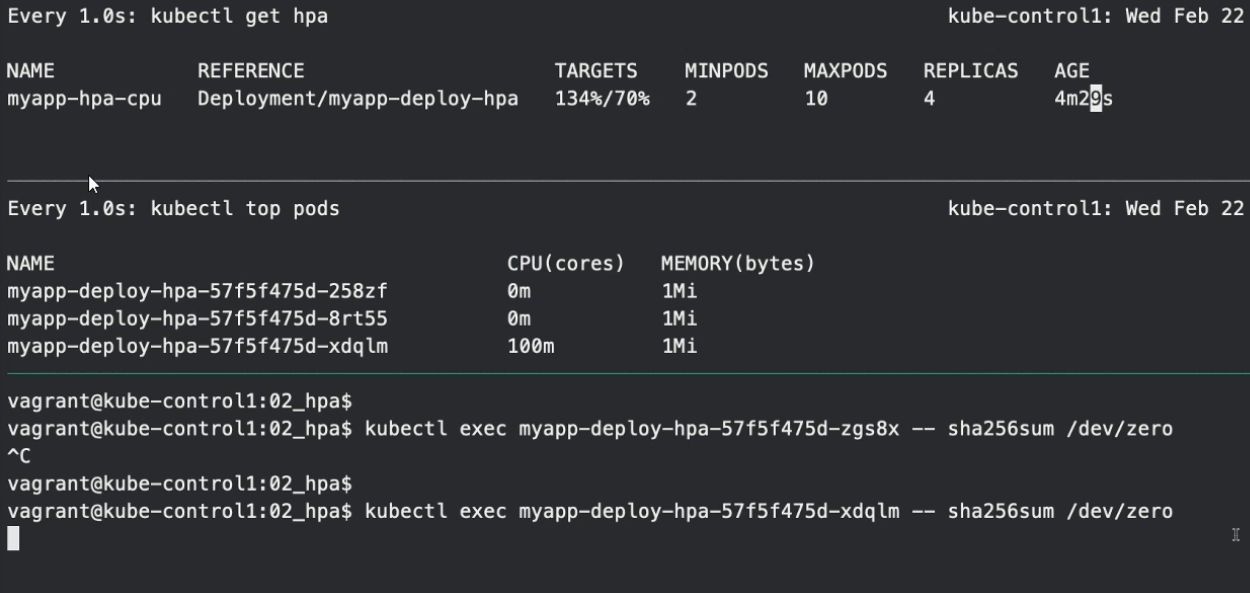
-> 만약 임의로 또 한 파드에 용량의 부하를 줬을 경우 3개의 파드 총 cpu사용률을 200이 될것이고, 200/150 = 133%이므로 replica의 수를 증가시킨다.
위의 replica 증가 알고리즘 공식에 의해
3*(133%/70%) = 5.7이므로 올림하여 replicas는 6이 된다.
즉, 현재 3개의 파드에서 추가로 3개의 파드를 더 생성한다.
만약 용량 부하가 걸린 파드를 삭제해서 cpu사용률을 낮추게 되면 autoscailing에 의해 파드의 개수를 최소개수까지 낮출것이다. 하지만 파드의 개수가 바로 변화되지 않는것을 알 수 있다. 이유는 바로 stabilizationWindowSeconds 때문이다.
kubectl explain hpa.spec.behavior.scaleDown kubectl explain hpa.spec.behavior.scaleUp만약 cpu사용률이 69%~71%를 왔다갔다 한다고 가정하자.
이때 만약 오토스케일링이 즉시 반응을 한다면 왔다갔다 함에 따라 계속해서 파드를 늘리거나 줄일것이다. 이런 scale과정이 오히려 리소스에 부하를 더 많이 주게 된다.
따라서 stabilizationWindowSeconds를 설정해 오토스케일링이 바로 반응하지 않고 특정 시간만큼 기다렸다가 스케일을 진행한다.
-> stabilizationWindowSeconds의 default값은 300초이다.
-> 따라서 5분을 기다리면 파드가 최소개수로 낮춰지는 것을 볼 수 있다.
파드 스케줄러
파드를 노드에 배치하는 방법
nodename
nodename은 특정 노드만 지정해서 사용해야하기 때문에 유연하지 않다.
모든 복제본이 같은 파드에 배치되기 때문에 고가용성 문제가 발생하기 때문에 잘 사용하지 않는다. 따라서 보통 사용하지 않고 nodeselector를 사용한다.
vi myapp-rs-nn.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-nn
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs-nn
template:
metadata:
labels:
app: myapp-rs-nn
spec:
nodeName: kube-node1 # 특정 노드 지정, 생성된 파드는 지정한 node1에만 배치된다.
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
nodeselector
nodename과 달리 노드이름을 지정하는 것이 아니라, 레이블을 통해 노드를 선택하기 때문에 유연하게 여러 노드를 선택할 수 있다.
# 각 노드에 레이블 설정
kubectl label node kube-node1 gpu=lowend
kubectl label node kube-node2 gpu=highend
kubectl label node kube-node3 gpu=highend
# 설정한 gpu확인
kubectl get nodes -L gpu
vi myapp-rs-ns.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-ns
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs-ns
template:
metadata:
labels:
app: myapp-rs-ns
spec:
nodeSelector: # label을 선택한다.
gpu: highend # 해당 레이블을 가진 노드들을 선택
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
# 생성
kubectl create -f myapp-rs-ns.yaml
kubectl get po -o wide
# 스케일해보고 확인
kubectl scale rs myapp-rs-ns --replicas 4
kubectl get po -o wide
-> 노드 셀렉터에 의해 gpu: highend 레이블을 가진 node2,node3에만 파드가 배치된다.
어피니티
nodeSelector 는 파드를 특정 레이블이 있는 노드로 제한하는 가장 간단한 방법이다. 어피니티/안티-어피니티 기능은 표현할 수 있는 제약 종류를 크게 확장한다. 주요 개선 사항은 다음과 같다.
-
어피니티/안티-어피니티 언어가 더 표현적이다. nodeSelector로는 명시한 레이블이 있는 노드만 선택할 수 있다. 어피니티/안티-어피니티는 선택 로직에 대한 좀 더 많은 제어권을 제공한다.
-
규칙이 "소프트(soft)" 또는 "선호사항(preference)" 임을 나타낼 수 있으며, 이 덕분에 스케줄러는 매치되는 노드를 찾지 못한 경우에도 파드를 스케줄링할 수 있다.
-
다른 노드 (또는 다른 토폴로지 도메인)에서 실행 중인 다른 파드의 레이블을 사용하여 파드를 제한할 수 있으며, 이를 통해 어떤 파드들이 노드에 함께 위치할 수 있는지에 대한 규칙을 정의할 수 있다.
nodeAffinity
노드 어피니티 기능은 nodeSelector 필드와 비슷하지만 더 표현적이고 소프트(soft) 규칙을 지정할 수 있게 해 준다.
# 노드에 레이블 설정
kubectl label node kube-node1 gpu-model=3080
kubectl label node kube-node2 gpu-model=2080
kubectl label node kube-node3 gpu-model=1660
kubectl get nodes -L gpu-model
vi myapp-rs-nodeaff.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-nodeaff
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs-nodeaff
template:
metadata:
labels:
app: myapp-rs-nodeaff
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 요청(hard)
nodeSelectorTerms: # 노드의 레이블 선택,
# 반드시 하나를 선택해야하기 때문에 가중치가 없다
- matchExpressions:
- key: gpu-model
operator: In
values:
- '3080'
- '2080'
preferredDuringSchedulingIgnoredDuringExecution: # 요청(soft)
- weight: 10 # 선호하는 정도, 여러개의 선호가 있다면 가중치로 순위를 매김
preference:
matchExpressions: # 노드의 레이블 선택
- key: gpu-model
operator: In
values:
- titan
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
# 생성
kubectl create -f myapp-rs-nodeaff.yaml
kubectl get po -o wide
# 스케일해보고 확인
kubectl scale rs myapp-rs-ns --replicas 4
kubectl get po -o widenodeaffinity를 실행하면 파드 두개는 node1 or node2에만 배치되는 것을 확인
-> 만약 스케일을 통해서 파드 개수를 늘려도 마찬가지로 node1 or node2에만 배치
nodeselector랑 비슷하며, nodeaffinity는 복잡하기 때문에 보통 nodeselector를 사용한다.
- preferredDuringSchedulingIgnoredDuringExecution
요청(soft) : 특정 노드를 선호하지만 되면 배치되고 아니여도 상관 x- requiredDuringSchedulingIgnoredDuringExecution
요청(hard) : 특정 노드에 반드시 배치되어야 한다.-> 요청한 노드가 더이상 파드를 받을 수 없거나, 해당 레이블을 가진 노드가 없다면 파드는 생성되지 않는다.
podAffinity / podAntiAffinity
파드 간 어피니티/안티-어피니티 는 다른 파드의 레이블을 이용하여 해당 파드를 제한할 수 있게 해 준다.
# 1 . cache 파드 생성
vi myapp-rs-podaff-cache.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-aff-cache
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs-aff-cache
tier: cache
template:
metadata:
labels:
app: myapp-rs-aff-cache
tier: cache # 파드에 레이블 설정
spec:
affinity:
podAntiAffinity: # 파드가 서로 배척한다
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: tier
operator: In
values:
- cache
topologyKey: "kubernetes.io/hostname"
# 노드의 hostname으로 구역을 나눈다
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine- 현재 파드마다 tier: cache 어노테이션이 들어가 있다. 여기서는 파드가 같은 노드에 설정될 수 없다는 것을 의미한다.
- topologyKey: 노드가 3개가 있는데 노드를 기준으로 같이 있거나 배척한다. 여기서는 레이블을 지정해주는데 "kubernetes.io/hostname" 이것은 분리시키는 기준을 노드별로 하겠다는 의미이다.
노드의 가용영역을 구별해주는 레이블이 있는데 이를 기준으로 하면 실제로 토폴로지를 따로 구성할 수도 있다.
# front 파드 생성
vi myapp-rs-podaff-front.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-aff-front
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs-aff-front
tier: frontend
template:
metadata:
labels:
app: myapp-rs-aff-front
tier: frontend # 파드에 레이블 설정
spec:
affinity:
podAntiAffinity: # 파드가 서로를 배척한다
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: tier
operator: In
values:
- frontend
topologyKey: "kubernetes.io/hostname"
podAffinity: # 파드가 붙어서 노드에 배치된다
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: tier
operator: In
values:
- cache
topologyKey: "kubernetes.io/hostname"
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
# 실습 진행
kubectl create -f myapp-rs-podaff-cache.yaml
kubectl get po -o wide
# cache의 노드 위치에 front가 무조건 배치됨
kubectl create -f myapp-rs-podaff-front.yaml
kubectl get po -o wide-> 하나의 노드에 cache파드와 front파드가 한 쌍으로 묶여서 배치된다. 다른 노드에도 마찬가지로 한 쌍으로 묶여서 배치된다.
만약 파드 어피니티를 사용하지 않는다면 한 쌍으로 묶여서 배치되어야 할 파드들이 각 노드에 퍼져서 배치될 수 있다.
-
물론, 노드간에도 네트워크 연결이 되어있기 때문에 떨어진 파드끼리 노드의 네트워크를 통해서 통신이 가능하다. 하지만 노드간 네트워크 통신은 네트워크 홉을 증가시키기 때문에 성능에 지대한 영향을 끼칠 수 있다.
-
파드 어피니티를 통해 한 쌍으로 묶어서 하나의 노드에 배치하게되면 노드안에서 통신이 되기 때문에 노드 간 통신보다 성능이 좋다.
테인트(Taints) & 톨러레이션(Tolerations)
노드 어피니티는 노드 셋을 (기본 설정 또는 어려운 요구 사항으로) 끌어들이는 파드의 속성이다. 테인트는 그 반대로, 노드가 파드 셋을 제외시킬 수 있다.
-
톨러레이션은 파드에 적용된다. 톨러레이션을 통해 스케줄러는 그와 일치하는 테인트가 있는 파드를 스케줄할 수 있다. 톨러레이션은 스케줄을 허용하지만 보장하지는 않는다. 스케줄러는 그 기능의 일부로서 다른 매개변수를 고려한다.
-
테인트와 톨러레이션은 함께 작동하여 파드가 부적절한 노드에 스케줄되지 않게 한다. 하나 이상의 테인트가 노드에 적용되는데, 이것은 노드가 테인트를 용인하지 않는 파드를 수용해서는 안 된다는 것을 나타낸다.
# 테인트 확인, 현재 컨트롤 노드에만 설정되어 있는 것을 확인
kubectl get nodes kube-control1 -o jsonpath='{.spec.taints}'
kubectl get nodes kube-node1 -o jsonpath='{.spec.taints}'
kubectl get nodes kube-node2 -o jsonpath='{.spec.taints}'
kubectl get nodes kube-node3 -o jsonpath='{.spec.taints}'지금까지 파드 중심으로 생각했다면, 테인트와 톨러레이션은 노드 중심
테인트와 톨러레이션은 쌍으로 작동한다.
테인트는 국가의 입국 정책, 톨러레이션은 비자라고 생각하면 쉽다.
= 테인트는 노드의 역할/정책, 톨러레이션은 파드에 부착되어서 특정 톨러레이션이 있는 파드만이 노드의 정책에 의해 해당 노드에 배치된다.
- .effect 필드 값의 효과

# taint 생성 - 위에서 cache와 front가 생성되어 있지 않은 노드에 생성
kubectl taint node kube-node1 env=production:NoSchedule
# 해당 노드의 taint 보기
kubectl get nodes kube-node1 -o jsonpath='{.spec.taints}'
# taint 해제
kubectl taint node kube-node1 env-
# 위의 podAffinity / podAntiAffinity실습의 연장선이기에 지우지 말것
# cache를 배척하고 있기 때문에 node1에만 배치될 수 있음
vi myapp-rs-notol.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-tol
spec:
replicas: 1
selector:
matchLabels:
app: myapp-rs-tol
tier: backend
template:
metadata:
labels:
app: myapp-rs-tol
tier: backend
spec:
affinity:
podAntiAffinity: # cache 레이블을 가진 파드를 배척
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: tier
operator: In
values:
- cache
topologyKey: "kubernetes.io/hostname"
tolerations: # 톨러레이션 부여
- key: env
operator: Equal
value: production
effect: NoSchedule
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
kubectl create -f myapp-rs-notol.yaml
# 상태를 보면 만들어지지 않고 pending 임
kubectl get po -o wide
kubectl describe po 파드명
-> 위의 podAffinity / podAntiAffinity실습에 의해서 node2,node3에 각각 cache,front 레이블을 가진 한쌍을 배치했었다.
-> podAntiAffinity설정에 의해 cache레이블을 가진 파드를 배척하기 때문에 node2,3에는 배치될 수 없다.
-> 따라서 node1에만 배치될 수 있는데 node1에 taint를 설정했기 때문에 taint가 가진 정책에 부합하는 tolerations를 가져야 된다. 톨러레이션이 없다면 파드가 만들어지지 않고 pending로 지속됨
-> taint정책에 부합하는 key,value를 가진 tolerations를 부여했기 때문에 node1에 배치되는 것을 볼 수 있다.
cordon & drain
유지보수나 서버증설을 위해 해당 노드를 재부팅 시켜야할때 해당 노드에는 파드가 존재하면 안된다. 따라서 커든을 통해 새로운 파드의 스케줄링을 막고 드레인을 통해 기존의 존재하는 파드들을 퇴거시킨다.
- 해당 노드에 스케줄링되는 것을 막는다.
# 커든 적용
kubectl cordon kube-node3
# 상태를 보면 스케줄disabled 되어있음
kubectl get nodes
# 커든 해제
kubectl uncordon kube-node3 - 해당 노드에 있는 모든 파드들을 퇴거(evict) 시킨다.
kubectl drain kube-node3
kubectl drain kube-node3 --ignore-daemonsets-> 하지만 데몬셋이 관리하는 파드들은 복제본 컨트롤러가 아니기 때문에 퇴거시키지 못한다. 따라서 --ignore옵션을 사용한다.
-> 다른 복제본 컨트롤러가 관리하는 파드들은 지워져도 다른 노드에 자동으로 생성되기 때문에 문제가 안된다.
-> drain을 하게 되면 자동으로 커든이 되기때문에 작업이 끝나고나면 커든을 해제해야 한다.
