문제
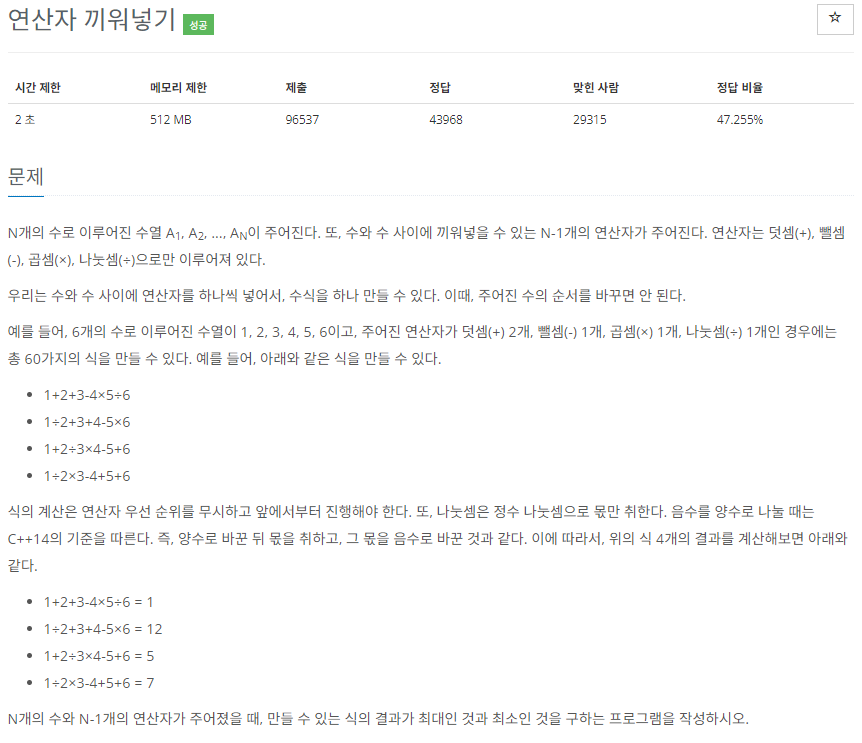
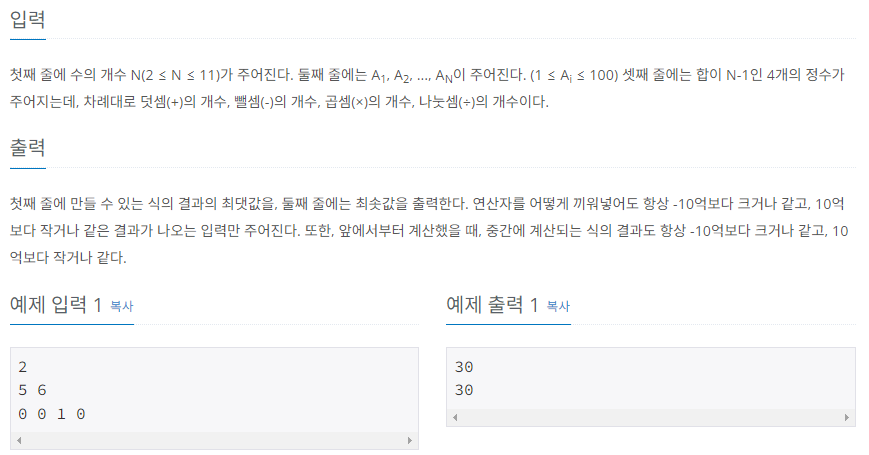
이해
입력으로는 수열과 사용할 수 있는 연산자의 개수가 주어진다.
N개의 수열을 입력받으면 N-1개의 연산자를 입력받는다. 각 연산자는 수열의 수 사이에 들어가서 식을 완성한다.
완성된 식은 연산자 우선 순위를 무시하고 연산한다. 따라서, 식에 * 연산이 있더라도 다른 연산자보다 뒤에 있다면 위치대로 연산을 수행한다.
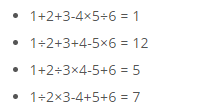
따라서, 위와 같은 식의 결과가 계산된다.
조합가능한 식의 값 중에서 최댓값과 최솟값을 구하여라.
접근
입력받은 수와 연산자 간에는 특별한 관계가 있어보이지 않는다. 따라서, 그리디 알고리즘은 제외.
최댓값과 최솟값을 구하기 위해서는 모든 식의 경우를 탐색해야 할 것으로 보인다. 수의 개수도 최대 11개로 충분히 탐색 가능할 것으로 보인다. 따라서, dfs를 선택한다.
다음으로는 연산자를 배치하는 방법이다.
연산자는 4개의 정수로 입력받는데 각 수는 연산자의 사용가능 횟수이다.

예제 입력 3의 경우에는 2, 1, 1, 1로 '+' 연산자은 2개이며 그 외의 연산자는 1개씩 쓸 수 있다.
식을 완성할 때 이전에 사용했던 연산자는 사용할 수 없기 때문에 사용했던 연산자를 기록하기 위한 배열을 생성해야 한다 (visited[])
dfs는 일반적인 dfs 처럼 N개의 연산자를 배치했다면 현재까지 결과를 저장된 max, min과 비교하여 갱신한다.
코드
package java_baekjoon;
import java.io.*;
public class prob14888 {
static int N;
static int[] arr;
static String[] op_arr;
static boolean[] visited;
static int max = Integer.MIN_VALUE;
static int min = Integer.MAX_VALUE;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
N = Integer.parseInt(br.readLine());
String[] input_num = br.readLine().split(" ");
arr = new int[N];
for (int i = 0; i < N; i++) {
arr[i] = Integer.parseInt(input_num[i]);
}
String[] input_op = br.readLine().split(" ");
op_arr = new String[N - 1];
visited = new boolean[N - 1];
int cnt = 0;
for (int i = 0; i < Integer.parseInt(input_op[0]); i++) {
op_arr[cnt++] = "+";
}
for (int i = 0; i < Integer.parseInt(input_op[1]); i++) {
op_arr[cnt++] = "-";
}
for (int i = 0; i < Integer.parseInt(input_op[2]); i++) {
op_arr[cnt++] = "*";
}
for (int i = 0; i < Integer.parseInt(input_op[3]); i++) {
op_arr[cnt++] = "/";
}
dfs(arr[0], 0);
System.out.println(max);
System.out.println(min);
}
static void dfs(int cur, int depth) {
if (depth == N - 1) {
max = Math.max(max, cur);
min = Math.min(min, cur);
return;
}
for (int i = 0; i < N - 1; i++) {
if (visited[i]) {
continue;
}
visited[i] = true;
dfs(cal(op_arr[i], cur, arr[depth + 1]), depth + 1);
visited[i] = false;
}
}
static int cal(String op, int operand1, int operand2) {
switch (op.charAt(0)) {
case '+':
return operand1 + operand2;
case '-':
return operand1 - operand2;
case '*':
return operand1 * operand2;
case '/':
return operand1 / operand2;
default:
return Integer.MAX_VALUE + 1;
}
}
}연산자의 입력을 조금 독특하게 했는데 입력받은 수 만큼 String형 배열에 저장했다. 예제 입력3 처럼 2, 1, 1, 1 이라면 ("+", "+", "-", "*", "/") 처럼 저장된다.
dfs는 현재까지 계산된 결과와 depth를 전달한다. N개의 연산자를 모두 배치했다면 한 분기의 탐색을 종료하고 결과를 갱신한다.
https://st-lab.tistory.com/121
풀고나서 st-lab님의 코드를 참고했는데 dfs를 사용한다는 점에선 비슷하지만 다른 점이 존재했다.
나는 연산자를 String형으로 새로이 저장하여 꺼내서 사용했다.
st-lab님의 코드에서는 단순하게 입력받은 연산자 정보를 그대로 int형 배열에 저장하여 꺼낼때 마다 -1을 한다. 그리고 분기에서 돌아오면 다시 +1을 한다.
이 방법은 입력받는 방법이 단순하기도 하지만 나처럼 방문정보를 담는 visited 배열이 필요없기 때문에 좋은 코드인 것 같다.
또한, 나는 같은 연산자의 개수가 2이상인 경우 새로 저장하는 과정에서 각각을 다른 연산자로 취급한다. 예를 들어, 내 코드에서는 (1 + 1 + 1) 과 (1 + 1 + 1)을 다른 경우로 판단하여 탐색한다. (각 '+'를 서로 다른 연산자로 취급)
하지만 st-lab님은 그대로 카운트 방식으로 활용하여 중복된 경우를 탐색하지 않는다.
시간적으로나 공간적으로나 좋은 코드라고 할 수 있다.
결과

