GC를 수행하는 Garabage Collector는 아래와 같은 일을 한다.
- 메모리 할당
- 사용 중인 메모리 인식
- 미사용 메모리 인식
Stop-the-World
- 자바 애플리케이션은 GC 실행시 GC 실행 스레드를 제외한 모든 스레들르 멈추고, GC 완료 후 다시 스레드들을 실행 상태로 변경
- Stop the World는 모든 애플리케이션 스레드들의 작업이 멈추는 상태
- 어떤 GC 알고리즘을 사용해도 Stop-the-World는 불가피하며 대개의 GC 튜닝이란 이 Stop-the-World 시간을 줄이는 것이다.
전제
가비지 컬렉터는 두가지 전제 조건 하에서 만들어졌다.
- 대부분의 객체는 금방 접근 불가능 상태(unreachable)가 된다.
- 오래된 객체에서 젊은 객체로의 참조는 아주 적게 존재한다.
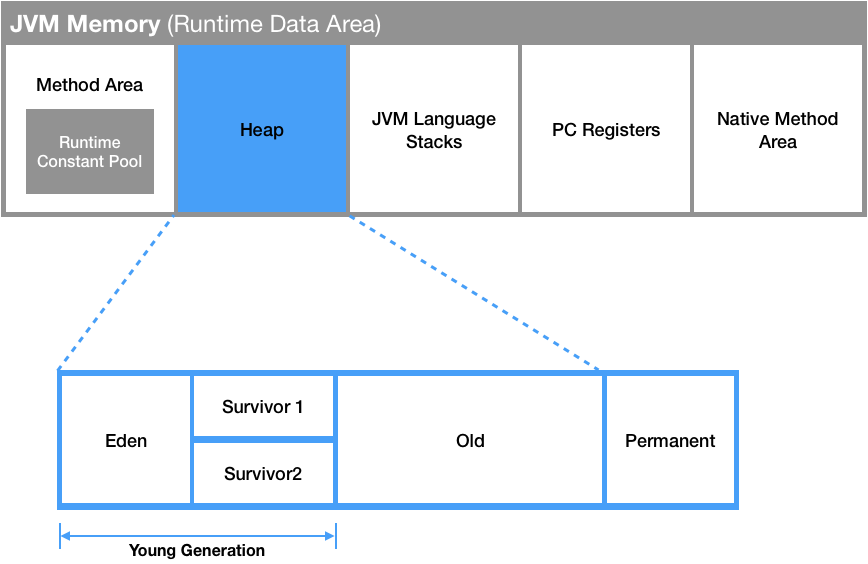
이것을 'weak generational hypothesis'라고 하는데 이것을 살리기 위해서 Young 영역과 Old 영역으로 나누었다.
- Young 영역 (Young Generation 영역) : 새롭게 생성한 객체 대부분이 여기에 위치하고, 대부분이 금방 접근불가능 상태가 되기 때문에 매우 많은 객체가 Young 영역에 생성되었다가 사라진다. 이 영역에서 객체가 사라질때 Minor GC가 발생한다고 말함.
- Old 영역 (Old Generation 영역) : 접근 불가능 상태로 되지 않아 Young 영역에서 살아남은 객체가 여기로 복사된다. 대부분 Young 영역보다 크게 할당하며, 크기가 큰 만큼 Young 영역보다는 GC가 적게 발생한다.(쉽게 가득차지 않으니) 이 영역에서 객체가 사라질 때 Major GC가 발생한다고 말한다.
객체의 데이터 흐름은 아래와 같다. PermG는 Java 8에서 Metaspace로 교체되었다.
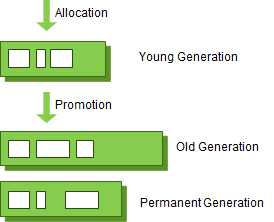
PermG에서 GC가 발생해도 MajorGC의 횟수로 친다.
전제의 두번째가 "오래된 객체에서 젊은 객체로의 참조는 아주 적게 존재한다"인데, 만약 실제로 Old 영역의 객체가 Young 영역의 객체를 참조하는 경우가 생긴다면 Old 영역에 512Byte의 chunck로 되어 있는 card table을 따로 두어 해결한다.
카드 테이블에는 Old 영역에 있는 객체가 Young 영역의 객체를 참조할 때마다 정보가 표시된다. Young 영역의 GC를 실행할 때에는 Old 영역에 있는 모든 객체의 참조를 확인하지 않고, 이 카드테이블만 확인해 GC 대상인지 식별한다.
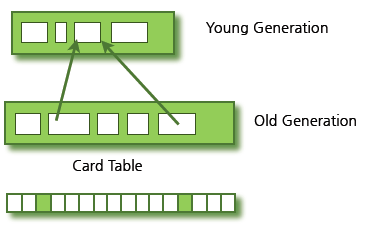
카드 테이블은 write barrier를 사용하여 관리한다. write barrier는 Minor GC를 빠르게 할 수 있도록 하는 장치인데, 이것 때문에 약간의 오버헤드는 있지만 (Old가 Young을 참조하는지 Old 영역 전체를 일일이 확인하지 않아도 되기에) 전반적인 GC시간은 줄어든다.
Young 영역의 구성
객체가 제일 먼저 생성되는 Young 영역은 크게 3가지로 나뉜다.
- Eden 영역
- Survivor 영역(2개,From과 To)
각 영역의 처리 절차를 순서에 따라 기술하면 다음과 같다.
- 새롭게 생성한 대부분의 객체는 Eden 영역에 위치한다.
- Eden 영역에서 GC가 한 번 발생한 후 살아남은 객체는 Survivor 영역 중 하나로 이동한다.
- Eden 영역에서 GC가 발생하면 이미 살아남은 객체가 존재하는 Survivor 영역으로 객체가 계속 쌓인다.
- 하나의 Survivor 영역이 가득차게 되면, 그 중에서 살아남은 객체를 다른 Surivor 영역으로 이동한다. 그리고 가득찬 Survivor 영역은 이제 아무 데이터가 없는 상태가 된다.
- 이 과정을 반복하다 계속해서 살아남아 있는 객체는 Old 영역으로 이동하게 된다.
이 절차에 따라서 Survivor 영역 중 하나는 반드시 비어있는 상태로 남아 있어야 한다.
💡 오래되었다고 하는 기준은 Young Generation 영역에서 Minor GC 가 발생하는 동안 얼마나 오래 살아남았는지로 판단한다. 각 객체는 Minor GC에서 살아남은 횟수를 기록하는 age bit 를 가지고 있으며, Minor GC가 발생할 때마다 age bit 값은 1씩 증가 하게되며, age bit 값이 MaxTenuringThreshold 라는 설정값을 초과하게 되는 경우 Old Generation 영역을 객체가 이동 되는 것이다. 또는 Age bit가 MaxTenuringThreshold 초과하기 전이라도 Survivor 영역의 메모리가 부족할 경우에는 미리 Old Generation 으로 객체가 옮겨질 수도 있다. JVM 옵션 : -XX:MaxTenuringThreshold
그럼 왜 Survivor 영역이 두개인가?
퍼포먼스와 연관있는데, fragmentation(단편화)를 줄이기 위함이다.
예를 들어 새로운 객체는 Eden에 생성된다. Eden이 가득차면 GC가 수행되고 살아있는 객체는 Survivor로 옮겨진다. 근데 그다음에 Eden이 가득차면, Eden과 Survivor 영역의 메모리를 정리하지만 이 영역은 연속적이지 않게 된다. 이런 현상을 방지하기 위해 두가지 Survivor 영역을 두어서 위의 예시에서 두번째 GC시에 Eden과 Survivor 안에 있는 reachable한 객체들은 비어 있는 새로운 Survivor로 옮겨지거나 특정 객체(Old enough한)는 Old로 Promotion된다. 그리고 두 Survivor space는 역할을 바꾼다. 하나는 텅텅 비어있고 하나는 Eden에서 올라오는 것을 수용하는 공간. 이 과정을 통해 Heap에서의 연속적인 메모리 사용을 가능하게 한다.
다시 말하면 Eden에서도 빈 공간 생기고, Survivor에서도 드문드문 빈 공간이 생기게 되는것. Memory internal Fragmentation과 비슷한일이 일어나는것)
Mark and Copy
SerialGC에서 Young Generation에게 쓰는 GC 방식이다.
- Fragmentation(단편화) 방지에는 효과적이다.
- Heap의 절반 밖에 사용하지 못하니 공간 활용의 비효율성
- Suspend 현상(Copy할때), Copy에 대한 Overhaed 존재
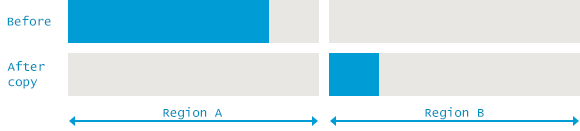
Mark and Copy algorithms are very similar to the Mark and Compact as they too relocate all live objects. The important difference is that the target of relocation is a different memory region as a new home for survivors. Mark and Copy approach has some advantages as copying can occur simultaneously with marking during the same phase. The disadvantage is the need for one more memory region, which should be large enough to accommodate survived objects.
Old 영역에 대한 GC
Old 영역은 기본적으로 데이터가 가득 차면 GC를 실행한다. GC 방식에 따라 처리 절차가 달라지므로 GC 방식에 따라 접근하고 이해해야 한다. JDK 7 기준 5가지 방식
- Serial GC (싱글코어를 상정하고 만든 방식이라 운영서버 사용금지)
- Parallel GC
- Parallel Old GC(Parallel Compacting GC)
- Concurrent Mark & Sweep GC(CMS)
- G1(Garbage First) GC (도입은 JDK7, JDK9부터 기본 GC)
Serial GC
Young 영역에서의 GC는 앞에서 설명한 방식을 사용하고,(Mark and Copy) Old 영역의 GC는 mark-sweep-compact 알고리즘을 사용한다. 디스크 조각모음과 비슷하다. 두 GC 모두 Stop-the-World를 트리거한다.
- Old 영역에 살아 있는 객체를 식별(Mark)한다.
- Heap의 앞 부분부터 확인하여 살아있는 것만 남긴다.(Sweep)
- 각 객체들이 연속되게 쌓이도록 Heap의 가장 앞 부분부터 채워서 객체가 존재하는 부분과 존재하지 않는 부분으로 남긴다.(Compaction)
적은 메모리와 CPU 코어 개수가 적을때 적합한 방식이다.
Parallel GC
기본적인 알고리즘은 Serial GC와 같다. 그러나 SerialGC가 GC를 처리하는 스레드가 하나인 것에 비해 Parallel GC는 GC를 처리하는 스레드가 여러개로 SerialGC보다 빠르게 수행된다. 메모리가 충분하고 코어의 개수가 많을 때 유리하다. Throughput GC라고도 부른다.
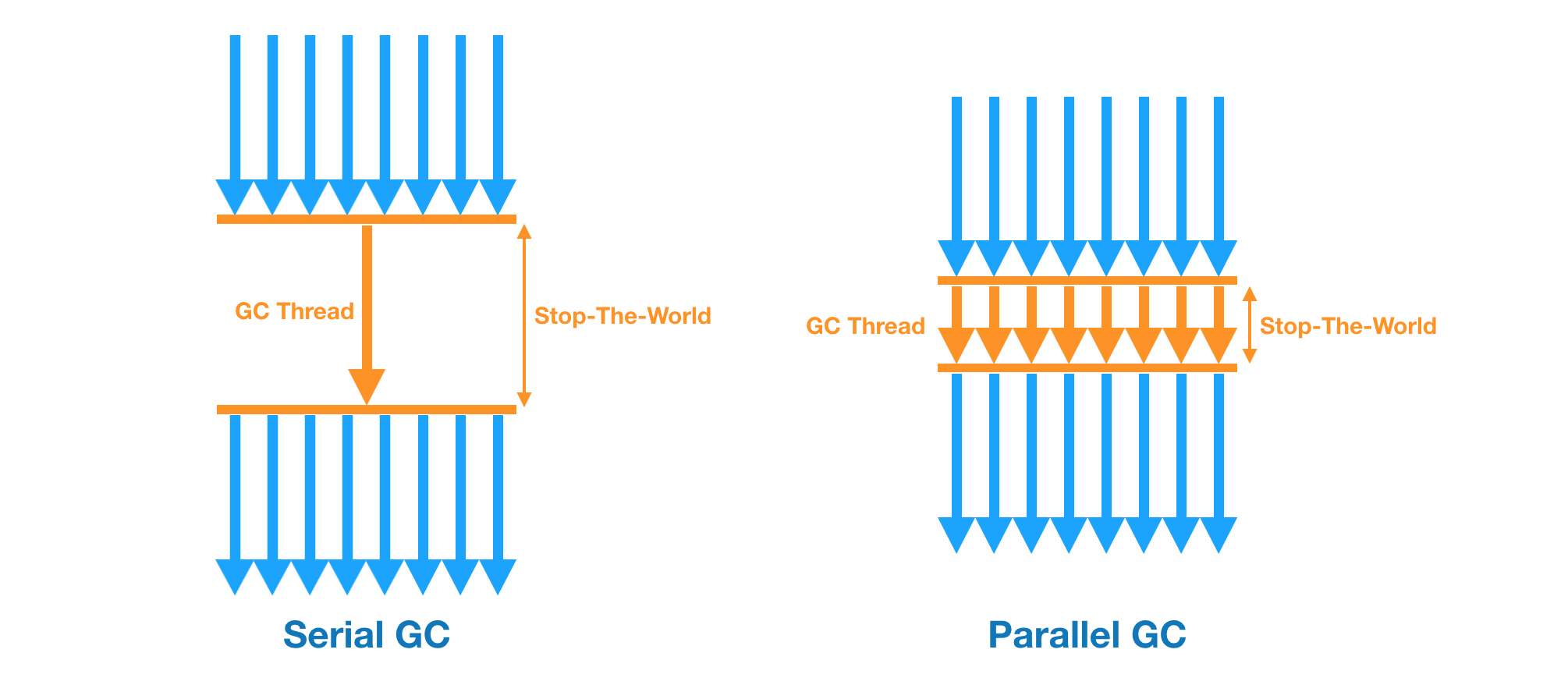
더 빠르게 동작하니 Stop-the-World의 시간도 줄여주는 효과를 얻을 수 있고 Java 애플리케이션 전체가 매끄럽게 동작한다.
Parallel Old GC
JDK5u6부터 제공한 GC 방식이고, Parallel GC와 비교하여 Old 영역의 GC 알고리즘만 다르다. 이 방식은 Mark-Summary-Compaction 단계를 거친다. Summary 단계는 앞서 GC를 수행한 영역에 대해 별도로 살아 있는 객체를 식별한다는 점에서 Mark-Sweep-Compcation 알고리즘의 sweep 단계와는 다르며, 약간 더 복잡하다.
- Sweep은 단일 스레드가 Old 영역 전체를 훑어 살아있는 객체만 찾는다.
- Summary는 여러 스레드가 Old 영역을 분리하여 훑는다. 또 효율성을 위해 Compaction된 영역도 별도로 훑는다.
CMS GC (Concurrent Mark-Sweep Garbage Collector)
GC 과정에서 발생하는 Stop-the-World의 시간을 최소화하는데 초점을 맞춘 GC 방식으로 GC의 과정이 복잡하다.
GC 대상을 최대한 자세히 파악한후, 정리하는 시간(STW가 발생하는 시간)을 짧게 가져가는 컨셉으로, 과정이 복잡한 만큼 다른 GC 대비 CPU 사용량이 높다.
아래의 그림은 Serial GC와 CMS GC를 비교한 그림이다. 엄청 복잡.
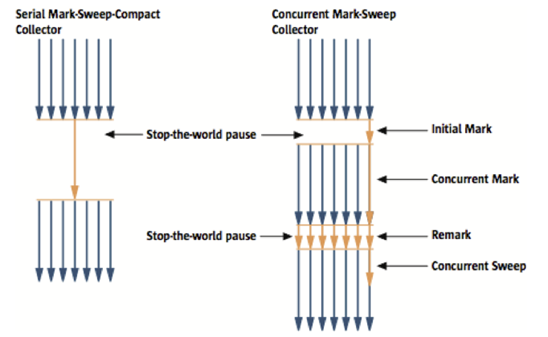
Young 영역에서는 Mark and copy방식을 그대로 사용하고 Old 영역은 Concurrent Mark-Sweep 알고리즘을 사용한다.
CMS GC는 Initial Mark → Concurrent Mark → Remark → Concurrent Sweep 과정이다.
- Initial Mark
- GC 과정에서 살아남은 객체를 탐색하는 시작 객체(GC Root)에서 참조 Tree상 가장 가까운 객체만 1차적으로 찾아가며 객체가 GC대상(참조가 끊긴)인지를 판단한다. 이때는 STW 현상이 발생하지만, 탐색 깊이가 얕아 STW 발생 기간이 매우 짧다.
- Concurrent Mark
- STW 현상없이 진행되며, Initial Mark 단계에서 GC 대상으로 판별된 객체들이 참조하는 다른 객체들을 따라가며 GC 대상인지를 추가적으로 확인한다.
- 이 단계의 특징은 다른 스레드가 실행중인 상태에서 동시에 진행된다는 것.
- Remark
- Concurrent Mark 단계의 결과를 검증하며, 이전 단계에서 GC 대상으로 추가 확인되거나 참조가 제거되었는지 등을 확인한다. 이 과정은 STW를 유발하기 때문에 STW 지속시간을 최대한 줄이기 위해 멀티스레드로 검증 작업을 수행한다.
- Concurrent Sweep
- STW 없이 Remark 단계에서 검증 완료된 GC 객체들을 메모리에서 제거한다.
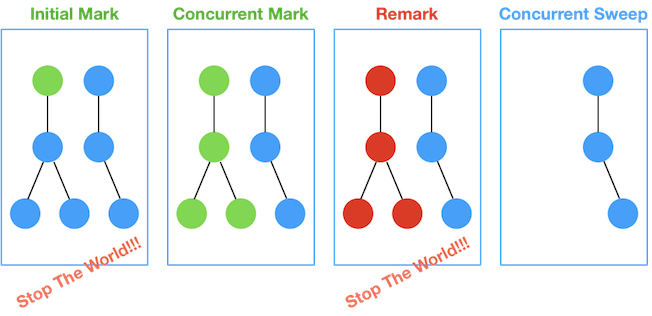
Initial Mark -> Concurrent Mark -> Remark -> Concurrent Sweep , CMS의 상황
CMS GC는 Compaction 작업을 필요한 경우에만 수행한다. 즉, 연속적인 메모리 할당이 어려울 정도로 메모리 단편화과 심한 경우에만 Compaction 과정을 수행하는 것이다.
또 이러한 단계로 진행되는 것이기에 STW 시간이 매우 짧고, 모든 애플리케이션의 응답 속도가 매우 중요할 때 CMS GC를 사용하며, Low Latency GC라고도 부른다.
G1 GC (Garbage First)
G1 GC는 기존의 Young 영역과 Old 영역을 구분하던 방식과는 다른 접근을 한다.
아래 그림과 같이 G1 GC는 바둑판처럼 영역을 구분하고 그 영역에 객체를 할당하고 GC를 실행한다. 해당 영역이 꽉 차면 다른 영역에서 객체를 할당하고 GC를 실행한다.
기존의 Young의 Eden/Survivor 영역에서 데이터가 Old 영역으로 이동하는 단계가 사라진 GC방식이다. 또 G1 GC에선 각각의 바둑판 모양의 영역이 Eden,Survivor,Old 영역의 역할을 동적으로 바꿔가며 GC가 일어난다.
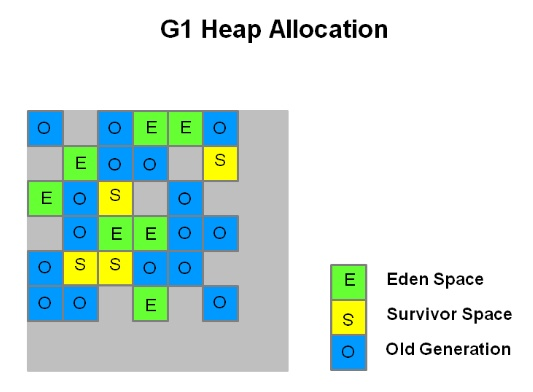
G1 GC는 지금껏 얘기한 어떤 GC 방식보다 빠른 성능을 장점으로 가진다. 다시 말해 짧은 STW를 지향한다는 것이다.
G1 GC는 굉장히 크기가 큰 Heap에서도 짧은 STW 시간은 보이는데 왜 그런것일까?
G1 GC의 비밀
Heap의 용량이 커지면 커질수록, 객체의 갯수가 많아지고, 자연스럽게 GC 수행시간이 길어지며 STW 시간도 늘어난다. 하지만 G1 GC는 다르다.
- GC시에 전체 Heap에 대해서 GC를 수행할 필요가 없다. GC 해야하는 영역만 GC를 수행하면 되기 때문이다.
- Old 영역에 대한 Compaction을 할때, 전체 Old 영역에 대해서 Compaction을 할 필요가 없다. 특정한 영역에 대해서만 Compaction을 하면 된다.
- Garbage를 먼저 수집해간다. G1 GC는 살아있는 객체를 마킹한후에 영역 별로 얼만큼 살려줘야 하는지를 알 수 있다. 그 후 영역 중에 모든 객체가 죽은 리전(유효한 객체가 없는,Garbage만 있는 영역)부터 먼저 회수를 한다. 메모리 회수를 먼저하기에 빈 공간 확보를 더 빨리 할 수 있다. 그러면 GC가 낮은 빈도로 일어난다.
왜 G1GC가 JDK9부터 default GC로 선정되었을까?
G1 GC의 목표는 일시정지 시간 (STW)을 최소화하는데 있다. 영역별로 나누어서 GC를 수행하기 때문에 전체 Old 영역에 대한 GC를 수행하는 일이 생기지 않아 긴 시간의 STW를 가지는 Major GC의 빈도를 낮출수 있어서 선택되었다고 생각한다.
출처 :
