개요
마감 임박 상품을 저렴하게 판매하는 서비스(딜라이트)백엔드 개발의주문 파트를 맡고 있습니다.
그러던 중 동시에 여러 명의 고객이 한 상품을 주문할 때갱신 손실,데드락문제가 발생했고 이를 해결하는 과정에 대한 내용입니다.
- 프로젝트 링크 : Dealight:딜라이트
- 동시 주문 상황을 테스트 코드와 jmeter를 이용해 테스트하는 과정은 링크를 참고해 주시기 바랍니다.
- 프로젝트 기술 스택 : Java 17, Spring boot 2.7, MySQL 8, Spring Data JPA, Redis, AWS, Docker, Github Actions
문제 상황
1. 실제 100건 주문 -> DB 상에는 70개 주문
100건의 주문을 동시에 진행하였으나 재고는 100개가 아닌 70개 내외(72개, 70개만) 줄어들었습니다.
- 100개 동시 주문 테스트
전

- 100개 동시 주문 테스트
후

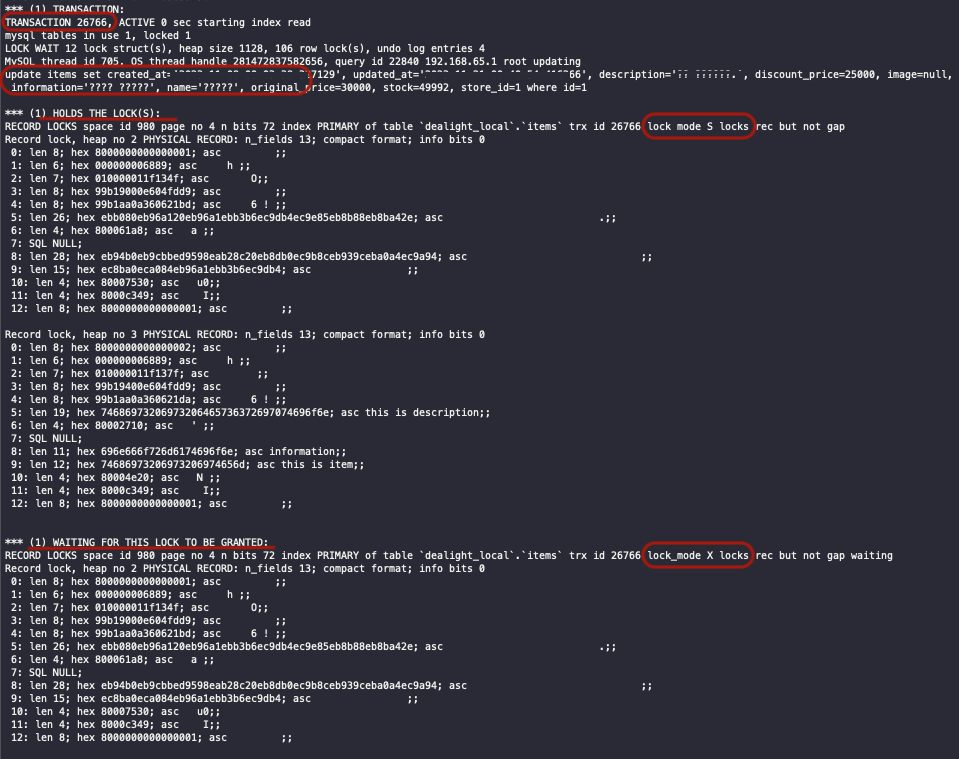
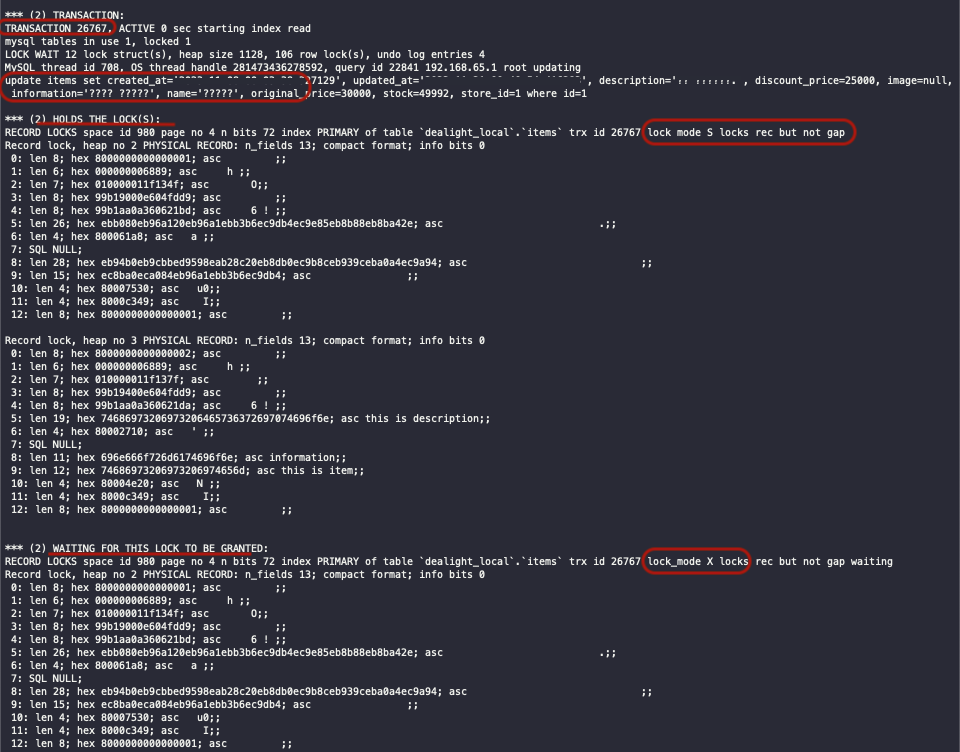
2. 데드락 발생
DB상의 lock을 사용하지 않았음에도 데드락이 발생했습니다.
show engine innodb status;
원인 분석
1. Lost Update
100건의 API 요청은 정상적으로 이루어졌으며 DB 상에도 100건의 주문이 저장되었습니다. 그러나 재고가 정상적으로 줄어들지 않은 이유는 상품이라는 공유 자원에 여러 트랜잭션(고객)이 접근하면서 발생한 race condition 때문입니다.
race condition(경쟁 상태) : 둘 이상의 입력 또는 조작의 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태
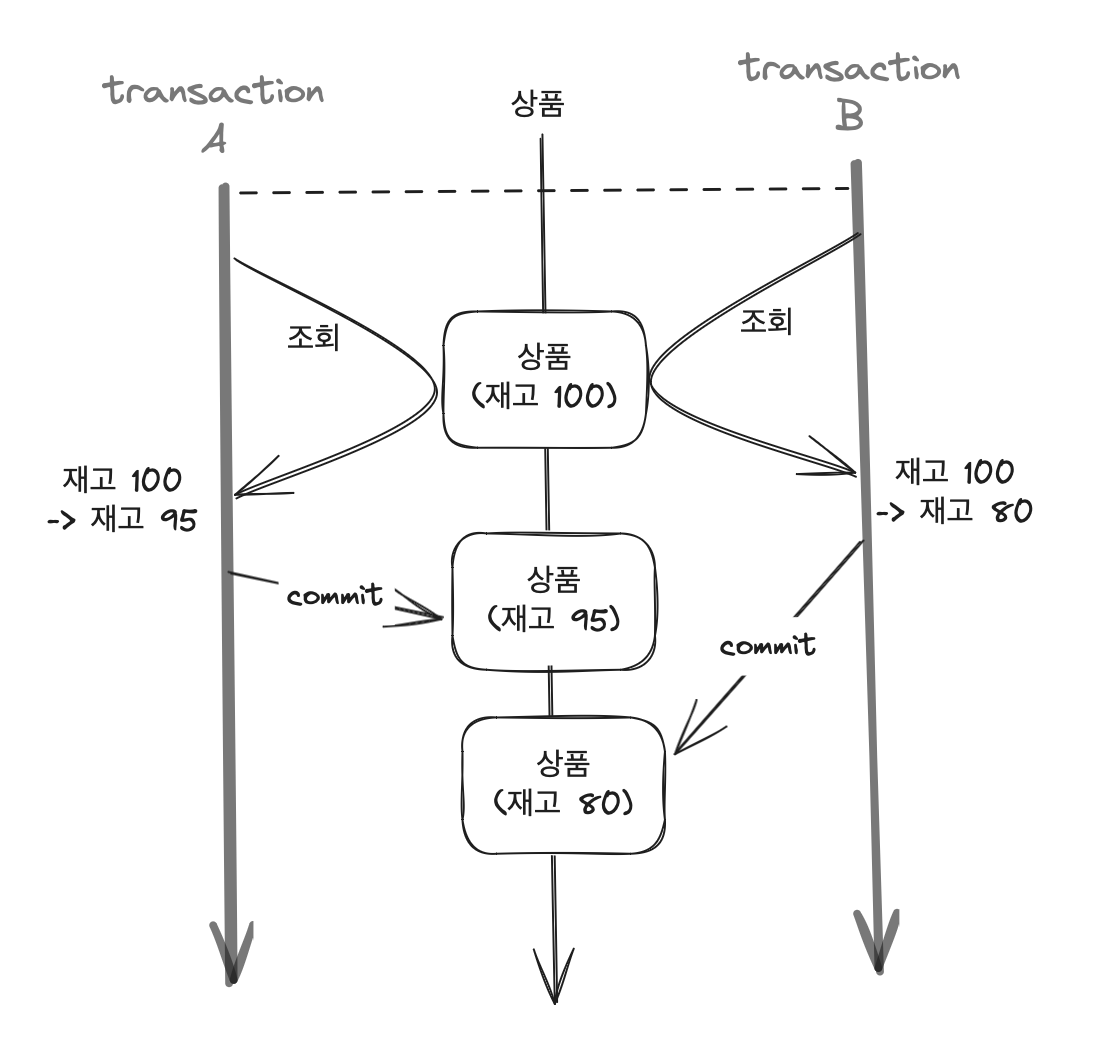
고객 A, B 모두 같은 상품을 하나씩 구매한다고 가정할 때
동일한 재고를 읽어온 뒤
고객 A에 의해 해당 상품의 재고가 감소하여 db에 반영되기 전
고객 B로 인한 상품의 재고 감소가 이루어지면서 A에 의한 재고 감소가 무시되고 B에 의한 요청만 처리됩니다.
결과적으로 두 번의 갱신 중 하나만 반영되는 갱신 손실(두 번의 갱신 분실 문제)이 발생한 것입니다.
2. 데드락 발생 : MySQL lock
상품(Item) 재고를 차감하는 과정에서 두 트랜잭션이 s lock을 건 상태로 x lock을 걸기 위해 시도하다가 무한 대기 중입니다.

별도로 DB 상의 lock을 사용하지 않았는데 s-lock, x-lock을 획득 시도하고 데드락이 발생했습니다.
적용하지 않은 lock으로 인해 데드락이 걸리는 것이 의아해 mysql 자체적인 기능이 있지 않을까 하여 공식 문서에 lock,s lock,x lock 등의 키워드로 검색해 보니 다음과 같은 내용을 확인할 수 있었습니다.
-
외래키 제약 조건이 있는 테이블에서 insert/update/delete 수행시 제약 조건 확인을 위해 해당 레코드에 shared lock이 걸립니다.
If a FOREIGN KEY constraint is defined on a table, any insert, update, or delete that requires the constraint condition to be checked sets shared record-level locks on the records that it looks at to check the constraint. InnoDB also sets these locks in the case where the constraint fails.
-
Update 수행시 exclusive next-key lock이 걸립니다.
UPDATE ... WHERE ... sets an exclusive next-key lock on every record the search encounters. However, only an index record lock is required for statements that lock rows using a unique index to search for a unique row.
🔒 제 프로젝트에서는....
각 주문(Order)와 주문된 상품(Item)들의 다대다 관계를 매핑하는 OrderItem 테이블이 있습니다. 이 테이블에서는 주문 ID(orderId)와 상품 ID를 외래키로 갖습니다.
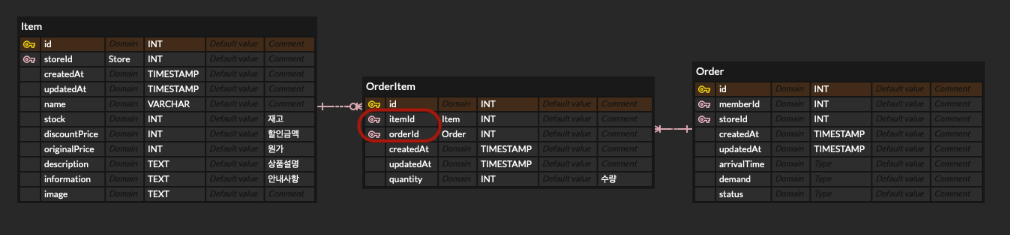
트랜잭션 A와 B가 같은 상품을 구매하기 위해 시도할 때
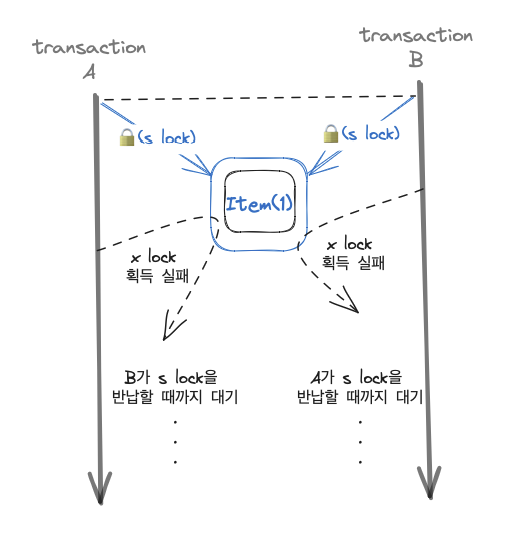
- s lock이 다른 트랜잭션에 걸려 있으면 x lock을 획득할 수 없음
- Repeatable의 격리 수준에서 트랜잭션이 s lock을 획득하면 트랜잭션이 종료될 때 반납
이 두 가지를 전제로 아래와 같은 상황에 의해 데드락이 발생합니다.
(1) A와 B에서 OrderItem에 Insert를 수행할 때 Item에 shared lock 획득
(2) A가 해당 상품의 재고를 차감하는 과정에서 exclusive lock을 얻기 위해 시도하지만 B가 shared lock을 가지고 있어 실패 -> 대기
(3) B도 재고 차감을 위해 exclusive lock 획득 시도 -> B의 shared lock으로 인해 실패 -> 대기
(4) A와 B는 Repeatable Read의 격리 수준에서는 트랜잭션이 끝날 때 shared lock을 반납하므로 무한 대기
해결 과정
(1) 🔒 데드락 해결
데이터베이스(MySQL) 격리 수준을 READ COMMITTED으로 변경
데이터를 조회할 때에 s lock을 요청하지 않아 위와 같은 데드락이 발생하지 않습니다. 다만 Non-Repeatable Read의 문제가 발생할 수 있고 대부분의 데이터베이스에서 최소 Read Committed의 격리 수준을 권장합니다.
외래키를 사용하지 않도록 수정
👉🏻 그러나 저희 프로젝트에서는 외래키를 사용했습니다.
학습 단계에 있기에 더욱더 외래키 제약조건을 강제하지 않는다면 무결성이 깨질 우려가 높다고 판단했고 쓰지 않는다면 테스트 데이터를 넣기에 편하지만, 무결성을 검증하는 것이 더 리소스가 든다고 보았습니다.
👉🏻 외래키가 체크하는 무결성은 다음과 같습니다.
(참조되는 테이블 : 부모 테이블, 참조하는 테이블 : 자식 테이블)
- 자식 테이블에서 INSERT 할 때 참조키가 부모 테이블에 있는지
- 자식 테이블에서 참조키를 UPDATE할 때 변경 후 값이 부모 테이블에 있는지
- 부모 테이블에서 DELETE 할 때 자식 테이블에서 참조하고 있는지
외래키 없이 애플리케이션 단에서 검증하기 위해서는 추가적인 조회(정합성 검증 프로세스)가 필요합니다.
-> 개발 과정에서 복잡도를 높이며 프로그램 성능에도 좋지 않습니다.
(2) Lost Update 해결
🧩 쿼리문 수정
: UPDATE items SET stock = 99 WHERE item_id = 1
->
UPDATE items SET stock = stock - 1 WHERE item_id = 1
- 동시에 재고를 읽고 그 값에서 수량만큼 줄인 뒤 갱신할 때 누락되는 거라면 현 재고에서 1씩 빼주면 문제가 없을까 해서 시도해 봤습니다.
- 그러나 이 경우 재고를 불러와서 검증하는 과정이 생략되어 재고가 0임에도 계속 구매가 승인되거나 기존 재고 이상으로 늘어날 위험성이 있습니다.
- 그리고 수량이 1이 아닌 경우 반복적인 쿼리문이 발생하고 그 중간에 오류가 발생하는 경우 데이터 정합성이 깨질 우려가 있습니다.
🧩 격리 수준 높이기
(1) Repeatable Read에서의 갱신 손실 원리
spring의 어노테이션 @Transactional 을 이용해 격리 수준 높여서 해결해 보고자 했습니다.
그 전에 각 격리 수준에 대해 알기 위해선 데이터베이스 병행제어 실패시 발생하는 문제들에 대해 알아야 합니다.
- Dirty read : 트랜잭션 t1이 데이터를 수정하고 커밋하기 전에 트랜잭션 t2가 해당 데이터를 읽는 것. t1이 데이터를 복구(롤백)하면 t2는 커밋된적 없는(=존재한 적 없는) 데이터를 읽게 되는 것입니다.
- Non-Repeatable Read : 트랜잭션 t1이 데이터를 읽기 -> 트랜잭션 t2가 데이터를 수정하거나 삭제하여 커밋 -> t1이 다시 같은 데이터를 읽었을 때는 처음과 달라지는 것.
- Phantom (Read) : 트랜잭션 t1이 특정 조건에 만족하는 n개의 데이터를 읽기 -> t2가 해당 조건에 만족하는 데이터를 추가하거나 삭제한 경우. t1이 같은 조건으로 데이터를 조회하면 조회된 데이터의 개수가 n개와 달라지는 것.
그리고 격리 수준에 따라 발생할 수 있는 문제들입니다.
| Read Uncommitted | Read Committed | Repeatable Read | Serializable Read | |
|---|---|---|---|---|
| level | ANSI level 0 | ANSI level 1 | ANSI level 2 | ANSI level 3 |
| Dirty Read | O | X | X | X |
| Non-Repeatable Read | O | O | X | X |
| Phantom Read | O | O | O | X |
다시 돌아와 MySQL의 기본 격리 수준은 REPEATABLE READ 입니다.
해당 격리 수준에서 갱신 손실은 다음과 같이 발생합니다.
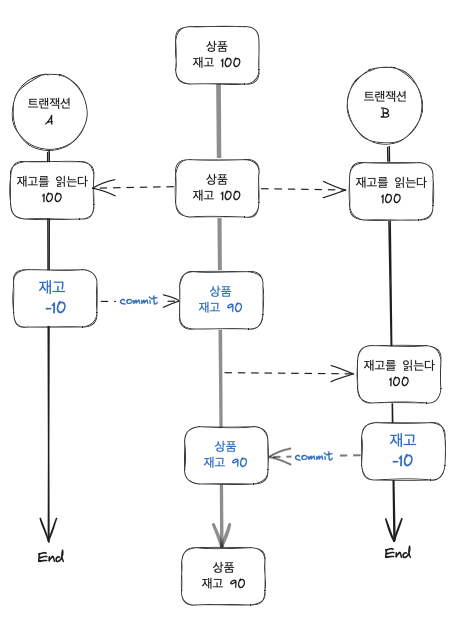
격리 수준이 Repeatable Read인 경우에는 다른 트랜잭션에서 해당 데이터를 변경할 수 없도록 보장합니다.
다시 말해, 트랜잭션이 읽은 데이터를 해당 트랜잭션이 종료될 때까지 동일한 값으로 유지하는 것이 목표이므로 트랜잭션 A에 의해 재고가 감소하였음에도 불구하고 트랜잭션 B에 의해 두 번째로 상품의 재고를 읽었을 때 처음과 동일한 100으로 조회됩니다.
결과적으로 트랜잭션 A에 의해 수행된 갱신이 무시되는 것입니다.
cf. DB는 쿼리를 실행할 때 log를 저장한 뒤 log를 통한 특정 시점의 DB 스냅샷을 복구하는 방식으로 non-repeatable read를 방지합니다.
구체적으로는 ROLLBACK이 될 가능성을 대비해 변경되기 전 레코드를 Undo 공간에 백업해 두고 실제 레코드값을 변경합니다.
(2) 격리 수준을 Serializable로 올린다?
처음에는 격리 수준 과 DB Lock의 개념이 헷갈려 격리 수준을 올리면 되는 것 아닌가 라고 생각했습니다.
그 둘의 차이는
- 격리 수준을 높이는 것은 트랜잭션 단위의 데이터 정합성을 보장하기 위함이고
- DB lock은 여러 커넥션이 한 데이터에 접근할 때의 동시성을 제어하기 위함입니다.
격리 수준을 serializable로 올린다면 shared lock / exclusive lock이 사용됩니다.
이에 따라
특정 사용자가 조회 중인 상품에 대해서는(shared lock이 설정된 row)
다른 고객이 구매할 수 없습니다(exclusive lock을 사용할 수 없음).
기존의 데드락을 해결할 수 없을 뿐만 아니라 심화되고 성능상의 문제도 있습니다.
🧩 Pessimistic Lock
트랜잭션 간의 충돌이 발생한다고 가정하고, 데이터에 접근하기 전에 락을 걸어 다른 트랜잭션의 접근을 막는 것입니다.
데이터베이스 select for update 을 사용합니다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<Item> findById(Long providerId);추가적인 락으로 인한 성능 저하와 데드락(교착 상태)이 발생할 수 있습니다.
그리고 종류로는 다음과 같습니다.
- Shared Lock (S Lock): 여러 트랜잭션에서 동시에 읽기를 허용하지만, 쓰기는 막습니다.
- Exclusive Lock (X Lock): 특정 트랜잭션이 데이터를 독점적으로 읽고 쓸 수 있도록 합니다.
- Update Lock (U Lock) : X 락을 획득하기 위해 사용되는 임시 락으로, 다른 U 락이나 X 락을 막습니다.
🧩 Optimisitic Lock
트랜잭션간의 충돌이 발생하지 않는다고 '낙관적으로' 가정하고, 동시성 문제가 발생하면 처리하는 방식입니다.
두 번의 갱신 분실 문제에 대해 최초 커밋만 인정하고 나머지 커밋에 대해서는 예외가 발생하는 방식으로 버전을 이용합니다.(참고)
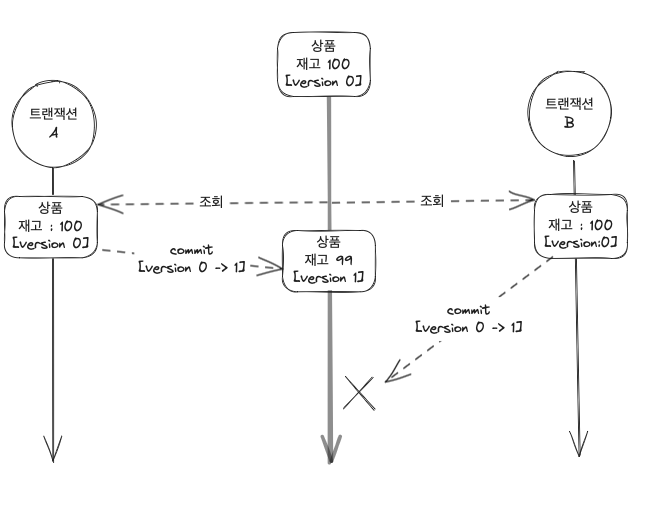
상품 엔티티에 버전 체크를 위한 필드를 추가하고 @Version 어노테이션을 붙여 관리하도록 하였습니다.
@Version
private Long version;
그리고 주문을 위해 상품을 조회하는 메소드에 다음과 같이 lock을 겁니다.
@Query(value = "SELECT i FROM Item i WHERE i.id = :id")
@Lock(LockModeType.OPTIMISTIC_FORCE_INCREMENT)
Optional<Item> findById(Long id);Optimistic lock에 여러 옵션이 있지만 연관관계를 맺고 있는 엔티티의 변경에도 버전을 증가시키기 위해 OPTIMISTIC_FORCE_INCREMENT 옵션을 사용했습니다.
Optimisitic Lock은 최초 커밋만 인정하고 나머지 커밋에 대해서는 예외가 발생하는 방식인데 이때 다음과 같은 예외가 발생합니다.
javax.persistence.OptimisticLockException(JPA)org.hibernate.StaleObjectStateException(Hibernate)org.springframework.orm.ObjectOptimisticLockingFailureException(Spring)
try-catch 문으로 예외를 잡아 처리하거나 재시도하도록 하는 방식으로 해결할 수 있습니다.
그래서 저는 컨트롤러 단에서 아래와 같이 상품 재고가 부족하여 예외가 발생하지 않는 이상 반복 처리하도록 했습니다. 이유는 트랜잭션 간의 충돌이 발생이 적을 것으로 예상하고 낙관적 락을 사용하는 것이기 때문입니다.
{
OrderRes orderRes;
while (true) {
try {
orderRes = orderService.create(request, providerId);
break;
} catch (OptimisticLockException | StaleObjectStateException |
ObjectOptimisticLockingFailureException ignored) {
}
}
URI uri = ServletUriComponentsBuilder
.fromCurrentRequest()
.path("/{id}")
.buildAndExpand(orderRes.orderId())
.toUri();
return ResponseEntity.created(uri)
.body(orderRes);
}퍼사드 클래스로 분리할 수도 있겠지만 아래와 같은 처리에서는 반복 외에 특별한 기능이 있지 않고 재사용의 여지도 없어 분리할 필요성을 느끼지는 못했습니다.
🧩 Named Query를 이용해 동시성 문제 & 데드락 해결
기존에는
(1) OrderItem을 생성하는 과정에서 외래키인 상품 아이디에 해당하는 상품 레코드에 s lock을 획득
(2) Item 재고 감소를 위해 x lock 요청
의 순서로 이루어 졌습니다. 그리고 (2) 단계에서 동시에 해당 상품을 주문한 다른 고객, 즉, 다른 트랜잭션에 의한 s lock으로 인해 데드락에 걸렸습니다.
(2)번 단계를 구체적으로는
영속성 컨텍스트에 의해 관리되고 있는 상품을 가져와 상품 재고를 차감하여 dirty checking에 의해 상품 엔티티가 수정됩니다.
Item item = itemRepository.findById(request.itemId())
.orElseThrow(() -> {
log.warn("GET:READ:NOT_FOUND_ITEM_BY_ID : {}", request.itemId());
return new EntityNotFoundException(NOT_FOUND_ITEM);
});
int quantity = request.quantity();
item.deductStock(quantity);
return OrderItem.builder()
.item(item)
.order(order)
.quantity(quantity)
.build();그래서 x lock 을 먼저 획득하는 방식으로 해결해 보고자 했습니다. Dirty checking 대신 DB에 저장된 재고에서 구매 수량을 차감하는 방식으로 수정하였습니다.
int orderedCount = itemRepository.updateStock(itemId, quantity);
if (orderedCount == 0) {
throw new BusinessException(INVALID_ITEM_QUANTITY);
}
아래와 같은 쿼리문을 Atomic Query 라고 합니다.
@Modifying(clearAutomatically = true, flushAutomatically = true)
@Query(value = """
UPDATE Item i SET i.stock = i.stock - :quantity
WHERE i.id = :itemId AND i.stock > 0 AND i.stock >= :quantity
""")
int updateStock(Long itemId, int quantity);재고 차감시에
(1) 기존 재고가 0보다 크고
(2) 구매 수량 이상의 재고가 남았는지 확인
합니다.
따라서 반환 값이 0인 경우는 이미 재고가 0이거나 구매 수량이 재고보다 큰 경우입니다. 이 경우 미리 정의해 둔 예외를 던지도록 하였습니다.
이를 통해 갱신 분실을 해결할 수 있고 (DB에 저장된 재고에서 수량을 차감하므로) s lock보다 x lock을 먼저 획득함으로써 데드락을 해결할 수 있습니다.
🧩 Redis를 활용한 해결
현재 Redis를 다른 기능을 위해 사용 중이어서 추가 인프라 구축이 필요 없다는 장점이 있습니다. 그리고 락에 대한 관리/부하를 Redis로 분리하는 것이 효율적일 수 있습니다.
-
Lettuce로 분산락을 사용하면 락을 획득할 때까지 반복적으로 요청하는 방식으로 요청에 비례하여 Redis가 받는 부하도 커지게 됩니다.
-
현재 한정된 메모리와 ec2를 사용하는 상황에서 분산락을 사용하는 경우 redis의 장점을 살릴 수 없겠다고 판단했고 별도의 lock interface까지 지원하는 Redisson으로 구현했습니다.
-
Redisson은 Pub-sub 방식으로 락이 해제되면 subscribe 하던 클라이언트가 락이 해제되었다는 신호를 받고 락 획득을 시도합니다.
재고를 redis에 관리하고 아래와 같은 플로우도 생각했습니다.
- 상품 구매 -> redis에 해당 상품에 대한 정보가 있는지 확인 -> 있다면 redis 에서 재고 차감, 없다면 DB에서 재고 데이터를 가져와 저장
그러나 상품 재고는 중요한 데이터인 것에(재고보다 많은 주문을 받으면 안되고 정산과도 이어지므로) 비해 redis에 저장하는 것은 유실될 위험이 있고 위의 플로우의 경우 redis와 DB간의 데이터 정합성이 깨질 우려도 있습니다.
성능 테스트 & 결론
고객 1000명이 동시에 한 상품을 구매할 때에 대한 테스트를 Jmeter를 활용하여 진행했습니다.
테스트 환경 : MacBook Pro 로컬 환경 (Apple M1 Pro RAM 16GB, CPU 10 core)
| 비관적락 | 낙관적락 | redis | named query & db lock | |
|---|---|---|---|---|
| TPS(Transactions/s) | 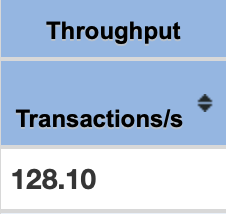 |  |  | 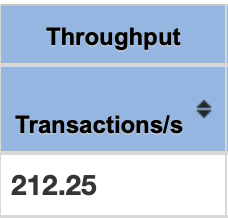 |
프로젝트에는 named query와 db lock으로 추가적인 lock을 최소화하는 방법으로 구현했습니다.
이유는
- 스케일 아웃된 DB 환경 또는 여러 대의 서버를 구현하고 있지 않아 분산락의 필요성은 느끼지 못했고
- 나머지 비관적락/낙관적락/named query를 이용하는 방법 중에는 named query를 사용하는 편이 성능이 좋았습니다.
다만 단점으로는
- 기존 Order 도메인 내부에서 dirty checking을 통해 처리하던 재고 차감을 도메인 외부인 service 레이어에서 처리하게 됩니다
- 영속성 컨텍스트와 데이터베이스 간의 정합성이 어긋나는 점과
named query전flush()가 발생해야 하는 점으로 인해 추가적인 영향이 우려됩니다.(확인하지는 못했습니다)
그 외
- 링크의
Slotted Counter Pattern을 이용해 병렬적인 실행도 가능케 할 수 있습니다
